the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 14 Oct 2019
| 14 Oct 2019
seNorge_2018, daily precipitation, and temperature datasets over Norway
Ole Einar Tveito
Andreas Dobler
Ketil Tunheim
seNorge_2018 is a collection of observational gridded datasets over Norway for daily total precipitation: daily mean, maximum, and minimum temperatures. The time period covers 1957 to 2017, and the data are presented over a high-resolution terrain-following grid with 1 km spacing in both meridional and zonal directions. The seNorge family of observational gridded datasets developed at the Norwegian Meteorological Institute (MET Norway) has a 20-year-long history and seNorge_2018 is its newest member, the first providing daily minimum and maximum temperatures. seNorge datasets are used for a wide range of applications in climatology, hydrology, and meteorology. The observational dataset is based on MET Norway's climate data, which have been integrated by the “European Climate Assessment and Dataset” database. Two distinct statistical interpolation methods have been developed, one for temperature and the other for precipitation. They are both based on a spatial scale-separation approach where, at first, the analysis (i.e., predictions) at larger spatial scales is estimated. Subsequently they are used to infer the small-scale details down to a spatial scale comparable to the local observation density. Mean, maximum, and minimum temperatures are interpolated separately; then physical consistency among them is enforced. For precipitation, in addition to observational data, the spatial interpolation makes use of information provided by a climate model. The analysis evaluation is based on cross-validation statistics and comparison with a previous seNorge version. The analysis quality is presented as a function of the local station density. We show that the occurrence of large errors in the analyses decays at an exponential rate with the increase in the station density. Temperature analyses over most of the domain are generally not affected by significant biases. However, during wintertime in data-sparse regions the analyzed minimum temperatures do have a bias between 2 ∘C and 3 ∘C. Minimum temperatures are more challenging to represent and large errors are more frequent than for maximum and mean temperatures. The precipitation analysis quality depends crucially on station density: the frequency of occurrence of large errors for intense precipitation is less than 5% in data-dense regions, while it is approximately 30 % in data-sparse regions. The open-access datasets are available for public download at daily total precipitation (https://doi.org/10.5281/zenodo.2082320, Lussana, 2018b); and daily mean (https://doi.org/10.5281/zenodo.2023997, Lussana, 2018c), maximum (https://doi.org/10.5281/zenodo.2559372, Lussana, 2018e), and minimum (https://doi.org/10.5281/zenodo.2559354, Lussana, 2018d) temperatures.
- Article
(14065 KB) - Full-text XML
- BibTeX
- EndNote





Long-term observational gridded datasets of near-surface meteorological variables are widely used products. In climatology, they have been used for example to monitor the regional climate (Simmons et al., 2017) and to validate and bias-correct climate simulations (Kotlarski et al., 2017). In meteorology, they are used at national meteorological institutes, such as the Norwegian Meteorological Institute (MET Norway), to monitor and report the weather conditions. In hydrology, they are used as external forcing for hydrological and snow modeling (Saloranta, 2012; Skaugen and Onof, 2014; Magnusson et al., 2015).
seNorge_2018 is a collection of four long-term observational datasets over Norway covering the 61-year time period 1957–2017 for daily total precipitation (RR; https://doi.org/10.5281/zenodo.2082320, Lussana, 2018b), daily mean temperature (TG; https://doi.org/10.5281/zenodo.2023997, Lussana, 2018c), and daily minimum (TN) and maximum (TX; https://doi.org/10.5281/zenodo.2559372, Lussana, 2018e) temperatures. It builds upon the previous work on establishing MET Norway's observational datasets (Tveito and Førland, 1999; Lussana et al., 2018a, b) and the core of its statistical interpolation method is the optimal interpolation (OI, Gandin and Hardin, 1965; Kalnay, 2003). A review of the relevant literature for our spatial interpolation applications is given in the paper by Lussana et al. (2018a).
Like the previous versions of seNorge, precipitation and temperature data are provided on a high-resolution grid with 1 km grid spacing in both meridional and zonal directions. seNorge_2018 aims at achieving a higher effective resolution of the analyzed (or predicted) fields than the previous versions. It is worth spending a few words on effective resolution in OI. The difference between grid spacing and resolution is described by Grasso (2000). In the context of numerical modeling, Walters (2000) defines the effective resolution as “the minimum wavelength the model can describe with some required level of accuracy (not defined)” and it concludes that as many as 10 grid points may be required to properly represent a field. As pointed out by Pielke (2001), there is a subjective component in the number of grid points needed to resolve a feature in a field. In contrast to in situ observations which represent point values, our gridded analyses produce areal averages. What this means is that for each grid point, we calculate weighted averages of the nearest observations. The larger the extensions of the spatial support for these averages, the lower the effective resolution of the analysis fields. In short, it is the availability of measurements that determines the highest possible effective resolution, irrespective of the chosen grid spacing, with topographic complexity a compounding factor (Hofstra et al., 2008). The settings used in the interpolation must consider this limitation, and if the same settings are to be used over the whole area, then the subregion of the lowest station density may dictate the effective resolution of the entire domain.
The following definitions of spatial scales are used in the text. The regional scale coincides with the whole domain. Given the importance of the observational network, at an arbitrary point we refer to scales that are defined with respect to the station distribution in its surroundings. The subregional scale (or local scale) defines an area – around the point – that includes dozens of observations (10–100). The small scale defines an area that includes few observations (1–10). The unresolved scale refers to those spatial scales that are smaller than the average distance between a station and its closest neighbors, such that atmospheric fields could not be properly represented by the observational network.
The main original aspect of our research is that the spatial interpolation methods automatically adapt OI settings to the local station density, such that in data-dense regions the spatial supports of the areal-averaged analyses are smaller than in data-sparse regions. In other words, the effective resolution of the analysis fields is higher in data-dense than in data-sparse regions. Because the spatial analysis depends on station density, the integral data influence (IDI: Uboldi et al., 2008; Lussana et al., 2010) has been used as a diagnostic parameter to quantify the effects of station density on the analysis.
The presented research includes several other original aspects. In the case of precipitation, the measurements have been adjusted for the wind-induced under-catch in a way that is consistent with the method proposed by Wolff et al. (2015). A multi-scale OI scheme has been implemented on precipitation relative anomalies with respect to a reference field that captures the field variability at unresolved spatial scales. The reference fields are the monthly totals derived from a regional climate simulation with a resolution of 2.5 km. The climate simulation is based on the dynamical downscaling of the global reanalysis ERA-Interim and it is available for the time period 2003–2016. In the paper by Crespi et al. (2019), it has been demonstrated that the combination of the same model fields with observed data does improve the representation of monthly total precipitation over Norway. Masson and Frei (2014) proved that the use of a reference field as a first guess for the precipitation patterns is also a successful approach in the Alps. They found that daily precipitation over the Alpine region is well represented by using the seasonal precipitation mean as a single predictor field in kriging with external drift.
In the case of temperature, seNorge_2018 is the first seNorge dataset that includes daily minimum and maximum temperatures. The availability of these two additional variables allows for the computation of several more indices for climate variability and extremes, such as the ones reported in the paper by Zhang et al. (2011). The three temperature variables are treated separately with the same interpolation method. With respect to seNorge2 (Lussana et al., 2018b), the regional spatial trend of temperature is obtained as the blending of a much larger number of subregional trends. The analysis method has been implemented on a grid point-by-grid point basis in order to take advantage of a local Kalman gain.
The structure of the paper is as follows. Section 2 presents the observational network and the regional climate simulation used as the precipitation reference. Furthermore, IDI is described and discussed in Sect. 2 as for spatial analysis we regard this parameter as one of the basic properties characterizing a station, such as its altitude or the geographical location. The spatial interpolation methods are described in Sect. 3. An example application for precipitation is presented in Sect. 4. The features of seNorge_2018 daily temperature fields are very much similar to those displayed in Figs. 4–6 in the paper by Lussana et al. (2018b) since the grid is the same and the spatial analyses are based on the same principles. For this reason, example applications for temperature are not included. Section 5 presents the validation of seNorge_2018, which is largely based on cross-validation (CV) and comparison against seNorge2. Then, the results are discussed in Sect. 6.
2.1 Observations
The in situ observations are retrieved from MET Norway's climate database and the European Climate Assessment and Dataset (ECA&D; Klein Tank et al., 2002). The spatial domain covers the Norwegian mainland, plus an adjacent strip of land extending into Sweden, Finland, and Russia in order to reduce boundary effects along the Norwegian border. The observations have been quality controlled by experienced staff and with the help of automatic procedures, such as the spatial consistency test described by Lussana et al. (2010). The variables are defined as follows: TG is the 24 h average between 06:00 UTC of the day, reported as time stamp, and 06:00 UTC of the previous day; RR is the accumulated precipitation over the same time interval as TG, and RR data have been corrected for the wind-induced under-catch of the gauges; TX and TN are, respectively, the maximum and minimum observed temperatures between 18:00 UTC of the day reported as time stamp and 18:00 UTC of the previous day. TG and RR share the same day definition so as to serve hydrological applications (Saloranta, 2016; Skaugen and Mengistu, 2016). As a result of choices made in the past at MET Norway, TX and TN have a different day definition than RR and TG.
The measured RR value (i.e.,RRraw) at an arbitrary location is adjusted for wind-induced under-catch of solid precipitation by means of a procedure similar to the one presented by Wolff et al. (2015):
where TG is extracted from the analysis field (Sect. 3.1) so as to always have a temperature estimate; W is the 10 m wind speed at the station location extracted from a gridded dataset derived from numerical model output. The (NORA10; Reistad et al., 2011) wind speed dataset, which covers the whole time period 1957–2017, has been downscaled onto the 1 km grid by using a quantile mapping approach (Bremnes, 2004) to match the climatology of the high-resolution numerical weather prediction model (AROME-MEtCoOp; Müller et al., 2017). The wind dataset is available for public download at http://thredds.met.no/thredds/catalog/metusers/klinogrid/KliNoGrid_16.12/FFMRR-Nor/catalog.html (last access: 2 October 2019). In the original paper by Wolff et al. (2015), they were considering sub-daily precipitation measurements and both temperature and wind were measured at the same location as the precipitation. We are operating under different conditions and the requirement of having temperature and wind measurements together with precipitation would reduce the number of suitable observations to a very small subset. As a consequence, in Eqs. (1)–(2) we had to use parameter values which are different from those used by Wolff et al. (2015). We have decided to use seNorge version 1.1 (Mohr, 2008, 2009) as a reference for the extreme values returned by the precipitation adjustment. seNorge version 1.1 includes a precipitation correction based on geographical parameters, summarized in site exposure classes such that a systematic increase in precipitation is carried out. The correction presented in Eqs. (1)–(3) takes advantage of wind and temperature estimates but we do not expect the extreme values of those two corrections to differ significantly. The parameter values used in Eqs. (1)–(3), which have been optimized to better match seNorge version 1.1 extremes, are θ=4.7449, β=0.6667, τ1=0.4930, τ2=0.9134, Tτ=0.9134, and sτ=0.7759.
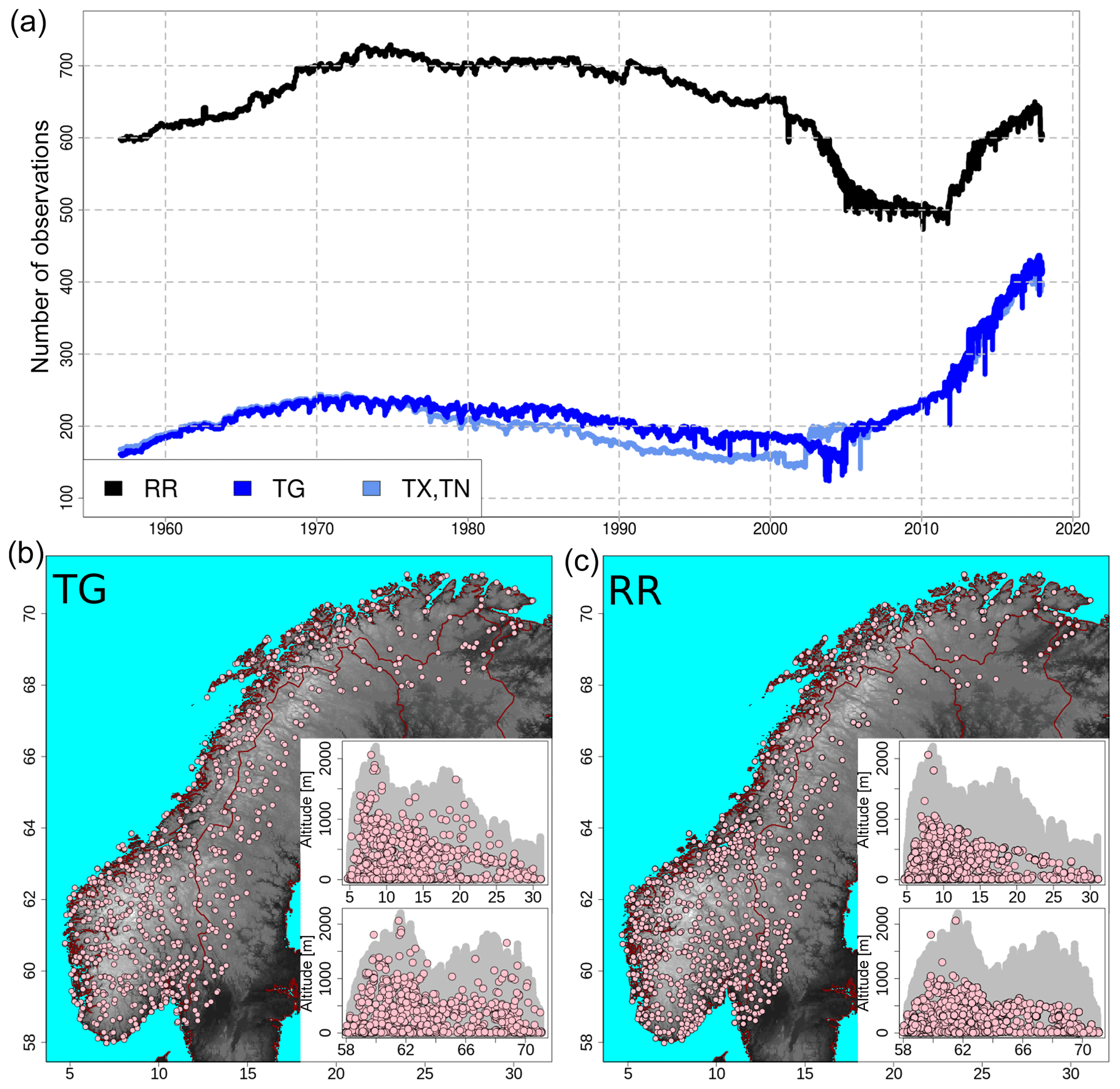
Figure 1The observational network for the four variables: RR, TG, TX, and TN. Panel (a) shows the time series for the number of available observations over the Norwegian mainland. Panels (b, c) show the observational networks for TG (b) and RR (c). TX and TN are not shown because they are similar to TG. The pink dots mark station locations with more than 1 year of data. In the bottom panels, the geographic coordinate system is used and the maps show the domain with topographic information derived from a high-resolution digital elevation model (DEM). For each of the two bottom panels, the two inset graphs show altitude above mean sea level as a function of latitude (top graph) and longitude (bottom graph). In each inset graph, the gray area shows the altitude of the terrain at grid points, while the pink dots are the altitudes of stations.
