the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 13 Dec 2019
| 13 Dec 2019
Reference crop evapotranspiration database in Spain (1961–2014)
Miquel Tomas-Burguera
Sergio M. Vicente-Serrano
Santiago Beguería
Fergus Reig
Borja Latorre
Obtaining climate grids describing distinct variables is important for developing better climate studies. These grids are also useful products for other researchers and end users. The atmospheric evaporative demand (AED) may be measured in terms of the reference evapotranspiration (ETo), a key variable for understanding water and energy terrestrial balances and an important variable in climatology, hydrology and agronomy. Despite its importance, the calculation of ETo is not commonly undertaken, mainly because datasets consisting of a high number of climate variables are required and some of the required variables are not commonly available.
To address this problem, a strategy based on the spatial interpolation of climate variables prior to the calculation of ETo using FAO-56 Penman–Monteith equation was followed to obtain an ETo database for continental Spain and the Balearic Islands, covering the 1961–2014 period at a spatial resolution of 1.1 km and at a weekly temporal resolution. In this database, values for the radiative and aerodynamic components as well as the estimated uncertainty related to ETo were also provided.
This database is available for download in the Network Common Data Form (netCDF) at https://doi.org/10.20350/digitalCSIC/8615 (Tomas-Burguera et al., 2019). A map visualization tool (http://speto.csic.es, last access: 10 December 2019) is available to help users download the data corresponding to one specific point in comma-separated values (csv) format.
A relevant number of research areas could take advantage of this database. For example, (i) studies of the Budyko curve, which relates rainfall data to the evapotranspiration and AED at the watershed scale, (ii) calculations of drought indices using AED data, such as the Standardized Precipitation–Evapotranspiration Index (SPEI) or Palmer Drought Severity Index (PDSI), (iii) agroclimatic studies related to irrigation requirements, (iv) validation of climate models' water and energy balance, and (v) studies of the impacts of climate change in terms of the AED.
- Article
(4983 KB) - Full-text XML
- BibTeX
- EndNote





Reference evapotranspiration (ETo) is a theoretical variable describing the evapotranspiration that would occur from a well-watered reference surface under specific meteorological conditions (Allen et al., 1998). Because well-watered conditions and a reference crop are assumed, both spatial and temporal ETo variability depends solely on the variability of the meteorological conditions. Hence, ETo is an accepted proxy for the atmospheric evaporative demand (AED), which is a key variable for understanding both water and energy terrestrial balances and, therefore, relevant to a variety of disciplines, including climatology, hydrology and agronomy (Espadafor et al., 2011). To compute ETo, the Food and Agriculture Organization of the United Nations (FAO) recommends using a modified version of a Penman–Monteith equation (Allen et al., 1998). The main advantage of this method is that it is physically based. It has also been tested against lysimeter data, obtaining reliable results (Jensen et al., 1990; Itenfisu et al., 2000; Berengena and Gavilán, 2005; Trajkovic, 2007). On the other hand, its main problem is its high data requirement, as data corresponding to the maximum and minimum air temperature, air humidity, wind speed, and solar radiation are needed. Although the maximum and minimum air temperature are commonly collected at weather observatories, observations of the other variables are scarce, especially if long time series are required for climate studies (Vanderlinden et al., 2004; McVicar et al., 2007; Irmak et al., 2012; Vicente-Serrano et al., 2014) or to generate ETo grids. The other significant problem facing the generation of ETo climate grids is the changing number of observations, which can introduce non-climatic changes in variance (Beguería et al., 2016).
In the event that some of the variables are not available, two types of approaches have been used to allow ETo calculations to be classified: (i) using of methods for calculating ETo requiring fewer climatic variables, commonly known as “less demanding methods”, and (ii) estimation of missing data prior to ETo calculation.
- i.
Less demanding methods. The use of methods for calculating ETo requiring only temperature data, such as the Thornthwaite (Thornthwaite, 1948) or Hargreaves (Hargreaves and Samani, 1985) approaches, are still common, especially because temperature is commonly available, and temperature and solar radiation accounts for 80 % of the ETo variability (Mendicino and Senatore, 2013; Samani, 2000). One of the major drawbacks of these methods is that variability and trends in the estimated ETo values depend only on temperature, regardless of the importance of the other variables (Irmak et al., 2012; McVicar et al., 2012; Sheffield et al., 2012; Tomas-Burguera et al., 2017).
- ii.
Estimation of missing data. Estimations of missing data prior to ETo calculation can also be divided into two possibilities: (i) use of the recommendations described in the FAO-56 document, which is the FAO document describing the guidelines for computing ETo, and (ii) use of nearby weather station data. Whenever data corresponding to the non-observed variables have been collected at nearby locations, the use of FAO-56 recommendations should be avoided for two reasons. First, they use stationary relationships between variables that were empirically derived, which can be problematic in the context of climate change since these relationships may also change. This is in fact the same problem that affects the less demanding methods, which also rely on empirically derived relationships (Tomas-Burguera et al., 2017). Second, temperature data are always required, limiting the number of locations from which ETo can be obtained.
The use of nearby weather station data to estimate missing data takes advantage of spatial interpolation methods, and it is the only approach among the above-mentioned methods that estimates missing data using information about the same variable. This strategy, usually known as interpolate-then-calculate (IC), has two main steps. First, the missing variables are estimated using a spatial interpolation method, and, second, the Penman–Monteith value (PM) is calculated. This method was tested in various regions, such as Greece, China and Great Britain (Mardikis et al., 2005; McVicar et al., 2007; Robinson et al., 2017). Tomas-Burguera et al. (2017) compared the performance of this method with the performances of some of the aforementioned solutions in the Iberian Peninsula, concluding that the IC strategy yielded better results.
The changing number of observations available over time is another relevant problem affecting the generation of ETo climate grids. To avoid negative effects, usually only the longest climate time series are used to generate climate grids using geostatistical methods, such as universal kriging (UK). Obviously, this strategy diminishes the number of usable climatic observations.
The problems mentioned above usually restrict the availability of high-spatial-resolution climate datasets of ETo, especially if they are developed using the Penman–Monteith equation. During the last several years, a ETo climate grid at a 1 km spatial resolution over Great Britain was presented Robinson et al. (2017). Haslinger and Bartsch (2016) presented a climate grid at a 1 km spatial resolution over Austria, but their grid was based on the Hargreaves equation.
A method focused on overcoming the above-mentioned problems related to data availability was designed to generate a climate grid of ETo over continental Spain and the Balearic Islands with a spatial resolution of 1.1 km covering the 1961–2014 period with a weekly temporal resolution. This method took advantage of two estimation processes prior to ETo calculation: (i) gap filling, used to obtain a subset of the complete time series over the period of interest for each of the climatic variables, and (ii) spatial interpolation, used to generate climate grids of each of the required climate variables. After spatial interpolation, ETo was calculated using climate grids as its source of data. This means that a PM-IC scheme was used. In addition to the estimation processes, quality control and homogenization steps were necessary. Although not commonly used, an uncertainty propagation scheme was designed, considering the two estimation processes (gap filling and interpolation) as the unique sources of uncertainty. The method and validation of the gap-filling, homogenization and interpolation steps are presented in detail in this paper.
The original dataset contained data corresponding to the daily maximum temperature (Tmax), minimum temperature (Tmin), wind speed (W), relative humidity (RH) and sunshine duration (SD) and was provided by Spanish Meteorological Agency (AEMET) across the whole region of Spain. Sunshine duration was used to estimate the radiation data, as the number of weather stations collecting radiation data was very low, and Sanchez-Lorenzo et al. (2013) assessed this method to obtain satisfactory results.
The number of observations available (Table 1) depended on the variable. More than 4000 weather stations collected the maximum and minimum temperature. Fewer than 1000 weather stations collected the other variables, and fewer than 300 collected the sunshine duration. The number of selected weather stations was always much lower than the available ones, as only the longest time series were selected.
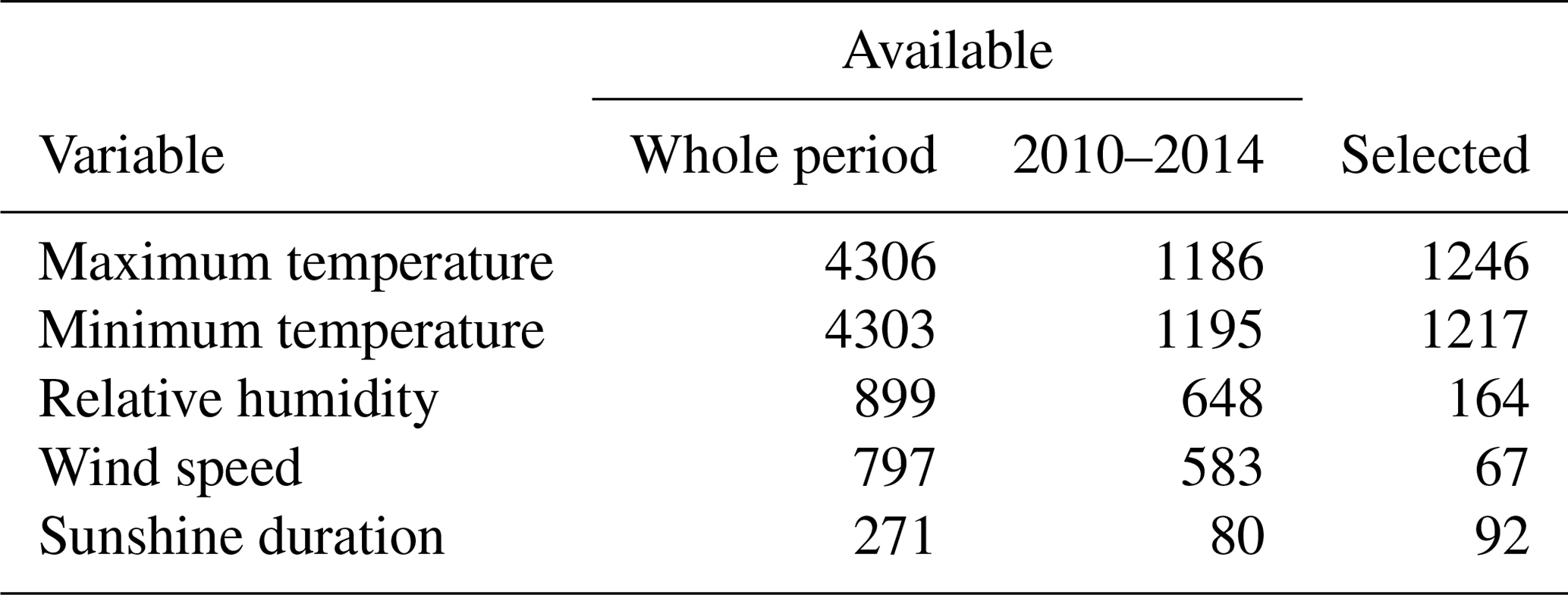
These weather stations did not collect data throughout the entire period. Figure 1 provides the number of weather observations available for each variable and each year for the 1961–2014 period. Temperature data showed the highest number of observations, always higher than 500, reaching 2000 observations available in the mid-90s, followed by a subsequent decrease. The relative humidity and wind speed showed a low number of observations during the study period. Nevertheless, in the mid-2000s, the installation of a large number of automatic weather stations (AWSs) sharply increased the availability of these two climatic variables. The sunshine duration measurements remained constant throughout the entire period.

