the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 30 Aug 2021
| 30 Aug 2021
An all-sky 1 km daily land surface air temperature product over mainland China for 2003–2019 from MODIS and ancillary data
Shunlin Liang
Bing Li
Qian Wang
Surface air temperature (Ta), as an important climate variable, has been used in a wide range of fields such as ecology, hydrology, climatology, epidemiology, and environmental science. However, ground measurements are limited by poor spatial representation and inconsistency, and reanalysis and meteorological forcing datasets suffer from coarse spatial resolution and inaccuracy. Previous studies using satellite data have mainly estimated Ta under clear-sky conditions or with limited temporal and spatial coverage. In this study, an all-sky daily mean land Ta product at a 1 km spatial resolution over mainland China for 2003–2019 has been generated mainly from the Moderate Resolution Imaging Spectroradiometer (MODIS) products and the Global Land Data Assimilation System (GLDAS) dataset. Three Ta estimation models based on random forest were trained using ground measurements from 2384 stations for three different clear-sky and cloudy-sky conditions. The random sample validation results showed that the R2 and root-mean-square error (RMSE) values of the three models ranged from 0.984 to 0.986 and from 1.342 to 1.440 K, respectively. We examined the spatiotemporal patterns and land cover type dependences of model accuracy. Two cross-validation (CV) strategies of leave-time-out (LTO) CV and leave-location-out (LLO) CV were also used to evaluate the models. Finally, we developed the all-sky Ta dataset from 2003 to 2009 and compared it with the China Land Data Assimilation System (CLDAS) dataset at a 0.0625∘ spatial resolution, the China Meteorological Forcing Data (CMFD) dataset at a 0.1∘ spatial resolution, and the GLDAS dataset at a 0.25∘ spatial resolution. Validation accuracy of our product in 2010 was significantly better than other datasets, with R2 and RMSE values of 0.992 and 1.010 K, respectively. In summary, the developed all-sky daily mean land Ta dataset has achieved satisfactory accuracy and high spatial resolution simultaneously, which fills the current dataset gap in this field and plays an important role in the studies of climate change and the hydrological cycle. This dataset is currently freely available at https://doi.org/10.5281/zenodo.4399453 (Chen et al., 2021b) and the University of Maryland (http://glass.umd.edu/Ta_China/, last access: 24 August 2021). A sub-dataset that covers Beijing generated from this dataset is also publicly available at https://doi.org/10.5281/zenodo.4405123 (Chen et al., 2021a).
- Article
(7443 KB) - Full-text XML
- BibTeX
- EndNote





Surface air temperature (Ta) is one of the most important variables in a wide range of fields including ecology, hydrology, climatology, epidemiology, and environmental science (Goetz et al., 2000; Stisen et al., 2007; Vancutsem et al., 2010; Zhang et al., 2018). Ta refers to the atmospheric temperature 1.5–2 m above the surface, which represents the thermal state information of the surface and the lower atmosphere. It influences the carbon cycle through the biophysical effects of vegetation and regulates many surface processes such as photosynthesis, respiration, and evaporation (Khesali and Mobasheri, 2020). Reliable estimates of Ta at fine spatiotemporal resolution are important to better understand and simulate complex surface processes and reveal changes due to climate change or local disturbances (Guan et al., 2013). Moreover, in the context of continuous global warming, meteorological disasters caused by frequent extreme weather events and consequential social and economic losses are gradually increasing. A deep understanding of the spatiotemporal patterns of Ta is also of great guiding significance for disaster prevention and reduction.
However, because of its proximity to the interface between the land/ocean and atmosphere, the near-surface air is influenced by various exchange processes between these three Earth system compartments (Schwingshackl et al., 2018). The spatiotemporal patterns of Ta can vary and be complicated due to the heterogeneity of various environmental factors (such as solar radiation, latitude, underlying surface, cloud cover, and season) that impact the energy balance of the land–atmosphere system (Benali et al., 2012; Chen et al., 2015; Prihodko and Goward, 1997).
Ta data are one of the most frequent forms of observation data recorded by meteorological stations. In situ Ta usually has reliable accuracy and high temporal resolution; however, it has some flaws, such as limited spatial representation, measurement inconsistency, and uneven spatial distribution of ground stations (Jang et al., 2014; Prihodko and Goward, 1997). Geographical interpolation methods such as inverse distance weighting (IDW), kriging, and spline function have been widely used to estimate the spatial distribution of Ta (Benavides et al., 2007; Ishida and Kawashima, 1993; Kurtzman and Kadmon, 1999). However, these methods usually consider only the autocorrelation of Ta, ignoring the complex factors that lead to its heterogeneity. The accuracy of interpolated Ta is greatly affected by station network density, which leads to relatively poor accuracy being obtained in areas with sparse station density (Stisen et al., 2007; Vogt et al., 1997). Therefore, the accuracy of interpolated Ta may have significant errors associated with unrepresentative spatial patterns, and there can be great uncertainty in describing the spatial patterns of Ta over large areas in this way (Benali et al., 2012; Rao et al., 2018).
Remotely sensed data have provided unprecedented spatial coverage at regional and global spatial scales (Liang, 2004). Over the past few decades, many schemes have been developed to estimate Ta from remotely sensed data. The strong physical relationship between the land surface temperature (LST) and Ta has become the research basis of many Ta estimation methods. Generally speaking, the LST-based Ta estimation methods can be divided into three distinct categories. The first type is the traditional statistical method, including the univariate regression method to establish a linear relationship between Ta and LST, and multiple regression methods considering various variables (such as solar zenith angle, elevation, and Julian day) in addition to LST (Lin et al., 2012; Zeng et al., 2015). The second is the temperature–vegetation index (TVX) method, based on the negative correlation between the normalized difference vegetation index (NDVI) and LST in the study area (Stisen et al., 2007; Vancutsem et al., 2010; Zhu et al., 2013). The third is the land surface energy-balance physical method, which uses the crop water stress index (CWSI) and the aerodynamic resistance to estimate Ta. This method has a good physical basis but usually relies on numerous input parameters (such as roughness and soil physical properties), which are always difficult to obtain (Sun et al., 2004). In principle, the atmospheric profile products from satellite observations include the temperature profile of the entire atmosphere but usually require additional processes to obtain Ta. The Moderate Resolution Imaging Spectroradiometer (MODIS) atmospheric profile product has been used for this purpose (Bisht and Bras, 2010; Borbas and Menzel, 2017; Famiglietti et al., 2018; Zhu et al., 2017). Generally, traditional statistical methods have been commonly used but have reported low accuracy. In recent years, machine learning methods, particularly deep learning methods, such as support vector machine (Zhang et al., 2016), artificial neural network (Jang et al., 2010; Zhang et al., 2016), M5 model trees (Emamifar et al., 2013), random forest (RF) models (Noi et al., 2017; Xu et al., 2014; Zhang et al., 2016), cubist models (Meyer et al., 2016; Noi et al., 2017; Rao et al., 2019), and advanced deep learning methods (Shen et al., 2020), have been gradually applied to Ta estimation from satellite data because of their stronger learning ability to capture the complex nonlinear relationship between various factors.
Most LST-based Ta estimation methods mentioned above are suitable only for clear-sky conditions as the current LST datasets are mainly derived from satellite thermal infrared radiances (TIR) that are susceptible to cloud contamination (Liang et al., 2019; Ma et al., 2020). Currently, there are two main strategies for estimating all-sky Ta based on LST: one is to first derive Ta from the available LST and then fill the Ta gaps (Rosenfeld et al., 2017; Zhang, 2017); the other is to first fill the LST gaps to develop a seamless product and then estimate the all-sky Ta (Kilibarda et al., 2014; Li et al., 2018; Rao et al., 2019). For example, Zhang (2017) estimated Ta under clear-sky conditions based on MODIS LST, and the Atmospheric Infrared Sounder (AIRS) standard Ta products were used to fill the cloudy-sky pixels after a downscaling process, with a mean absolute error (MAE) of 1.2 K and a root-mean-square error (RMSE) of 1.6 K overall. According to the research conducted by Kilibarda et al. (2014), the 8 d composite LST was interpolated into a daily dataset and then combined with topographic layers and a geometric temperature trend to interpolate the all-sky daily Ta, and the results reported that the RMSE values were between 2 and 4 ∘C for daily mean, maximum, and minimum Ta. In addition, Zhu et al. (2017) developed a parameterization scheme to estimate all-sky instantaneous daytime Ta only relying on the MODIS atmospheric profile product. They first established the relationship between LST and Ta under clear-sky conditions and then estimated Ta under cloudy-sky conditions based on the established relationship, with RMSE values ranging from 2.50 to 2.56 ∘C.
Currently, several studies have been conducted to develop all-sky Ta datasets based on remotely sensed data. For instance, Li et al. (2018) used a three-step hybrid gap-filling method to attain seamless LST; they then developed daily geographically weighted regression (GWR) models to interpolate Ta using gap-filled LST and elevation, and finally developed a 1 km daily minimum/maximum Ta dataset in urban and surrounding areas in the conterminous US for 2003–2016. The cross-validation results reported that the RMSE values were 2.1 and 1.9 ∘C for daily minimum and maximum Ta, respectively. In the recent work conducted by Yao et al. (2020), the MODIS 8 d composite LST was averaged to obtain monthly mean LST and was then combined with the enhanced vegetation index (EVI), solar radiation, topographic index, and other features to establish a cubist model for generating 1 km monthly maximum/mean/minimum Ta products in China: the RMSE of the estimated monthly mean Ta was 0.629 ∘C. Rao et al. (2019) first filled the gaps of LSTs and then used the gap-filled LSTs and some radiation products to build cubist models for estimating all-sky daily mean Ta, with an RMSE of 1.87 ∘C. Finally, a 0.05∘ × 0.05∘ daily mean Ta product over the Tibetan Plateau for 2002–2016 was developed. In addition, multiple reanalysis and meteorological forcing datasets covering large areas or global areas exist, which are usually generated by data assimilation or data interpolation, such as the Global Land Data Assimilation System (GLDAS; Rodell et al., 2004); Modern-Era Retrospective Analysis and Research and Application, version 2 (MERRA-2; Gelaro et al., 2017); China Meteorological Forcing Data (CMFD; Yang and He, 2019); and China Land Data Assimilation System (CLDAS; Shi et al., 2011). However, these datasets have coarse spatial resolution (generally ≥ 0.1∘ except for CLDAS, which has a spatial resolution of 0.0625∘) and regional inaccuracy, which may limit their potential to accurately capture the spatial heterogeneity of Ta in the urban and mountainous areas and lead to uncertainties for applications at local to regional scales (Jang et al., 2014; Li et al., 2018; Zhu et al., 2017). To our knowledge, there is currently a lack of long-time-series all-sky Ta products covering vast areas with both high spatial and temporal resolution.
The main objective of this study is to develop an all-sky 1 km daily mean land Ta over mainland China for 2003–2019 by integrating satellite data products, model simulations, and ground measurements. For the first time, assimilated Ta was applied to supplement and substitute MODIS LSTs and provide the initial values of model prediction. In order to solve the issue of missing LST, a simple temporal gap-filling method was used to fill the gaps of MODIS LSTs first. Considering the differences in the relationship between Ta and other features under different weather conditions, we divided all data pairs into three types of weather conditions – (1) clear-sky conditions, (2) cloudy-sky conditions case I, and (3) cloudy-sky conditions case II – and then established three machine learning models to estimate daily mean Ta under different weather conditions. The structure of this paper is organized as follows: Sect. 2 describes the study area and the data used; Sect. 3 summarizes the overall research method; Sect. 4 reports the validation results and discusses the model performance; Sect. 5 compares the developed dataset with the existing datasets; and Sect. 6 presents the overall conclusions.
2.1 Meteorological station data
This study was conducted in mainland China. The station-observed daily mean Ta from 2003 to 2019 was collected from 2384 standard meteorological stations in mainland China for model training and validation. During the production process of this dataset, it experienced strict quality control. Figure 1 shows the study area and the geographical location of the meteorological stations used in this study. Each dot represents a station, and different colors correspond to different land cover types. The land cover data used in the study are Finer Resolution Observation and Monitoring of Global Land Cover (FROM-GLC), version2 (2015_v1), which are 30 m resolution global land cover maps (Gong et al., 2013).
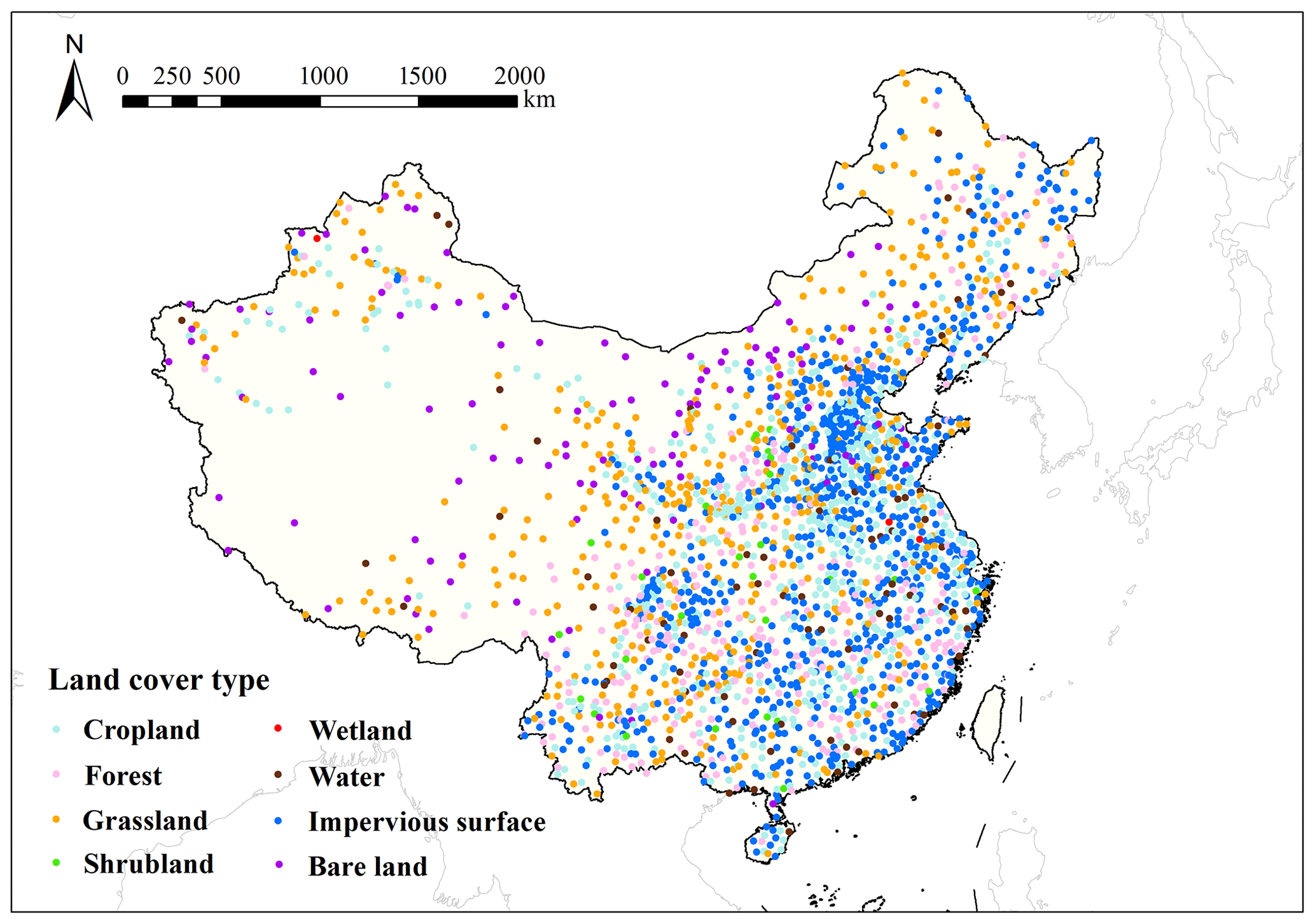
Figure 1Study area and the location of meteorological stations used in this study. Each dot represents a station, and different colors correspond to different land cover types as shown in this figure legend.