Figure 1 shows the observational network and its evolution in time. The number of available observations was rather stable from 1957 to 2000. In the following decade, the number of RR observations dropped to 500, which was the minimum value, and then it gradually increased again to over 600 in recent years. The number of temperature observations has been constantly increasing since year 2000, and for 2017 there are about twice as many stations as in 1957. The meteorological stations have been mainly installed to monitor the weather in cities and villages, so the network is denser in urban areas. In the mountainous regions, the digital elevation model (resolution of 1 km2) can reach 2000 m but most of the stations are located below the elevation of 1000 m. A difference in the station density between the southern and the northern portions of the domain is also clearly visible, with a higher density in the south of Norway. Ideally, spatial interpolation would require a denser network of observations where the variance of the field is larger, in order to get a fine-scale representation of the field where it varies the most. However, this is hardly the case in most situations because of the inherent difficulties in station installation and maintenance over complex terrain and in remote areas. As a result, we should expect better performances of the interpolation methods over urban areas and larger analysis uncertainties over data-sparse areas, such as mountainous regions.
2.2 Reference fields for spatial interpolation of precipitation
The reference fields are derived from long-term averages calculated from the output of a high-resolution numerical model. The reference datasets used for precipitation are based on hourly precipitation provided by the climate model version of HARMONIE (version cy38h1.2), a seamless NWP model framework developed and used by several national meteorological services. HARMONIE includes a set of different physics packages adapted for different horizontal resolutions. For the high-resolution, convection-permitting simulations in this case, the model has been set up with AROME physics (Seity et al., 2011) and the SURFEX surface scheme (Masson et al., 2013). The climate runs have been carried out within the HARMONIE script system, covering the period July 2003 to December 2016 on a 2.5 km grid over the Norwegian mainland. More details on the climate model can be found in Lind et al. (2016) and references therein and at http://www.hirlam.org/index.php/documentation (last access: 2 October 2019). The numerical model does not include measurements from the network of rain gauges. The mean monthly total precipitation fields have been computed considering the available hourly data and they have been used as reference fields for the spatial interpolation of precipitation as described in Sect. 3.2.
Over our domain, we have chosen not to use precipitation climatologies derived by observational gridded datasets as the reference because in some regions the observational network is extremely sparse (Fig. 1).
2.3 Integral data influence
IDI is similar to the degrees of freedom introduced by Cardinali et al. (2004) and it has also been used to evaluate the distribution of weather stations (Horel and Dong, 2010). In practice, IDI is obtained as the result of an OI performed by arbitrarily assigning a value of 1 to the observations (i.e., maximum amount of available information) and the reference value of 0 to the background (i.e, basic amount of information available everywhere). The analytical function that usually represents the background error correlation in OI, in the case of IDI, represents the station influence on the analysis according to a predefined metric. This metric is defined as a function of the geographical parameters. For an arbitrary point in space, the geographical parameters are stored in a vector r having four components: latitude, longitude, altitude, and land area fraction (i.e., fraction of land in the 1 km square box centered at the point). The land area fraction is introduced here and used in Sect. 3.1. Functions are applied to a pair of points: d(r,s) returns the horizontal (radial) distance in kilometers between r and s; z(r,s) returns their absolute elevation difference; w(r,s) returns their absolute land area fraction difference. The correlation function between two points r and s is based on Gaussian functions of the form
where u() is an arbitrary function, such as the ones previously defined, applied to the points; D is a reference length scale governing the decreasing rate. We have chosen to model the station influence using Gaussian functions. For TG, TX, and TN, the station influence is factorized into the product of two Gaussian functions: one depends on distances, such that in Eq. (4) u=d() and D=50 km; the other depending on elevation differences, with u=z() and D=200 km. In the case of RR, the station influence depends only on distances; therefore u=d() and D=10 km. The values of the de-correlation length scales used for temperature are consistent with the findings of Sect. 3.1. For precipitation, the value chosen is representative of the smallest spatial scales used in multi-scale OI of Sect. 3.2.
For the purpose of evaluation in Sect. 5, the CV IDI at station locations (i.e., IDI at a station location computed without considering the presence of that station) is introduced to link the CV statistics to the IDI of the hypothetical grid point represented by a station location.
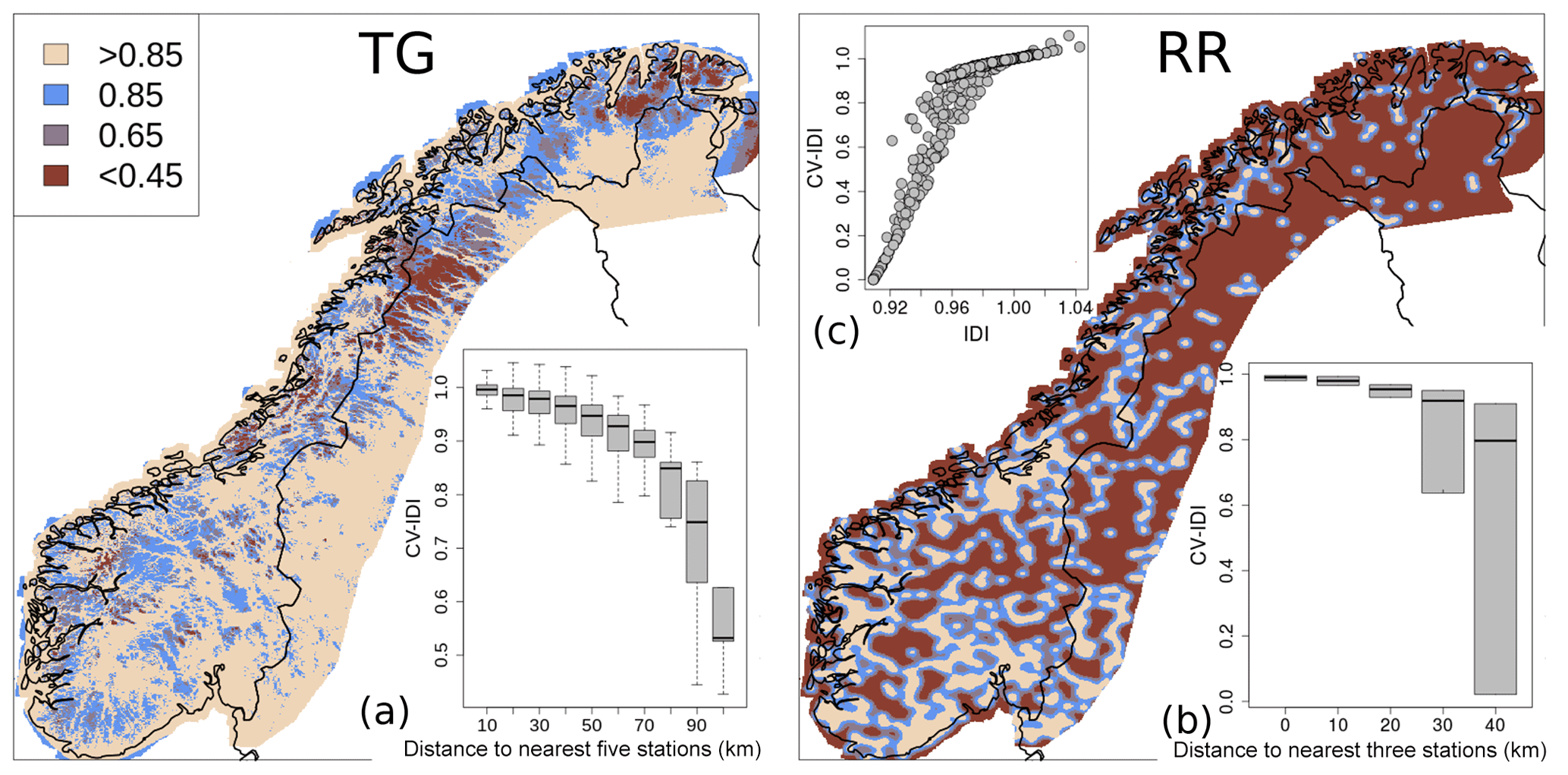
Figure 2A representation of the observational network useful for spatial analysis of TG (a) and RR (b, c). As for Fig. 1, TX and TN are not shown because they are similar to TG. The displayed fields are the integral data influence (IDI) at grid points (same color scale for both fields). Panels (a) (TG, inset) and (b) (RR, inset bottom) show the cross-validation IDI (CV IDI) as a function of the distance to the nearest stations. The distribution of CV IDI is shown by boxplots, where each gray box represents a sample distribution: the thick black horizontal line is the median; the gray box width is the interquartile range; the whiskers extend to the tails. In panel (c) (RR, inset top), CV IDI and IDI are compared and CV IDI is shown as a function of IDI.
In the two maps of Fig. 2, the IDI is shown for TG and RR based on the station distributions shown in Fig. 1. The IDIs for TX and TN are very similar to TG. In the vicinity of an observation the IDI field is approximately equal to 1 whereas for data-sparse areas its value is close to 0. The IDI and CV IDI values have been arbitrarily divided into four classes: values smaller than 0.45 define observations/grid points in data-sparse regions (i.e., where the station influence on the analysis is very limited); values larger than 0.85 define observations/grid points in data-dense regions (i.e., where the station influence on the analysis is substantial), then two transition classes between data-dense and data-sparse regions have been defined.
For temperature, elevation plays a predominant role and even only a few stations at higher elevations can provide a reasonable approximation of the subregional near-surface temperature lapse rate. Figure 2 shows that the regions where our observational network is sparser are the northernmost part of Norway (i.e., above latitude 69∘ N) and the Scandinavian Mountains between latitude 66 and 68∘ N. For precipitation, we have decided to not consider elevation in the spatial analysis because we are aware that our network is very sparse at higher elevations (see Fig. 1).
For precipitation, the IDI map in Fig. 2 shows values larger than 0.85 for those regions where the observational network can reconstruct patterns in the analysis fields where the small scales have a resolution of approximately 10 km. The largest continuous regions with IDI larger than 0.85 are located in the southern part of the domain (i.e, below latitude 65∘ N) and mostly along the coast.
Fig. 2a and b show the close relationships between CV IDI and the station density. As shown by Fig. 2c, at station locations IDI has a smaller range of values than CV IDI. In fact, even an isolated station constitutes more information than the background alone, while an isolated grid point must have IDI equal to 0 as it is CV IDI at an isolated station.
The notation used is based on both Ide et al. (1997) and Sakov and Bertino (2011). The number of grid points is m. The number of observations is p. Uppercase bold symbols are used for matrices, lowercase bold symbols for vectors, and italic symbols for scalars. For an arbitrary matrix X, Xj means the jth column, Xi, the ith row, and Xij the element at the ith row and jth column. For an arbitrary vector x, xi denotes the ith element. The superscripts at the upper left-hand corner of a symbol identify analysis, a; background, b; and observation, o. Upper accents have been used too. In the case of temperature, where we iterate over the grid points, the notation indicates that matrix X is valid for the ith grid point and in this sense we may refer to it as a local matrix. In the case of precipitation, where we iterate over spatial scales, those length scales are indicated with Greek letters and the notation indicates that matrix X is obtained as a function of the spatial scale of α km. Upper accents are not used only for matrices; for instance the in situ observations are stored in the p vector yo but in the following we will refer to the vector of the nearest observations to the ith grid point.
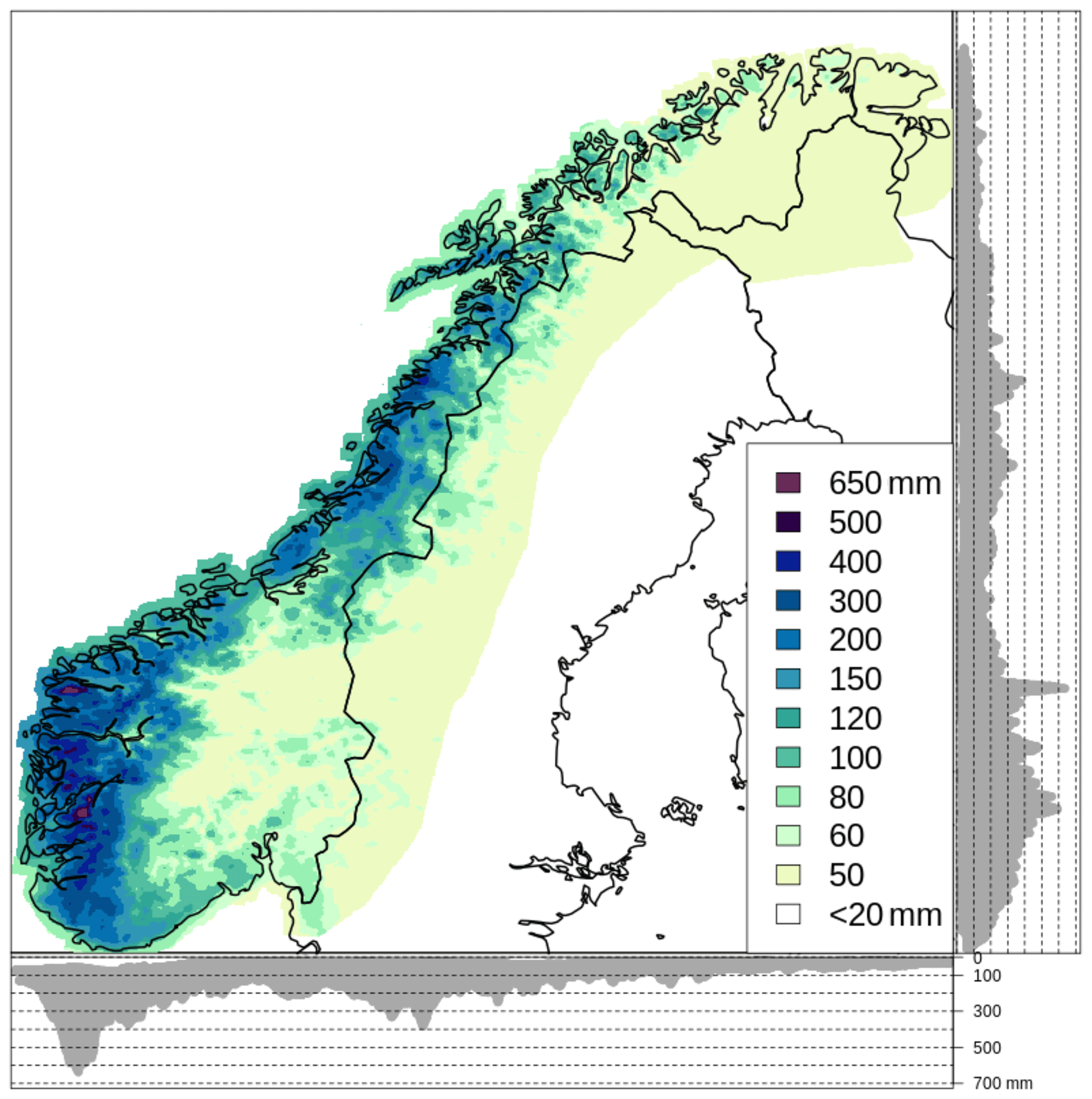
Figure 3Precipitation reference field for October, that is, xref in Eq. (10), used for the spatial analysis of RR for the day 24 October 1998 (Sect. 4). The lateral and bottom panels in both graphs show the projection of the reference precipitation values at grid points on the y and the x axes, respectively.