Some geographic variables were used in the interpolation process. The digital elevation model (DEM) was obtained from the IGN (Instituto Geográfico Nacional), and other variables, such as distance to the sea, were derived from the DEM.
The general scheme used to generate the ETo database involved two main steps: (i) generation of climatic grids and (ii) estimation of ETo (Fig. 2). The generation of the climatic grids could be divided into (a) daily quality control, (b) daily-to-weekly data conversion, (c) gap filling, (d) data selection, (e) homogenization and (f) interpolation, and all of these steps were implemented individually for each climatic variable. The estimation of ETo consisted of the calculation of ETo using the FAO-56 Penman–Monteith equation over the climatic grid data sources.

Figure 2Main steps involved in generating the ETo database. First, we interpolated each climatic variable then calculated ETo.
On the other hand, the uncertainty in ETo was estimated using a two-step process: (i) uncertainty estimation of the climatic grids and (ii) uncertainty propagation from the climatic grids to ETo. The uncertainty estimation of the climatic grids estimated the uncertainty of each climatic grid after the interpolation process and considered the uncertainty related to the gap-filling process and the interpolation process. Uncertainty propagation refers to the technique used to estimate the uncertainty in ETo values by combining the uncertainty in each climatic variable with the Jacobian of the Penman–Monteith equation.
The quality of the data were assessed by implementing an automated daily quality control in R. Daily data were tested against two types of controls: codification errors and out-of-range values. The presence of duplicate data or n consecutive days having the exact same values in different observatories were the two most relevant codification errors detected. Out-of-range values mainly detected out-of-physical-range-values and out-of-climate-range values. More details can be found in Tomas-Burguera et al. (2016). The temporal aggregation of daily data into weekly data was then executed. For all variables, weekly time series were obtained by calculating the mean value of the daily data. Weeks presenting more than 1 d without data were considered to have no data. This is an adaptation of the World Meteorological Organization (WMO) rules for monthly data (WMO, 1989).
Some comparison problems between distinct years emerged if a timescale of 7 d was used, mainly because the number of days in a year is not divisible by 7. In an attempt to combine weekly timescales to preserve comparability between years, each month was divided into 4 periods (days 1–8, 9–15, 16–22, 23–28/29/30/31). For the remainder of this discussion, the use of the word week(s) refers to this definition of a sub-monthly period.
After this step, the relative humidity data were transformed into dew point temperature (Td) using the temperature data. Gap-filling and interpolation tests revealed that Td was easier to work with than RH. The Td data adjusted better to a Gaussian distribution than RH data; therefore, working with Td data was preferable for most of the implemented steps.
3.1 Gap filling
In an effort to obtain a complete time series of distinct climate variables, a gap-filling procedure based on the estimation of missing data using nearby weather station data, designed by Beguería et al. (2019), was implemented. The standard error of the estimated data was obtained and used as a measure of the uncertainty of the process.
The selection of nearby weather stations was relevant to the process, and a selection based on three steps was implemented: (i) overlapping periods longer than 7 years, (ii) locations closer than 100 km and (iii) values of R2 higher than 0.6.
The procedure used standardized values prior to gap filling in order to avoid problems related to differences in the mean values and/or variances between weather stations.
All weather stations available were used in the gap-filling process. The last step of the process involved data selection and depended on the amount of original data available. For temperature, only time series accounting for more than 25 years of the original data were used. For the rest of variables, this period was reduced to 15 years due to the low availability of long records (Fig. 3). Up to three gap-filling loops were implemented for less frequent variables (sunshine duration, dew point temperature and wind speed). Various steps in the gap-filling procedure took advantage of nonoverlapping data. This configuration was used previously to generate other databases over Spain (Gonzalez-Hidalgo et al., 2015).
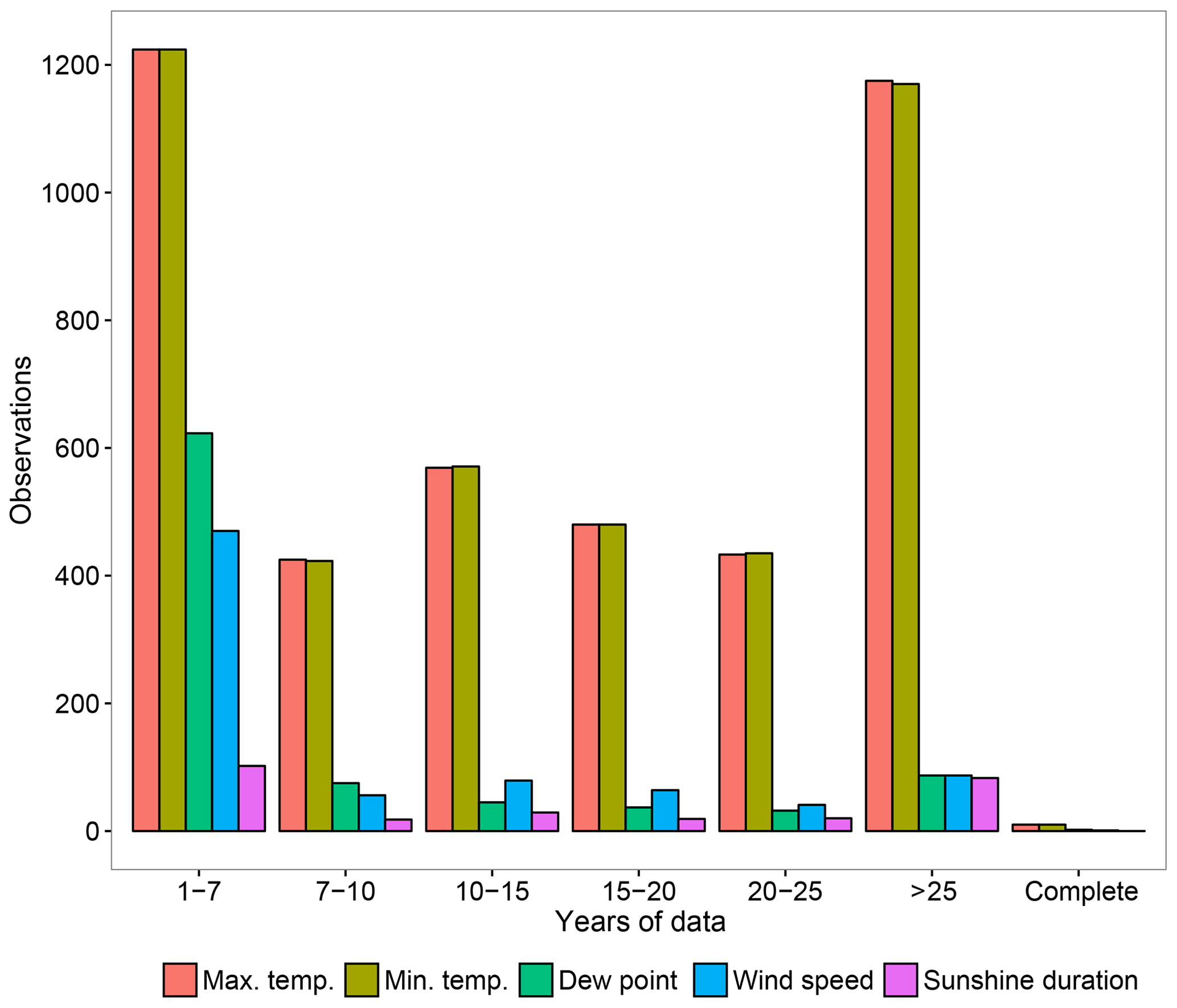
Figure 3Number of available observations grouped by variable and by years of data available.
3.2 Homogenization
The homogeneity of the obtained time series after the gap-filling process was tested using the Standard Normal Homogeneity Test (SNHT) (Alexandersson, 1986). This method used as a basis the comparison of the time series to be homogenized, the candidate series and a reference time series. Reference time series were obtained using the same process used to obtain the gap-filling reference time series.
The test was implemented at the monthly timescale after the conversion of time series to timescales, mainly because homogeneity tests, in general, are more robust when they are used with monthly data than with sub-monthly data. Weekly homogeneous time series were obtained by transforming the monthly parameters to weekly parameters.
The climate series homogeneity was tested after gap filling to (i) detect inhomogeneities introduced by the gap-filling process and (ii) determine if the process was more reliable if the time series had no gaps.
Present observations were assumed to be standard, meaning that any inhomogeneities were corrected to adjust the values of the past to the present values.
3.3 Interpolation
Kriging is a geostatistical method widely used in climatology to generate interpolated surfaces for many variables (Aalto et al., 2013; Hofstra et al., 2008). Kriging is, in fact, a set of different methods, for example, ordinary kriging (OK) or universal kriging (UK). The main difference between OK and UK is that the former assumes the presence of a spatial constant mean, whereas the latter assumes that the spatial mean is a function that can depend on geographical factors (Cressie, 1993). The latter assumption is preferable in climatology because climate variables commonly depend on geographical factors, such as latitude, longitude, or elevation (Aalto et al., 2013). In this paper, climate grids for each variable were generated individually using UK to predict a value at each grid point for each time step.
