the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 21 Jun 2022
| 21 Jun 2022
HOTRUNZ: an open-access 1 km resolution monthly 1910–2019 time series of interpolated temperature and rainfall grids with associated uncertainty for New Zealand
Thomas R. Etherington
George L. W. Perry
Janet M. Wilmshurst
Long time series of temperature and rainfall grids are fundamental to understanding how these environmental variables affect environmental or ecological patterns and processes such as plant distributions, plant and animal phenology, wildfires, and hydrology. Ideally such temperature and rainfall grids are openly available and associated with uncertainties so that data-quality issues are transparent to users. We present a History of Open Temperature and Rainfall with Uncertainty in New Zealand (HOTRUNZ) that uses climatological aided natural neighbour interpolation to provide monthly 1 km resolution grids of total rainfall, mean air temperature, mean daily maximum air temperature, and mean daily minimum air temperature across New Zealand from 1910 to 2019. HOTRUNZ matches the best available temporal extent and spatial resolution of any open-access temperature and rainfall grids that include New Zealand and is unique in providing associated spatial uncertainty in the variables' units. The HOTRUNZ grids capture the dynamic spatial and temporal nature of monthly temperature and rainfall and the uncertainties associated with the interpolation. We also demonstrate how to quantify and visualise temporal trends across New Zealand that recognise the temporal and spatial variation in uncertainties in the HOTRUNZ data. The HOTRUNZ data are openly available at https://doi.org/10.7931/zmvz-xf30 (Etherington et al., 2021).
- Article
(5451 KB) - Full-text XML
-
Supplement
(909 KB) - BibTeX
- EndNote





Climatologies such as WorldClim 2 (Fick and Hijmans, 2017) and CHELSA (Karger et al., 2017) that provide spatial grids (or layers, surfaces) consisting of cells (or grid points, pixels) that record climatic variables such as temperature and rainfall underpin thousands of environmental and ecological studies. These climatologies represent long-term ≈30-year climate averages, but long time series of temperature and rainfall grids, each of which covers a shorter period, are also highly desirable as they can be correlated with long-term environmental or ecological data to explore how temperature and rainfall influence such processes. For example, monthly time-series data of temperature and rainfall conditions can be used to improve the understanding of plant distributions (Stewart et al., 2021), plant and animal phenology (Gordo and Sanz, 2005), wildfire histories (Girardin and Wotton, 2009), and hydrology (Remesan et al., 2014).
Meteorologists and climatologists are recognising the importance of implementing open-access methodologies, as openly sharing data, source code, and knowledge provides exciting opportunities for scientific discovery (de Vos et al., 2020). For New Zealand there are limited time-series options for national-scale temperature and rainfall grids (Table 1), and while each varies in its spatial and temporal characteristics, no one open-access dataset has the combined criteria of ≤1 km2 spatial and monthly temporal resolution over the last century. Producing such historical temperature and rainfall data is challenging because weather station data are often sparse, especially in remote areas and for earlier time periods. However, this challenge should not preclude the creation of historical data, if we accept that we cannot be consistently successful for all locations and dates and we prioritise providing temperature and rainfall data with associated uncertainty data.