2.2 Remotely sensed data
The satellite datasets used in this study are listed in Table 1.

Terra and Aqua MODIS daily 1 km LST products (MOD11A1/MYD11A1, C6) both provide daytime and nighttime LSTs with a spatial resolution of 1 km (Wan et al., 2015).
Three all-sky products from the Global LAnd Surface Satellite (GLASS) products suite (Liang et al., 2013, 2021) were used, including the GLASS 1 km 8 d surface broadband albedo (ALB) product GLASS02A06 (Liu et al., 2013), the GLASS 0.05∘ daily downward shortwave radiation (DSR) product GLASS05B01 (Zhang et al., 2019), and the GLASS 1 km 8 d leaf area index (LAI) product GLASS01A01 (Xiao et al., 2014). For the ALB product, we used the black-sky albedo of shortwave (BSA_sw), visible (BSA_vis), and near-infrared (BSA_nir) bands. As radiation products, DSR and ALB determine the shortwave solar radiation received at the surface and the fraction of total radiation reflected and absorbed by the surface, respectively.
The Global Multi-resolution Terrain Elevation Data 2010 (GMTED2010) elevation dataset, downloaded from the United States Geological Survey (USGS, https://topotools.cr.usgs.gov/GMTED_viewer/viewer.htm, last access: 24 August 2021), was also chosen to estimate Ta.
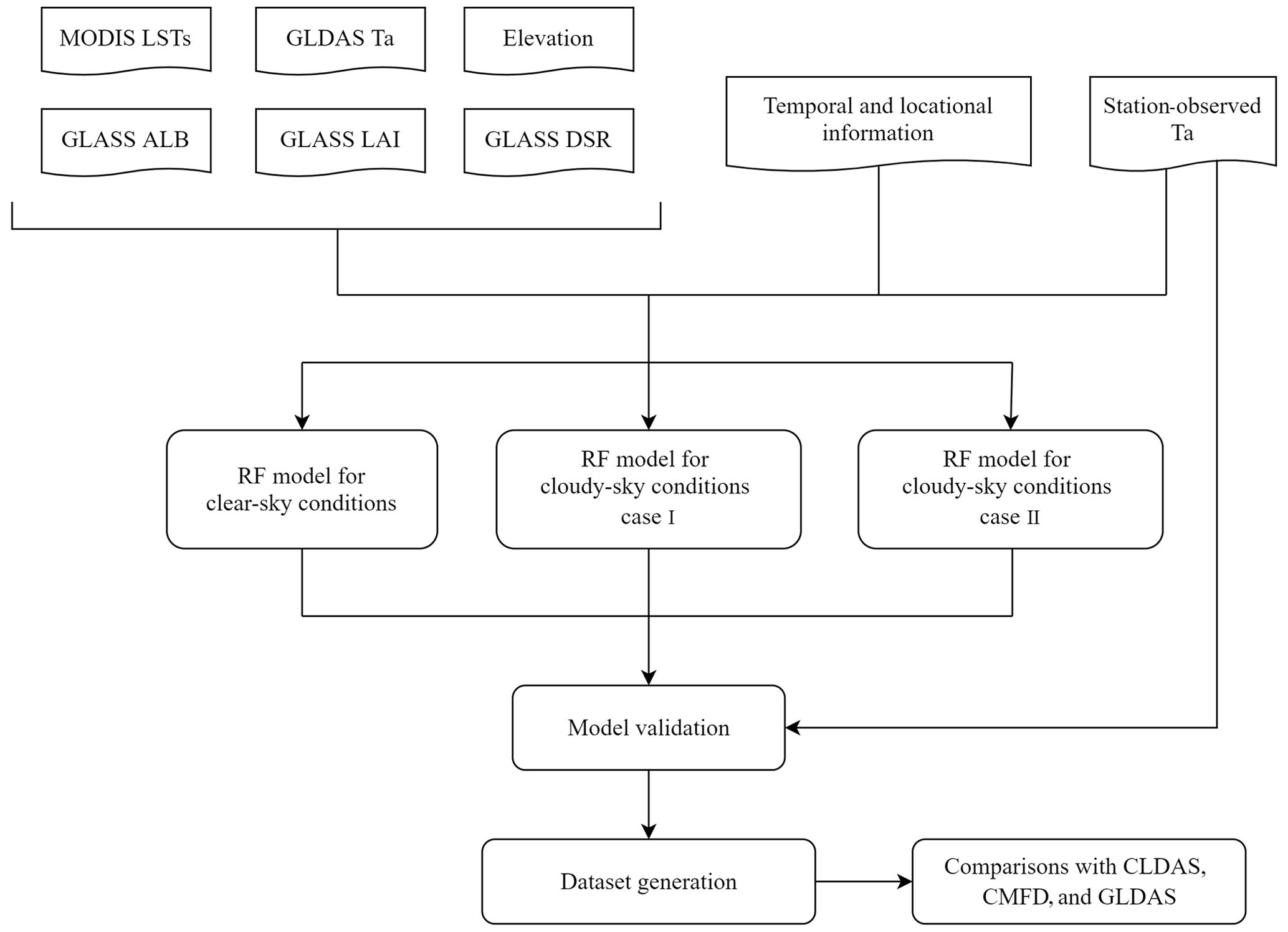
The overall framework of this study is shown in Fig. 2. First, all datasets from 2003 to 2019 were preprocessed into identical spatial and temporal resolutions. Second, we filled the gaps of MODIS LSTs and then divided all data pairs into three weather conditions according to the gap-filling results. Next, the values of all datasets were extracted using the nearest-neighbor method according to the geographical location of stations and then matched with the in situ Ta to obtain data pairs. Data pairs under different weather conditions from 2003 to 2016 were randomly divided into training, validation, and test sets (ratio of ). Three RF models for different weather conditions were established and trained using the training set. Three model validation strategies of random sample validation, leave-time-out (LTO) cross-validation (CV), and leave-location-out (LLO) CV were then used to evaluate the models. Finally, we used the models to develop the all-sky Ta dataset from 2003 to 2009 and compared it with the existing datasets.
3.1 Data preprocessing
Because the spatial and temporal resolutions of all datasets were not completely consistent, we preprocessed all remotely sensed datasets and reanalysis datasets from 2003 to 2019 into identical 1 km and daily spatial and temporal resolutions, respectively. DSR, elevation, and assimilated Ta were resampled to a 1 km spatial resolution using the nearest-neighbor method. As LAI and ALB datasets both have an 8 d temporal resolution, we first combined them into a time series and then interpolated the time series using the linear interpolation method to obtain the daily datasets. For GLDAS assimilation data with a 3 h temporal resolution, we averaged all assimilated instantaneous Ta in a day to acquire the assimilated daily mean Ta for all days.
The values of all datasets were then extracted using the nearest-neighbor method according to the geographical locations of stations and matched with the in situ Ta to obtain data pairs. Next, we used a temporal gap-filling method to fill the MODIS LST gaps and divided all data pairs into three weather conditions according to the gap-filling results. The detailed gap-filling method and strategy for the division into weather condition categories is described in the Sect. 3.2. The data pairs with different weather conditions from 2003 to 2016 were then randomly divided into training, validation, and test sets (ratio of ). Among them, the training set was used for model training, the validation set was used to determine the best model parameters, and the test set was used to evaluate the final model performance.
3.2 Strategies for LST gap-filling and division into weather condition categories
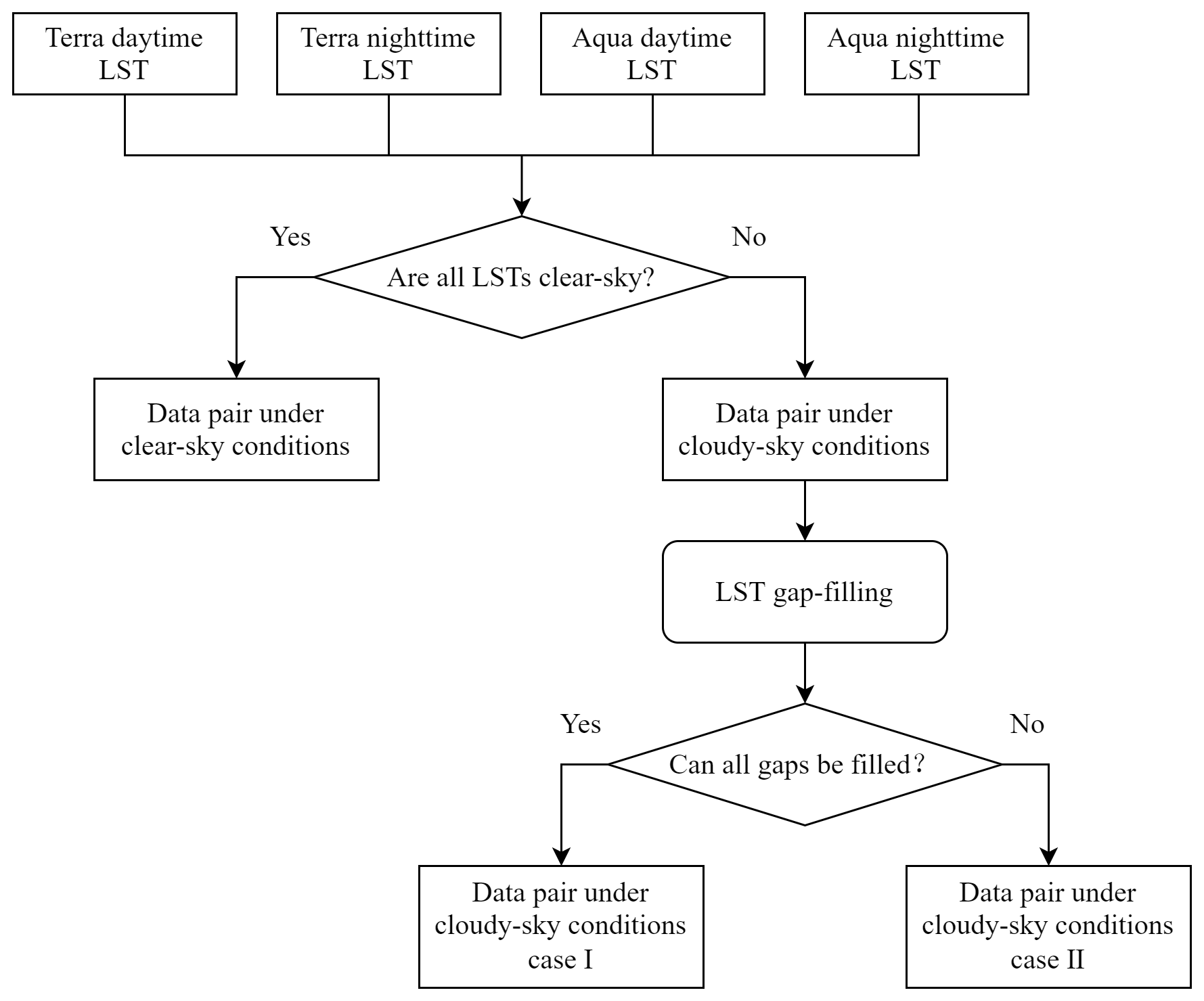
MODIS LSTs were produced under strict quality control, with each pixel marked as either a clear-sky or cloudy-sky observation. Pixels under cloudy-sky conditions had missing LST values, meaning that the LST-based method could not be applied to estimate Ta. In this study, a simple multitemporal method was used to fill the MODIS LST gaps. First, we set a time threshold (±2 d), and the missing pixel value was replaced by the clear-sky value of the nearest date within the set time threshold. If no clear-sky pixel was found within the time threshold, the missing pixel was not filled to avoid introducing high uncertainty caused by a huge temperature change between dates with large differences. This multitemporal method was used to fill the gaps of all four MODIS LSTs each day.
Considering the differences in the relationship between Ta and other features under different weather conditions, we divided data pairs into clear-sky conditions and cloudy-sky conditions according to the LSTs gap-filling results. When all four LSTs in a day were under clear-sky conditions, the data pair was identified as being under clear-sky conditions; otherwise, it was identified as being under cloudy-sky conditions. To control the uncertainty introduced by LST gap-filling, cloudy-sky conditions were divided into two cases: case I and case II. In particular, a data pair was identified as being under cloudy-sky conditions case I when there were LST gaps in the data pair and the gaps could be filled using the method mentioned above. If the LST gaps could not all be filled, the data pair was identified as being under cloudy-sky conditions case II. Therefore, we finally divided all data pairs into three weather condition categories: (1) clear-sky conditions, (2) cloudy-sky conditions case I, and (3) cloudy-sky conditions case II. The detailed criteria for dividing weather conditions are shown in Fig. 3.
Next, we established three machine learning models (clear-sky model, cloudy-sky model I, and cloudy-sky model II) and trained them separately for different weather conditions. Daily LSTs were used in models for clear-sky conditions (clear-sky model) and cloudy-sky conditions case I (cloudy-sky model I), but not for cloudy-sky conditions case II (cloudy-sky model II). GLDAS-assimilated Ta, GLASS DSR, GLASS ALB, GLASS LAI, elevation, and temporal and locational information were also used in all three models as input features. For the clear-sky model, the utilized features included four clear-sky LSTs in a day. The qualification for a pixel of a given day to be judged as clear-sky may be harsh, but this ensured the use of completely clear-sky LSTs. The features of cloudy-sky model I included gap-filled LST(s), which increased the availability of LST, but the simple gap-filling strategy also introduced errors to the models. To avoid instilling high uncertainty caused by a large temperature change between dates with large differences, cloudy-sky model II did not use LST to estimate Ta.
3.3 Random forest
The RF method (Breiman, 2001) is an ensemble learning method based on classification and regression tree (CART) proposed by Breiman et al. (1984). Since it was proposed, it has attracted the attention of quite a few fields of study and has specifically had various applications in remote sensing in recent years (Gislason et al., 2006; Ham et al., 2005; Li and Zha, 2019; Xu et al., 2014).
A decision tree is a tree-like prediction model composed of nodes and directed edges. In each internal node of the decision tree, the sample set is segmented by selecting the optimal splitting feature until the segmentation termination condition is reached. Each path from the root node to the leaf nodes of a decision tree forms a classification. There are many algorithms for decision tree, such as ID3 (Quinlan, 1986), C4.5 (Quinlan, 1992), and CART. These algorithms all adopt the top-down greedy algorithm, and each internal node chooses the feature with the best classification effect to split, in order to achieve the goal of dividing samples into subsets that are as homogenous as possible, with the fastest speed. In the generation algorithms of ID3 and C4.5 decision tree, information gain or the information gain rate is used as the criterion to judge the optimal segmentation. Another type of optimal segmentation criterion is Gini impurity, which is utilized in the CART decision tree. In the RF model, multiple CART decision trees are included. The bagging method (Breiman, 1996) is used to generate independent identically distributed training sample sets for each tree and train on them.