3.1 Statistical interpolation of temperature
The same interpolation scheme is used for the mean, the maximum, and the minimum daily temperature. The physical consistency among the three variables is assured by post-processing the independently analyzed datasets and for each grid point we make sure that TN is always smaller than or equal to TG and TX is always greater than or equal to TG. The cross-checking is further discussed in Sect. 6.1.
The spatial interpolation is implemented on a grid point-by-grid point basis. It combines a regional pseudo-background field, which is the weighted average of numerous subregional fields, with the observations. The temperature analysis at the generic ith grid point is written as
and are vectors of the nearest stations to the ith grid point.
The local Kalman gain in Eq. (5) is
is the x identity matrix and is the ratio between the constant observed () and pseudo-background () error variances that has been set to 0.5, as for seNorge2 (Lussana et al., 2018b). The local pseudo-background error correlation matrices are defined on the basis of the correlation function between a pair of points ρT(rj,rk) as
such that the correlation between the jth grid point and the kth station is . Analogously, the correlation between the jth station and the kth station is . The Gaussian functions f are defined in Eq. (4). A formulation similar to Eq. (7) has been used in the paper by Lussana et al. (2009); in that case the land area fraction has been replaced by the land use. wmin sets the minimum value for the factor related to land area fraction when w(ri,rj) is maximum (i.e., equals to 1). Dz and wmin are fixed over the domain, while is allowed to vary between grid points, although with some restrictions. In an ideal situation of a very dense observational network, one may consider relying on adaptive estimates for the three parameters. This is not the case for our station distribution, so we have opted for a “hybrid” configuration (i.e., Dz and wmin fixed, Dh adaptive) that would return robust estimates. The impact of large land area fraction differences on ρT is less dramatic that those of large horizontal or elevation differences and it also impacts only a limited number of stations along the coast. Eventually, we have manually set wmin=0.5 to achieve the desired effect of attenuating the influence of coastal areas over inland areas and vice versa, while at the same time avoiding the introduction of sharp gradients between those two regions. The optimization procedure for and Dz is described in the following section.
The pseudo-background in Eq. (5) is the blending of n subregional pseudo-backgrounds and it is in many ways similar to those described by Lussana et al. (2018b). Each subregional pseudo-background is defined by a centroid and it includes only the 30 stations closest to this centroid. The pseudo-background field with centroid at rc is the m vector and its value at the ith grid point is . The seNorge_2018 domain has been divided on a 50×50 grid, each cell is a 24 km by 31 km rectangular box, and the nodes (i.e., centers of the cells) are the “candidate” centroids. If a node is inside the domain and has at least 30 stations in a neighborhood of 250 km, then it is a suitable centroid. Those 30 temperature observations are used to estimate a subregional pseudo-background field as a function of the elevation only. The analytical function used to model the vertical profile of temperature is the one proposed by Frei (2014) for the alpine region and its parameters have been obtained by fitting the function to the aforementioned 30 observations. We assume that 30 observations can provide a reliable fitting. The generic cth pseudo-background field is derived directly from the digital elevation model by assuming that the cth subregional vertical temperature profile is valid for the whole domain. By using a 50×50 grid, the number of subregions n is usually between 500 and 600 and there are significant overlaps between neighboring subregions, such that the continuity of the regional pseudo-background is guaranteed. Finally, is a weighted average of n values:
where the weights at the ith grid point are the n IDI values (Sect. 2) and is computed considering only those stations included in cth subregional pseudo-background field. The settings used in the IDI calculation are similar to those used for precipitation in Fig. 2, in the sense that the station influences decays with horizontal distance only and its de-correlation length scale is set to 27.5 km, that is, the average of a box width and height on the 50×50 grid.
The optimization of Dz and of Eq. (7) is based on the statistics of the innovation (i.e., observation minus background) at station locations. As described by Desroziers et al. (2005), the elements of the background error covariance matrix at station locations, which is modeled by us as , should match the innovation sample covariances. In Tables 1–3, the values of the parameters determining are shown for a selection of years (1960, 1970, 1980, 1990, 2000, 2010) in the assumption of a constant Dh (i.e., , ). Note that we have also added the average number of stations available for a specific year, the average distances between them, and the estimated observation error variance, which is not strictly required to compute S and it is set to be half of in our analysis. The TN error variances are significantly higher than those for TG and TX, thus indicating that TN is a more challenging variable to interpolate. Dh and Dz do not differ significantly among TG, TX, and TN, probably because the common observational network constitutes the major constraint in determining their value. This justifies our choice to set Dz=210 m for the three variables. The parameter values in the tables are more influenced by the majority of stations that are located in station-dense areas. Therefore, the value of Dh=55 km can be considered a suitable reference for the minimum allowed value. The procedure used for the estimates is similar to the one described for the regional pseudo-background field. is a weighted average as the one reported in Eq. (8) where is replaced by the cth length scale, which is constant for all grid points. For the cth subregion this length scale is set to the average distance between a station and its nearest three stations, provided that this distance is larger than Dh=55 km, otherwise Dh=55 km is used. In this way, the analysis in data-sparse regions is the result of an interaction between a few (approximately four) stations. At the same time, we take advantage of data-dense areas to locally increase the effective resolution of the analysis without destroying the continuity of the field. Note that the use of extremely different Dh values between data-dense and data-sparse areas (i.e., with differences around 1 order of magnitude or more) would result in a rather confusing field to look at. In those cases it would be better to split the domain into sub-domains and operate independently on them.
Table 1TG annual statistics: “n” is the average number of stations; “d” (km) is the average distance between a station and its nearest third station; Dh (km), Dz (m), ((∘C)2), and ((∘C)2) are the spatial interpolation parameters defined in Sect. 3.1. For each year, the optimal values of the interpolation parameters are obtained by imposing the constraint and considering the 1-year statistics of the innovation (observation minus background, Sect. 5).

Table 2TX annual statistics. See Table 1 caption for further details.
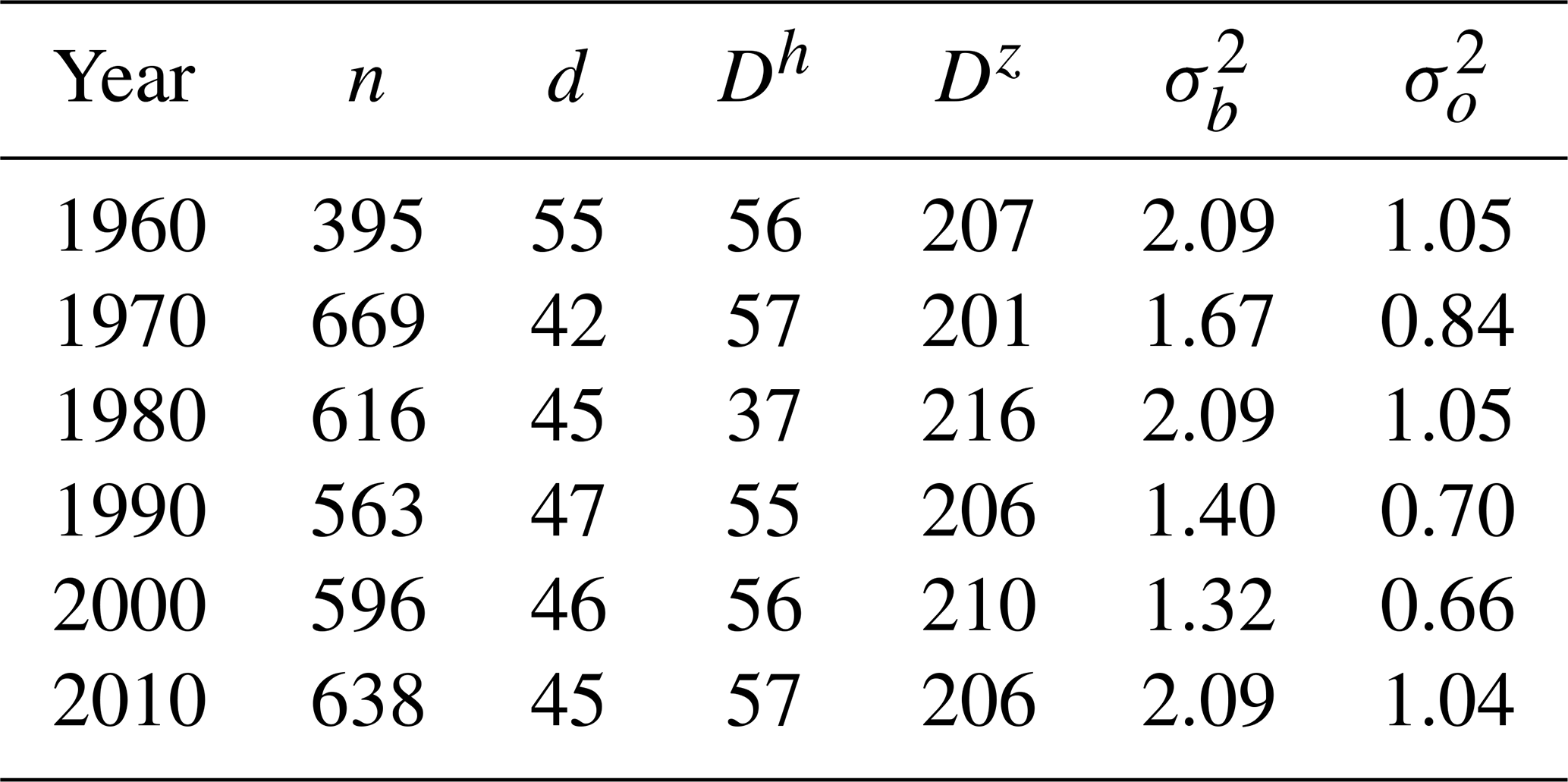
Table 3TN annual statistics. See Table 1 caption for further details.
3.2 Statistical interpolation of precipitation
The multi-scale OI analyses are the results of successive approximations of the observations over a sequence of decreasing spatial scales that at station locations converge to the observed values.
The interpolation scheme is not applied directly to the RR values (the vector of the raw observed values adjusted for the wind-induced under-catch is indicated as yrr) but to their anomalies relative to a reference field of monthly precipitation (see Sect. 2, indicated with the abbreviation ref in the following). In addition, a Box–Cox transformation with the power parameter set to 0.5 is used and the transformation is indicated with the function g(). A similar transformation has been suggested by Erdin et al. (2012), though in the context of a combination of radar with gauge data. The ith element of yo used in multi-scale OI is
The analysis procedure can be written as
where the three fundamental operations are (1) the composition of several applications of the same statistical interpolation model down a hierarchy of spatial scales of , such that the results of a model application are used to initialize the successive one, ∘ stands for model composition, and ℳη stands for the application of the statistical model to the largest length scale of η km, and is the average of the yo elements; (2) the Box–Cox inverse transformation g−1(); (3) the elementwise multiplication of vectors ⊙ to transform the relative anomalies into RR values and at the same time include the effects of unresolved spatial scales. Ideally, the sequence of spatial scales to be used in Eq. (10) should be bounded between a very large scale (e.g, half the largest domain dimension) and a fine scale corresponding to the average distance between two stations in data-dense areas. The number of scales in between those two extremes is not critical for the final results, provided that they are enough to guarantee a continuous analysis field in all situations. For seNorge_2018, we are using approximately 100 scales with a minimum of 2 km and a maximum of 1400 km. According to Thunis and Bornstein (1996) and Orlanski (1975), those spatial scales range from regional synoptic down to the lower boundary of the mesoscale. The sequence is unevenly spaced as the difference between two consecutive scales is somewhat proportional to their values.
The step-by-step description of the model for two arbitrary consecutive length scales of β km and α km (with β>α) is
In order to reduce the multi-scale OI computational expenses, the original 1 km grid is aggregated onto a new coarser grid, with an aggregation factor equal to the integer value nearest to (α∕2) km. The aggregation groups several smaller rectangular boxes into a bigger one (e.g., if α=8 km then 16 of the 1 km-by-1 km boxes are aggregated into a single box measuring 4 km by 4 km). The analysis at scale β is used as the background for scale α in an OI scheme. The analysis values are transferred between the two non-matching grids by the operator of Eq. (11), that is, a bilinear interpolation mapping vectors on the (coarser) β-grid to vectors on the (finer) α-grid. The observation operator of Eq. (13) is also a bilinear interpolation transforming vectors on the α-grid to p vectors. ε2 is set to 1, which means that observations and background are assumed the have the same error variances. The background error correlation matrices of Eq. (12) are defined on the basis of the correlation function ρR:
The Gaussian function f is defined in Eq. (4) and the notation is similar to Eq. (7). Note that the length scales enter multi-scale OI of Eq. (10) through the correlation function of Eq. (14).
An OI scheme such as the one presented in Eqs. (11)–(14) is realizing a low-pass filter whose cutoff wavelength is approximately α km (Uboldi et al., 2008) so every iteration over a smaller spatial scale returns a field with more fine-scale details in it. For a given element of the observation vector, there may be a critical scale at which the background coincides exactly with the observed value such that its contribution to the innovation in Eq. (13) (i.e., the term in parentheses) is equal to zero. As a consequence, the analysis values in the surroundings of that observation are unlikely to change in the passage between scales α and β and those analysis values are also unlikely to change over the subsequent iterations because all the available information has still been used by the interpolation scheme. For the ith grid point, the critical scale can be defined as the spatial scale α where the last significant variation in the interpolated relative anomaly has occurred with respect to the value (or equivalently ) obtained for the immediately preceding scale β. The critical scale is variable across the domain and depends on both the spatial structure of the precipitation field and the local station density. The smaller the critical scale, the noisier and rougher the analysis field. Typically, stratiform precipitation would lead to larger critical scales than convective precipitation. In any case, the small scales determined locally by the observational network, as defined in the Introduction, pose lower limits to the critical scale.
An example of application of the spatial interpolation method described in Sect. 3.2 is given in this section. We have chosen to illustrate the analysis procedure applied to the day 24 October 1998, that is, one of the days within the period 1957–2017 with the highest value of averaged observed precipitation and where almost all the gauges have measured precipitation.
The reference field for October (see Sect. 2) is the prior information used in our spatial analysis and it is shown in Fig. 3. The highest precipitation values occur in the western part of Norway and a precipitation gradient between the coast and inland areas is evident.