Table 1Datasets providing a time series of spatial grids that estimate rainfall and temperature that include New Zealand.
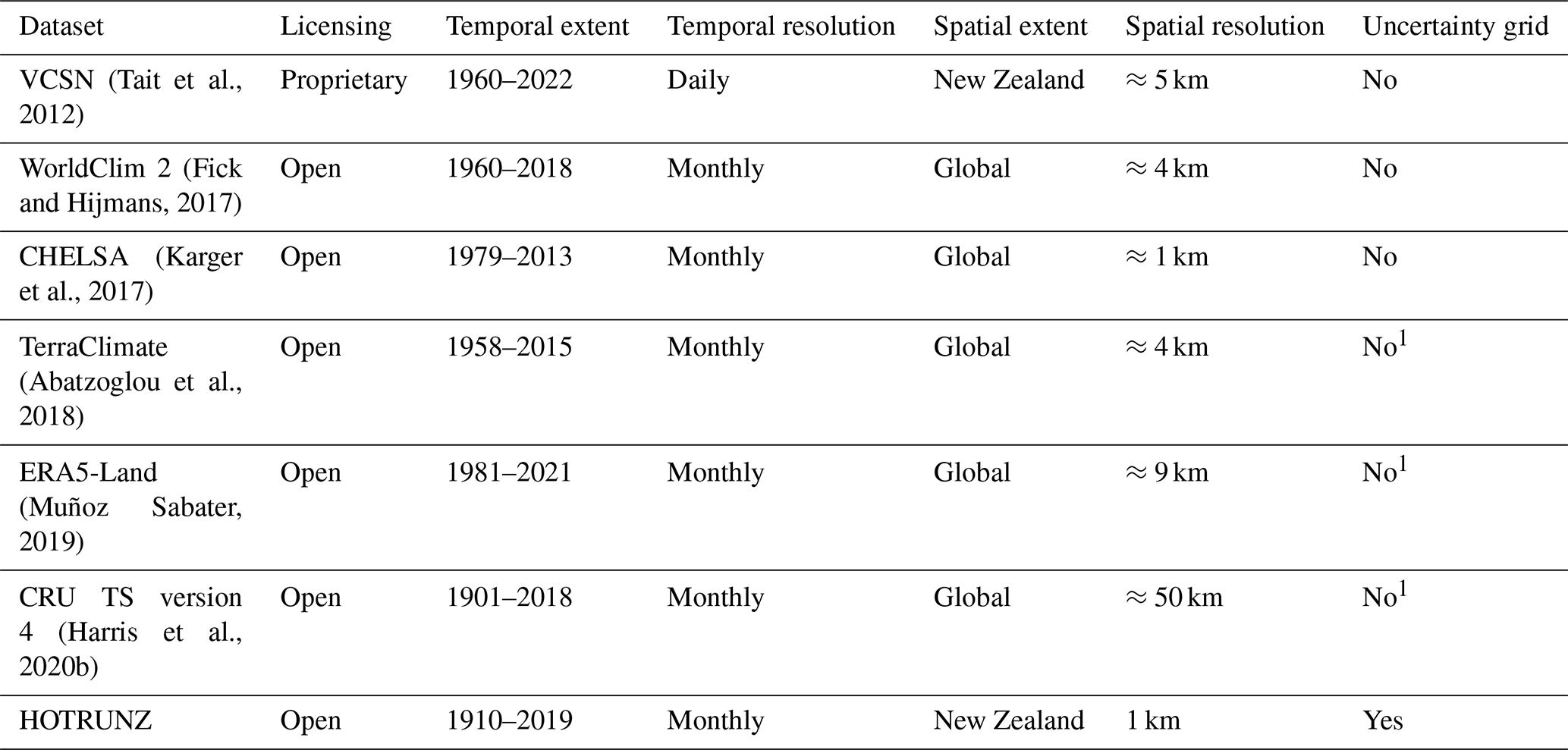
1 An uncertainty grid is provided to aid a user to make a personal uncertainty assessment but it is not in the variables' units.
Much emphasis has been placed on quantifying (Foley, 2010) and visualising (Retchless and Brewer, 2016) the uncertainty of future climates. Quantifying and visualising uncertainty are also critical for the judicious use of historic climate and weather data, as even when following open science practices that involve sharing data and code it can still be difficult to ensure that an end-user is aware of and understands the quality of the data (de Vos et al., 2020). Historical climate and weather data are often used predictively, but these predictions must recognise the underlying uncertainties so that their reliability can be understood and communicated. The uncertainty (or reliability) of weather and climate spatial data is often quantified with metrics such as the root-mean-square error (RMSE) or the mean absolute error (MAE) derived from cross-validation that iteratively excludes each weather station and then interpolates a value for the weather station using the remaining data (Willmott and Matsuura, 2006). However, these are global metrics that describe uncertainty with a single spatially averaged value and provide no information about how the uncertainty will vary across space (Zhang and Goodchild, 2002). When estimates of spatial uncertainty accompany climate and weather data, they typically provide only simple indications of areas that are reliable (Abatzoglou et al., 2018; Harris et al., 2020b), which limits how uncertainty can be incorporated into analyses as estimates from individual cells are not matched with an uncertainty in the variables' units.
To facilitate understanding of how long-term temperature and rainfall patterns have been changing and potentially affecting environmental and ecological processes in New Zealand, we use climatologically aided interpolation to produce a History of Open Temperature and Rainfall with Uncertainty in New Zealand (HOTRUNZ). HOTRUNZ is an openly available history of monthly temperature and rainfall data for 1 km2 grid cells across New Zealand that matches the best available spatial and temporal extent and resolution of any currently available open data and is unique in providing associated spatial uncertainty grids in each variable's units (Table 1).
Precomputed monthly statistics calculated from weather station data are freely available from New Zealand's National Climate Database (NIWA, 2020). For New Zealand's three main islands and their associated near-shore islands, we queried the database for data from 1900 to 2019 for monthly statistics of total rainfall, mean air temperature, mean daily maximum air temperature, and mean daily minimum air temperature. Using older weather station data can be problematic as the manual nature of the recording can lead to gaps in the records over time, and locations can be poorly recorded. Therefore, to ensure a high quality of weather station data, we only used monthly statistics data for weather stations that were recorded in the database as having a complete set of daily records for every day of the month and hence did not contain any estimated values. We also only used data from weather stations whose locations were recorded in the database as being reliable to within 100–200 m at worst and therefore could be reliably located within a 1 km2 grid cell.