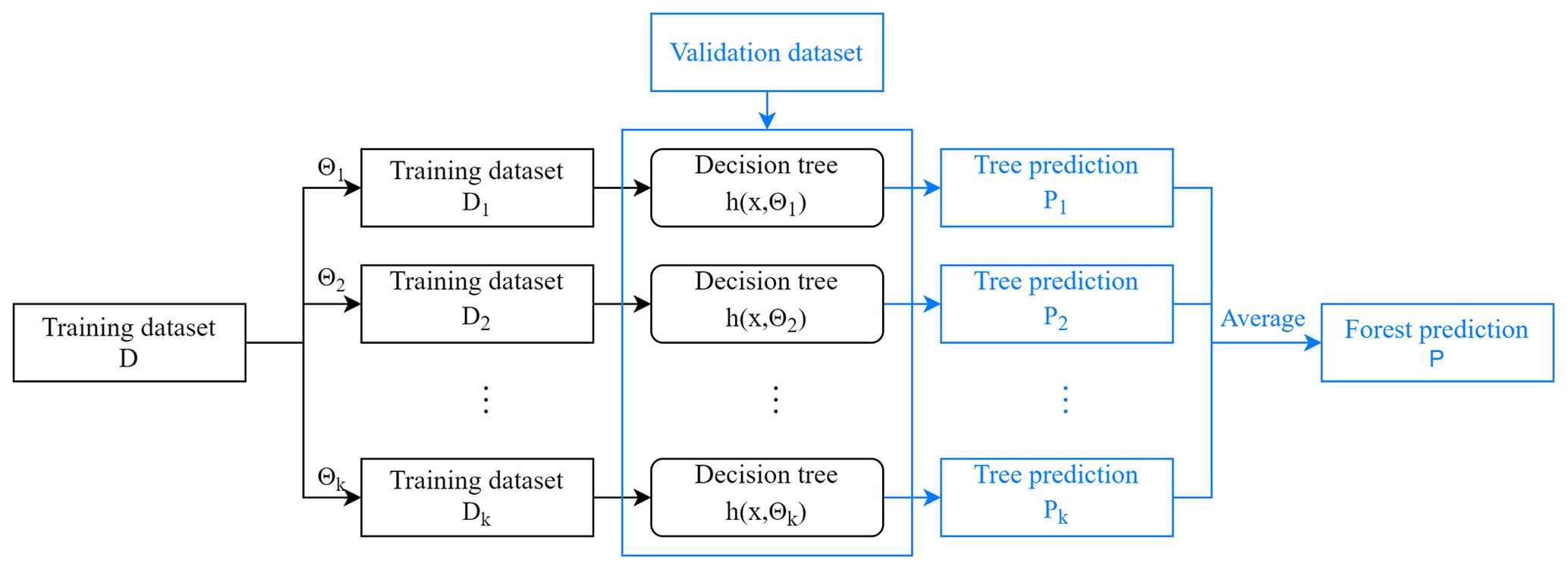
Although the application of RF at present is mainly focused on classification, it can be also used in regression analysis effectively, which can usually achieve higher accuracy than traditional regression analysis methods. The training and prediction process of the RF regression model is shown in Fig. 4. First, the bootstrapping method is used to acquire k datasets and then k decision trees are established, respectively, where x is the input vector, and Θk () is the random vector determining the sampling of bootstrap datasets and candidate splitting features of each tree. The construction of a decision tree is realized by iteratively dividing the datasets into two subsets. Different from the RF classification model, the mean square error (MSE) is used as the optimal segmentation criterion in the RF regression model to split the nodes. Each decision tree in the RF regression model takes values rather than types as output targets, and the average of the predicted values of all the trees is used as the final prediction.
3.4 Model training and validation
During the model training process, the training set was used for model training, and the validation set was used to determine the models with the optimal hyperparameters.
Compared with artificial neural network, the RF regression model does not need to carry out complicated parameter tuning work, and changing some insignificant parameters of the RF model may not cause substantial fluctuations in model performance. The two most critical hyperparameters, ntree and mtry, need to be determined during training. Among them, ntree refers to the number of decision trees in the RF model. Increasing ntree is conducive to improving the model performance and stability but also affects the computational efficiency of the program. Mtry refers to the maximum number of features used in a single decision tree. When mtry is less than the total number of features, the segmentation of a node is determined based on partial features that are randomly selected rather than all features. Increasing mtry allows nodes to consider more features when splitting but also reduces the diversity of individual trees, thereby increasing the risk of overfitting. Therefore, both parameters need to be properly balanced and selected, and we used the validation set to evaluate the model performance with different combinations of parameters to obtain the optimal hyperparameters.
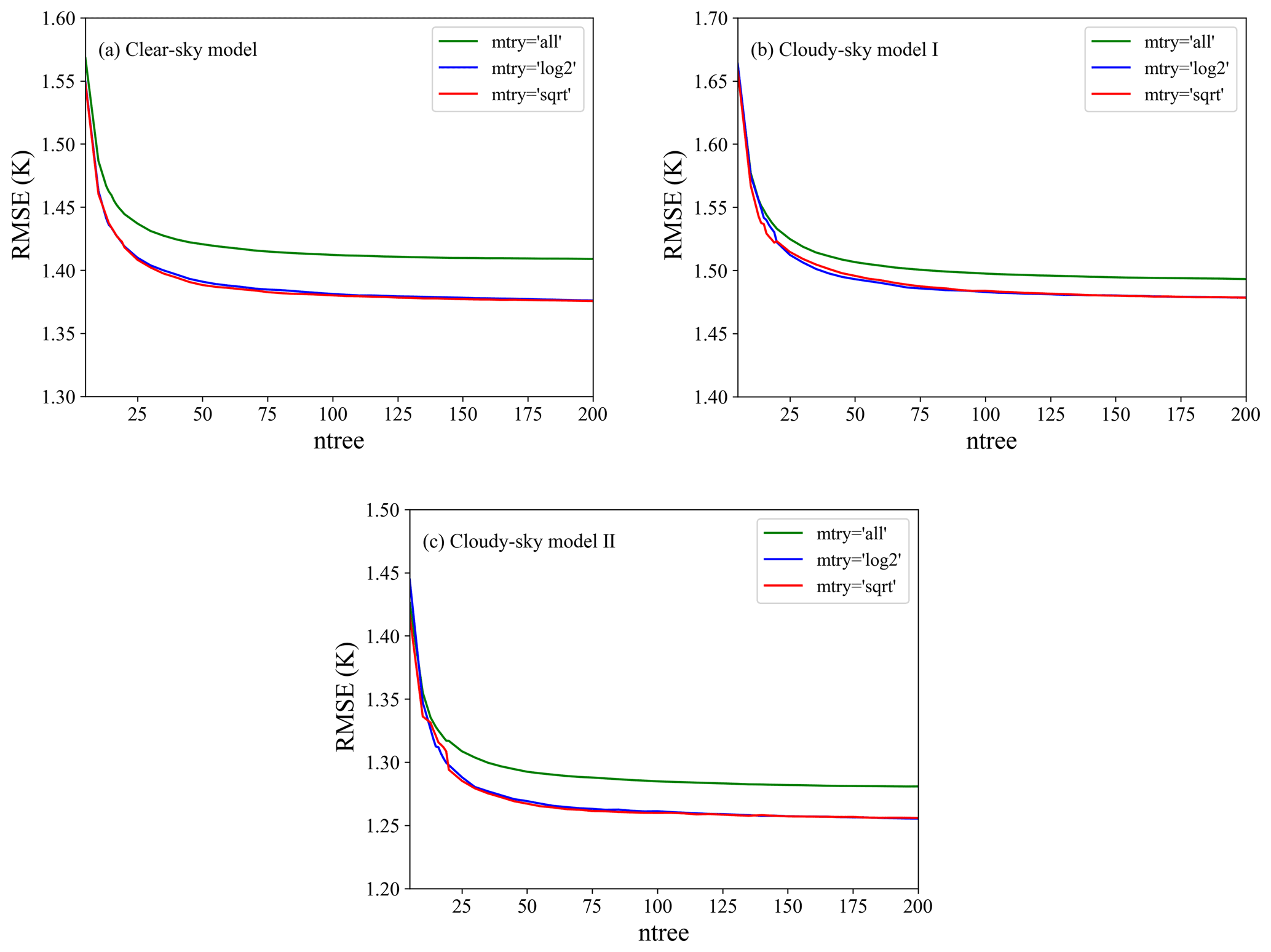
Assuming the total number of features of a sample is m, the values of mtry include log2m, sqrt(m), and m, and ntree is set to 5–200. To analyze the RF model performance sensitivity to hyperparameters, the RMSE values of the three models for different weather conditions were calculated when setting different parameters, and the result is shown in Fig. 5. It can be seen from the results that with the change in model parameters, the three models showed similar variation patterns. With the increase of ntree, the RMSE value decreased gradually until it became almost constant (when ntree ≥ 100). The continued increase of ntree made very little contribution to improving the model performance but affected the computing efficiency. For mtry, we can see that using partial features (mtry of log2m or sqrt(m)) resulted in significantly better performance than using all features (mtry of m). Overall, setting mtry to log2m and sqrt(m) presented similar performance, and the setting of sqrt(m) performed slightly better than log2m when ntree was larger than 175. Therefore, we set ntree to 200 and mtry to sqrt(m) in all models.
To quantitatively evaluate the effect of each feature on the models, we calculated the feature importance (FI) of every feature using the permutation method for each model. The permutation method breaks the statistical relationship between feature i and the target variable and then measures the degree of deterioration in the model performance to evaluate the importance of feature i to the model (Mcgovern et al., 2019). Specifically, the model is first trained with the training set, and the RMSE of the validation set (RMSEtrue) is then calculated using Eq. (1). For the calculation of the FI of feature i, RMSEi is calculated again after all the features i of the validation set are shuffled. The difference between RMSEtrue and RMSEi is calculated and then divided by RMSEtrue, and the result is used as FI, as shown in the Eq. (2). A large FI value means that the model performance decreases significantly after shuffling this feature, which indicates that this feature has a great impact on the accuracy of prediction results. On the contrary, if the model performance does not deteriorate significantly, it is obvious that this feature has less influence on the prediction process, or that other linearly dependent features are included in the model to make this feature redundant.
where ypre refers to model prediction result, and yobs refers to the corresponding station observation. RMSEtrue is the RMSE of the validation set, and RMSEi refers to the RMSE of the validation set after feature i has been shuffled.
The Ta predicted by the models was compared to the corresponding station observations. The RMSE, MAE, and R2 were selected as criteria for model evaluation. In order to comprehensively evaluate the performance of the models, we adopted three model validation strategies: random sample validation, LTO CV, and LLO CV. For random sample validation, the test set (one-fifth of the total data from 2003 to 2016 selected randomly) was used to evaluate the performance of the final Ta estimation models. The results were grouped by elevation range, land cover type, and month to evaluate the model performance under different situations. For LTO CV and LLO CV, we divided all data pairs into 14 groups according to calendar year and 7 groups according to geographical location. In each iteration, one group of data was used for validation, and the other groups of data were used as the training set for model training. The modeling and validation process were repeated 14 and 7 times until each year's data and each cluster of data were validated, respectively. These two CV strategies have been used in some studies to evaluate the performance of spatiotemporal models in unknown time or unknown space (Liu et al., 2020; Ploton et al., 2020; Xiao et al., 2018).
4.1 Overall accuracy and model comparison
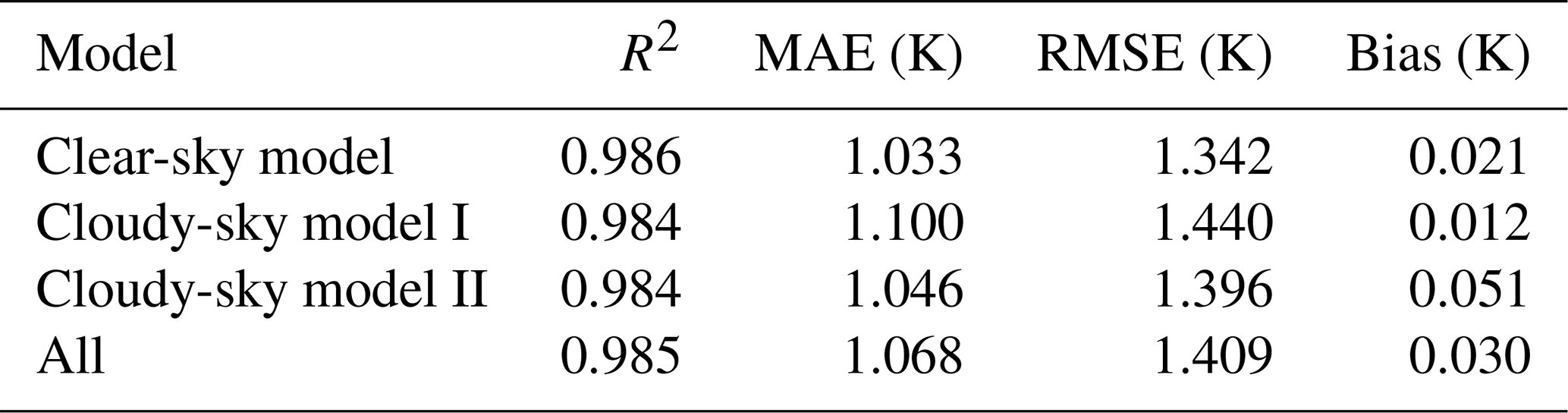
Approximately three-fifths and one-fifth of the data pairs from 2003 to 2016 were randomly selected for training and tuning the models, respectively, and the remaining one-fifth of the total data pairs were used to evaluate the performance of the final Ta estimation models. Validation statistics of models for different weather conditions and the overall accuracy of all estimated daily mean Ta are shown in Table 2. The three models presented similar validation statistics, with R2, MAE, RMSE, and bias values ranging from 0.984 to 0.986, 1.033 K to 1.100 K, 1.342 K to 1.440 K, and 0.012 K to 0.051 K, respectively. The overall R2, MAE, RMSE, and bias values of the estimated all-sky Ta were 0.985, 1.068 K, 1.409 K, and 0.03 K, respectively. Compared with the in situ Ta, the estimated Ta of all models showed a high correlation with little difference, confirming the great potential of the RF method to estimate the all-sky daily mean Ta over a wide spatial and temporal range.