As a first step in the interpolation process, a semi-variogram model was generated. This model was unique for each time step and each climatic variable. This process was implemented using the gstat package in R (Pebesma, 2004; Gräler et al., 2016).
Using UK data, a variance of the prediction was also obtained, and this value was used to estimate the uncertainty. One of the advantages of using the gstat package is that an uncertainty associated with observed data can be provided. We decided to use the quantification of the uncertainty obtained from the gap-filling process, which is the previous estimation process.
3.4 ETo calculation
Predicted values of distinct climate variables were used to calculate ETo using the FAO-PM equation (Allen et al., 1998).
where Rn is the net radiation at the crop surface (MJ m−2 d−1), G is the soil heat flux density (MJ m−2 d−1), T is the mean air temperature at 2 m (∘C), U2 is the wind speed at 2 m (m s−1), es is the saturation vapor pressure (kPa), ea is the actual vapor pressure (kPa), es−ea is the saturation vapor pressure deficit (kPa), Δ is the slope of the vapor pressure curve (kPa ∘C−1) and γ is the psychrometric constant (kPa ∘C−1). The value 0.408 was used to convert from MJ m−2 d−1 units to kg m−2 d−1 (alternatively mm d−1). Following the recommendations of Allen et al. (1998), we fixed G to 0, as we estimated ETo over a time period of fewer than 10 d.
The main advantages of this equation are that it is physically based and accounts for both the radiative and aerodynamic components of evapotranspiration. The former is related to the energy available for evaporation and the latter is related to the capacity of the air to store the vapor from evapotranspiration (Azorin-Molina et al., 2015). Although the radiative component was strongly related to the solar radiation and presented a high seasonality in the study region due to its latitude, the aerodynamic component was more variable throughout the year, as it was influenced by the vapor pressure deficit as well as the wind speed. Splitting Eq. (1) into the sum of its two parts yielded the radiative component (EToRa) and the aerodynamic component (EToAe).
This dataset contained data describing each of the two components, EToRa and EToAe, as well as their summation, which is ETo. A variability and trend analysis could benefit from the availability of the two components. For example, wind stilling and solar brightening have opposite effects in ETo, but studying the two components separately facilitates the study of the impacts of each one on ETo.
3.5 ETo uncertainty estimation
Due to the complexity of the process involved in estimating the uncertainty in ETo, the uncertainty in this first version of the dataset was estimated only for the final value of ETo and not for its two components (EToRa and EToAe).
3.5.1 Uncertainty estimation in the climatic grids
Climate grid generation involves many sources of data uncertainty, including uncertainty related to the observation, the interpolation process and other sources (Haylock et al., 2008). In this paper, we assumed that uncertainty was only related to the estimation processes, i.e., gap filling and interpolation. Moreover, we considered the uncertainty of each climatic grid at each time step to be equal to the uncertainty after the interpolation process.
Uncertainty estimation over the gap-filling process was based on the number of weather observations used to estimate the missing data and the covariance between these data points. Less covariance between data was associated with more uncertainty.
The interpolation process assumed that any uncertainty was equal to the variance of the prediction, i.e., the variance of the kriging. The uncertainty estimated over the gap-filling process was propagated to the interpolation process using the gstat package in R, as the uncertainties related to the observational data used in the interpolation process were available.
3.5.2 Uncertainty propagation
The uncertainty propagation allowed us to obtain the uncertainty associated with the predicted values of ETo (R), using the posterior variance of the climate grids and the Jacobian of the FAO-PM.
where is the Jacobian of ETo and Q is the covariance matrix of the variables. For simplicity, the variables were considered to be independent, yielding a diagonal matrix with variance positions distinct from 0.
The Jacobian assumed the following form and was analytically derived.
The covariance matrix could be expressed as follows:
where σ2 is the variance of the kriging of each of the climatic variables. In fact, as Q is a diagonal matrix, the R calculation could be rewritten as follows:
3.6 Using 2010–2014 data to validate the air humidity and wind speed grids
During the last part of the period (2010–2014), a high number of AWSs were installed. A sharp increase in the available RH and W data was observed during this period, compared with the data available from weather stations used to generate the original database (Table 1). The values of these observations and the values of the climate grids were compared directly to obtain the relative humidity and wind speed over the 2010–2014 period using the new stations as an independent dataset.
4.1 Gap filling
The performance of the gap-filling step was verified by comparing the original data and estimated data. Obviously, this comparison was only possible for periods having original data.
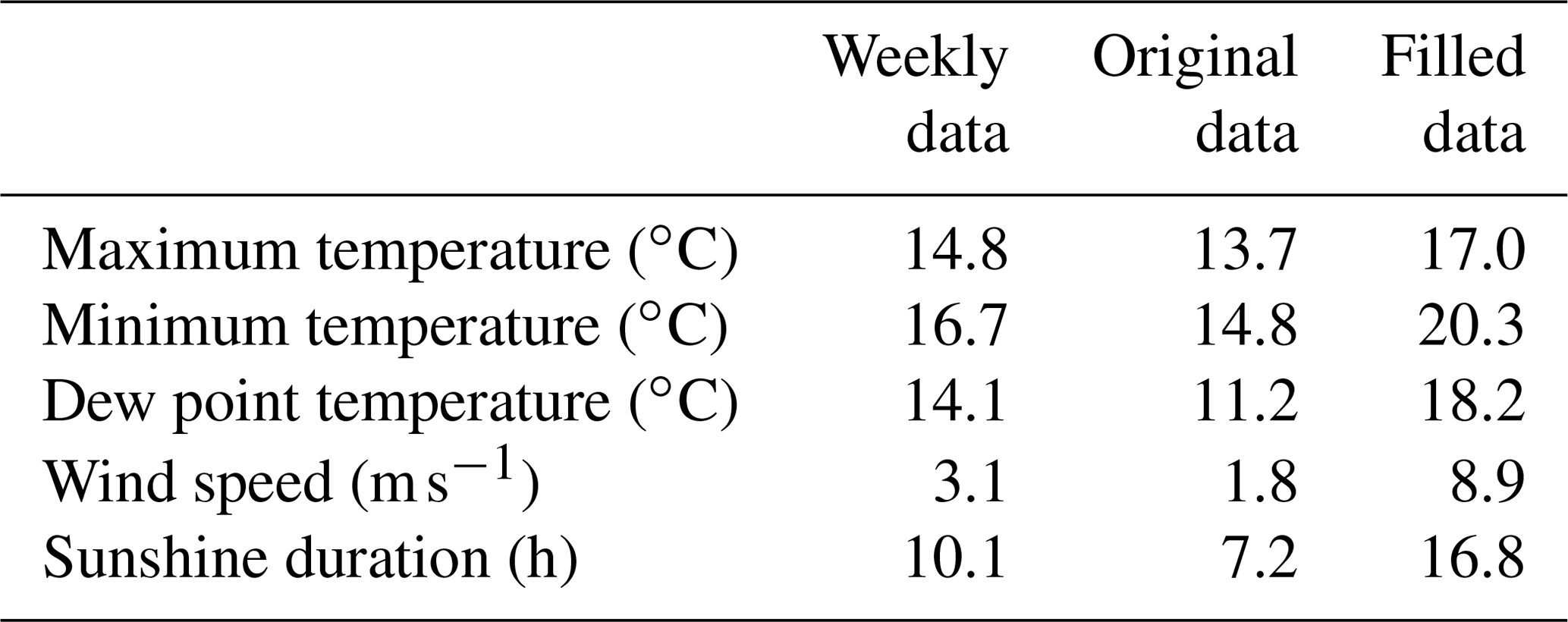
Table 2 lists certain statistics associated with the verification process. In general, satisfactory values of R2 were achieved, with values higher than 0.9 for all variables except for the wind speed, which showed an R2 of only 0.53. Evaluation of mean error (ME) and percent bias (PBIAS) showed no bias for the maximum and minimum temperature, a small negative bias for the dew point temperature (ME of −0.01 and PBIAS of −0.15) and the sunshine duration (ME of −0.01 and PBIAS of −0.23), and a positive bias for the wind speed (ME of 0.08 and PBIAS of 0.64). The ratio of the mean values and the ratio of the standard deviation showed values close to 1 for all variables. The wind speed displayed a standard deviation ratio of 1.05, meaning that the temporal variability of the gap-filling data was slightly higher than the temporal variability of the original data.
Table 2Gap-filling statistics. Values for the following validation statistics are provided: (i) mean absolute error (MAE), (ii) coefficient of determination R2, (iii) mean error (ME), (iv) percent bias (PBIAS), (v) ratio of mean values (rM) and (vi) ratio of standard deviation (rSD).

Figure 4 evaluates the possible existence of temporal differences in the performance of the gap-filling process using decadal values of R2. In general, all analyzed periods showed similar performances. For wind speed, the most recent decade showed slightly higher R2 values than the other decades of the period.
As the amount of original data changed over time, the amount of filled data also showed a temporal evolution. Figure 5 indicates this temporal evolution, with a higher amount of filled data during the first years of the period and a large decline over time. The amount of filled data corresponding to the maximum and minimum temperature increased again during the last several years because of a slow decline in the number of observations and the disappearance of some of the weather stations with longer records.

The wind speed provided the lowest amount of filled data. It was difficult to obtain highly correlated time series to fill in the gaps, which had two major effects on the process: (i) the probability of obtaining a reference time series from the neighbors was decreased and (ii) the reconstruction was poor when the reference time series could be obtained. The low correlation of the wind speed time series was a consequence of (i) the high spatial and temporal variability of this variable and (ii) the low number of observations available.
4.2 Homogenization
The percentage of data affected by the homogenization process exceeded 10 % for all variables except for the wind speed (Table 3). For all variables, the percentage of homogenized data was higher for the filled data than for the original data, indicating the importance of implementing a homogenization process after gap filling. Two factors could explain this effect: (i) because the original data were not homogenized prior to the gap filling, the presence of inhomogeneities in the original data propagated to the homogenized data and (ii) inhomogeneities may have been introduced by the gap-filling procedure.
The temporal evolution of the quantity of data detected as inhomogeneous was analyzed (Fig. 5), revealing a temporal trend with maximum values at the start of the study period and minimum values at the end. The most likely explanation for this observation is the use of more recent conditions as the standard conditions.