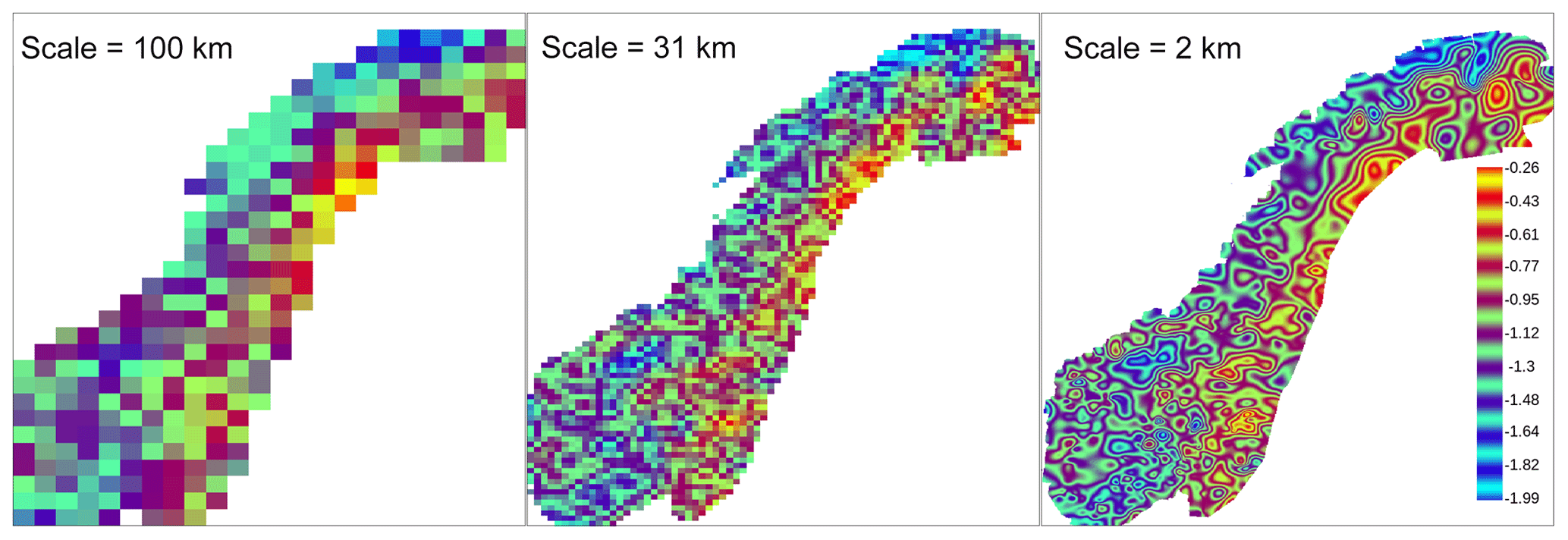
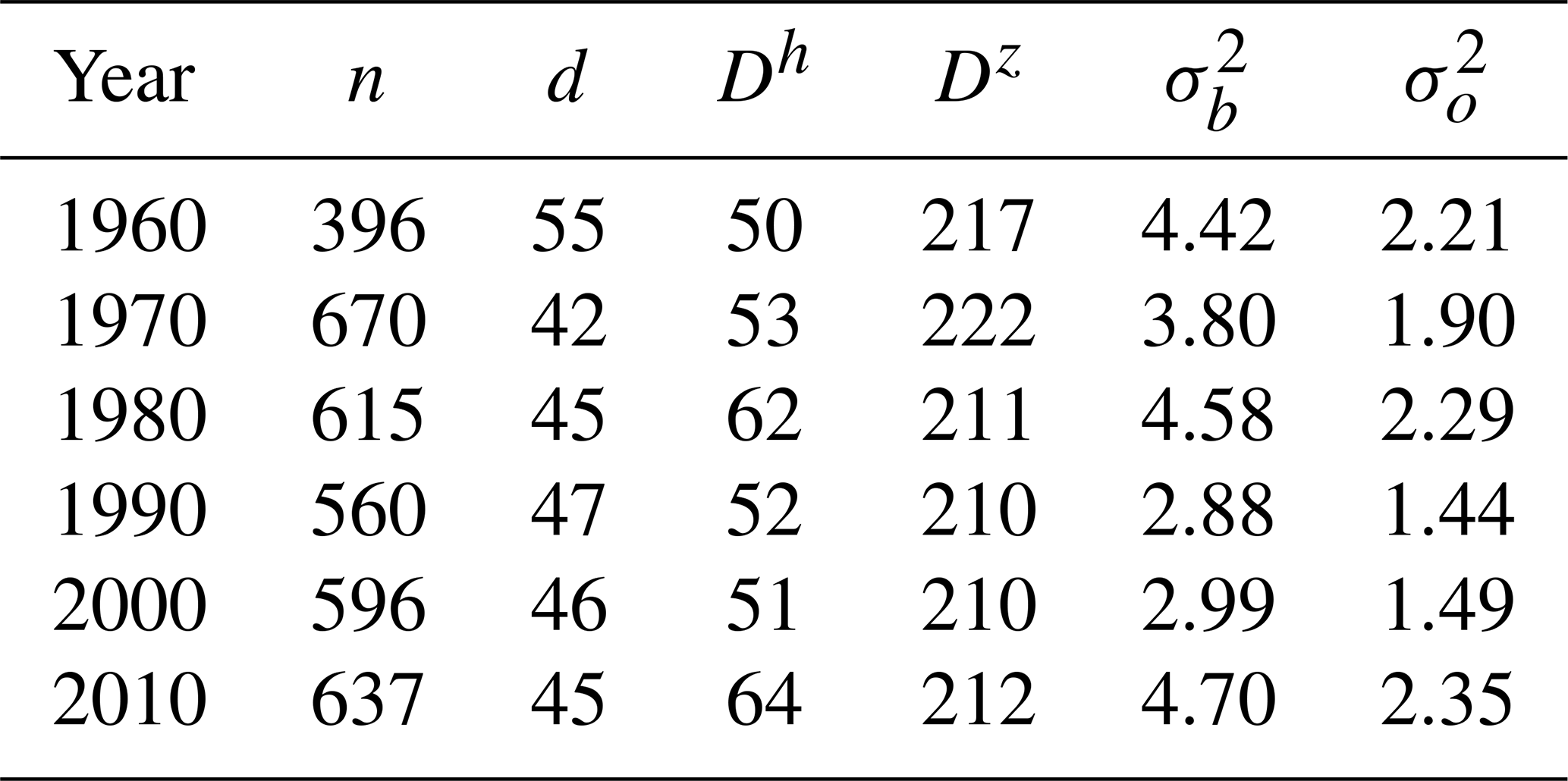
Figure 4RR from 24 October 1998. Statistical interpolation of relative anomalies (dimensionless units) over different spatial length scales with the scheme reported in Eqs. (11)–(13). The interpolation loops over a sequence of 91 decreasing spatial scales: 100 km is the 17th; 31 km is the 69th; 2 km is the 91st. The fields shown are three different values (Eq. 13) for α=100, α=31, and α=2 km. In each of the three cases, the interpolation is performed over a regular grid with the resolution of the integer value nearest to α∕2, that is, 50, 15, and 1 km. The color scale highlights the details in the field and it is the same for the three maps.
The first of the three fundamental steps in Eq. (10) is the iterative application of OI for the Box–Cox transformed relative anomalies over a sequence of decreasing spatial scales. We are looping over 91 scales and in Fig. 4 three of those scales are shown. As a result of the transformation, the analysis fields on the maps are not straightforward to interpret as they do not correspond to precipitation. For this reason, we have chosen an ad hoc color scale that highlights the patterns in the fields more than the differences among values. For each scale, the OI is implemented as in Eqs. (11)–(13). The smaller the spatial scale, the more fine-scale details the OI will represent and, as a consequence, the finer the grid used. For the scales of 100, 31, and 2 km, the interpolations are performed over grids of 50, 15, and 1 km, respectively. From the coarser scale represented in Fig. 4, it is only possible to have a rough idea of the final field as this is only the 17th iteration of the 91 totals. At the scale of 31 km, that is iteration 69, the main features of the field are easier to recognize: the largest values are in the eastern part of the domain, where the reference values are smaller; in the middle of southern Norway, the field reaches its minimum. The smallest scale is equal to 2 km. With reference to the station distribution in Fig. 1, the patterns become smaller in data-dense regions while the largest ”blobs” occur in data-sparse regions. As one may expect, the patterns on the 1 km grid in Fig. 4 match the spatial structure of the patterns in Fig. 2.
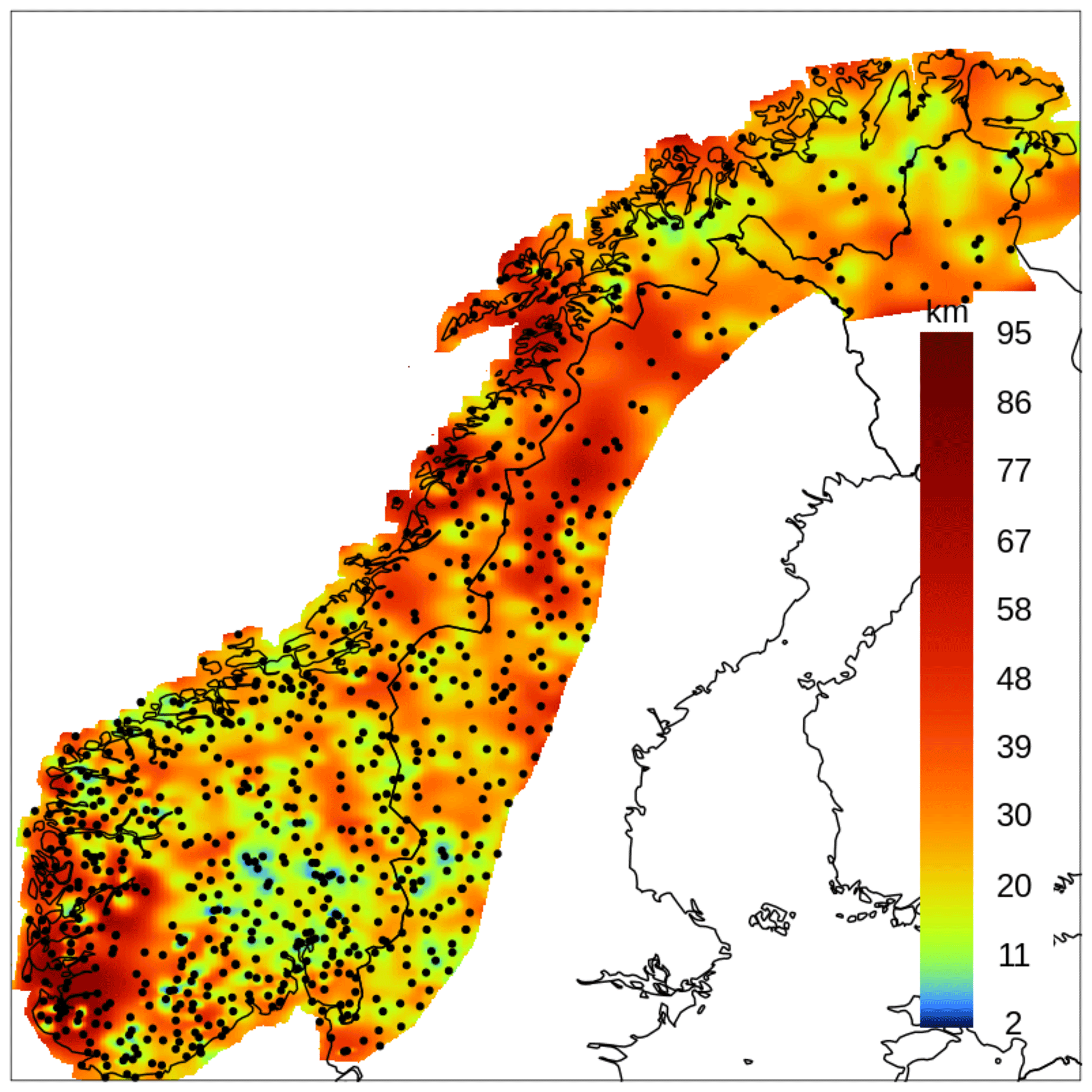
Figure 5RR from 24 October 1998. “Critical” scale (Sect. 3.2; shaded field, values are in kilometers) for the statistical interpolation scheme reported in Eqs. (11)–(13) given the observational network used (black dots mark the station locations). The critical scale varies for each grid point. For the ith grid point, the critical scale is the spatial scale α where the last significant variation in the interpolated relative anomaly has occurred with respect to the value (or equivalently ) obtained for the immediately preceding scale β. A variation is considered significant when it is larger than 0.01 (dimensionless units) or 1 %. The largest values of the critical scale may indicate either a data-sparse region or a region where stratiform precipitation is occurring. On the other hand, the smallest values occur in data-dense regions and they indicate regions where the field is highly variable over short distances (e.g., thunderstorms).
Figure 5 shows the critical scale defined in Sect. 3.2 for the day 24 October 1998. The critical scale is related to variations in the analyses between subsequent scales of the multi-scale OI scheme presented in Eqs. (11)–(13). Examples of such analyses are the fields shown in Fig. 4. Specifically, for each grid point, the field in Fig. 5 shows the spatial scale where the last significant variation in the interpolated precipitation relative anomaly has occurred. In practice, with reference to Eqs. (11)–(13), the critical scale at the ith grid point is the largest scale α where the absolute value of the difference is smaller than 0.01 (dimensionless units) or 1 %. In particular, it is interesting to know where the precipitation field represents features at the smallest spatial scales included in the multi-scale OI (i.e., from 2 to 20 km). Those spatial scales correspond to the meso-γ atmospheric scale and are suitable to properly represent thunderstorms, for example (Thunis and Bornstein, 1996). It is less relevant to distinguish between spatial scales above 30 km and up to 200 km as they belong to the same meso-β scale, e.g, fronts, thunderstorm groups. Fig. 5 emphasizes the gradient between meso-γ and meso-β scales. In the data-sparse regions marked as red in Fig. 2, the station network poses a constraint on the smallest scales the analysis can represent and, as a consequence, the critical scales belong to the meso-β scale, regardless of the precipitation type. On the other hand, where the observational network is dense, the critical scale assumes a broad range of values, that is, from 2 to 100 km, depending on the local characteristics of precipitation (e.g., stratiform or convective). In regions where the critical scale is within the meso-γ scale, the precipitation field is highly variable over relatively short distances and this might indicate the occurrence of convective precipitation.
Figure 6 shows the RR analysis field as derived from Eq. (10). It is a combination of the reference field shown in Fig. 3 and the multi-scale OI field shown in Fig. 4 for the scale of 2 km. In particular, the local variations in precipitation in almost-data-void regions (e.g, some mountainous areas in southern Norway that are marked as red regions in Fig. 2) are mostly due to the reference field.