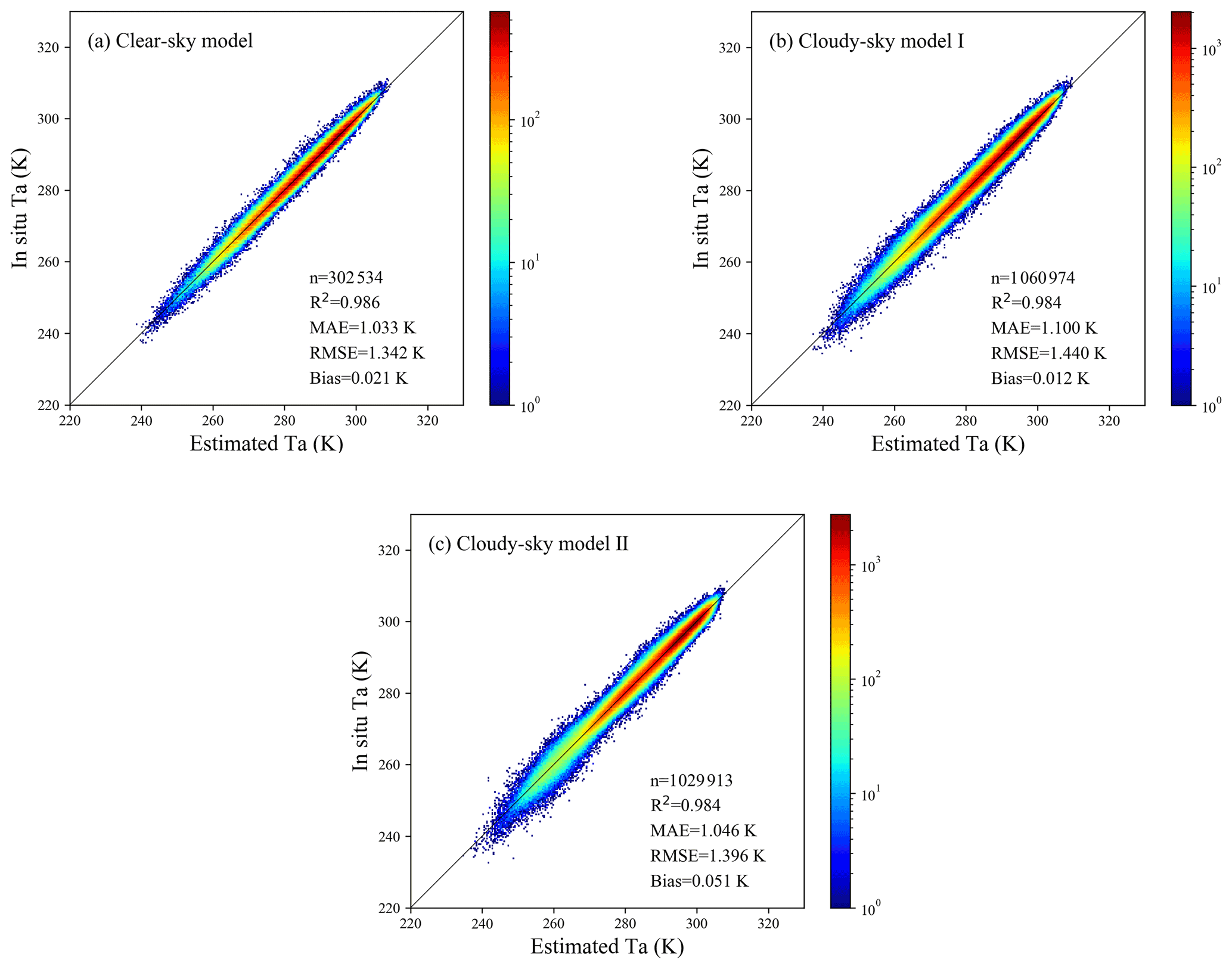
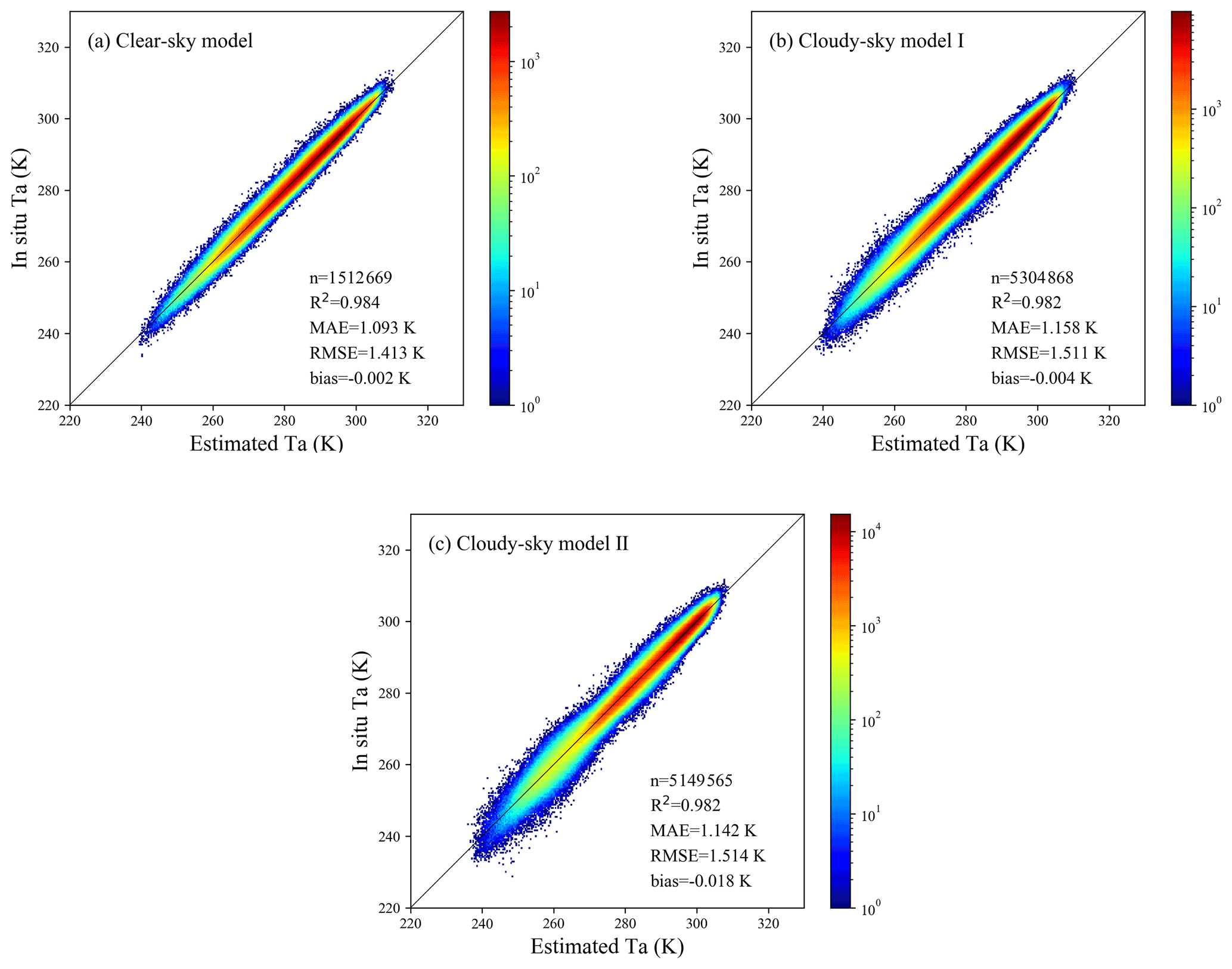
In addition, to further investigate the distribution of the prediction results and the differences between the three models, density scatterplots of the estimated Ta against the in situ Ta for the three models are shown in Fig. 6. In the three density scatterplots, most points were very concentrated near the 1:1 line, which also confirmed that these three models have achieved satisfactory accuracy in estimating daily mean Ta under different weather conditions. Among all the models, the clear-sky model had the highest stability and overall accuracy statistically, with the highest R2 and the lowest MAE and RMSE. It could predict Ta under clear-sky conditions from less than 250 K to more than 300 K accurately and steadily. Compared with the clear-sky model, cloudy-sky model I had a relatively large error, which demonstrated that the LST gap-filling strategy adopted in this study introduced errors into the model to some extent, thereby increasing the uncertainty in estimating Ta under cloudy-sky conditions case I. The accuracy of the cloudy-sky model II was statistically similar to that of the clear-sky model, and it could predict a moderate temperature range close to 275 K with satisfactory performance. However, it can be seen from the density scatterplot for cloudy-sky model II that some discrete points deviated from the 1:1 line in the low-temperature range, which indicated that there may be much uncertainty in predicting the low-temperature range, especially at temperatures less than 260 K.
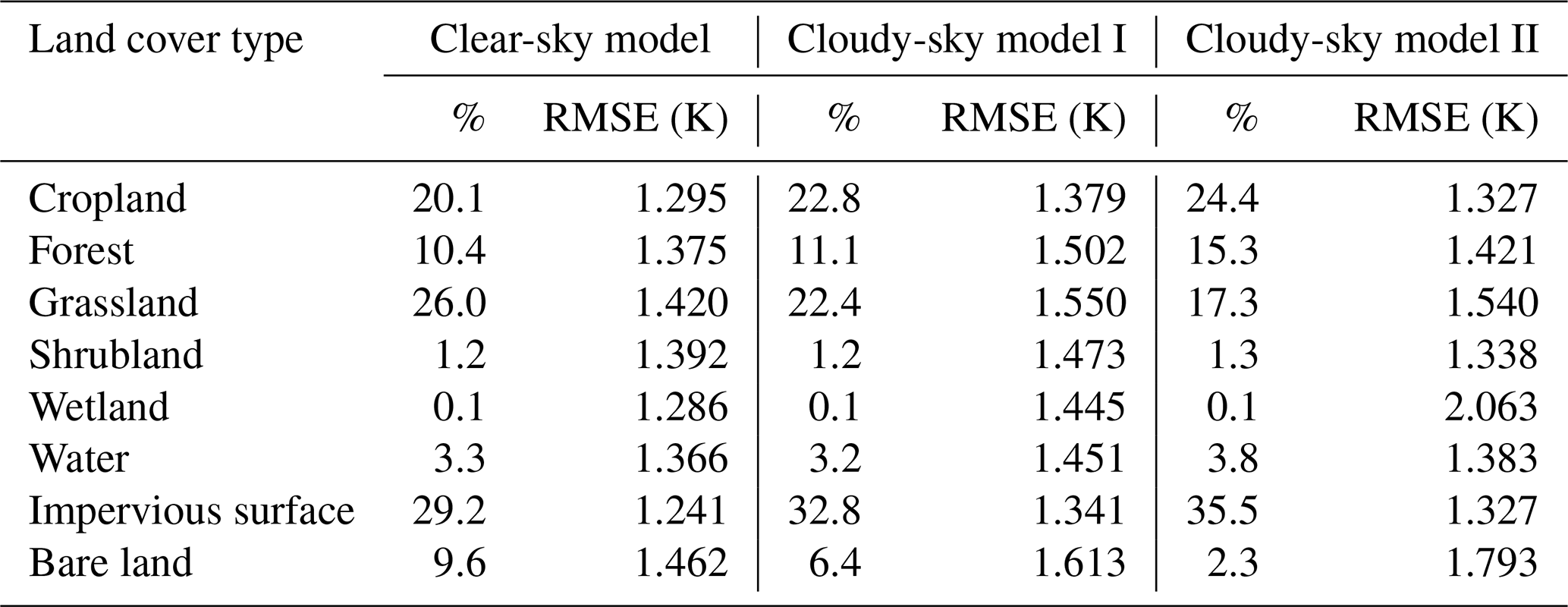
Many studies have proved that land cover type and elevation have a significant impact on the heterogeneity of Ta (Benali et al., 2012; Good et al., 2017; Lin et al., 2012; Marzban et al., 2017). Therefore, to comprehensively analyze the performance of the Ta estimation models, we grouped the results by land cover type and elevation range, and then compared the model performance for different groups. The model performance for different land cover types is listed in Table 3. All models showed relatively good performance (RMSE < 1.5 K) for cropland, shrubland, water, and impervious surface, whereas RMSE values were higher for grassland and bare land, which was consistent with the findings of Shen et al. (2020). The model performance for different elevation ranges is also listed in Table 4. With the increase in elevation, RMSE values of all models had a certain upward trend. However, as shown in the Fig. 7, the elevations of the stations used in this study are mainly distributed in the range from 0 to 2000 m, so the quantity of training samples in this elevation range have an absolute superiority, whereas the samples from higher elevations (elevation > 2000 m) only occupy a small part. The problem of class imbalance may contribute to the relatively large errors when predicting Ta at high elevation. In addition, factors such as complex and varied topography, vertical variation in Ta, and scale differences between remotely sensed image pixels and station observation data points will lead to high difficulty and uncertainty in Ta estimation at higher elevations (Rao et al., 2019).

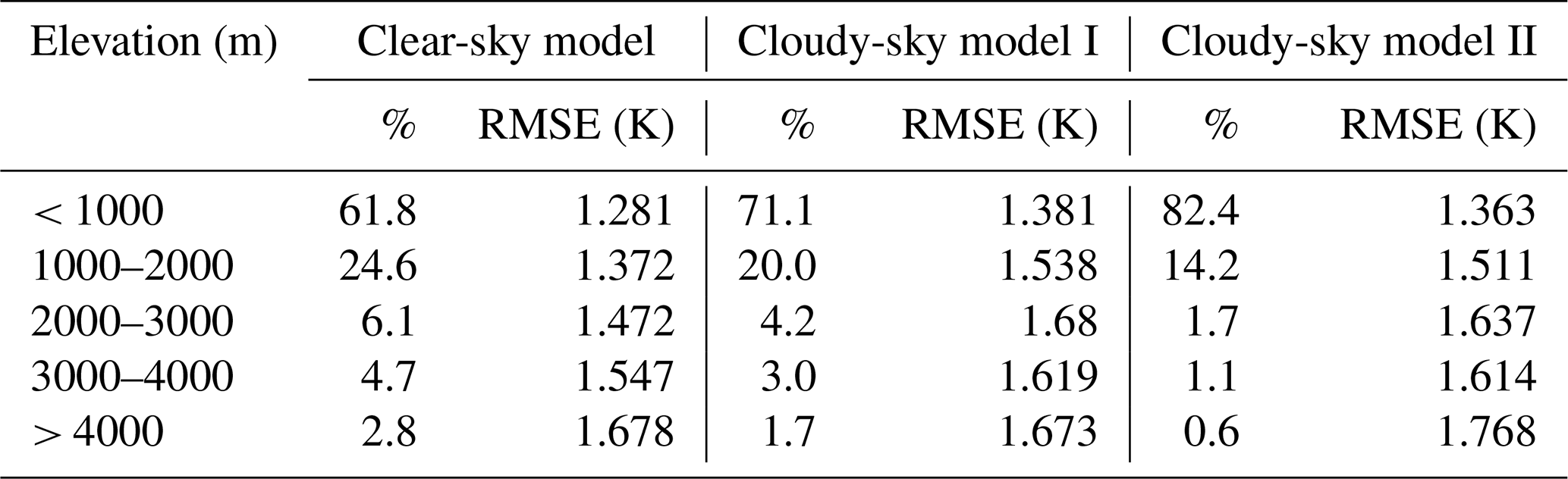
We further evaluated the error distribution of the three models at the stations. Due to the absence of in situ Ta at some ground stations on some days, only the stations that recorded more than 20 d for all three weather conditions were taken into account. Thus, the results of 2320 valid stations were finally obtained, as shown in Table 5. In general, the models showed good performance at most stations, with a mean RMSE value of 1.383 K. Moreover, 97 % of stations had RMSE values less than 2 K and only 1 of the 2320 statistical stations had an RMSE value greater than 3 K. The clear-sky model also had the best performance at the station scale, with the lowest mean RMSE of 1.231 K. A total of 508 stations had RMSE values less than 1 K, 2286 stations had RMSE values less than 2 K, while only 2 stations had RMSE values greater than 3 K. For cloudy-sky model I, the mean RMSE reached 1.432 K. The RMSE values of 2256 stations were less than 2 K, and only 1 station had an RMSE greater than 3 K. For cloudy-sky model II, the mean RMSE was 1.440 K, which was close to cloudy-sky model I, and 121 stations had RMSE values less than 1 K. However, 13 stations had RMSE values greater than 3 K for cloudy-sky model II, and most of these stations had RMSE values less than 3 K for the other two models.
For model comparison, as expected, the clear-sky model that used absolutely clear-sky LSTs performed better than cloudy-sky model I and cloudy-sky model II in almost every aspect and presented the highest stability. Cloudy-sky model I, which contained gap-filled LSTs, did not perform as well as the clear-sky model because, although the time threshold (±2 d) of the LST gap-filling method was relatively small, the LST value of a missing pixel of a date may be replaced by a clear-sky value with a difference of up to 2 d. However, the LST can vary considerably in just a few days, so the LST gap-filling process can introduce large errors into the model, thereby affecting the accuracy of Ta estimation. Surprisingly, cloudy-sky model II, which did not use LST features, achieved a comparative accuracy with the clear-sky model (respective RMSE values of 1.396 K vs. 1.342 K) statistically. However, when we further analyzed the model performance in specific situations, we detected differences in the performance of the three models. There may be considerable uncertainty associated with the cloudy-sky model II with respect to predicting the low-temperature range, especially at less than 260 K. Notably, cloudy-sky model II performed poorly for wetlands, with an RMSE of 2.063 K, whereas both the clear-sky model and cloudy-sky model I performed well on this type of land cover. This may be because wetlands are a mixture of water and land, with diverse complex ecological environments. Using LST can significantly improve the Ta estimation accuracy of this land cover type.
In summary, because of the strong correlation between Ta and LST, adding daily LSTs as features to models can improve the model stability and robustness. In the absence of LST, assimilated Ta can be used as a substitute for LST to provide an initial value or first guess for the model to estimate Ta with acceptable accuracy when combined with other features. However, the resolution of the reanalysis product is relatively coarse, and some local details were ignored when sampling from a larger scale (0.25∘ × 0.25∘) to a smaller scale (1 km × 1 km), thereby causing explicit uncertainties for cloudy-sky model II with respect to predicting the low-temperature range or some regions, especially some specific land cover types or regions with complex terrain. Overall, none of the three models showed significant differences in the model performance, and the model performance discrepancies for different land cover types and elevation ranges were acceptable. The proposed models can perform well in different situations and are suitable for Ta estimation under different weather conditions.
4.2 Cross-validation
In addition to random sample validation, two CV methods were used to further evaluate model performance. For the LTO CV, we divided the data pairs from 2003 to 2016 into 14 groups by calendar year. In each iteration, 13 groups of data were used as a training set for model training, and the remaining 1 group of data was used for validation. The modeling and validation process were repeated 14 times until the data for each year were validated. The results are shown in Fig. 8. The RMSE values of validation results for different groups of data ranged from 1.359 to 1.665 K. The minor difference between the LTO CV results proved that these models have good extensibility in time.