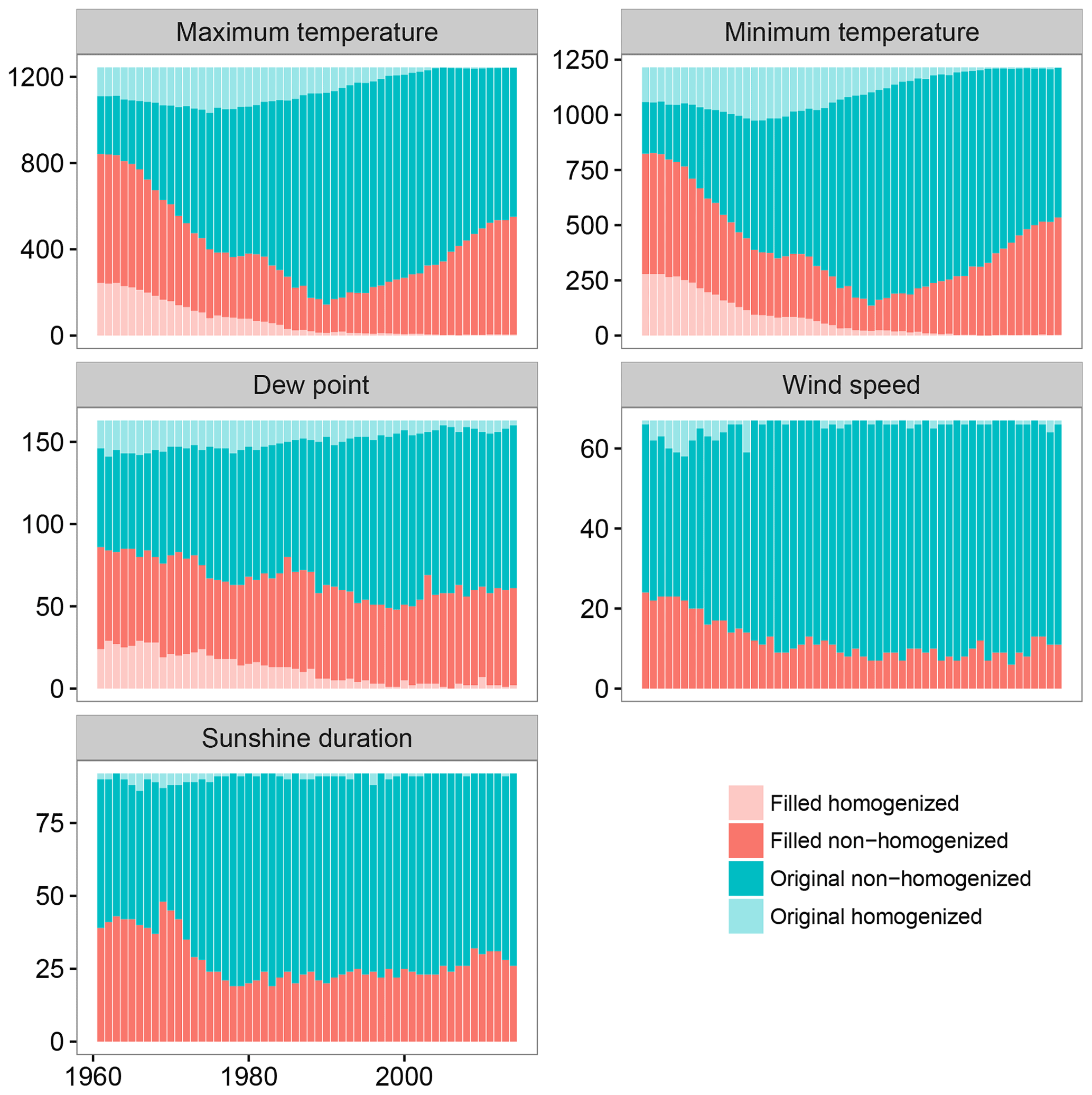
Figure 5Temporal evolution of the number of filled data for the different climatic variables. The temporal evolution of the homogenized data is also shown.
Another effect of this assumption is the propagation of the current conditions to the past, which was evaluated by comparing the spatial mean values of the homogenized and prior-to-homogenization time series. Figure 6 highlights this effect in the implemented homogenization process. The maximum and minimum temperature, which displayed a positive trend in Spain over the study period (del Río et al., 2012; Gonzalez-Hidalgo et al., 2016), suggested that higher values occurred in the present than in the past. A positive bias was observed in the homogenized data over the first decades (1961–1970, 1971–1980 and 1981–1990). Unlike the maximum and minimum temperature, the wind speed, which displayed a negative trend (Azorin-Molina et al., 2014), was affected by a negative bias during the first decades (1961–1970, 1971–1980 and 1981–1990) of the study period.
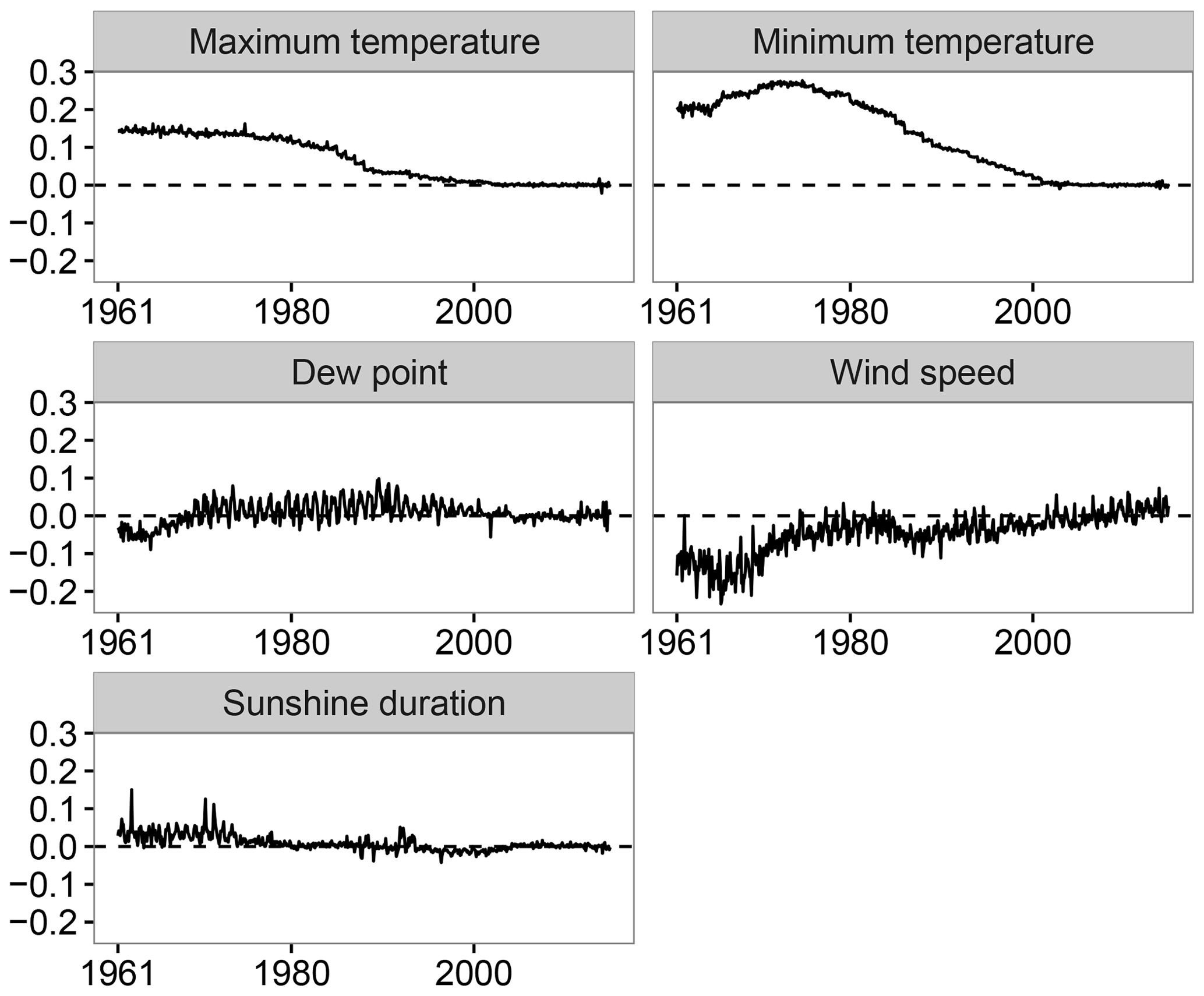
Figure 6Temporal evolution of the differences between the mean regional values before and after homogenization.
The effect of the homogenization process on ETo was evaluated using a similar procedure, which involved calculating the mean regional values of ETo before and after homogenization of the climatic variables. These regional values were obtained by calculating first a mean regional value of the climatic variables, followed by calculating the ETo using the Penman–Monteith equation.
No important differences were detected in a comparison of the two time series of ETo (Fig. 7). This result is relevant, as it shows that the undesirable detrending introduced by the homogenization process did not affect the spatial mean values of ETo.