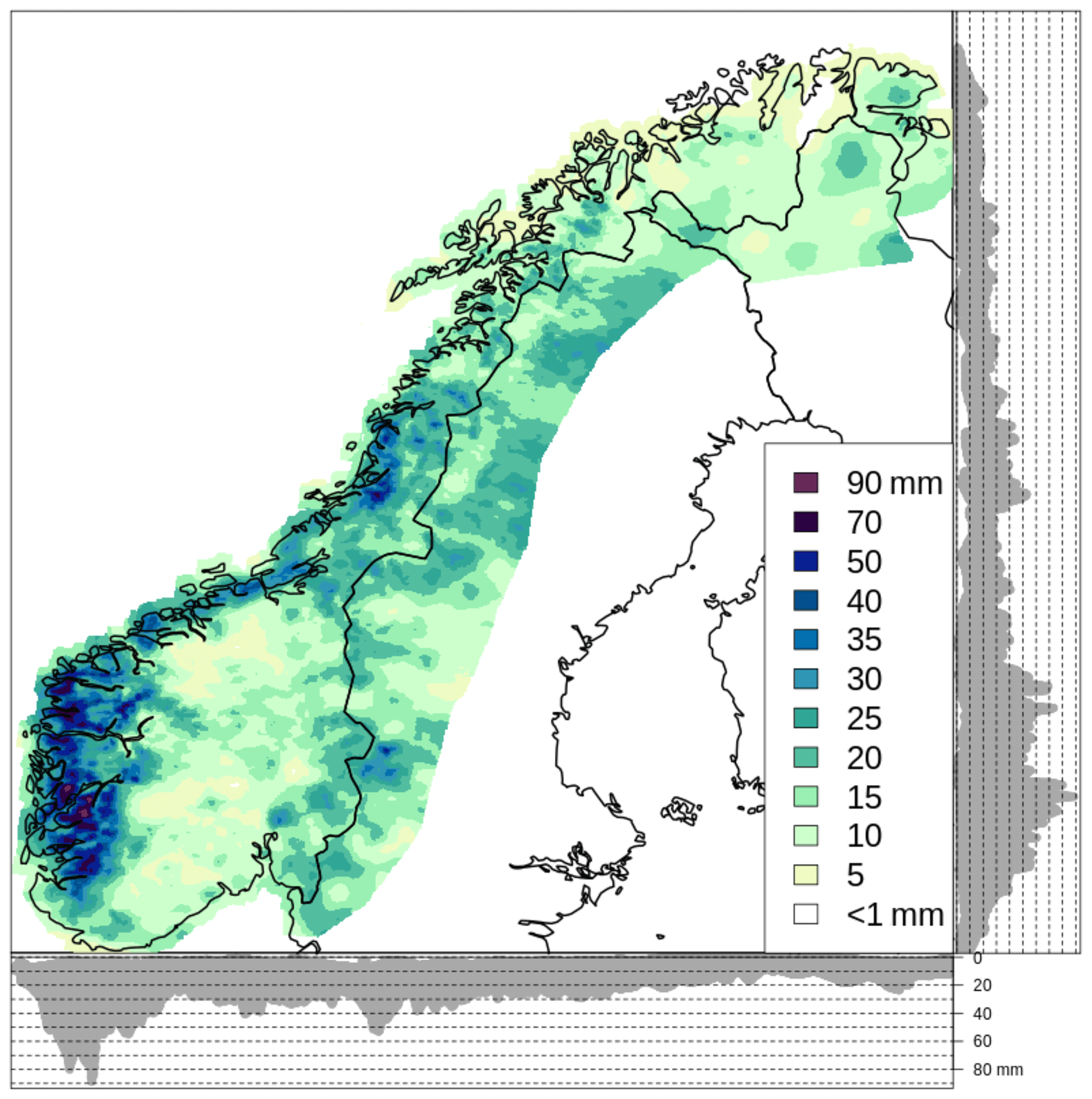
Figure 6RR analysis field xa of Eq. (10) from 24 October 1998. The lateral and bottom panels in both graphs show the projection of the differences on the y and the x axes, respectively.
The evaluation is based mostly on CV exercises and comparison against the seNorge2 datasets of RR and TG. The cross-validation analysis (i.e., CV analysis) is the analysis value at a station location obtained considering a selection of the available observations that does not include the one measured at that location. If CV is applied systematically to all stations and it includes all the remaining observations then it is called leave-one-out cross-validation (LOOCV).
The summary statistics of the following variables are used: CV analysis residuals (i.e, CV analyses minus observations), innovations (i.e., background minus observations), and analysis residuals (i.e, analyses minus background). The CV analysis, background, and analysis are evaluated through the statistics of CV analysis residuals, innovations, and analysis residuals, respectively. Note that the background is not considered in the verification of precipitation. At a generic station location, CV analysis and background are independent of the observation, while the analysis has been computed using the observation. As a consequence, the statistics of CV analysis residuals and innovations have similar interpretations. The CV analysis residual distributions are used in place of the unknown analysis error distributions at grid points. The innovation distributions are used to investigate the properties of the background error at grid points. On the other hand, the statistics of analysis residuals reveal the filtering properties of the statistical interpolation at station locations that are related to the observation representativeness error (Lussana et al., 2010; Lorenc, 1986; Desroziers et al., 2005). The mean absolute error (MAE) and the root-mean-square error (RMSE) quantify the average mean absolute deviation and the spread, respectively, of a variable.
For temperature, we use LOOCV. The comparison between the statistics of CV analysis residuals and innovations quantifies the improvement of the analysis over the pseudo-background at grid points. The fraction of errors (i.e., absolute deviations) greater than 3 ∘C has been used as a measure of the tails of the distribution of deviation values. Note that the threshold of 3 ∘C is used in MET Norway's verification practice to define a significant deviation that undermines the user's confidence in the forecast.
For precipitation, LOOCV is computationally too expensive. Thus, for each day a random sample of 10 % of the available stations have been reserved for CV and they are not used in the interpolation. Because precipitation errors follow a multiplicative rather than an additive error model (Tian et al., 2013), large errors for precipitation are defined as absolute deviations between CV analysis and observation greater than 50 % of the observed value.
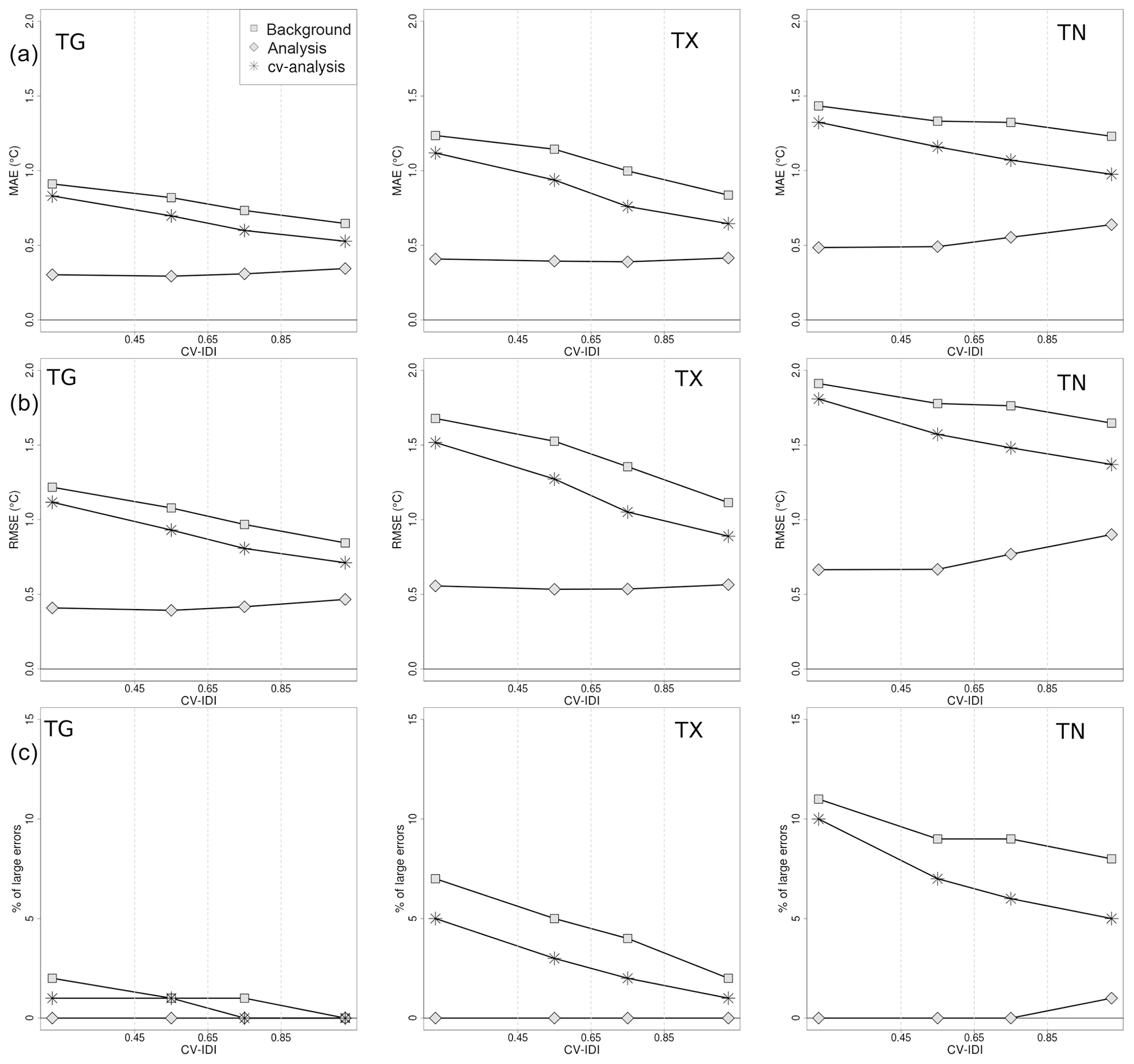
Figure 7TG, TX, and TN verification scores as a function of CV IDI for the summer seasons (June–July–August) of the 61-year time period 1957–2017. With reference to the definitions introduced in Sect. 5, the scores for the analysis are based on the analysis residuals, for the CV analysis on the CV analysis residuals, and for the background on the innovation. In the top row, the mean absolute error (MAE) is shown. In the middle row, the root-mean-square error (RMSE) is shown. In the bottom row, the percentage of large errors is shown. A large error is defined as the absolute value of innovation or residual larger than 3 ∘C.
5.1 Temperature
5.1.1 Summary statistics of the verification scores at station locations
In Figs. 7–8 the TG, TX, and TN evaluation results are shown for summer and winter, respectively, as a function of CV IDI (Sect. 2.3). The whole 61-year time period is considered. For each of the four CV IDI classes (Sect. 2.3), the mean value of the score is displayed. The CV analysis and background always score better in data-dense areas, as expected. The analysis evaluation scores do not vary much with respect to variations in station density, thus indicating that the observation representativeness error is rather constant for all stations. This result supports the use of a single value characterizing the whole observational network for ε2 in Eq. (6).
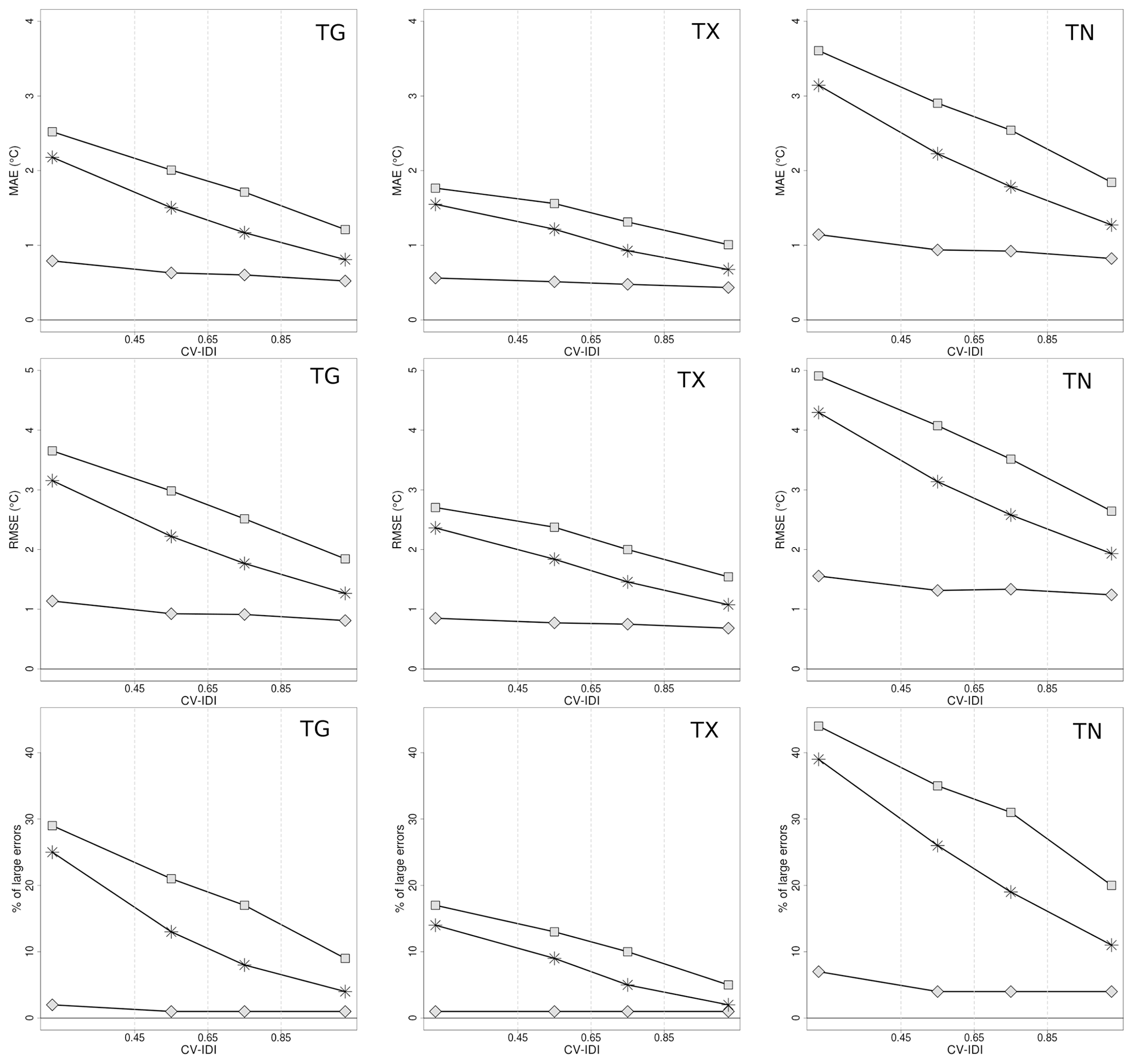
Figure 8TG, TX, and TN verification scores as a function of CV IDI for the winter seasons (December–January–February) of the 61-year time period 1957–2017. See Fig. 7 caption for further details.
For all variables, the spatial interpolation scheme generally performs better during summer than winter when small-scale processes (e.g., strong temperature inversion) are more frequent. The TG analysis error distribution at grid points, as estimated by CV analysis residuals, shows that during the summer, the MAE is between 0.5 and 1 ∘C and its RMSE is also around 1 ∘C, and errors larger than 3 ∘C are unlikely even in data-sparse regions; during winter, MAE and RMSE double their values and the differences between data-dense and data-sparse regions are larger, with the probability of having large errors being approximately 25 % in data-sparse regions. The TX analysis error behaves similarly to TG. Note that the spatial interpolation method during summer performs better on TG than on TX, while in winter the opposite occurs. The distribution of the TN analysis error at grid points has a much larger spread than those of TG and TX. The TN RMSE is between 1.5 and 2 ∘C in summer and up to approximately 4 ∘C during winter in data-sparse regions. The tail of the TN distribution is also longer and large errors are more frequent than for the other daily temperatures. At the same time, the average bias (MAE) is also larger for TN.