For the LLO CV, we then divided seven clusters in the Chinese region using the similar separation strategy of Xiao et al. (2018). Stations used in this study were divided into different clusters according to their spatial locations, and all data pairs were divided into seven groups according to the cluster of station. In each iteration, six groups of data were used as training sets and the remaining one group of data was used for validation. The modeling and validation process were repeated seven times until the data of each group were validated. The total validation results of the models under the three weather conditions are shown in Fig. 9, with RMSE values ranging from 1.615 to 1.957 K. As expected, the error of the LLO CV increased relative to random sample validation. This is because the relationship between Ta and other features varies with geographical location. The prediction error of the northwest and southwest clusters was larger than that of other clusters. The RMSE values of these two clusters exceeded 2.5 K under cloudy-sky conditions case II, whereas the RMSE values of the other clusters were about 1.5 K. This is consistent with the analysis of the spatial distribution of model accuracy in Sect. 4.4 of the paper. The meteorological stations in northwestern and southwestern China are distributed discretely and at a distance from other stations in China, leading to a large difference between the training set and the test set and, ultimately, resulting in the relatively poor performance in the LLO CV strategy in these two regions. Furthermore, the LLO CV results of cloudy-sky model II were worse than those of the clear-sky model and cloudy-sky model I, indicating that LSTs help to reduce the spatial overfitting of the models.
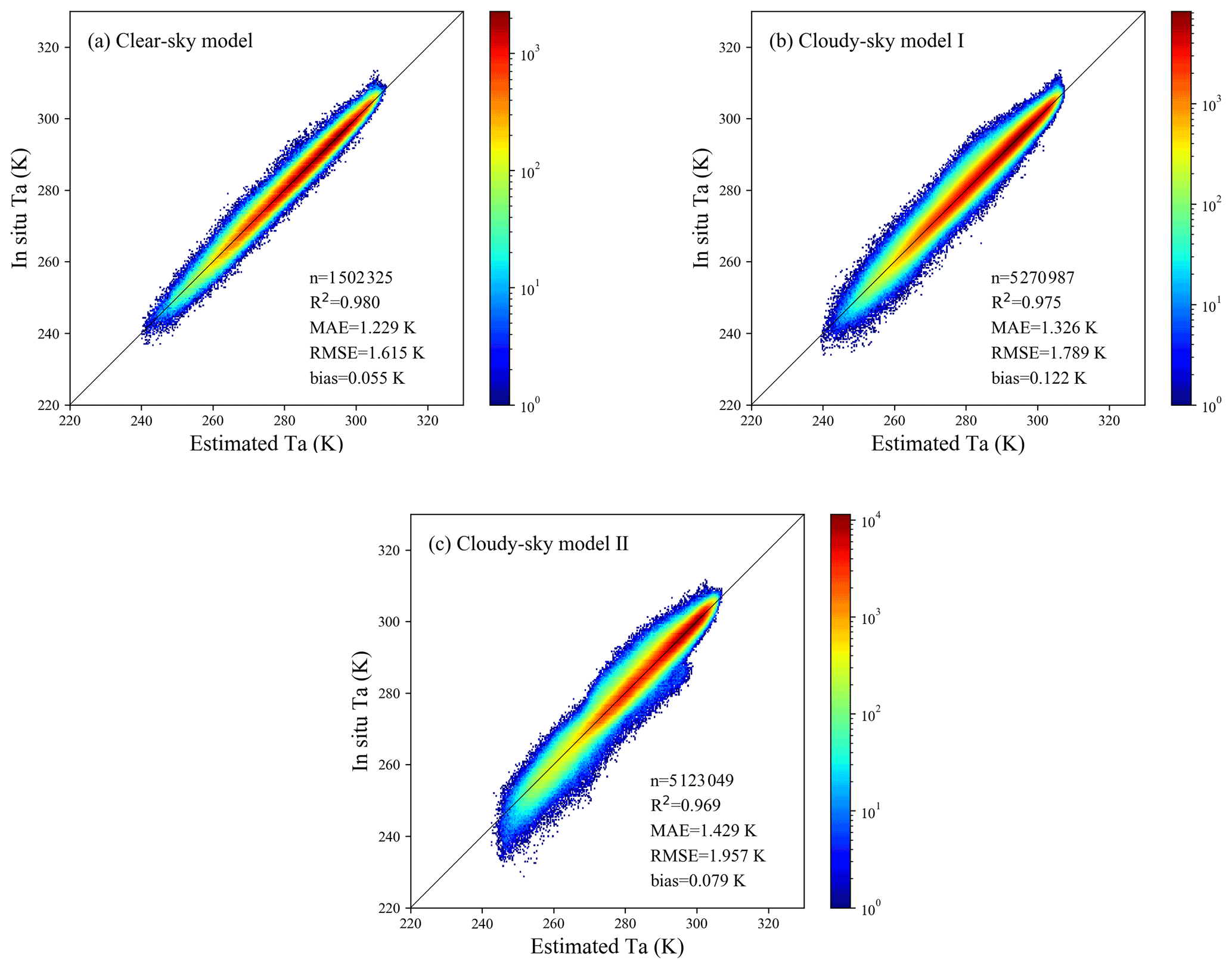
Figure 9Density scatterplots of the LLO CV results for three models.
4.3 Feature importance analysis
To quantitatively evaluate the contribution of each feature included in the RF models, the FI of every feature for the three models was calculated using the permutation method described in Sect. 3.4 and was then ranked. To reduce the impact of contingency on the experimental results, we repeated the experiment 30 times and took the average value of all experimental results as the final FI of each feature for each model. The FI results are shown in Fig. 10, with the importance decreasing from top to bottom. The gray line indicates the FI range of each feature for multiple repeated experiments. All features are divided into four types and represented by different colors, among which the blue rectangles represent MODIS LSTs, the orange rectangles represent GLDAS-assimilated Ta, the red rectangles represent radiation products including DSR and ALB, and the green rectangles represent other features.
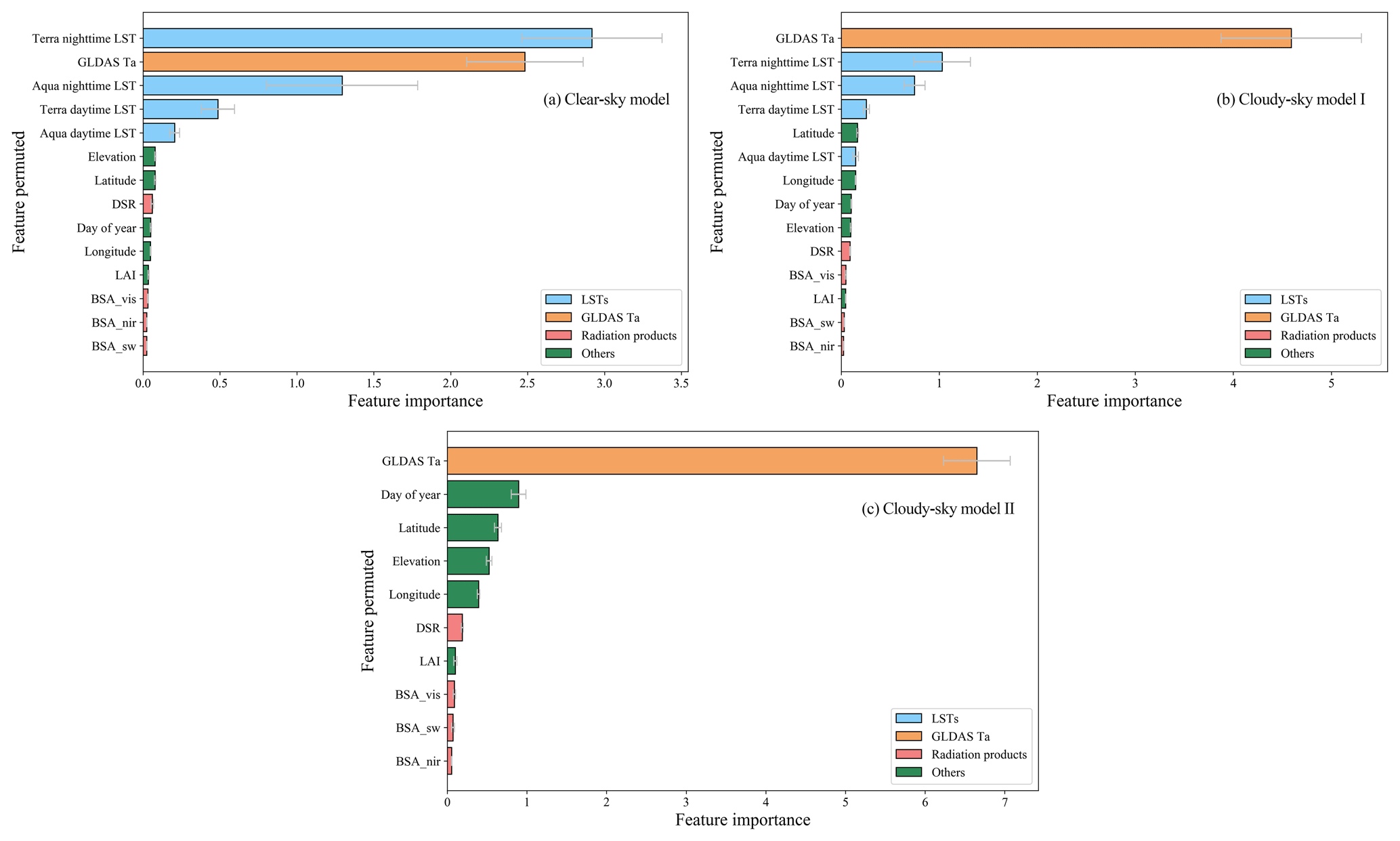
For clear-sky model, Terra nighttime LST was of the highest importance (FI of 2.92), followed by assimilated Ta (FI of 2.48), indicating that the prediction accuracy of the clear-sky model was significantly reduced after permuting these two features. They were followed by Aqua nighttime LST (FI of 1.3) and two daytime LSTs (FI of 0.49 and 0.21, respectively). For cloudy-sky model I, assimilated Ta ranked first (FI of 4.59), followed by Terra nighttime LST (FI of 1.03). For cloudy-sky model II, which did not include LST as features, assimilated Ta played a more importance role (FI of 6.65) than it did for cloudy-sky model I. The FI of radiation products and other features were all less than one for all the models, showing that they only slightly improved the model performance.
The energy exchange between the land surface and the near-surface atmosphere takes the form of longwave radiation, evapotranspiration, and turbulent exchange, or other phenomena. LST and land surface emissivity (LSE) determine the longwave radiation in land surface radiation and energy budgets (Liang and Wang, 2019). Thus, there is a strong and complicated physical correlation between LST and Ta. It can be seen from Fig. 8 that all four daily LSTs, especially nighttime LSTs, had relatively high FI values for both the clear-sky model and cloudy-sky model I. Among all the daily LSTs, nighttime LSTs outweighed daytime LSTs, and the Terra nighttime LST was of higher importance than the Aqua nighttime LST, which was consistent with the findings of many studies (Benali et al., 2012; Li and Zha, 2019; Zhang et al., 2011). In the study by Lin et al. (2012), the MAE between LST and Ta during the day and during the night were calculated separately, and they found that there was better agreement between LST and Ta during the night. In addition, due to the lack of solar radiation and its influence on the thermal infrared signal, remotely sensed nighttime LST products usually have higher stability (Benali et al., 2012; Vancutsem et al., 2010).
Assimilated Ta also mattered considerably for Ta estimation models. Its FI was second only to Terra nighttime LST for the clear-sky model and highest for cloudy-sky model I and cloudy-sky model II. For cloudy-sky model I, originally missed LSTs were replaced by clear-sky values from a nearby date, and the error introduced by this simple LST gap-filling strategy resulted in a decrease in the overall LST accuracy, thereby causing the FI of assimilated Ta to exceed that of LSTs. Compared with cloudy-sky model I, assimilated Ta was of higher importance, with a FI of 6.65 for cloudy-sky model II, indicating that it became the absolute dominant factor in Ta estimation when LST was not included in the Ta estimation model. Cloudy-sky model II also achieved satisfactory accuracy in the validation results. This demonstrates that although the spatial resolution of the assimilated Ta is relatively coarse, it can be a supplement or substitute for MODIS LSTs and provide an initial value or first guess for models to predict Ta with a higher resolution.
Radiation products and other features helped to improve the accuracy of Ta estimation models to a small extent. Among them, latitude, longitude, elevation, and day of year had relatively high importance in all three models. Latitude and longitude determine the relative position of the sun, which influences day length and, thus, the distribution of total solar radiation that the surface receives throughout the year; this, in turn, affects the patterns of Ta (Benali et al., 2012). Elevation affects how the ground is heated and how much radiation energy is absorbed by the atmosphere, resulting in vertical variations in Ta. In addition, the relationship between Ta and LST has great heterogeneity in different regions and at different times and is greatly affected by surface characteristics and atmospheric conditions. The day of year helps to explain the seasonal changes in atmospheric physical conditions, chemical composition, and surface characteristics to distinguish the different relationships between Ta and LST in different seasons and subsequently improve the accuracy of Ta estimation (Yao et al., 2020; Zhang et al., 2011). For LAI, DSR, and ALB, it is likely that other collinear features in the models made the information provided by them redundant, so their FI was relatively low in the Ta estimation models. However, in the analysis of the results of some stations, it was found that adding radiation features to the models helped improve the Ta estimation accuracy on some days. The radiation features can play a supplementary role in the case of some other features that do not perform well. Therefore, we finally decided to retain the radiation features in the Ta estimation models.
4.4 Spatial distribution of accuracy
The RMSE value was calculated for each meteorological station that recorded more than 20 d for all three weather conditions. To obtain a deeper understanding of the spatial distribution of model performance, the RMSE spatial distribution of stations for the three models was mapped, as shown in Fig. 11. It is evident that the model performance varied at different geographical locations for all three models. The clear-sky model presented the most stable results in different regions compared with cloudy-sky model I and cloudy-sky model II, with RMSE values of all stations ranging from 0.566 to 3.453 K. The RMSE range of cloudy-sky model I was 0.823–4.370 K and that of cloudy-sky model II was 0.809–4.198 K. The spatial patterns of cloudy-sky model I and cloudy-sky model II were generally similar, but there were more stations with good performance (RMSE < 1 K) and poor performance (RMSE > 3 K) for cloudy-sky model II, showing relatively poor stability.
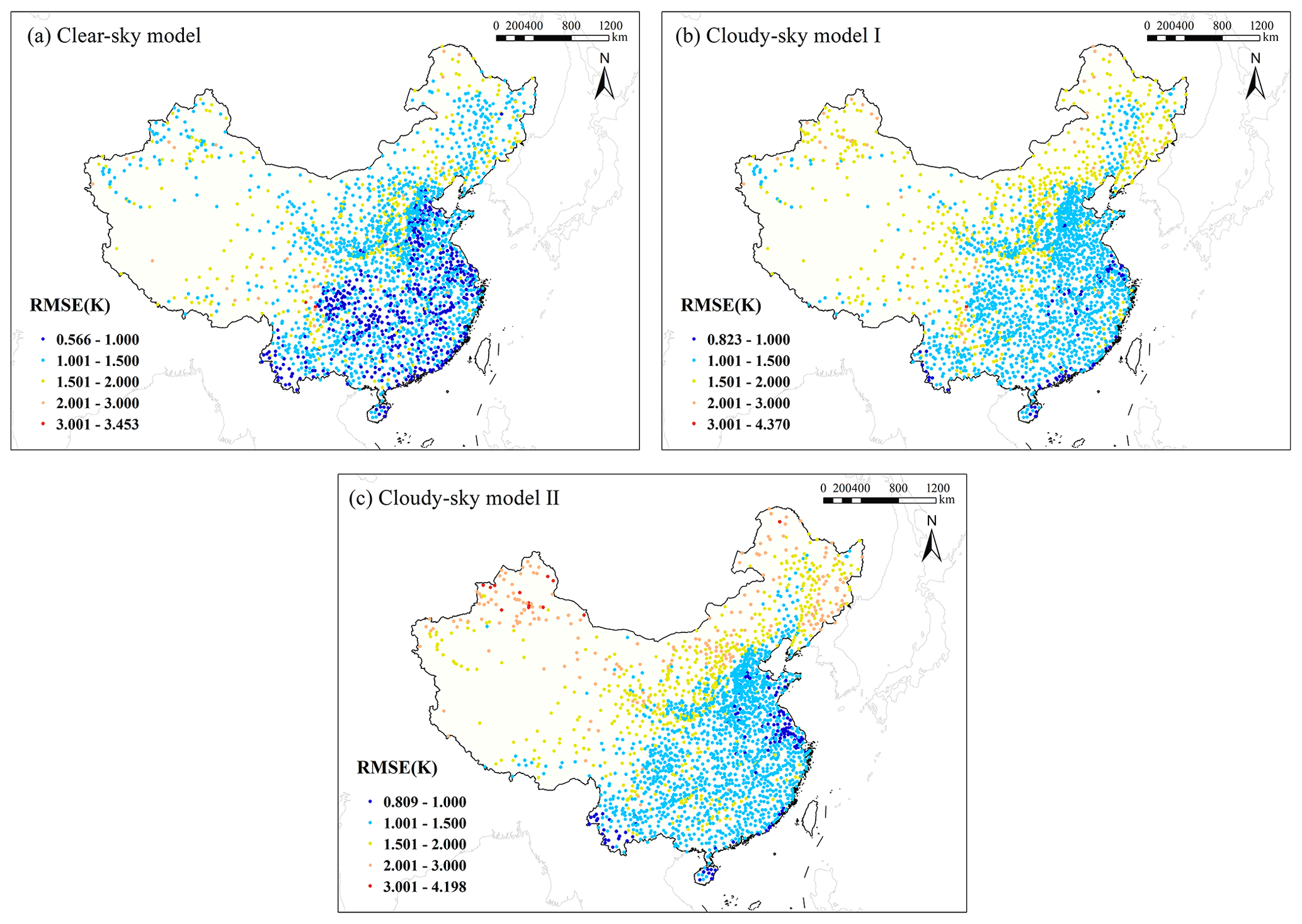
Figure 11RMSE spatial distribution of stations for three models.