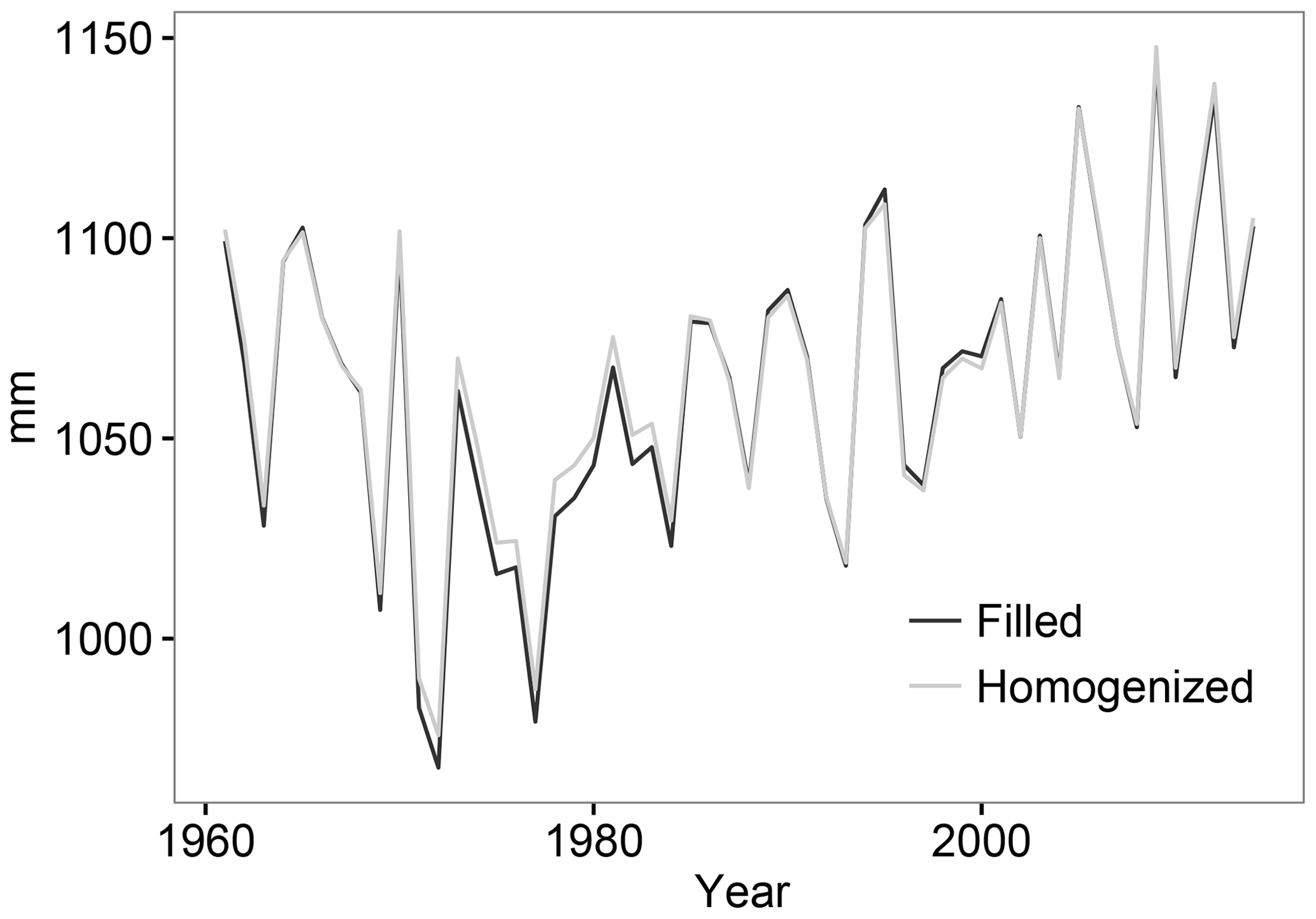
Figure 7Temporal evolution of the mean regional values of ETo before (filled) and after (homogenized) homogenization.
4.3 Interpolation validation
The interpolation process was validated by executing a leave-one-out cross-validation (LOO-CV) process, and validation statistics were calculated to evaluate the performance of the interpolation in predicting both the temporal variability and the spatial variability. The LOO-CV process consisted of repeating the interpolation process n times (n being the number of observations available) using each time n−1 observations and using the predicted value at the unused observatory as a way to evaluate the quality of the interpolation.
The temporal variability was evaluated by calculating the temporal statistics individually for each observatory and then computing the mean of all observatories. The spatial variability was evaluated by calculating the statistics at each time step using information comprising all observatories and then computing the mean of all time steps. The problem with the LOO-CV method is that validation could only be estimated at a given point if observations used during the interpolation process existed.
Another option for validating the interpolation process consisted of comparing the unused observational data over the 2010–2014 period (when a high number of wind speed and relative humidity observations existed) against the interpolated values.
4.3.1 Spatial and temporal validation using LOO-CV
The ability of the interpolation process to predict the spatial and the temporal variability of the climatic grids is summarized in Table 4. In general, temporal validation showed better statistics than spatial validation. All variables, except for the wind speed, showed R2 values greater than 0.9 for the temporal validation and close to 0.8 for the spatial validation.
Table 4Spatial and temporal validation of the interpolation process. Values for the following validation statistics are provided: (i) mean absolute error (MAE), (ii) coefficient of determination R2, (iii) mean error (ME), (iv) percent bias (PBIAS), (v) ratio of mean values (rM) and (vi) ratio of standard deviation (rSD).
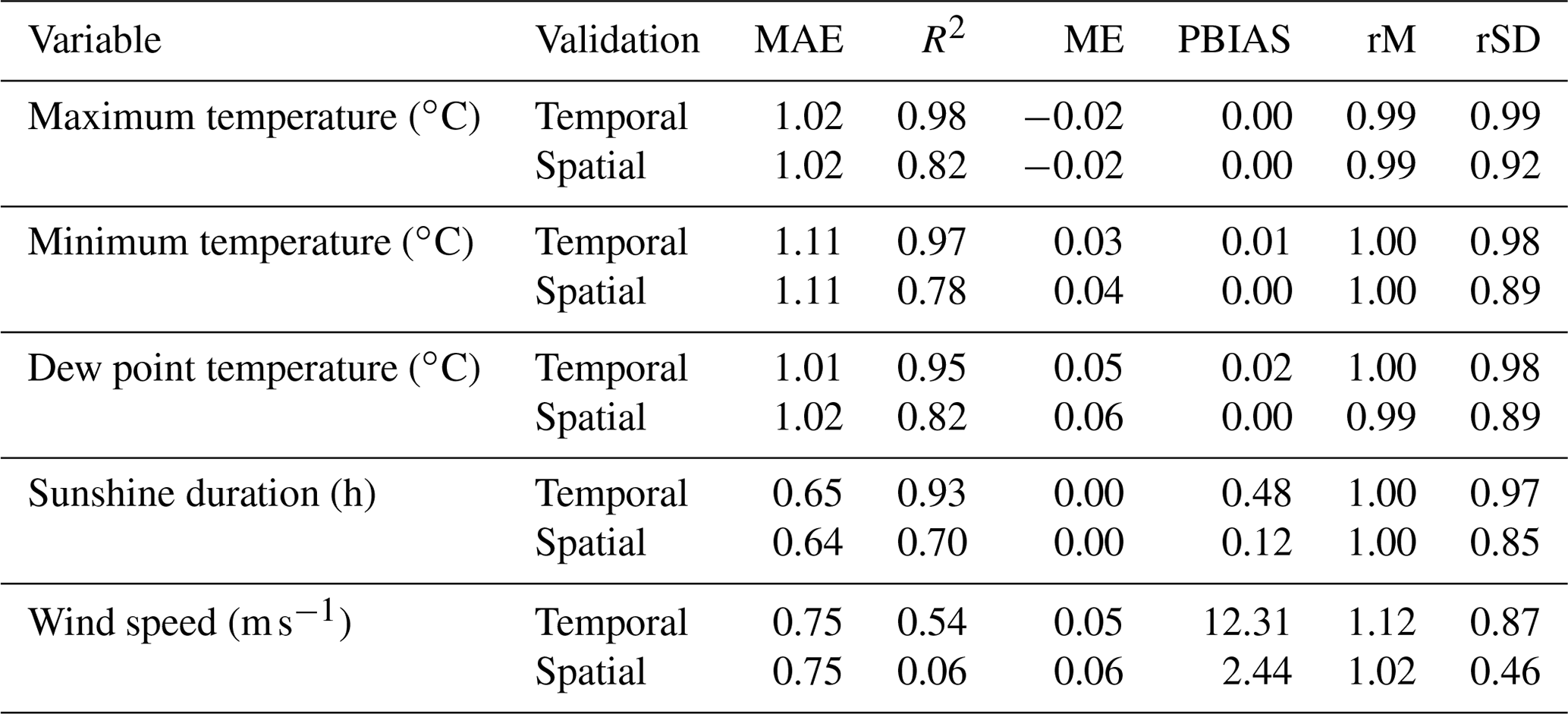
According to ME and PBIAS, the only variable that indicated the presence of bias in both validations was the wind speed, which yielded a PBIAS of 12.31 for the temporal validation.
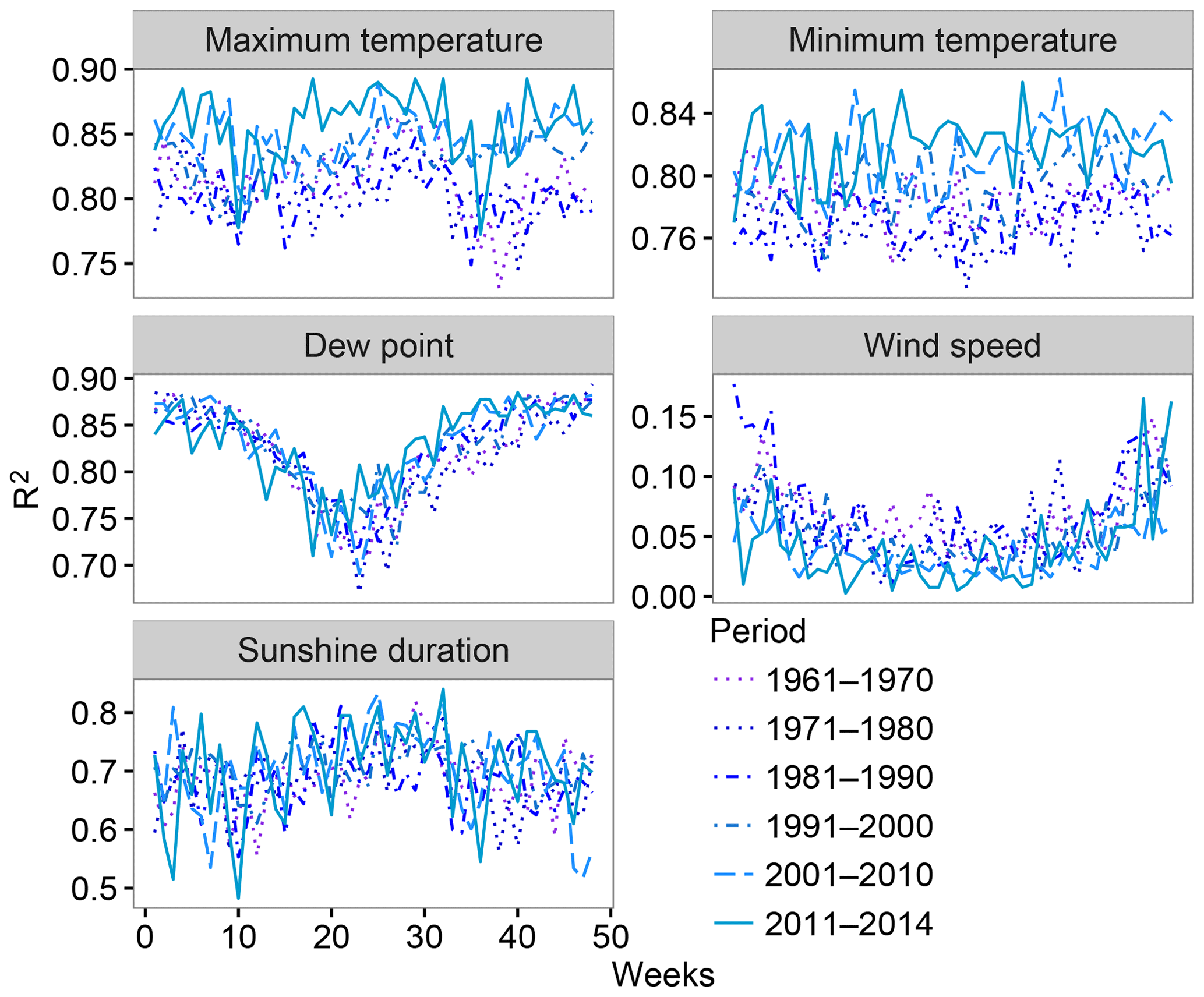
A temporal analysis of the R2 values obtained from the spatial validation of the maximum and minimum temperature (Fig. 8) showed slightly better statistics (i e., closer to one) in recent decades (2001–2010 and 2011-2014). Nevertheless, the most relevant detected effect was the presence of seasonality in the R2 of the dew point temperature, which indicated lower values during summer than during winter. A higher spatial variability in the air humidity in summer months due to the contrast between the high air humidity in the coastal areas and the low air humidity in the continental areas may be the source of the lower values during summer.