5.1.2 seNorge_2018 and seNorge2 comparison of TG
The seNorge_2018 spatial interpolation procedure builds upon seNorge2. Several modifications have been made, though keeping the scale-separation approach. In seNorge_2018 a single function has been used to model the subregional vertical profile, instead of the three different functions used in seNorge2. At the same time, in seNorge_2018 the blending of subregional fields into a regional pseudo-background field is based on a much larger number of subregional fields.
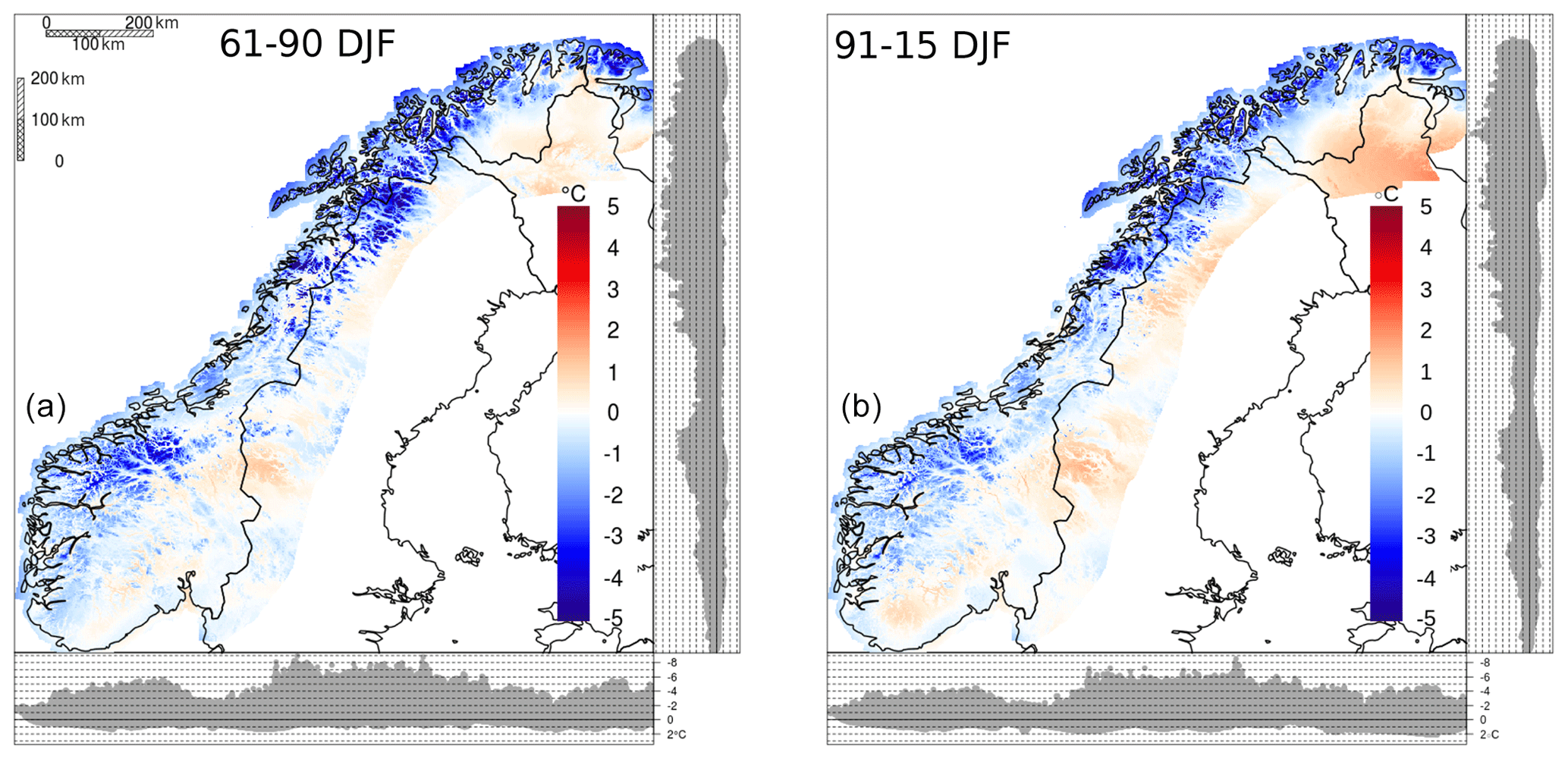
Figure 9TG, mean difference between seNorge_2018 and seNorge2 daily analysis during winter (December–January–February). (a) The 30-year period 1961–1990 is considered. (b) The mean is based on the 25-year period 1991–2015. The lateral and bottom panels in both graphs show the projection of the values at grid points on the y and the x axes, respectively.
In Fig. 9 the TG dataset is compared with seNorge2 over two multi-year time periods for the winter season. In the other seasons (not shown here) the differences are almost always between −2 and 1 ∘C. For most of the Norwegian mainland, seNorge_2018 is colder than seNorge2, with the larger differences on the mountaintops and along the coast in the north. The two periods show similar patterns; however for the 1991–2015 period there are some regions where seNorge_2018 is warmer than seNorge2, such as the plateau in the north between Finland, Russia, and Norway; along the border between Sweden and Norway; and in the mountains of southern Norway.
The variations between seNorge_2018 and seNorge2 having the most significant impacts on the differences shown in Fig. 9 are in the OI settings. seNorge_2018 includes the land area fraction as an additional parameter in Eq. (7) and this improvement causes the differences along the coastline, where stations having significantly different land area fractions are less correlated between each other. By considering only stations along the coast and CV analysis residual data from 1957 to 2017, seNorge2 has MAE =0.79 ∘C and RMSE =1.12 ∘C, while seNorge_2018 has MAE =0.7 ∘C and RMSE =1.03 ∘C. If compared to seNorge2, seNorge_2018 reduces the bias along the coast by 10 % and the RMSE by 8 %.
The evident differences between the two datasets are in the mountains, where seNorge_2018 often presents warmer valley floors and colder ridges. In particular, according to Fig. 9, the highest peaks of the Scandinavian Mountains are on average up to 9 ∘C colder, while the valley floors are a few degrees warmer. Those differences can be explained by (1) the reduced Dz value in seNorge_2018 (Dz=210 m instead of Dz=600 m as in seNorge2), which narrows the vertical layer where OI adjustments are effective; therefore temperatures in data-sparse high-altitude regions mostly coincide with background values. The differences can also be explained by (2) the modified procedure for the pseudo-background calculation that realizes a smoother transition between neighboring subregional pseudo-background fields. By considering all the stations and CV analysis residual data from 1957 to 2017, seNorge2 has MAE =0.81 ∘C and RMSE =1.18 ∘C, while seNorge_2018 has MAE =0.76 ∘C and RMSE =1.18 ∘C.
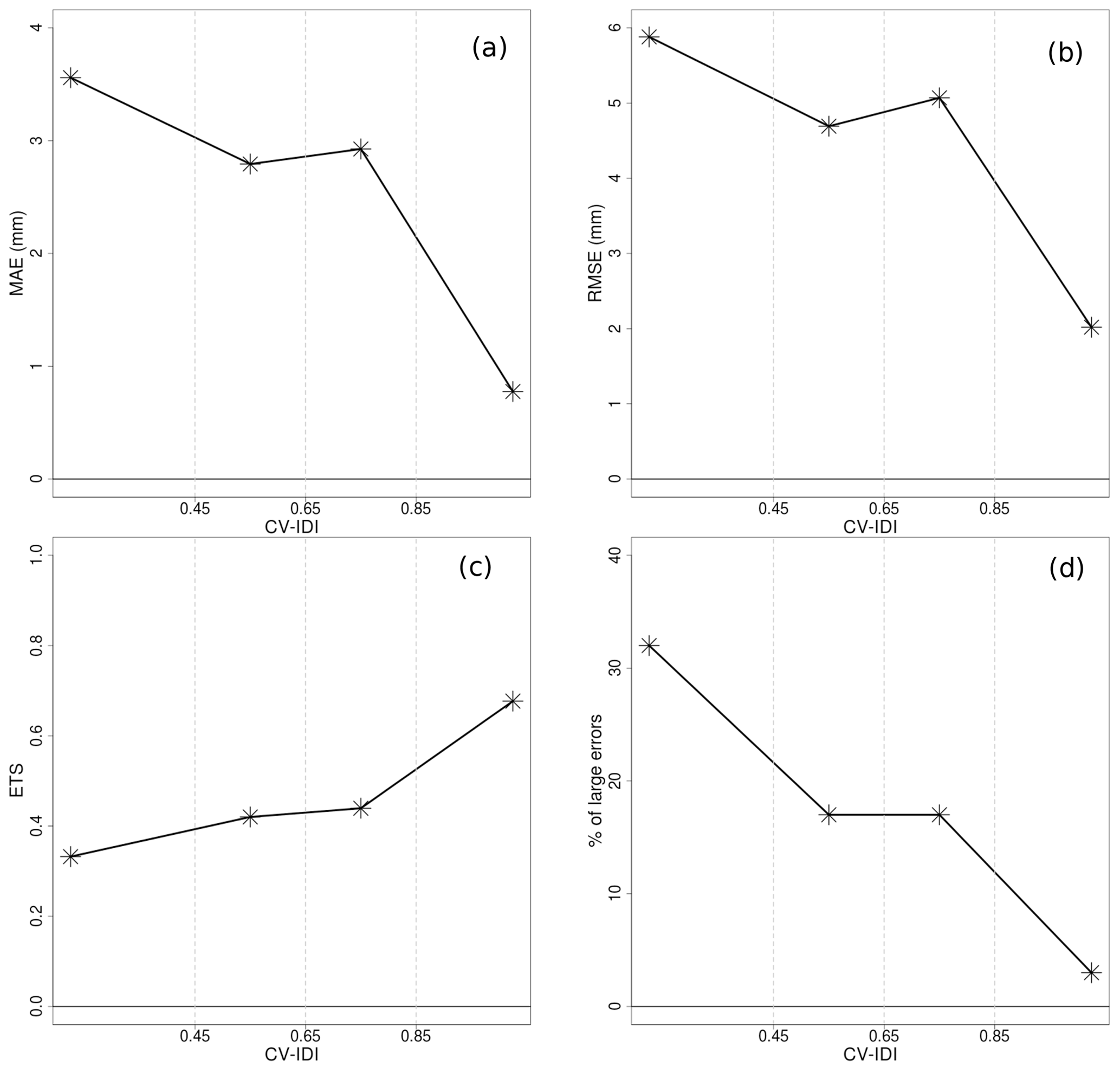
Figure 10RR and CV analysis verification scores as a function of CV IDI for the 61-year time period 1957–2017. The terminology used is introduced in Sect. 5. Panel (a) shows mean absolute error (MAE) considering only observations greater than 1 mm d−1. Panel (b) shows root-mean-squared error (RMSE) considering only observations greater than 1 mm d−1. Panel (c) shows the equitable threat score (ETS) with a threshold equal to 1 mm d−1. Panel (d) shows the percentage of large errors in the case of intense precipitation. Intense precipitation is defined as an observed value greater than 10 mm d−1. A large error is defined as the absolute value of a CV analysis residual larger than 50 % of the observed value.
5.2 Precipitation
5.2.1 Summary statistics of the verification scores
In Fig. 10, the RR dataset is evaluated through the statistics of CV analysis residuals. In general, the spatial interpolation performs significantly better for station-dense areas, then the performances degrade faster for data-sparse regions as shown by the MAE and RMSE for observations greater than 1 mm d−1. The ability in distinguishing between precipitation and no precipitation is shown by the equitable threat score (ETS) with a threshold of 1 mm d−1. In station-dense areas the fraction of correct predictions, accounting for hits due to chance, is approximately 70 %, while the ETS goes down to 0.4 in data-sparse regions. With respect to intense precipitation (i.e., observed values greater than 10 mm d−1), the probability of having large errors is less than 5 % in data-dense areas and around 30 % in data-sparse areas.
The close relationship between the terrain and the annual total precipitation is shown in Fig. 11, where values up to 4700 mm yr−1 are reconstructed along the Norwegian coast.

Figure 11Annual total precipitation as derived by summing RR. (a) The mean annual total precipitation based on the 61-year period 1957–2017: the lower precipitation class includes values smaller than 400 mm; the upper precipitation class includes values between 3500 and 4700 mm. (b) Mean annual total precipitation difference between seNorge_2018 and seNorge2 based on the 51-year period 1957–2015. On each graph, the lateral and bottom panels show the projection of the values at grid points on the y and the x axes, respectively.
5.2.2 seNorge_2018 and seNorge2 comparison
Figure 11 shows the differences between seNorge_2018 and seNorge2 mean annual total precipitation in the period 1957–2015. On average, seNorge_2018 has significantly higher precipitation values than seNorge2, especially in data-sparse mountainous regions, and this is due to (i) the correction of rain-gauge data for the wind-induced under-catch, which increases the observed precipitation mostly during winter, and (ii) the modified statistical interpolation scheme that uses more information in data-sparse regions, which often tends to increase the precipitation analysis when compared to seNorge2.