Overall, the stations in central, eastern, and southern China presented high levels of accuracy for all three models, with RMSE values of most stations in these places of less than 1.5 K. Most stations with large RMSE values were located in southwest, northwest, and northern China, which was consistent with the results of Shen et al. (2020), and the RMSE values of cloudy-sky model II in these positions were larger than those of the clear-sky model and cloudy-sky model I. On the one hand, the spatial heterogeneity of model performance is largely due to the uneven distribution density of meteorological stations. As can be seen from the geographical locations of the meteorological stations used in this study (Fig. 1), it is obvious that stations in central, eastern, and southern China are densely distributed, whereas stations in northern and western China are relatively rare, which may contribute to the uneven distribution of model performance. Additionally, the terrain environment in central, eastern, and southern China is not complex, whereas high elevation and some climate types will increase the uncertainty of Ta estimation in northern and western China. The climate types of stations with poor performance were mostly temperate continental and plateau mountain climates, and the land cover types were mainly bare land and grassland. It can be seen from Table 4 that cloudy-sky model II showed relatively poor performance for these two land cover types. Therefore, there was an explicit uncertainty when only assimilated Ta and other features except LSTs were included to predict Ta in places with these climate and land cover types. Overall, although the spatial distribution of the model performance was relatively uneven, the Ta estimation models for different weather conditions all showed satisfactory performance.
4.5 Seasonal distribution of accuracy
The model performance at the monthly scale was also evaluated, and the RMSE monthly distribution for the three models is shown in Fig. 12. The RMSE range of the clear-sky model was 1.109–1.508 K, the cloudy-sky model I was 1.178–1.692 K, and the cloudy-sky model II was 1.056–1.777 K. It is obvious that there was temporal heterogeneity in the model performance, and the estimation accuracy presented similar seasonal variation patterns for all three models. The RMSE values were lower in summer and autumn, and higher in spring and winter, reaching a peak in February and reaching a bottom in July or August. We can conclude that models performed better on warm days, with RMSE values for all three models of below 1.22 K in July and August. This finding was consistent with the validation results at the monthly scale of Yao et al. (2020) and Li and Zha (2019). This phenomenon may be partly due to the fact that China is vast in territory with a latitudinal difference between the northernmost station and the southernmost stations of about 30∘; therefore, the range of Ta is wider on cold days than on hot days.
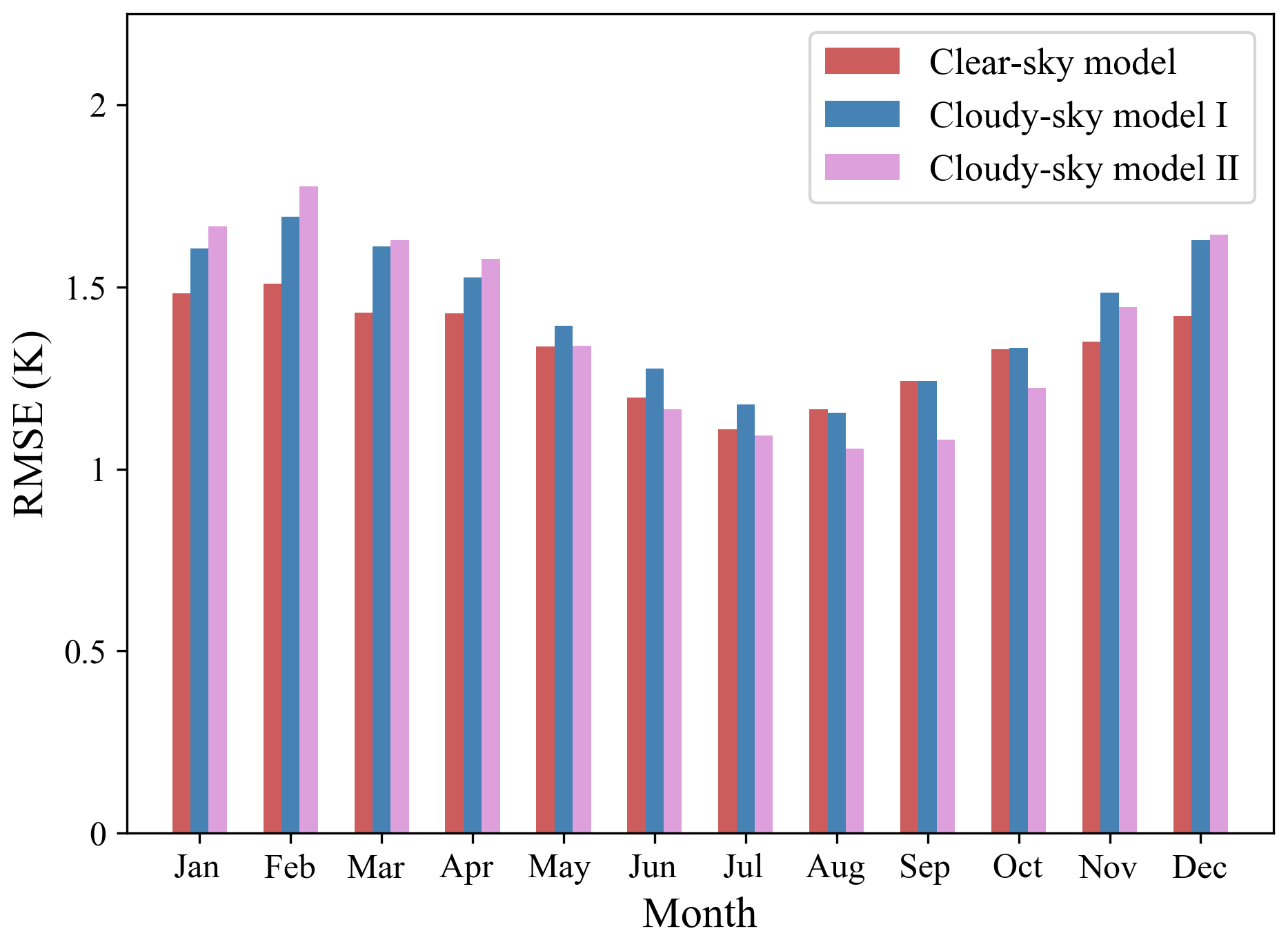
Monthly differences in model performance also indicated that the relationship between Ta and other factors varied seasonally and may have been more consistent in the same month. It was confirmed in the research of Yao et al. (2020) that modeling data of the same month together could achieve more accurate results. Therefore, although day of year was used in the modeling in this study, this temporal difference was not completely eliminated. Modeling the datasets of all seasons together in this study may increase the temporal heterogeneity of accuracy. It is worthwhile considering grouping the data of the same month to establish monthly models in the future, which may be conducive to further improving the accuracy of Ta estimation.
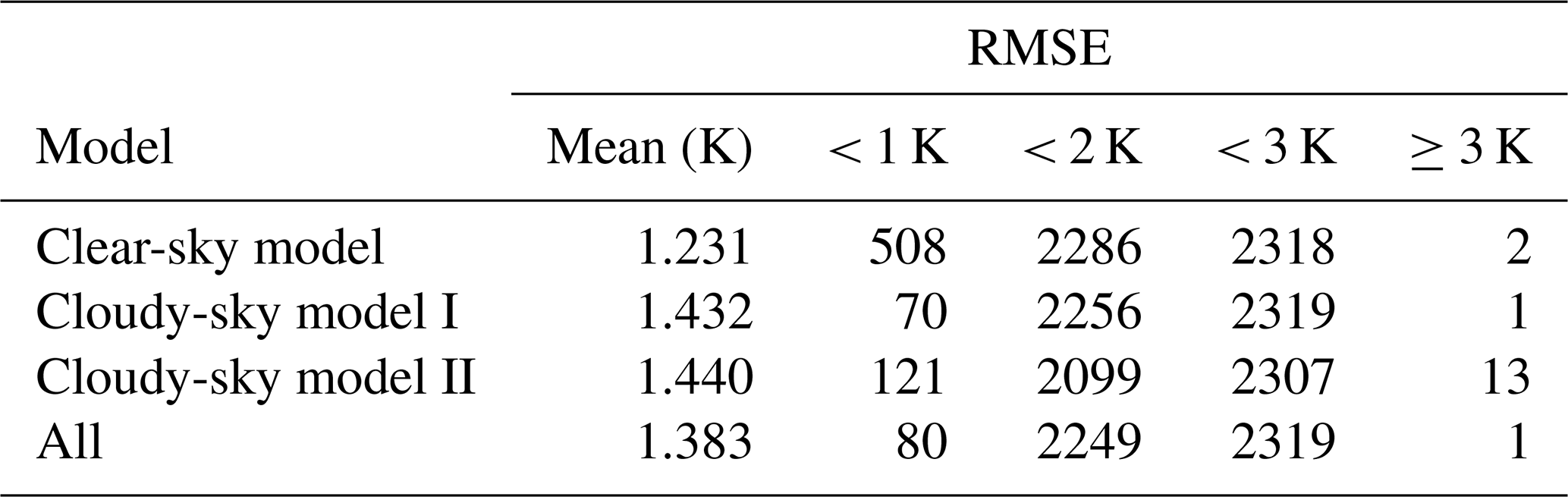
For a more comprehensive evaluation of the estimated daily mean Ta, we compared it with three reanalysis and meteorological forcing datasets, including CLDAS, CMFD, and GLDAS, in terms of validation statistics and spatiotemporal patterns. The station observations in 2010 were used to validate the accuracy of these four Ta datasets. It should be noted that we estimated daily mean Ta for the period ending at local midnight rather than 24:00 UTC. To ensure the time consistency, we calculated the average value of all simulations on a local day as the daily mean Ta for the reanalysis and meteorological forcing datasets. The statistical results and the density scatterplots are shown in Table 6 and Fig. 13, respectively. It can be seen that, compared with the reanalysis datasets, the RF Ta presented the highest consistency with the station observations, with the best performance in all accuracy assessment criteria (R2, MAE, RMSE, and bias values were 0.992, 0.680 K, 1.010 K, and 0.063 K, respectively). The points in the density scatterplot of the RF Ta were more concentrated near the 1:1 line. CLDAS Ta and CMFD Ta both showed almost zero bias with the station observations, but their RMSE values were both close to 2 K. GLDAS Ta reported slight underestimation (bias of 0.900 K). In general, this comparison confirmed the applicability of the RF method in Ta estimation and the higher accuracy of our estimated Ta compared with the reanalysis products.
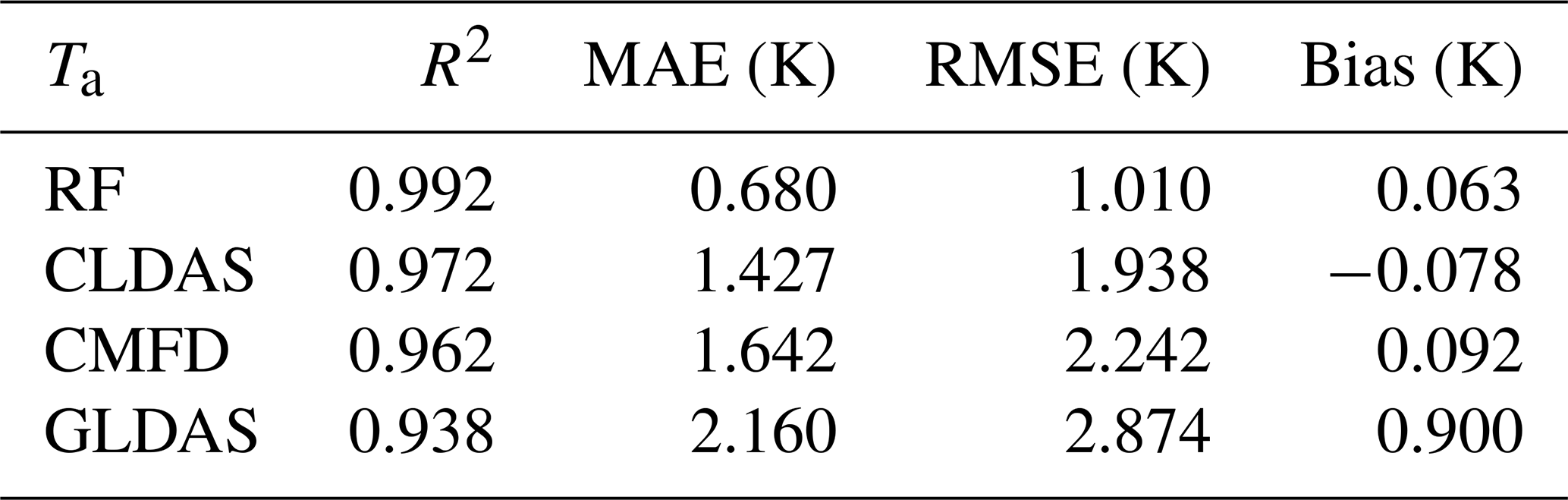
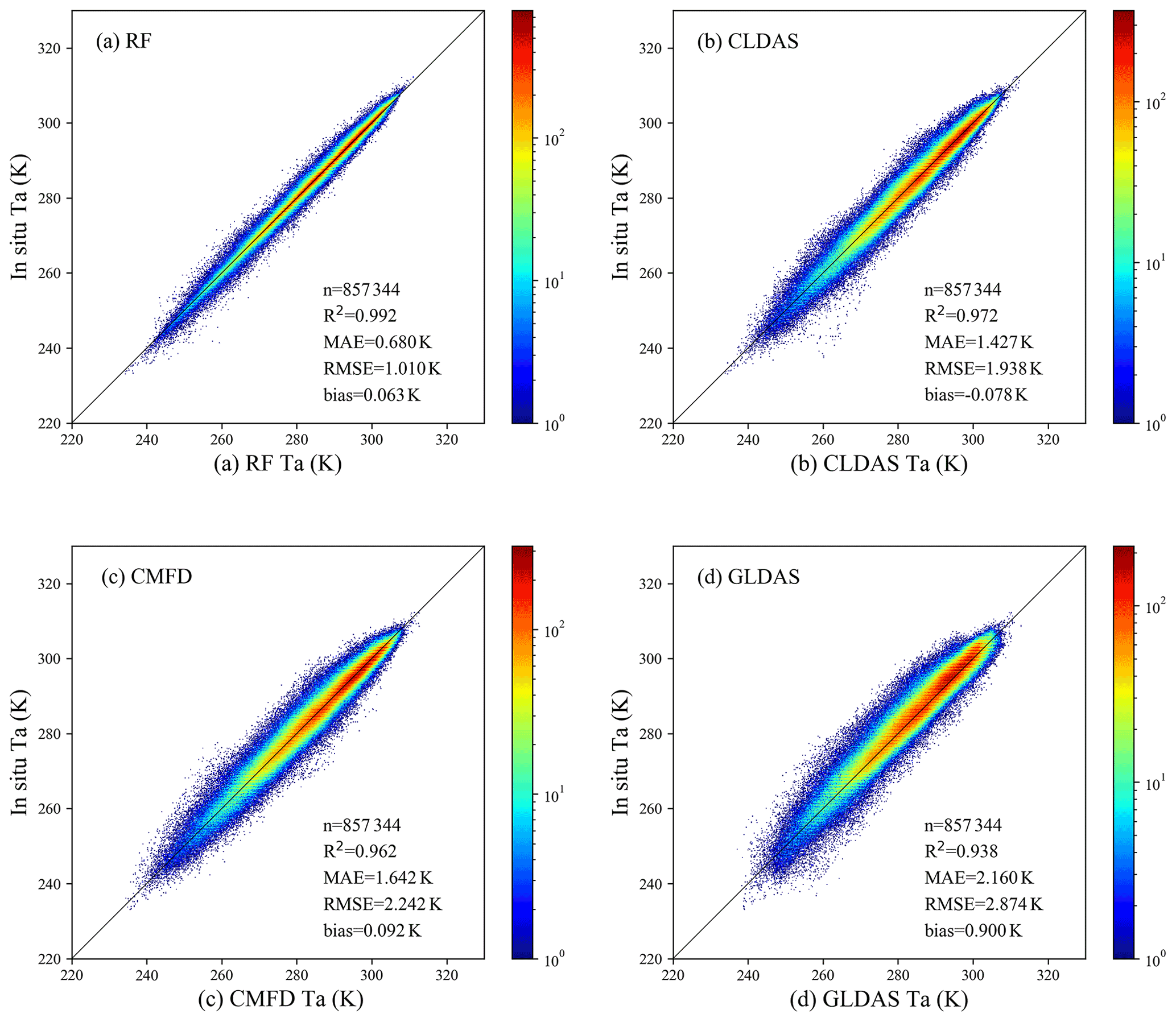
Figure 13Density scatterplots of the estimated Ta and reanalysis Ta against the in situ Ta in 2010.