4.3.2 The 2010–2014 validation
Validating the interpolation performance over the 2010–2014 independent time series of the wind speed and relative humidity revealed that the two most relevant detected problems were the overestimation of the wind speed during winter months in the northeastern region of the Iberian Peninsula and the overestimation of the dew point temperature in the inner region of the Iberian Peninsula during the summer months at the same time that an underestimation was detected in the maritime region. These two effects are visualized in Fig. 9, which shows the mean errors for January and July for the two variables.
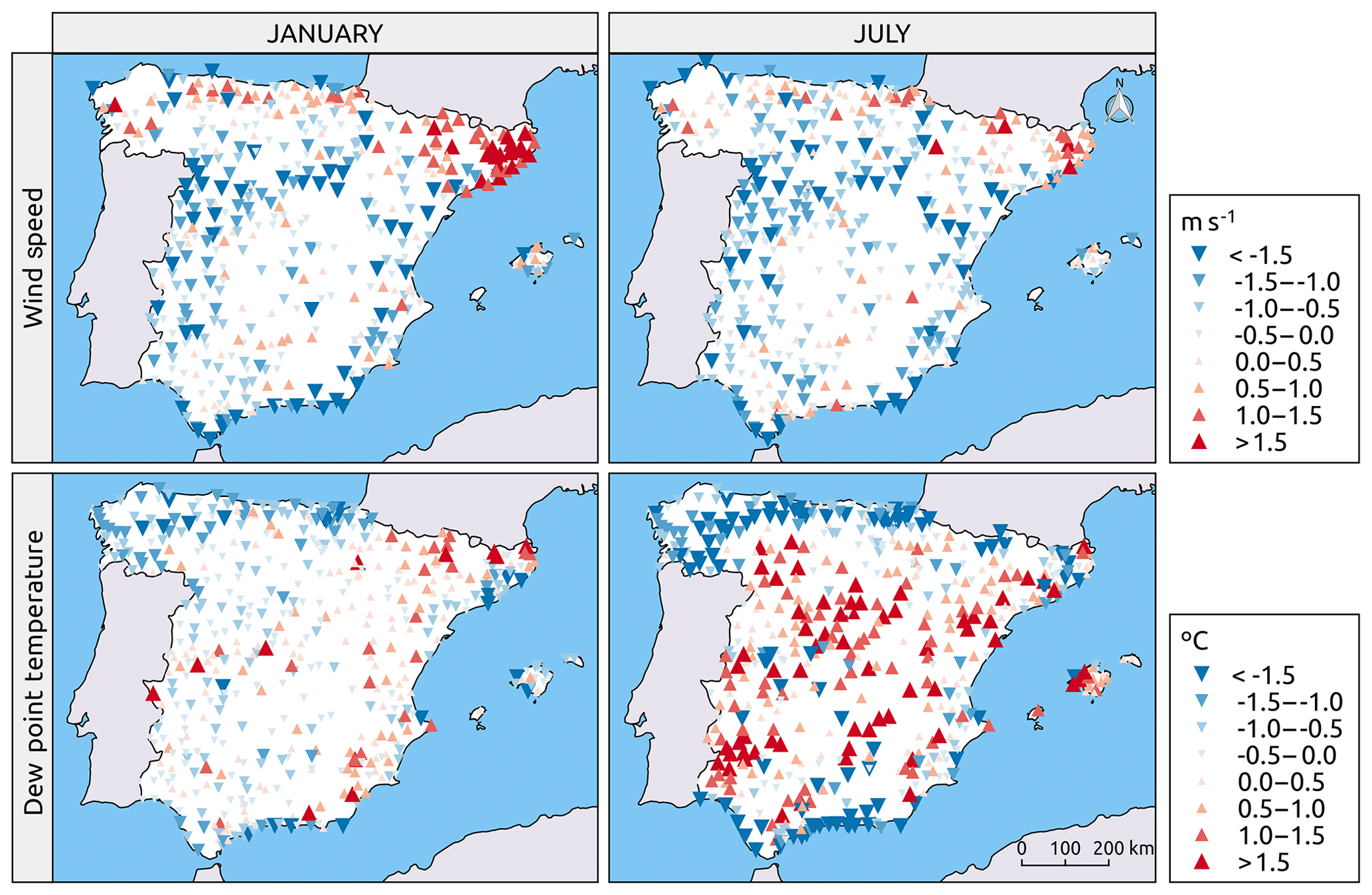
Figure 9Spatial validation of the dew point and wind speed climatic grids using a subset of independent observations over the 2010–2014 period, in terms of the mean error.
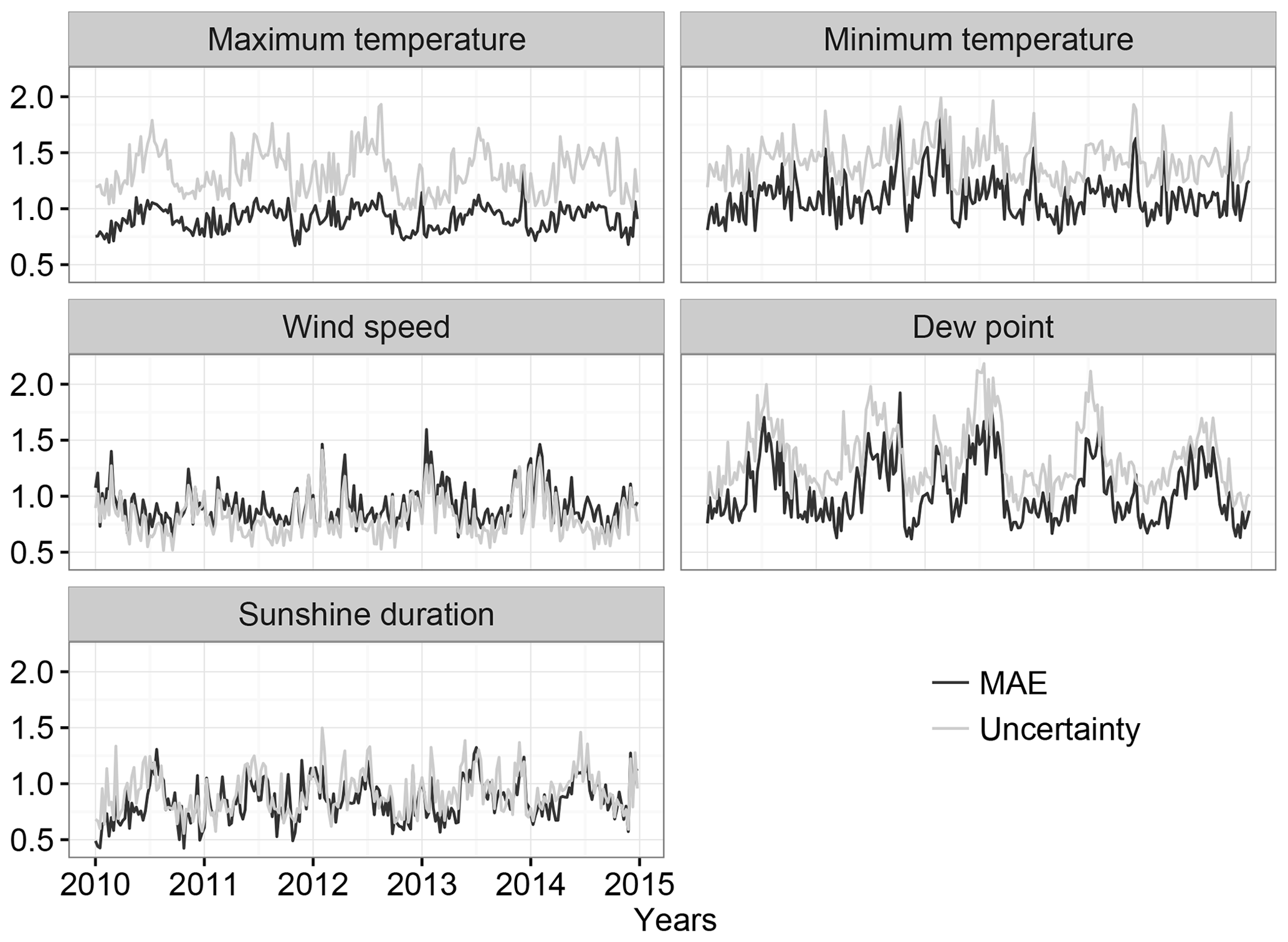
Figure 10Temporal evolution of the MAE and uncertainty of the interpolation at a subset of independent observations over the 2010–2014 period.