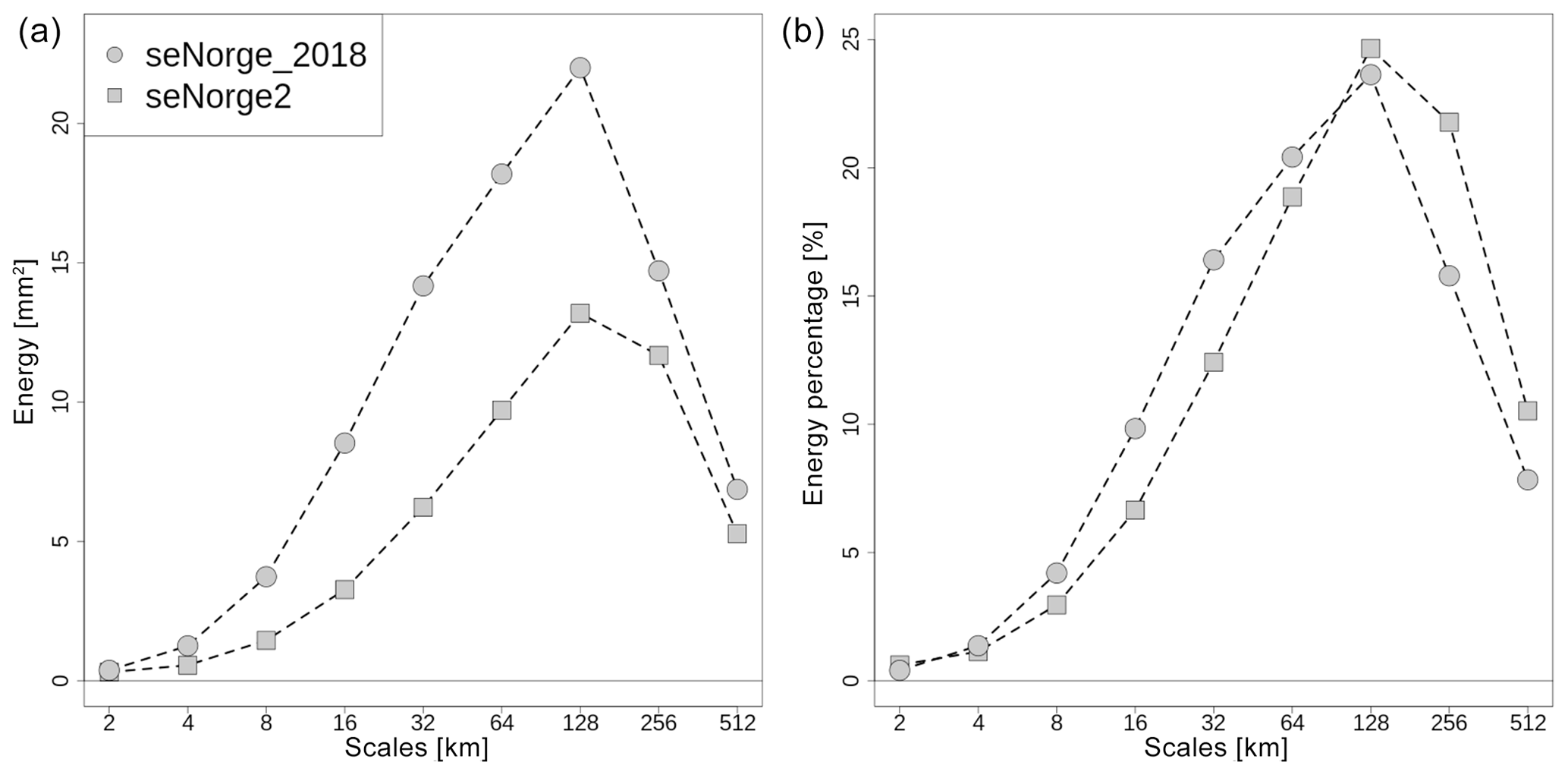
Figure 12Scale decomposition of precipitation energy based on 2-D discrete Haar wavelet transformation (Sect. 5.2.2). (a) The averaged energy as a function of the spatial scale for seNorge_2018 and seNorge2. (b) The averaged percentage of energy as a function of the spatial scale for the same datasets. The statistics is based on the 25 % of cases with the highest values of averaged precipitation over the domain.
For precipitation, we have stated in the Introduction that seNorge_2018 uses a reference to increase the effective resolution of the field, compared to the resolution given by the spatial distribution of the observational network alone. In the context of forecast verification, Casati et al. (2004) decompose precipitation fields on different spatial scales using a two-dimensional discrete Haar wavelet decomposition. As described in the paper by Casati (2010), this wavelet decomposition can be used to study the average energy per cell (hereafter energy) of the scale components of precipitation, where the energy is defined as “the average of the field grid point squared value”. Figure 12 shows the mean energy of the scale components for seNorge_2018 and seNorge2 based on the 25 % of cases with higher values of averaged precipitation over the domain within the time period 1957–2017. Figure 12a shows the energies, where seNorge_2018 has more energy than seNorge2 for all scales, a result that is in agreement with Fig. 11. The shapes of the two energy distributions are similar, with a maximum at the scale of 128 km and a gradual decrease in the energy for smaller spatial scales. However, Fig. 12b shows that the energy percentages for seNorge_2018 are systematically larger than for seNorge2 for scales smaller than 128 km. Because the effective resolution of seNorge2 is determined by the observational network only, the results presented in Fig. 12 support our initial statement on the increased effective resolution of seNorge_2018.
5.3 Occurrence of large errors as a function of the station density
Next we discuss more in detail the relationships between the occurrence of large errors, as they have been defined at the beginning of Sect. 5, and the observation densities. We have investigated those relationships for both temperature and precipitation aiming at quantifying the impacts on the analysis quality due to variations in the station distribution.

Figure 13Expected percentages of large errors on the grid (dimensionless units) based on the summary statistics of the analyses and the spatial distribution of stations of the observational network. The color scale is the same for all the maps. Wintertime (DJF) temperatures are considered, and large errors are defined as deviations between analysis and unknown truth larger than 3 ∘C. All precipitation data have been considered, and large errors are deviations between analysis and unknown truth larger than 50 % of the analysis value when the analysis value is greater than 10 mm d−1. The insets show the relation between IDI and percentage of large errors: the dots correspond to the percentage of large errors observed at station locations (on the x axis, CV IDI instead of IDI); the dashed lines are the best-fit functions used to infer the expected percentage of large errors at grid points.
In Fig. 13, the expected percentage of large errors at grid points is shown for all variables. In the case of temperature, the season of the year is an important factor in determining the quality of the analyses and in Fig. 13 we have considered only the winter seasons, that is, when errors are larger. For precipitation, the season of the year is a less compelling factor, compared to the station density, in determining the quality of the analysis. Then, the whole RR dataset is taken into account in Fig. 13. The close relationships between CV IDI and the occurrence of large errors are evident from the scatterplots in Figs. 8 (bottom row) and 10d. The same relationships are also represented in the scatterplots in the panels on the bottom left of each of the maps in Fig. 13. Note that for summertime temperatures, the relationship between CV IDI and occurrence of large errors is shown in Fig. 7 (bottom row). If we define the occurrence of large error (err) as a function of CV IDI (x) as err(x), then the points in the scatterplots of Fig. 13 represent the actual occurrence of large errors at station locations and the lines are the best fit to the points of the Gaussian function:
The estimated large error occurrence at grid points is obtained by replacing the CV IDI with the IDI fields (Fig. 2) in Eq. (15). The three parameters of the bell curve shape are the value of the curve's peak, a; the position of the center of the peak, b, and c which controls the width of the bell. The Gaussian function provides reasonably good fits to the points; the relationship between the station density and the analysis quality is non-linear and the analysis performances decay much faster in data-sparse than in data-dense regions. The parameter values for the three variables are TG a=703.012, , c=1.123; TX a=856.420, , c=1.114; and TN a=448.39, , c=1.431. The probability of having a large analysis error is remarkably small over the domain for TX, while for TN such large errors are quite common. The situation for TG is somewhat in between those two extreme cases and large regions of the domain are unlikely to present large errors. Once again, it is evident that the worst performances occur in those regions characterized by complex terrain and low station density, such as the mountainous region between Norway and Sweden in the northern part of the domain.
As for temperature, the expected percentage of large errors over the precipitation grid is shown in Fig. 13. The three parameters of Eq. (15) for RR are a=50.438, , and c=0.846. The elevation is not considered in the IDI definition for RR, so the map looks rather different than the temperature maps. Furthermore, by setting D=10 km in Eq. (4) (instead of D=50 km as for temperature) we have imposed a fast transition between data-dense and data-sparse regions. For data-dense regions, the expected percentage of large analysis errors for intense precipitation is less than 10 %. For data-sparse regions, the percentage of large errors is approximately 40 %.
Because the presented statistical interpolation methods automatically adapt to the local observation density, the user of the seNorge_2018 dataset must be aware that (i) the comparison between different subregions over the domain is influenced by the respective local station densities, and (ii) variations in the observational network over time will affect temporal trends derived from this dataset (Masson and Frei, 2016).
For the four variables, we have investigated the variations in the performances of our interpolation schemes between two different time periods, 1961–1990 (61–90) and 1991–2015 (91–15). The evaluation scores are similar to the ones presented in Sect. 5 for the whole 61-year time period, thus indicating that the ongoing climate change does not have a significant impact on the reconstruction skills of our statistical interpolation schemes.
The three main factors determining the quality of the temperature datasets are the season of the year, the station density and the terrain complexity. The last two factors are correlated, as shown by Figs. 1–2. TN is the most challenging variable to represent, possibly because atmospheric processes at unresolved spatial scales occur more frequently for this variable than for the others. It is worth pointing out that Fig. 7 shows that during the summer TN has a smaller representativeness error in data-sparse than in data-dense regions, even though the differences are rather small. It is not clear whether this is due to the spatial interpolation scheme or to the occurrence of specific atmospheric phenomena (e.g, urban heat island effect). In general, our results indicate that a denser station network is needed to deliver TN products having the same quality as TG and TX by using the statistical interpolation method presented in Sect. 3.1. Future developments of the method may also improve the representation of TN, such as (1) consider the differences between TG and TN, instead of TN; (2) develop a relationship for the vertical profile of TN, which would replace the one proposed in Sect. 3.1; and (3) use numerical model output fields (e.g., from reanalysis) in addition to the observed data.
The two main factors determining the quality of the precipitation dataset are the station density and the terrain complexity. The season of the year seems to have a smaller impact on the verification scores.
With respect to seNorge2, seNorge_2018 presents several methodological improvements and two additional variables, TX and TN. Furthermore, it should be mentioned that there had been variations in the observational datasets used for the production of the two gridded datasets. Even though the data sources are the same for both seNorge datasets, seNorge2 is based on an observational dataset that was produced in 2016, while seNorge_2018 benefits from the latest efforts in data collection and quality control made by MET and the ECA&D team. The verification results show that seNorge_2018 temperature predictions are on average more accurate than seNorge2, especially along the coast. With respect to the predictions of precipitation, as described in the seNorge2 paper by Lussana et al. (2018a), this dataset is likely to underestimate precipitation so we have designed seNorge_2018 to return higher precipitation values because this would better agree with the Norwegian water balance and eventually improve the results of hydrological simulations based on seNorge_2018 than for seNorge2. This last point needs to be verified in the near future. In Sect. 5.2.2, it has been demonstrated that seNorge_2018 has a higher effective resolution than seNorge2. In conclusion, we recommend the use of seNorge_2018 instead of seNorge2 for both TG and RR.
6.1 TG, TX, and TN cross-checking
The cross-checking is mentioned at the beginning of Sect. 3.1 and it is performed on the analyses. TG is used as a reference value for both TX and TN since (a) the construction of the pseudo-background field is based on a vertical profile relationship that has been developed for TG; (b) TG is expected to be a more robust variable than TX and TN (in the sense defined by Lanzante (1996)) because it is an averaged value instead of an extreme. For each grid point, we check whether TN (TX) is smaller (greater) than TG. Wherever the condition is not satisfied, TN (TX) is replaced by TG.
Because of the 12 h offset in the definitions of TG and either TX or TN, the cross-check can be wrong. Nevertheless, it is a useful check to identify those situations where the interpolation of daily extremes is not convincing. In fact, despite the offset in the definitions of the 24 h aggregation period, for a typical day TN is smaller than TG and TX is greater than TG. We have found very rare exceptions to these rules in the surroundings of station locations. In the vast majority of cases, the cross-check flags those grid points in the mountains (i.e., far from station locations) where the extrapolation of the vertical profile cannot be adjusted by means of observed data, which are located in large part on the valley floors (Fig. 1). As a result, the simulated daily extremes are affected by significant uncertainties and we use TG as a reference value to assess the significance of those uncertainties. When the cross-check reports possible violation of the physical consistency, our choice is to “mask out” the analyses of daily extremes and at the same time we propose TG as an alternative.
The number of grid points flagged by the cross-checking vary seasonally and it is higher in winter and lower in summer. In the case of TN, the cross-check flags on average 9 % of the grid points in winter and 1 % in summer. In the case of TX, the cross-check flags on average 7 % of the grid points in winter and 1 % in summer.
Future developments will focus on improving the cross-check, in order to properly handle those exceptional situations that are currently erroneously flagged as physical inconsistencies among the three variables.
The spatial interpolation software is available (https://doi.org/10.5281/zenodo.2022479, Lussana, 2018a).
The open-access datasets are available for public download as follows:
-
daily total precipitation (https://doi.org/10.5281/zenodo.2082320, Lussana, 2018b);
-
daily mean temperature (https://doi.org/10.5281/zenodo.2023997, Lussana, 2018c);
-
daily maximum temperature (https://doi.org/10.5281/zenodo.2559372, Lussana, 2018e);
-
daily minimum temperature (https://doi.org/10.5281/zenodo.2559354, Lussana, 2018d).
seNorge_2018 is updated daily by MET Norway and the most recent data are available at http://thredds.met.no/thredds/catalog/senorge/seNorge_2018/catalog.html (Norwegian Meteorological Institute, 2019a). Furthermore, it is possible to access the maps of precipitation or temperature analyses via
-
http://www.xgeo.no (Norwegian Water Resources and Energy Directorate, 2019a). Select All Data from the main menu, then Weather, then seNorge_2018 precipitation or seNorge_2018 temperature.
-
http://thredds.met.no/thredds/catalog/senorge/seNorge_2018/catalog.html (Norwegian Meteorological Institute, 2019a). Select a file (e.g., http://thredds.met.no/thredds/catalog/senorge/seNorge_2018/Archive/catalog.html?dataset=senorge/seNorge_2018/Archive/seNorge2018_2010.nc, Norwegian Meteorological Institute, 2019b), then Viewers and Godiva2.
seNorge_2018 provides 61-year (1957–2017) datasets of daily mean, maximum, and minimum temperatures, as well as daily total precipitation, over Norway and parts of Finland, Sweden, and Russia. The plan at MET Norway is to update the historical dataset once a year, while at the same time provisional daily estimates for the current year are computed every day. MET Norway has an open data policy and all the datasets, as well as most of the observations used in the calculations, are available for public download via its web services.
The observational datasets have been obtained through statistical methods that build upon our previous works. The interpolation schemes automatically adapt their settings to the local station density and this allows for a higher effective resolution in data-dense areas, while in data-sparse regions the analysis is always the estimate of at least a few stations.
The main factors determining the quality of the temperature analysis are the season of the year, the station density and the terrain complexity. In the case of precipitation, those factors are the station density and the terrain complexity. Because of the importance of the combination of station density and terrain, we have widely used the IDI concept in our evaluation.
The new seNorge_2018 shows significant differences when compared to its predecessor seNorge2, for both TG and especially RR. While first qualitative evaluations indicate that this is an improvement, an indirect evaluation where seNorge_2018 would be used as the forcing data for snow- and hydrological modeling is needed to confirm this.
seNorge_2018 is MET Norway's first observational dataset providing TX and TN from 1957. The temperature analysis has the largest errors during winter and the TN is the most challenging variable to represent. For TG and TX, large analysis errors are expected only in winter and limited to almost data-void areas such as mountain tops. TN may present large analysis errors more often than TG and TX and for larger portions of the domain, especially in mountainous regions.
To fill commonly occurring spatial gaps for RR in data-sparse regions, the interpolation uses monthly fields of a high-resolution numerical model and adjusts this to an optimal fit with the measurements that are available in the area. As a result, seNorge_2018 has a finer effective resolution than seNorge2. The ability of the method to correctly distinguish between precipitation and no-precipitation depends critically on the station density. In the north, the sparser observational network is associated with a high occurrence of large analysis errors. The evaluation shows that large analysis errors are unlikely in the data-dense regions of southern Norway, even for intense precipitation.
CL developed the spatial analysis methods and code for statistical interpolation and created the datasets. OET developed the analysis methods. AD performed the simulations with the climate model. KT developed the code for the daily updates of seNorge_2018. CL prepared the manuscript with contributions from all co-authors.