In addition, the spatiotemporal patterns of these four Ta datasets were compared. We calculated the monthly mean Ta in 2010 for all datasets. The RF monthly mean land Ta mappings over mainland China in February, May, August, and November 2010 are shown in Fig. 14a–d. The CLDAS (Fig. 14e–h), CMFD (Fig. 14i–l), and GLDAS (Fig. 14m–p) monthly mean Ta mappings in the same months are also shown in Fig. 12. The spatial resolutions of RF, CLDAS, CMFD, and GLDAS monthly mean Ta are approximately 0.01∘ × 0.01∘, 0.0625∘ × 0.0625∘, 0.1∘ × 0.1∘, and 0.25∘ × 0.25∘, respectively. We used GLDAS-assimilated Ta and GLASS LAI in Ta estimation, which have no value in most water bodies; thus, the Ta of these areas was also not estimated.
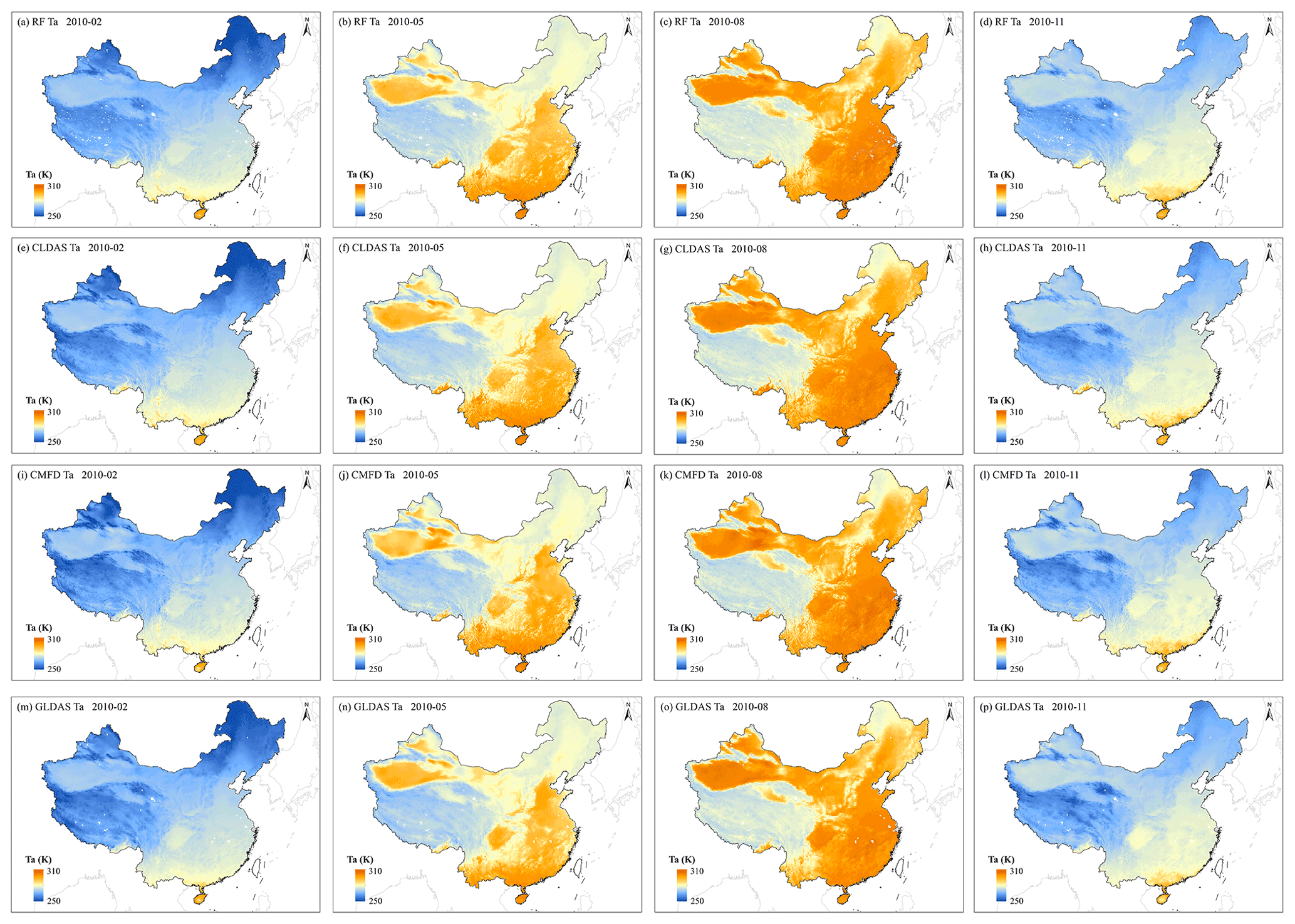
Figure 14Maps of monthly mean Ta over mainland China. Panels (a)–(d) show the the RF Ta, panels (e)–(h) show the CLDAS Ta, panels (i)–(l) show the CMFD Ta, and panels (m)–(p) show the GLDAS Ta in February, May, August, and November 2010, respectively. The white pixels in mainland China indicate no data value and are always water bodies.
As can be seen from Fig. 14, it is clear that these four datasets basically showed a high degree of consistency in the spatiotemporal patterns over mainland China. China has a vast territory, and its topography is high in the west and low in the east. The spatial patterns of Ta over mainland China present great seasonal heterogeneity. In winter, the sun shines directly in the Southern Hemisphere, and the Northern Hemisphere consequentially receives less solar energy. The Ta in northern China and the Tibetan Plateau are generally low, and the Ta difference between the north and the south exceeds 50 K. On the contrary, in summer, as the sun shines directly in the Northern Hemisphere, Ta in most parts of China are generally high except for the Tibetan Plateau, with little Ta difference between the north and the south. As an expectable consequence of higher spatial resolution, the RF Ta mappings were capable of providing more detail on the Ta spatial patterns than the reanalysis and meteorological forcing Ta, especially in mountainous areas with complicated terrain. GLDAS Ta presented an obvious pixel effect because of the relatively coarse spatial resolution. In summary, the all-sky daily mean land Ta product developed in this study has achieved satisfactory accuracy and high spatial resolution simultaneously, which can reveal the seasonal variation trend and the spatial patterns of Ta over China well. This product can provide a long time series of daily mean Ta with the spatial resolution of 1 km over mainland China, which fills the current dataset gap in this field. Moreover, this product is also conducive to observing and analyzing the climate characteristic of China and plays an important role in the studies of climate change and the hydrological cycle.
The daily mean land Ta product over mainland China is currently freely available at https://doi.org/10.5281/zenodo.4399453 for the period from 2003 to 2008 (Chen et al., 2021b) and at the University of Maryland (http://glass.umd.edu/Ta_China/, last access: 24 August 2021) for the period from 2003 to 2019. In order to make this big dataset easier to understand and use, we created a provincial sub-dataset with a smaller geographic coverage. An all-sky 0.01∘ daily Ta product over Beijing (2003–2019) was generated from the developed dataset over mainland China after resampling and clipping, and it is publicly available at https://doi.org/10.5281/zenodo.4405123 (Chen et al., 2021a).
The MODIS product and the GLDAS dataset were downloaded from https://earthdata.nasa.gov/ (last access: 24 August 2021). The GLASS products were downloaded from http://www.glass.umd.edu (last access: 24 August 2021). The CLDAS and CMFD datasets were downloaded from http://tipex.data.cma.cn (last access: 24 August 2021) and http://data.tpdc.ac.cn/ (last access: 24 August 2021), respectively.
Ta is a key variable in climate and global change research. In this study, we developed an all-sky 1 km daily mean land Ta product for 2003–2019 over mainland China mainly based on MODIS and GLDAS data using the RF method. An efficient temporal gap-filling method was first used to fill MODIS LST gaps under cloudy-sky conditions. We predicted Ta under three different weather conditions separately: clear-sky conditions (when the daily LSTs are all clear-sky), cloudy-sky conditions case I (when the daily LST gap(s) can be filled), and cloudy-sky conditions case II (when the daily LST gap(s) cannot all be filled). The validation results using station measurements (one-fifth of the total data from 2003 to 2016 selected randomly), which were not used for model training, showed that the R2 values were 0.986, 0.984, and 0.984 and the RMSE values were 1.342, 1.440, and 1.396 K for the clear-sky model, cloudy-sky model I, and cloudy-sky model II, respectively. In general, the models showed excellent performance at most stations, with a mean RMSE of 1.383 K, and there were 97 % stations with RMSE values less than 2 K and only 1 of 2320 stations with an RMSE value greater than 3 K. In addition, we examined the spatiotemporal patterns and land cover type dependences of model accuracy and concluded that model performance under all conditions was acceptable overall, despite some heterogeneity under different conditions. The relative contributions of different features to models were also quantitatively analyzed, and it was found that LST and assimilated Ta were of great significance in Ta estimation. Finally, we compared the Ta dataset in 2010 with the CLDAS, CMFD, and GLDAS datasets, finding great consistency in the spatiotemporal patterns. The estimated Ta in 2010 reported significantly higher accuracy against the station observations, with R2, RMSE, and bias values of 0.992, 1.010 K, and 0.063 K, respectively.
Overall, this study developed a robust scheme that used a machine learning method to estimate all-sky daily mean Ta over a large spatial and temporal range. This approach can be applied globally. The generated all-sky Ta product has achieved a high degree of accuracy compared with the existing datasets, which fills the current dataset gap in this field and plays an important role in many scientific fields such as climate change, the hydrological cycle, and the energy balance. Future work should focus on developing better LST gap-filling methods and experimenting with more advanced deep learning methods that take the spatial and temporal dependence of Ta into account.
SL and YC contributed to the design of this study and developed the overall methodology. HM, BL, and YC collected and preprocessed the data. YC carried out the experiments. YC, BL, TH, and QW produced the product. YC wrote the first draft of the paper. All authors revised the paper.
The authors declare that they have no conflict of interest.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
We gratefully acknowledge data support from the “National Earth System Science Data Center, National Science & Technology Infrastructure of China” (http://www.geodata.cn, last access: 24 August 2021). We thank the GLASS team for providing the data used in this study, which can be downloaded from https://www.glass.umd.edu (last access: 24 August 2021). We are grateful to the National Aeronautics and Space Administration team for providing the MODIS product and GLDAS data, which can be freely download from https://earthdata.nasa.gov/ (last access: 24 August 2021). We also thank the CLDAS and CMFD teams for providing the respective CLDAS and CMFD datasets, which can be freely download from http://tipex.data.cma.cn (last access: 24 August 2021) and http://data.tpdc.ac.cn/ (last access: 24 August 2021), respectively. Additionally, the authors would like to acknowledge the Chinese Meteorological Administration for providing in situ measurements. We are also very grateful to the reviewers for their valuable comments and suggestions.
This study was partially supported by the Chinese Grand Research Program on Climate Change and Response under project no 2016YFA0600103.
This paper was edited by David Carlson and reviewed by two anonymous referees.
Benali, A., Carvalho, A. C., Nunes, J. P., Carvalhais, N., and Santos, A.: Estimating air surface temperature in Portugal using MODIS LST data, Remote Sens. Environ., 124, 108–121, https://doi.org/10.1016/j.rse.2012.04.024, 2012.
Benavides, R., Montes, F., Rubio, A., and Osoro, K.: Geostatistical modelling of air temperature in a mountainous region of Northern Spain, Agr. Forest Meteorol., 146, 173–188, https://doi.org/10.1016/j.agrformet.2007.05.014, 2007.
Bisht, G. and Bras, R. L.: Estimation of net radiation from the MODIS data under all sky conditions: Southern Great Plains case study, Remote Sens. Environ., 114, 1522–1534, https://doi.org/10.1016/j.rse.2010.02.007, 2010.
Borbas, E. and Menzel, P.: MODIS Atmosphere L2 Atmosphere Profile Product, NASA MODIS Adaptive Processing System, Goddard Space Flight Center [data set], USA, https://doi.org/10.5067/MODIS/MOD07_L2.006, 2017.
Breiman, L.: Bagging predictors, Mach. Learn., 24, 123–140, 1996.
Breiman, L.: Random forests, Mach. Learn., 45, 5–32, 2001.
Breiman, L., Friedman, J. H., Olshen, R. A., and Stone, C. J.: Classification and Regression Trees, Wadsworth International Group, Belmont, California, USA, 1984.
Chen, F., Liu, Y., Liu, Q., and Qin, F.: A statistical method based on remote sensing for the estimation of air temperature in China, Int. J. Climatol., 35, 2131-2143, https://doi.org/10.1002/joc.4113, 2015.
Chen, Y., Liang, S., Ma, H., Li, B., He, T., and Wang, Q.: An All-sky 0.01∘ Daily Surface Air Temperature Product over Beijing (2003–2019), Zenodo [data set], https://doi.org/10.5281/zenodo.4405123, 2021a.
Chen, Y., Liang, S., Ma, H., Li, B., He, T., and Wang, Q.: An All-sky 1 km Daily Surface Air Temperature Product over Mainland China, Zenodo [data set], https://doi.org/10.5281/zenodo.4399453, 2021b.
Emamifar, S., Rahimikhoob, A., and Noroozi, A. A.: Daily mean air temperature estimation from MODIS land surface temperature products based on M5 model tree, Int. J. Climatol., 33, 3174–3181, https://doi.org/10.1002/joc.3655, 2013.
Famiglietti, C. A., Fisher, J. B., Halverson, G., and Borbas, E. E.: Global validation of MODIS near-surface air and dew point temperatures, Geophys. Res. Lett., 45, 7772–7780, https://doi.org/10.1029/2018GL077813, 2018.