Figure 11Example of the data visualization tool available at the following web page: http://speto.csic.es (last access: 10 December 2019).
4.3.3 Uncertainty validation
Data from the 2010–2014 period could also be used to validate the uncertainty estimation of the climatic grids. First, the mean absolute error (MAE) was calculated by comparing the independent weather station data against the climatic grid data. Then, the obtained values of the MAE were compared against the uncertainty values of the climatic grids.
The mean spatial values of the MAE and the uncertainty are represented in Fig. 10. In general, the uncertainty of the climatic grids was well estimated, especially for the wind speed and sunshine duration, as these variables showed similar values of the MAE and uncertainty. The other variables, (Tmax, Tmin and Td), showed slightly higher values of uncertainty than the MAE values but always with similar temporal oscillations.
The four files generated in this dataset (weekly values of reference evapotranspiration, uncertainty estimation of the weekly values of reference evapotranspiration, aerodynamic component values of the weekly reference evapotranspiration and the radiative component values of the weekly reference evapotranspiration) can be accessed and downloaded via two different sources.
From Digital CSIC, which is a long-term repository managed by the Spanish Research Council (CSIC), users can download the files in netCDF format through https://doi.org/10.20350/digitalCSIC/8615 (Tomas-Burguera et al., 2019).
The data can also be accessed at the following web page, which is a map visualization tool: http://speto.csic.es (last access: 10 December 2019). Users can visualize the data generated at different time steps, download the complete netcdf files or download a complete time series for a chosen point as a comma-separated value (csv) file. As the spatial resolution of the data is 1.1 km over continental Spain and the Balearic Islands, the total number of grid points is slightly higher than 400 000. The weekly temporal resolution yielded 2592 different weekly maps for each of the four available files.
We proposed a method for obtaining a 1961–2014 ETo climate grid across Spain based on the Penman–Monteith equation. Whereas previous studies of ETo and AED climatology in Spain have been developed (Azorin-Molina et al., 2015; Sanchez-Lorenzo et al., 2014; Vicente-Serrano et al., 2014), this is the first suitable ETo database for use in climate studies covering the full study area with a high spatial resolution and over a long time period.
As the number of weather stations collecting all variables required to calculate ETo was very low, the proposed methodology took advantage of two estimation processes: gap filling and spatial interpolation. The performances of the processes were carefully studied to detect the possible negative impacts on the generation of the ETo database. In general, no relevant problems were detected for most of the climatic variables. The wind speed displayed the worst performance in each of the estimation processes due to its high spatial and temporal variability.
The PM-IC strategy, which consisted of interpolating climatic variables prior to calculating ETo, was previously used to model other regions (Mardikis et al., 2005; McVicar et al., 2007) and was determined to be the best method for estimating ETo in the event of missing data in Spain (Tomas-Burguera et al., 2017). Another strategy, known as PM-CI, calculated ETo prior to interpolation and was also appropriate for use. The main advantage of the PM-CI over PM-IC strategy was that only one interpolation was required. The main disadvantage was that much of the available data were not used. In the case of Spain, the use of the PM-CI strategy would have restricted the calculation of ETo to nearly 50 weather stations, which is the number of weather stations used in previous studies (Vicente-Serrano et al., 2014). On the other hand, the use of the PM-IC strategy allowed the use of more data, especially of temperature data, from more than 1000 weather stations. As 80 % of the ETo variability was related to the variability in temperature and radiation (Mendicino and Senatore, 2013; Samani, 2000), using as many temperature observations as possible was important for ensuring the quality of the obtained results.
A comparison against an independent subset of climatic data collected over the 2010–2014 period showed the presence of a positive bias in the wind speed during winter over the northeastern region of the Iberian Peninsula. The overestimation of the wind speed in this region could be explained by the fact that a low number of observations were used in that region, and most of the observations used were located in places affected by Tramontane winds. Fortunately, the higher bias was detected in winter, when ETo values were lower and the importance of this variable for some uses (e.g., irrigation schedule) was also lower. Two factors appeared to be relevant for wind speed estimation problems: (i) the high spatial variability of the wind speed (Luo et al., 2008) and (ii) the fact that the wind speed was not normally distributed. Both the gap-filling and interpolation processes tend to perform better when applied to normally distributed data.
These comparisons also detected some problems related to the dew point temperature values predicted during summer. An inverse bias was detected between the inland and maritime regions. During the summer months, the humidity contrast between the inland and maritime regions was high in the Iberian Peninsula, as maritime regions experienced a higher humidity due to the contributions of the sea breezes. The detected overestimation of the dew point temperature during the summer across the continental regions led to an underestimation of the vapor pressure deficit and also to an underestimation of ETo. This effect suggested that the ETo values were underestimated to some degree across the continental regions of Spain, whereas the maritime regions may have been affected by an overestimation.
The performance of the homogenization process was tested, and changes in the spatial mean values of the first decades were detected in some of the climatic variables. Although the maximum and minimum temperatures were affected by an increase in their spatial mean, the wind speed was affected by a decrease in the spatial mean. Due to counteracting effects, the ETo mean spatial value was not affected by this problem.
Considering that each estimation process was affected by uncertainty, the uncertainty in ETo after applying the two estimation processes was obtained. For simplicity, the climatic variables were considered to be independent in the final step of the uncertainty estimation, which involved the propagation of the uncertainty of each climatic variable through the Penman–Monteith equation.
Haylock et al. (2008) pointed out that the variance of the kriging, which in this paper was used to estimate the uncertainty of each climatic grid, is not a true estimation of the uncertainty; however, an evaluation of the uncertainty estimations of each variable showed a good agreement between the MAE values and the estimated uncertainty values. Unfortunately, the uncertainty of ETo could not be verified because an independent subset of observatories that collected all variables was required to calculate ETo but was not available.
This dataset was first developed as an input to generate, in combination with the precipitation data, grids of drought indices over the study area (Vicente-Serrano et al., 2017). Due to the relevance of ETo and the high number of possible uses of these data, the ETo climate grid is now being made available to other research groups. As with drought studies, in some cases the interest was focused on the combined analysis of ETo and the precipitation data. This could be the case for hydrological studies in which the AED data can explain some of the most important processes taking place in a catchment. The combined analysis may provide better estimations of water balance and aridity indices. The present dataset covered a long period of time, thereby enabling studies of the temporal evolution of these indices.
Irrigated agriculture is another sector interested in these data, as the water balance is important both for irrigation planning and for irrigation scheduling. The development of modern irrigation systems has rendered irrigation a significant economic activity in some regions of Spain, such as the Ebro basin (Vidal-Macua et al., 2018), reinforcing the importance of the dataset in that region. More accurate models of ETo is also useful for rainfed agriculture. Hence, the whole agricultural sector could benefit from this dataset.
This dataset could be interpreted as the first available AED climate grid across Spain, which is quite relevant to the development of spatial and temporal climatology studies that could confirm the previously detected positive trends of certain variables across the study area. This database could also be used for regional (or global) climate model assessment in the context of climate change studies.
Calculating ETo using PM assumed a well-watered reference surface, which can differ significantly from the actual conditions present in a semiarid region, as is the case across most of our study area. A scarcity of soil moisture can decrease the air humidity and increase the air temperature compared with well-watered conditions due to the effects of the land–atmosphere continuum. Both changes, which especially affect the aerodynamic component of ETo, may have a noticeable effect on ETo, meaning that an overestimation can occur under semiarid conditions (Bouchet, 1963; Allen et al., 1998). Such an overestimation would be higher during the warm season when these conditions prevail. The possible overestimation due to the use of PM in a semiarid environment should be considered by potential users of this database.
MTB, in collaboration with SMVS and SB, conceived the research. MTB developed the quality control algorithms applied to the data, contributed to the computation of ETo, developed the data validation algorithms and prepared the manuscript. SB developed methods for data reconstruction and climate mapping. FR and BL processed the data and developed the web portal infrastructure.
The authors declare that they have no conflict of interest.
The authors thank the Spanish Meteorological Agency (AEMET) for providing the original data.
This research has been supported by the Ministerio de Economía y Competitividad (grant nos. PCIN-2015-220, CGL2014-52135-C03-01, CGL2014-52135-C03-02 and CGL2014-52135-C03-03), the Ministerio de Economía, Industria y Competitividad, Gobierno de España (grant no. CGL2017-83866-C3-3-R), and the Ministerio de Educación, Cultura y Deporte (grant no. FPU13/02976).
This paper was edited by Jens Klump and reviewed by two anonymous referees.