The authors declare that they have no conflict of interest.
This research has been partially funded by the Norwegian project “Felles aktiviteter NVE-MET tilknyttet nasjonal flom- og skredvarslingstjeneste”.
This research has been supported by The Norwegian Water Resources and Energy Directorate and The Norwegian Meteorological Institute (project “Felles aktiviteter NVE-MET tilknyttet: nasjonal flom- og skredvarslingstjeneste”).
This paper was edited by Scott Stevens and reviewed by two anonymous referees.
Bremnes, J. B.: Probabilistic wind power forecasts using local quantile regression, Wind Energy, 7, 47–54, https://doi.org/10.1002/we.107, 2004. a
Cardinali, C., Pezzulli, S., and Andersson, E.: Influence-matrix diagnostic of a data assimilation system, Q. J. Roy. Meteorological Society, 130, 2767–2786, https://doi.org/10.1256/qj.03.205, available at: https://rmets.onlinelibrary.wiley.com/doi/abs/10.1256/qj.03.205 (last access: 7 October 2019), 2004. a
Casati, B.: New Developments of the Intensity-Scale Technique within the Spatial Verification Methods Intercomparison Project, Weather Forecast., 25, 113–143, https://doi.org/10.1175/2009WAF2222257.1, 2010. a
Casati, B., Ross, G., and Stephenson, D. B.: A new intensity-scale approach for the verification of spatial precipitation forecasts, Meteorol. Appl., 11, 141–154, https://doi.org/10.1017/S1350482704001239, 2004. a
Crespi, A., Lussana, C., Brunetti, M., Dobler, A., Maugeri, M., and Tveito, O. E.: High-resolution monthly precipitation climatologies over Norway (1981–2010): Joining numerical model data sets and in situ observations, Int. J. Climatol., 39, 2057–2070, https://doi.org/10.1002/joc.5933, 2019. a
Desroziers, G., Berre, L., Chapnik, B., and Poli, P.: Diagnosis of observation, background and analysis-error statistics in observation space, Q. J. Roy. Meteor. Soc., 131, 3385–3396, https://doi.org/10.1256/qj.05.108, 2005. a, b
Erdin, R., Frei, C., and Künsch, H. R.: Data transformation and uncertainty in geostatistical combination of radar and rain gauges, J. Hydrometeorol., 13, 1332–1346, 2012. a
Frei, C.: Interpolation of temperature in a mountainous region using nonlinear profiles and non-Euclidean distances, Int. J. Climatol., 34, 1585–1605, https://doi.org/10.1002/joc.3786, 2014. a
Gandin, L. S. and Hardin, R.: Objective analysis of meteorological fields, vol. 242, Israel program for scientific translations Jerusalem, 1965. a
Grasso, L. D.: The differentiation between grid spacing and resolution and their application to numerical modeling, B. Am. Meteorol. Soc., 81, 579–580, https://doi.org/10.1175/1520-0477(2000)081<0579:CAA>2.3.CO;2, 2000. a
Hofstra, N., Haylock, M., New, M., Jones, P., and Frei, C.: Comparison of six methods for the interpolation of daily, European climate data, J. Geophys. Res.-Atmos., 113, 1–19, https://doi.org/10.1029/2008JD010100, 2008. a
Horel, J. D. and Dong, X.: An evaluation of the distribution of Remote Automated Weather Stations (RAWS), J. Appl. Meteorol. Clim., 49, 1563–1578, 2010. a
Ide, K., Courtier, P., Ghil, M., and Lorenc, A.: Unified notation for data assimilation: operational, sequential and variational, Practice, 75, 181–189, 1997. a
Kalnay, E.: Atmospheric Modeling, Data Assimilation and Predictability, Cambridge University Press, 2003. a
Klein Tank, A. M., Wijngaard, J. B., Können, G. P., Böhm, R., Demarée, G., Gocheva, A., Mileta, M., Pashiardis, S., Hejkrlik, L., Kern‐Hansen, C., Heino, R., Bessemoulin, P., Müller‐Westermeier, G., Tzanakou, M., Szalai, S., Pálsdóttir, T., Fitzgerald, D., Rubin, S., Capaldo, M., Maugeri, M., Leitass, A., Bukantis, A., Aberfeld, R., van Engelen, A. F., Forland, E., Mietus, M., Coelho, F., Mares, C., Razuvaev, V., Nieplova, E., Cegnar, T., Antonio López, J., Dahlström, B., Moberg, A., Kirchhofer, W., Ceylan, A., Pachaliuk, O., Alexander, L. V., and Petrovic, P.: Daily dataset of 20th-century surface air temperature and precipitation series for the European Climate Assessment, Int. J. Climatol., 22, 1441–1453, 2002. a
Kotlarski, S., Szabó, P., Herrera, S., Räty, O., Keuler, K., Soares, P. M., Cardoso, R. M., Bosshard, T., Pagé, C., Boberg, F., Gutiérrez, J. M., Isotta, F. A., Jaczewski, A., Kreienkamp, F., Liniger, M. A., Lussana, C., and Pianko-Kluczyńska, K.: Observational uncertainty and regional climate model evaluation: A pan-European perspective, Int. J. Climatol., 39, 3730–3749, https://doi.org/10.1002/joc.5249, 2017. a
Lanzante, J. R.: Resistant, robust and non-parametric techniques for the analysis of climate data: theory and examples, including applications to historical radiosonde station data, Int. J. Climatol., 16, 1197–1226, 1996. a
Lind, P., Lindstedt, D., Kjellström, E., and Jones, C.: Spatial and Temporal Characteristics of Summer Precipitation over Central Europe in a Suite of High-Resolution Climate Models, J. Climate, 29, 3501–3518, https://doi.org/10.1175/JCLI-D-15-0463.1, 2016. a
Lorenc, A. C.: Analysis methods for numerical weather prediction, Q. J. Roy. Meteor. Soc., 112, 1177–1194, https://doi.org/10.1002/qj.49711247414, 1986. a
Lussana, C.: BLISS – Bayesian statistical interpolation for spatial analysis, https://doi.org/10.5281/zenodo.2022479, the Norwegian Meteorological Institute, 2018a. a
Lussana, C.: seNorge_2018 daily total precipitation amount 1957–2017, https://doi.org/10.5281/zenodo.2082320, the Norwegian Meteorological Institute, 2018b. a, b, c
Lussana, C.: seNorge_2018 daily mean temperature 1957–2017, https://doi.org/10.5281/zenodo.2023997, the Norwegian Meteorological Institute, 2018c. a, b, c
Lussana, C.: seNorge_2018 daily minimum temperature 1957–2017, https://doi.org/10.5281/zenodo.2559354, the Norwegian Meteorological Institute, 2018d. a, b
Lussana, C.: seNorge_2018 daily maximum temperature 1957–2017, https://doi.org/10.5281/zenodo.2559372, the Norwegian Meteorological Institute, 2018e. a, b, c
Lussana, C., Salvati, M., Pellegrini, U., and Uboldi, F.: Efficient high-resolution 3-D interpolation of meteorological variables for operational use, Adv. Sci. Res., 3, 105–112, 2009. a
Lussana, C., Uboldi, F., and Salvati, M. R.: A spatial consistency test for surface observations from mesoscale meteorological networks, Q. J. Roy. Meteor. Soc., 136, 1075–1088, 2010. a, b, c
Lussana, C., Saloranta, T., Skaugen, T., Magnusson, J., Tveito, O. E., and Andersen, J.: seNorge2 daily precipitation, an observational gridded dataset over Norway from 1957 to the present day, Earth Syst. Sci. Data, 10, 235–249, https://doi.org/10.5194/essd-10-235-2018, 2018a. a, b, c
Lussana, C., Tveito, O. E., and Uboldi, F.: Three-dimensional spatial interpolation of 2m temperature over Norway, Q. J. Roy. Meteor. Soc., 144, 344–364, https://doi.org/10.1002/qj.3208, 2018b. a, b, c, d, e
Magnusson, J., Wever, N., Essery, R., Helbig, N., Winstral, A., and Jonas, T.: Evaluating snow models with varying process representations for hydrological applications, Water Resour. Res., 51, 2707–2723, 2015. a
Masson, D. and Frei, C.: Spatial analysis of precipitation in a high-mountain region: exploring methods with multi-scale topographic predictors and circulation types, Hydrol. Earth Syst. Sci., 18, 4543–4563, https://doi.org/10.5194/hess-18-4543-2014, 2014. a
Masson, D. and Frei, C.: Long-term variations and trends of mesoscale precipitation in the Alps: recalculation and update for 1901–2008, Int. J. Climatology, 36, 492–500, 2016. a
Masson, V., Le Moigne, P., Martin, E., Faroux, S., Alias, A., Alkama, R., Belamari, S., Barbu, A., Boone, A., Bouyssel, F., Brousseau, P., Brun, E., Calvet, J.-C., Carrer, D., Decharme, B., Delire, C., Donier, S., Essaouini, K., Gibelin, A.-L., Giordani, H., Habets, F., Jidane, M., Kerdraon, G., Kourzeneva, E., Lafaysse, M., Lafont, S., Lebeaupin Brossier, C., Lemonsu, A., Mahfouf, J.-F., Marguinaud, P., Mokhtari, M., Morin, S., Pigeon, G., Salgado, R., Seity, Y., Taillefer, F., Tanguy, G., Tulet, P., Vincendon, B., Vionnet, V., and Voldoire, A.: The SURFEXv7.2 land and ocean surface platform for coupled or offline simulation of earth surface variables and fluxes, Geosci. Model Dev., 6, 929–960, https://doi.org/10.5194/gmd-6-929-2013, 2013. a
Mohr, M.: New routines for gridding of temperature and precipitation observations for “seNorge. no”, Met. no Report, 8, 2008, 2008. a
Mohr, M.: Comparison of versions 1.1 and 1.0 of gridded temperature and precipitation data for Norway, Norwegian Meteorological Institute, met no note, 19, 2009. a
Müller, M., Homleid, M., Ivarsson, K., Køltzow, M. A., Lindskog, M., Midtbø, K. H., Andrae, U., Aspelien, T., Berggren, L., Bjørge, D., Dahlgren, P., Kristiansen, J., Randriamampianina, R., Ridal, M., and Vignes, O.: AROME-MetCoOp: a nordic convective-scale operational weather prediction model, Weather Forecast., 32, 609–627, 2017. a
Norwegian Meteorological Institute: seNorge_2018 on-line archive, available at: http://thredds.met.no/thredds/catalog/senorge/seNorge_2018/catalog.html last access: 7 October 2019a. a, b
Norwegian Meteorological Institute: seNorge_2018 on-line archive, available at: http://thredds.met.no/thredds/catalog/senorge/seNorge_2018/Archive/catalog.html?dataset=senorge/seNorge_2018/Archive/seNorge2018_2010.nc, last access: 7 October 2019b. a
Norwegian Water Resources and Energy Directorate: expert tool for notification and emergency, available at: http://www.xgeo.no, last access: 7 October 2019. a
Orlanski, I.: A rational subdivision of scales for atmospheric processes, B. Am. Meteorol. Soc., 56, 527–530, 1975. a
Pielke, R. A.: Further Comments on “The Differentiation between Grid Spacing and Resolution and Their Application to Numerical Modeling”, B. Am. Meteorol. Soc., 82, 699–700, https://doi.org/10.1175/1520-0477(2001)082<0699:FCOTDB>2.3.CO;2, 2001. a
Reistad, M., Breivik, Ø., Haakenstad, H., Aarnes, O. J., Furevik, B. R., and Bidlot, J.-R.: A high-resolution hindcast of wind and waves for the North Sea, the Norwegian Sea, and the Barents Sea, J. Geophys. Res.-Oceans, 116, 1–18, https://doi.org/10.1029/2010JC006402, 2011. a
Sakov, P. and Bertino, L.: Relation between two common localisation methods for the EnKF, Computational Geosciences, 15, 225–237, 2011. a
Saloranta, T. M.: Simulating snow maps for Norway: description and statistical evaluation of the seNorge snow model, The Cryosphere, 6, 1323–1337, https://doi.org/10.5194/tc-6-1323-2012, 2012. a
Saloranta, T. M.: Operational snow mapping with simplified data assimilation using the seNorge snow model, J. Hydrol., 538, 314–325, 2016. a
Seity, Y., Brousseau, P., Malardel, S., Hello, G., Bénard, P., Bouttier, F., Lac, C., and Masson, V.: The AROME-France Convective-Scale Operational Model, Mon. Weather Rev., 139, 976–991, https://doi.org/10.1175/2010MWR3425.1, 2011. a
Simmons, A. J., Berrisford, P., Dee, D. P., Hersbach, H., Hirahara, S., and Thépaut, J.-N.: A reassessment of temperature variations and trends from global reanalyses and monthly surface climatological datasets, Q. J. Roy. Meteor. Soc., 143, 101–119, https://doi.org/10.1002/qj.2949, 2017. a
Skaugen, T. and Mengistu, Z.: Estimating catchment-scale groundwater dynamics from recession analysis – enhanced constraining of hydrological models, Hydrol. Earth Syst. Sci., 20, 4963–4981, https://doi.org/10.5194/hess-20-4963-2016, 2016. a
Skaugen, T. and Onof, C.: A rainfall-runoff model parameterized from GIS and runoff data, Hydrol. Process., 28, 4529–4542, 2014. a
Thunis, P. and Bornstein, R.: Hierarchy of mesoscale flow assumptions and equations, J. Atmos. Sci., 53, 380–397, 1996. a, b
Tian, Y., Huffman, G. J., Adler, R. F., Tang, L., Sapiano, M., Maggioni, V., and Wu, H.: Modeling errors in daily precipitation measurements: Additive or multiplicative?, Geophys. Res. Lett., 40, 2060–2065, 2013. a
Tveito, O. E. and Førland, E. J.: Mapping temperatures in Norway applying terrain information, geostatistics and GIS, Norsk Geogr. Tidsskr., 53, 202–212, 1999. a
Uboldi, F., Lussana, C., and Salvati, M.: Three-dimensional spatial interpolation of surface meteorological observations from high-resolution local networks, Meteorol. Appl., 15, 331–345, 2008. a, b
Walters, M. K.: commentary and analysis, B. Am. Meteorol. Soc., 81, 2475–2479, https://doi.org/10.1175/1520-0477(2000)081<2475:CAACOT>2.3.CO;2, 2000. a
Wolff, M. A., Isaksen, K., Petersen-Øverleir, A., Ødemark, K., Reitan, T., and Brækkan, R.: Derivation of a new continuous adjustment function for correcting wind-induced loss of solid precipitation: results of a Norwegian field study, Hydrol. Earth Syst. Sci., 19, 951–967, https://doi.org/10.5194/hess-19-951-2015, 2015. a, b, c, d
Zhang, X., Alexander, L., Hegerl, G. C., Jones, P., Tank, A. K., Peterson, T. C., Trewin, B., and Zwiers, F. W.: Indices for monitoring changes in extremes based on daily temperature and precipitation data, Wiley Interdisciplinary Reviews: Climate Change, 2, 851–870, https://doi.org/10.1002/wcc.147, 2011. a