Gelaro, R., McCarty, W., Suarez, M. J., Todling, R., Molod, A., Takacs, L., Randles, C. A., Darmenov, A., Bosilovich, M. G., Reichle, R., Wargan, K., Coy, L., Cullather, R., Draper, C., Akella, S., Buchard, V., Conaty, A., da Silva, A. M., Gu, W., Kim, G. K., Koster, R., Lucchesi, R., Merkova, D., Nielsen, J. E., Partyka, G., Pawson, S., Putman, W., Rienecker, M., Schubert, S. D., Sienkiewicz, M., and Zhao, B.: The Modern-Era Retrospective Analysis for Research and Applications, Version 2 (MERRA-2), J. Climate, 30, 5419–5454, https://doi.org/10.1175/jcli-d-16-0758.1, 2017.
Gislason, P. O., Benediktsson, J. A., and Sveinsson, J. R.: Random Forests for land cover classification, Pattern Recogn. Lett., 27, 294–300, https://doi.org/10.1016/j.patrec.2005.08.011, 2006.
Goetz, S. J., Prince, S. D., and Small, J.: Advances in satellite remote sensing of environmental variables for epidemiological applications, Adv. Parasit., 47, 289–307, https://doi.org/10.1016/S0065-308X(00)47012-0, 2000.
Gong, P., Wang, J., Yu, L., Zhao, Y., Zhao, Y., Liang, L., Niu, Z., Huang, X., Fu, H., and Liu, S.: Finer resolution observation and monitoring of global land cover: First mapping results with Landsat TM and ETM+ data, Int. J. Remote Sens., 34, 2607–2654, https://doi.org/10.1080/01431161.2012.748992, 2013.
Good, E. J., Ghent, D. J., Bulgin, C. E., and Remedios, J. J.: A spatiotemporal analysis of the relationship between near-surface air temperature and satellite land surface temperatures using 17 years of data from the ATSR series, J. Geophys. Res.-Atmos., 122, 9185–9210, https://doi.org/10.1002/2017jd026880, 2017.
Guan, H., Zhang, X., Makhnin, O., and Sun, Z.: Mapping Mean Monthly Temperatures over a Coastal Hilly Area Incorporating Terrain Aspect Effects, J. Hydrometeorol., 14, 233–250, https://doi.org/10.1175/jhm-d-12-014.1, 2013.
Ham, J., Yangchi, C., Crawford, M. M., and Ghosh, J.: Investigation of the random forest framework for classification of hyperspectral data, IEEE T. Geosci. Remote, 43, 492–501, https://doi.org/10.1109/tgrs.2004.842481, 2005.
Ishida, T. and Kawashima, S.: Use of cokriging to estimate surface air-temperature from elevation, Theor. Appl. Climatol., 47, 147–157, https://doi.org/10.1007/bf00867447, 1993.
Jang, J. D., Viau, A. A., and Anctil, F.: Neural network estimation of air temperatures from AVHRR data, Int. J. Remote Sens., 25, 4541–4554, https://doi.org/10.1080/01431160310001657533, 2010.
Jang, K., Kang, S., Kimball, J., and Hong, S.: Retrievals of All-Weather Daily Air Temperature Using MODIS and AMSR-E Data, Remote Sens., 6, 8387–8404, https://doi.org/10.3390/rs6098387, 2014.
Khesali, E. and Mobasheri, M.: A method in near-surface estimation of air temperature (NEAT) in times following the satellite passing time using MODIS images, Adv. Space Res., 65, 2339–2347, https://doi.org/10.1016/j.asr.2020.02.006, 2020.
Kilibarda, M., Hengl, T., Heuvelink, G. B. M., Gräler, B., Pebesma, E., Perčec Tadić, M., and Bajat, B.: Spatio-temporal interpolation of daily temperatures for global land areas at 1 km resolution, J. Geophys. Res.-Atmos., 119, 2294–2313, https://doi.org/10.1002/2013jd020803, 2014.
Kurtzman, D. and Kadmon, R.: Mapping of temperature variables in Israel: a comparison of different interpolation methods, Clim. Res., 13, 33–43, https://doi.org/10.3354/cr013033, 1999.
Li, L. and Zha, Y.: Estimating monthly average temperature by remote sensing in China, Adv. Space Res., 63, 2345–2357, https://doi.org/10.1016/j.asr.2018.12.039, 2019.
Li, X., Zhou, Y., Asrar, G. R., and Zhu, Z.: Developing a 1 km resolution daily air temperature dataset for urban and surrounding areas in the conterminous United States, Remote Sens. Environ., 215, 74–84, https://doi.org/10.1016/j.rse.2018.05.034, 2018.
Liang, S.: Quantitative remote sensing of land surfaces, John Wiley & Sons, Inc., Hoboken, NJ, USA, 2004.
Liang, S., Zhao, X., Liu, S., Yuan, W., Cheng, X., Xiao, Z., Zhang, X., Liu, Q., Cheng, J., Tang, H., Qu, Y., Bo, Y., Qu, Y., Ren, H., Yu, K., and Townshend, J.: A long-term Global LAnd Surface Satellite (GLASS) data-set for environmental studies, Int. J. Digit. Earth, 6, 5–33, https://doi.org/10.1080/17538947.2013.805262, 2013.
Liang, S., Wang, D., He, T., and Yu, Y.: Remote sensing of earth's energy budget: synthesis and review, Int. J. Digit. Earth, 12, 737–780, https://doi.org/10.1080/17538947.2019.1597189, 2019.
Liang, S. and Wang, J.: Advanced remote sensing: terrestrial information extraction and applications, 2nd Edn., Academic Press, 2019.
Liang, S., Cheng, J., Jia, K., Jiang, B., Liu, Q., Xiao, Z., Yao, Y., Yuan, W., Zhang, X., and Zhao, X.: The Global LAnd Surface Satellite (GLASS) product suite, B. Am. Meteorol. Soc., 102, E323–E337, https://doi.org/10.1175/BAMS-D-18-0341.1, 2021.
Lin, S., Moore, N. J., Messina, J. P., DeVisser, M. H., and Wu, J.: Evaluation of estimating daily maximum and minimum air temperature with MODIS data in east Africa, Int. J. Appl. Earth Obs., 18, 128–140, https://doi.org/10.1016/j.jag.2012.01.004, 2012.
Liu, Q., Wang, L., Qu, Y., Liu, N., Liu, S., Tang, H., and Liang, S.: Preliminary evaluation of the long-term GLASS albedo product, Int. J. Digit. Earth, 6, 69–95, https://doi.org/10.1175/BAMS-D-18-0341.1, 2013.
Liu, R., Ma, Z., Liu, Y., Shao, Y., Zhao, W., and Bi, J.: Spatiotemporal distributions of surface ozone levels in China from 2005 to 2017: A machine learning approach, Environ. Int., 142, 105823, https://doi.org/10.1016/j.envint.2020.105823, 2020.
Ma, J., Zhou, J., Göttsche, F.-M., Liang, S., Wang, S., and Li, M.: A global long-term (1981–2000) land surface temperature product for NOAA AVHRR, Earth Syst. Sci. Data, 12, 3247–3268, https://doi.org/10.5194/essd-12-3247-2020, 2020.
Marzban, F., Sodoudi, S., and Preusker, R.: The influence of land-cover type on the relationship between NDVI–LST and LST-Tair, Int. J. Remote Sens., 39, 1377–1398, https://doi.org/10.1080/01431161.2017.1402386, 2017.
McGovern, A., Lagerquist, R., Gagne, D. J., Jergensen, G. E., Elmore, K. L., Homeyer, C. R., and Smith, T.: Making the black box more transparent: Understanding the physical implications of machine learning, B. Am. Meteorol. Soc., 100, 2175–2199, 2019.
Meyer, H., Katurji, M., Appelhans, T., Müller, M., Nauss, T., Roudier, P., and Zawar-Reza, P.: Mapping Daily Air Temperature for Antarctica Based on MODIS LST, Remote Sens., 8, 732, https://doi.org/10.3390/rs8090732, 2016.
Noi, P., Degener, J., and Kappas, M.: Comparison of Multiple Linear Regression, Cubist Regression, and Random Forest Algorithms to Estimate Daily Air Surface Temperature from Dynamic Combinations of MODIS LST Data, Remote Sens., 9, 398, https://doi.org/10.3390/rs9050398, 2017.
Ploton, P., Mortier, F., Rejou-Mechain, M., Barbier, N., Picard, N., Rossi, V., Dormann, C., Cornu, G., Viennois, G., Bayol, N., Lyapustin, A., Gourlet-Fleury, S., and Pelissier, R.: Spatial validation reveals poor predictive performance of large-scale ecological mapping models, Nat. Commun., 11, 4540, https://doi.org/10.1038/s41467-020-18321-y, 2020.
Prihodko, L. and Goward, S. N.: Estimation of air temperature from remotely sensed surface observations, Remote Sens. Environ., 60, 335–346, https://doi.org/10.1016/S0034-4257(96)00216-7, 1997.
Quinlan, J. R.: Induction of decision trees, Mach. Learn., 1, 81–106, 1986.
Quinlan, J. R.: C4.5 : programs for machine learning, Morgan Kaufmann Publishers Inc., 1992.
Rao, Y., Liang, S., and Yu, Y.: Land Surface Air Temperature Data Are Considerably Different Among BEST-LAND, CRU-TEM4v, NASA-GISS, and NOAA-NCEI, J. Geophys. Res.-Atmos., 123, 5881–5900, https://doi.org/10.1029/2018jd028355, 2018.
Rao, Y., Liang, S., Wang, D., Yu, Y., Song, Z., Zhou, Y., Shen, M., and Xu, B.: Estimating daily average surface air temperature using satellite land surface temperature and top-of-atmosphere radiation products over the Tibetan Plateau, Remote Sens. Environ., 234, 111462, https://doi.org/10.1016/j.rse.2019.111462, 2019.
Rodell, M., Houser, P. R., Jambor, U., Gottschalck, J., Mitchell, K., Meng, C. J., Arsenault, K., Cosgrove, B., Radakovich, J., Bosilovich, M., Entin, J. K., Walker, J. P., Lohmann, D., and Toll, D.: The Global Land Data Assimilation System, B. Am. Meteorol. Soc., 85, 381–394, https://doi.org/10.1175/bams-85-3-381, 2004.
Rosenfeld, A., Dorman, M., Schwartz, J., Novack, V., Just, A. C., and Kloog, I.: Estimating daily minimum, maximum, and mean near surface air temperature using hybrid satellite models across Israel, Environ. Res., 159, 297–312, https://doi.org/10.1016/j.envres.2017.08.017, 2017.
Schwingshackl, C., Hirschi, M., and Seneviratne, S. I.: Global Contributions of Incoming Radiation and Land Surface Conditions to Maximum Near-Surface Air Temperature Variability and Trend, Geophys. Res. Lett., 45, 5034–5044, https://doi.org/10.1029/2018GL077794, 2018.
Shen, H., Jiang, Y., Li, T., Cheng, Q., Zeng, C., and Zhang, L.: Deep learning-based air temperature mapping by fusing remote sensing, station, simulation and socioeconomic data, Remote Sens. Environ., 240, 111692, https://doi.org/10.1016/j.rse.2020.111692, 2020.
Shi, C., Xie, Z., Qian, H., Liang, M., and Yang, X.: China land soil moisture EnKF data assimilation based on satellite remote sensing data, Sci. China Earth Sci., 54, 1430–1440, https://doi.org/10.1007/s11430-010-4160-3, 2011.
Stisen, S., Sandholt, I., Nørgaard, A., Fensholt, R., and Eklundh, L.: Estimation of diurnal air temperature using MSG SEVIRI data in West Africa, Remote Sens. Environ., 110, 262–274, https://doi.org/10.1016/j.rse.2007.02.025, 2007.
Sun, Y. J., Wang, J. F., Zhang, R. H., Gillies, R. R., Xue, Y., and Bo, Y. C.: Air temperature retrieval from remote sensing data based on thermodynamics, Theor. Appl. Climatol., 80, 37–48, https://doi.org/10.1007/s00704-004-0079-y, 2004.
Vancutsem, C., Ceccato, P., Dinku, T., and Connor, S. J.: Evaluation of MODIS land surface temperature data to estimate air temperature in different ecosystems over Africa, Remote Sens. Environ., 114, 449–465, https://doi.org/10.1016/j.rse.2009.10.002, 2010.
Vogt, J. V., Viau, A. A., and Paquet, F.: Mapping regional air temperature fields using satellite-derived surface skin temperatures, Int. J. Climatol., 17, 1559–1579, 1997.
Wan, Z., Hook, S., and Hulley, G.: MOD11A1 MODIS/Terra Land Surface Temperature/Emissivity Daily L3 Global 1km SIN Grid, NASA LP DAAC [data set], https://doi.org/10.5067/MODIS/MOD11A1.006, 2015.
Xiao, Q., Chang, H. H., Geng, G., and Liu, Y.: An Ensemble Machine-Learning Model To Predict Historical PM2.5 Concentrations in China from Satellite Data, Environ. Sci. Technol., 52, 13260–13269, https://doi.org/10.1021/acs.est.8b02917, 2018.
Xiao, Z., Liang, S., Wang, J., Chen, P., Yin, X., Zhang, L., and Song, J.: Use of General Regression Neural Networks for Generating the GLASS Leaf Area Index Product From Time-Series MODIS Surface Reflectance, IEEE T. Geosci. Remote, 52, 209–223, https://doi.org/10.1109/tgrs.2013.2237780, 2014.
Xu, Y., Knudby, A., and Ho, H. C.: Estimating daily maximum air temperature from MODIS in British Columbia, Canada, Int. J. Remote Sens., 35, 8108–8121, https://doi.org/10.1080/01431161.2014.978957, 2014.
Yang, K. and He, J.: China meteorological forcing dataset (1979–2018), National Tibetan Plateau Data Center [data set], https://doi.org/10.11888/AtmosphericPhysics.tpe.249369.file, 2019.
Yao, R., Wang, L., Huang, X., Li, L., Sun, J., Wu, X., and Jiang, W.: Developing a temporally accurate air temperature dataset for Mainland China, Sci. Total Environ., 706, 136037, https://doi.org/10.1016/j.scitotenv.2019.136037, 2020.
Zeng, L., Wardlow, B., Tadesse, T., Shan, J., Hayes, M., Li, D., and Xiang, D.: Estimation of Daily Air Temperature Based on MODIS Land Surface Temperature Products over the Corn Belt in the US, Remote Sens., 7, 951–970, https://doi.org/10.3390/rs70100951, 2015.
Zhang, H., Zhang, F., Ye, M., Che, T., and Zhang, G.: Estimating daily air temperatures over the Tibetan Plateau by dynamically integrating MODIS LST data, J. Geophys. Res.-Atmos., 121, 11425–11441, https://doi.org/10.1002/2016jd025154, 2016.
Zhang, H.: Estimation of daily average near-surface air temperature using MODIS and AIRS data, 2017 2nd International Conference on Frontiers of Sensors Technologies (ICFST), 377-381, 2017.
Zhang, H., Zhang, F. A. N., Zhang, G., Ma, Y., Yang, K. U. N., and Ye, M.: Daily air temperature estimation on glacier surfaces in the Tibetan Plateau using MODIS LST data, J. Glaciol., 64, 132–147, https://doi.org/10.1017/jog.2018.6, 2018.
Zhang, W., Huang, Y., Yu, Y., and Sun, W.: Empirical models for estimating daily maximum, minimum and mean air temperatures with MODIS land surface temperatures, Int. J. Remote Sens., 32, 9415–9440, https://doi.org/10.1080/01431161.2011.560622, 2011.
Zhang, X., Wang, D., Liu, Q., Yao, Y., Jia, K., He, T., Jiang, B., Wei, Y., Ma, H., and Zhao, X.: An operational approach for generating the global land surface downward shortwave radiation product from MODIS data, IEEE T. Geosci. Remote, 57, 4636–4650, https://doi.org/10.1109/TGRS.2019.2891945, 2019.
Zhu, W., Lű, A., and Jia, S.: Estimation of daily maximum and minimum air temperature using MODIS land surface temperature products, Remote Sens. Environ., 130, 62–73, https://doi.org/10.1016/j.rse.2012.10.034, 2013.
Zhu, W., Lű, A., Jia, S., Yan, J., and Mahmood, R.: Retrievals of all-weather daytime air temperature from MODIS products, Remote Sens. Environ., 189, 152–163, https://doi.org/10.1016/j.rse.2016.11.011, 2017.