Aalto, J., Pirinen, P., Heikkinen, J., and Venäläinen, A.: Spatial interpolation of monthly climate data for Finland: Comparing the performance of kriging and generalized additive models, Theor. Appl. Climatol., 112, 99–111, https://doi.org/10.1007/s00704-012-0716-9, 2013. a, b
Alexandersson, H.: A homogeneity test applied to precipitation data, J. Climatol., 6, 661–675, https://doi.org/10.1002/joc.3370060607, 1986. a
Allen, R. G., Pereira, L. S., Raes, D., and Smith, M.: Fao irrigation and drainage paper 56 – crop evapotranspiration – guidelines for computing crop water requirements, Rome, 1998. a, b, c, d, e
Azorin-Molina, C., Vicente-Serrano, S. M., McVicar, T. R., Jerez, S., Sanchez-Lorenzo, A., López-Moreno, J. I., Revuelto, J., Trigo, R. M., Lopez-Bustins, J. A., and Espírito-Santo, F.: Homogenization and assessment of observed near-surface wind speed trends over Spain and Portugal, 1961–2011, J. Climate, 27, 3692–3712, https://doi.org/10.1175/JCLI-D-13-00652.1, 2014. a
Azorin-Molina, C., Vicente-Serrano, S. M., Sanchez-Lorenzo, A., McVicar, T. R., Morán-Tejeda, E., Revuelto, J., El Kenawy, A., Martín-Hernández, N., and Tomas-Burguera, M.: Atmospheric evaporative demand observations, estimates and driving factors in Spain (1961–2011), J. Hydrol., 523, 262–277, https://doi.org/10.1016/j.jhydrol.2015.01.046, 2015. a, b
Beguería, S., Vicente-Serrano, S. M., Tomás-Burguera, M., and Maneta, M.: Bias in the variance of gridded data sets leads to misleading conclusions about changes in climate variability, Int. J. Climatol., 36, 3413–3422, https://doi.org/10.1002/joc.4561, 2016. a
Beguería, S., Tomas-Burguera, M., Serrano-Notivoli, R., Peña-Angulo, D., Vicente-Serrano, S. M., and González-Hidalgo, J. C.: Gap filling of monthly temperature data and its effect on climatic variability and trends, J. Climate, 32, 7797–7821, https://doi.org/10.1175/JCLI-D-19-0244.1, 2019. a
Berengena, J. and Gavilán, P.: Reference evapotranspiration estimation in a highly advective semiarid environment, J. Irrig. Drain. E., 131, 147–163, https://doi.org/10.1061/(ASCE)0733-9437(2005)131:2(147), 2005. a
Bouchet, R.: Evapotranspiration réelle et potentielle, signification climatique, Int. Assoc. Sci. Hydrol. Publ., 62, 134–142, 1963. a
Cressie, N. A. C.: Statistics for Spatial Data, Wiley, New Yor, 1993. a
del Río, S., Cano-Ortiz, A., Herrero, L., and Penas, A.: Recent trends in mean maximum and minimum air temperatures over Spain (1961–2006), Theor. Appl. Climatol., 109, 605–626, https://doi.org/10.1007/s00704-012-0593-2, 2012. a
Espadafor, M., Lorite, I. J., Gavilán, P., and Berengena, J.: An analysis of the tendency of reference evapotranspiration estimates and other climate variables during the last 45 years in Southern Spain, Agr. Water Manage., 98, 1045–1061, https://doi.org/10.1016/j.agwat.2011.01.015, 2011. a
Gonzalez-Hidalgo, J. C., Peña-Angulo, D., Brunetti, M., and Cortesi, N.: MOTEDAS: A new monthly temperature database for mainland Spain and the trend in temperature (1951–2010), Int. J. Climatol., 35, 4444–4463, https://doi.org/10.1002/joc.4298, 2015. a
Gonzalez-Hidalgo, J. C., Peña-Angulo, D., Brunetti, M., and Cortesi, N.: Recent trend in temperature evolution in Spanish mainland (1951–2010): From warming to hiatus, Int. J. Climatol., 36, 2405–2416, https://doi.org/10.1002/joc.4519, 2016. a
Gräler, B., Pebesma, E., and Heuvelink, G.: Spatio-temporal geostatistics using gstat, R J., 8, 204–218, https://doi.org/10.32614/RJ-2016-014, 2016. a
Hargreaves, G. and Samani, Z.: Reference crop evapotranspiration from temperature, Appl. Eng. Agric., 1, 96–99, 1985. a
Haslinger, K. and Bartsch, A.: Creating long-term gridded fields of reference evapotranspiration in Alpine terrain based on a recalibrated Hargreaves method, Hydrol. Earth Syst. Sci., 20, 1211–1223, https://doi.org/10.5194/hess-20-1211-2016, 2016. a
Haylock, M. R., Hofstra, N., Klein Tank, A. M. G., Klok, E. J., Jones, P. D., and New, M.: A European daily high-resolution gridded dataset of surface temperature and precipitation, J. Geophys. Res.-Atmos., 113, D20119, https://doi.org/10.1029/2008JD010201, 2008. a
Hofstra, N., Haylock, M., New, M., Jones, P., and Frei, C.: Comparison of six methods for the interpolation of daily, European climate data, J. Geophys. Res.-Atmos., 113, D211110, https://doi.org/10.1029/2008JD010100, 2008. a
Irmak, S., Kabenge, I., Skaggs, K. E., and Mutiibwa, D.: Trend and magnitude of changes in climate variables and reference evapotranspiration over 116-yr period in the Platte River Basin, central Nebraska-USA, J. Hydrol., 420-421, 228–244, https://doi.org/10.1016/j.jhydrol.2011.12.006, 2012. a, b
Itenfisu, D., Elliot, R., Allen, R., and Walter, I.: Comparison of reference evapotranspiration calculations across a range of climates, in: Proceedings of the 4th National Irrigation Symposium, St. Joseph, ASAE Edn., 216–227, 2000. a
Jensen, M., Burman, R., and Allen, R.: Evapotranspiration and irrigation water requirements, in: ASCE manual No. 70, p. 332, New York, ASCE Edn., 1990. a
Luo, W., Taylor, M., and Parker, S.: A comparison of spatial interpolation methods to estimate continuous wind speed surfaces using irregularly distributed data from England and Wales, Int. J. Climatol., 28, 947–959, https://doi.org/10.1002/joc.1583, 2008. a
Mardikis, M. G., Kalivas, D. P., and Kollias, V. J.: Comparison of interpolation methods for the prediction of reference evapotranspiration – An application in Greece, Water Resour. Manage., 19, 251–278, https://doi.org/10.1007/s11269-005-3179-2, 2005. a, b
McVicar, T. R., Van Niel, T. G., Li, L. T., Hutchinson, M. F., Mu, X. M., and Liu, Z. H.: Spatially distributing monthly reference evapotranspiration and pan evaporation considering topographic influences, J. Hydrol., 338, 196–220, https://doi.org/10.1016/j.jhydrol.2007.02.018, 2007. a, b, c
McVicar, T. R., Roderick, M. L., Donohue, R. J., and Van Niel, T. G.: Less bluster ahead? ecohydrological implications of global trends of terrestrial near-surface wind speeds, Ecohydrology, 5, 381–388, https://doi.org/10.1002/eco.1298, 2012. a
Mendicino, G. and Senatore, A.: Regionalization of the Hargreaves Coefficient for the Assessment of Distributed Reference Evapotranspiration in Southern Italy, J. Irrig. Drain. E., 139, 349–362, https://doi.org/10.1061/(ASCE)IR.1943-4774.0000547, 2013. a, b
Pebesma, E. J.: Multivariable geostatistics in S: The gstat package, Comput. Geosci., 30, 683–691, https://doi.org/10.1016/j.cageo.2004.03.012, 2004. a
Robinson, E. L., Blyth, E. M., Clark, D. B., Finch, J., and Rudd, A. C.: Trends in atmospheric evaporative demand in Great Britain using high-resolution meteorological data, Hydrol. Earth Syst. Sci., 21, 1189–1224, https://doi.org/10.5194/hess-21-1189-2017, 2017. a, b
Samani, Z.: Estimating solar radiation and evapotranspiration using minimum climatological data, J. Irrig. Drain. E., 126, 265–267, 2000. a, b
Sanchez-Lorenzo, A., Calbó, J., and Wild, M.: Global and diffuse solar radiation in Spain: Building a homogeneous dataset and assessing their trends, Global Planet. Change, 100, 343–352, https://doi.org/10.1016/j.gloplacha.2012.11.010, 2013. a
Sanchez-Lorenzo, A., Vicente-Serrano, S. M., Wild, M., Calbó, J., Azorin-Molina, C., and Peñuelas, J.: Evaporation trends in Spain: A comparison of class A pan and Piché atmometer measurements, Clim. Res., 61, 269–280, https://doi.org/10.3354/cr01255, 2014. a
Sheffield, J., Wood, E. F., and Roderick, M. L.: Little change in global drought over the past 60 years, Nature, 491, 435–438, https://doi.org/10.1038/nature11575, 2012. a
Thornthwaite, C. W.: An Approach toward a Rational Classification of Climate, Geogr. Rev., 38, 55–94, https://doi.org/10.2307/210739, 1948. a
Tomas-Burguera, M., Jiménez Castañeda, A., Luna Rico, M. Y., Morata, A., Vicente-Serrano, S., González-Hidalgo, J. C., and Beguería, S.: Control de calidad de siete variables del banco nacional de datos de AEMET, in: X Congreso Internacional AEC: Clima, sociedad, riesgos y ordenación del territorio, edited by: Olcina Cantos, J., Rico Amorós, A. M., and Moltó Manterio, E., Alicante, 407–415, 2016. a
Tomas-Burguera, M., Vicente-Serrano, S. M., Grimalt, M., and Beguería, S.: Accuracy of reference evapotranspiration (ETo) estimates under data scarcity scenarios in the Iberian Peninsula, Agr. Water Manage., 182, 103–116, https://doi.org/10.1016/j.agwat.2016.12.013, 2017. a, b, c, d
Tomas-Burguera, M., Beguería, S., Vicente-Serrano, S. M., Reig, F., and Latorre, B.: SPETo (Spanish reference evapotranspiration) [Dataset], https://doi.org/10.20350/digitalCSIC/8615, 2019. a, b
Trajkovic, S.: Hargreaves versus Penman-Monteith, J. Irrig. Drain. E., 133, 38–42, https://doi.org/10.1061/(ASCE)0733-9437(2007)133:1(38), 2007. a
Vanderlinden, K., Giráldez, J. V., and Van Meirvenne, M.: Assessing Reference Evapotranspiration by the Hargreaves Method in Southern Spain, J. Irrig. Drain. E., 130, 184–191, https://doi.org/10.1061/(asce)0733-9437(2004)130:3(184), 2004. a
Vicente-Serrano, S. M., Azorin-Molina, C., Sanchez-Lorenzo, A., Revuelto, J., López-Moreno, J. I., González-Hidalgo, J. C., Moran-Tejeda, E., and Espejo, F.: Reference evapotranspiration variability and trends in Spain, 1961–2011, Global Planet. Change, 121, 26–40, https://doi.org/10.1016/j.gloplacha.2014.06.005, 2014. a, b, c
Vicente-Serrano, S. M., Tomas-Burguera, M., Beguería, S., Reig, F., Latorre, B., Peña-Gallardo, M., Luna, M. Y., Morata, A., and González-Hidalgo, J. C.: A High Resolution Dataset of Drought Indices for Spain, Data, 2, 22, https://doi.org/10.3390/data2030022, 2017. a
Vidal-Macua, J. J., Ninyerola, M., Zabala, A., Domingo-Marimon, C., Gonzalez-Guerrero, O., and Pons, X.: Environmental and socioeconomic factors of abandonment of rainfed and irrigated crops in northeast Spain, Appl. Geogr., 90, 155–174, https://doi.org/10.1016/j.apgeog.2017.12.005, 2018. a