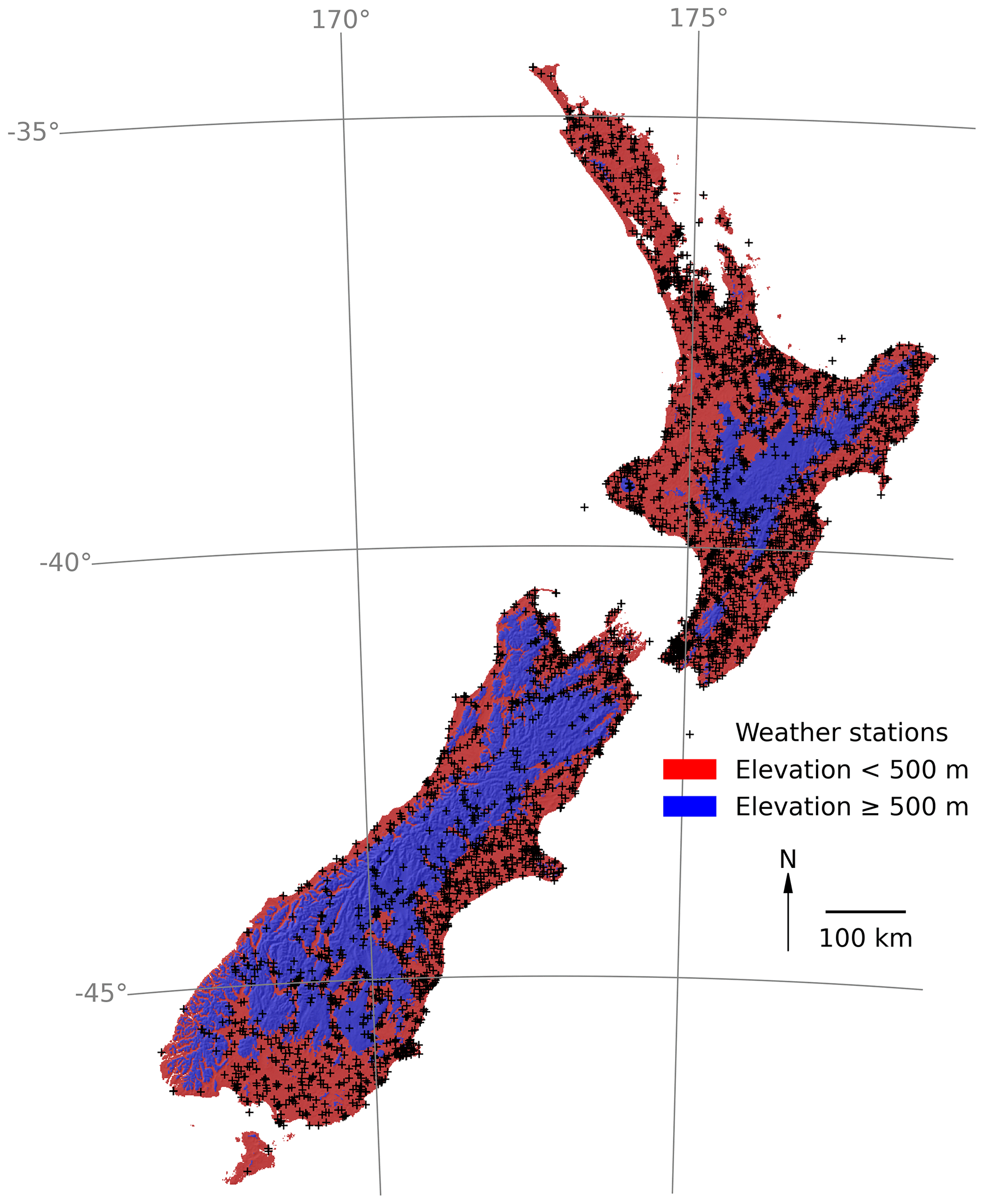
Figure 1The topography of New Zealand and the location of all weather stations contributing data.
Having applied these filters to the weather station database, we had data from 3438 weather stations across New Zealand, but most of these stations were from lower elevational areas, with 89 % below 500 m (Fig. 1). This lack of weather station data at higher elevations has been noted before and is in part why interpolations of temperature and rainfall data in New Zealand are usually less accurate at higher elevations (Tait and Macara, 2014; Tait et al., 2012). To recognise the challenges of interpolating temperature and rainfall at higher elevations, we will follow Tait et al. (2012) and will evaluate the accuracy of our data for locations below and above 500 m elevation (Fig. 1). Further complexity is added to data availability in that many of the weather stations were short-lived or provided intermittent records, so the amount of data available in any given month varied through time, across space, and between variables, but there were some consistencies. There were much more rainfall data than temperature data, there were more data in recent times (with a peak around 1980), and there were always fewer data in the mountainous interiors of both islands and in the more remote southerly and westerly regions of New Zealand (Fig. 2).
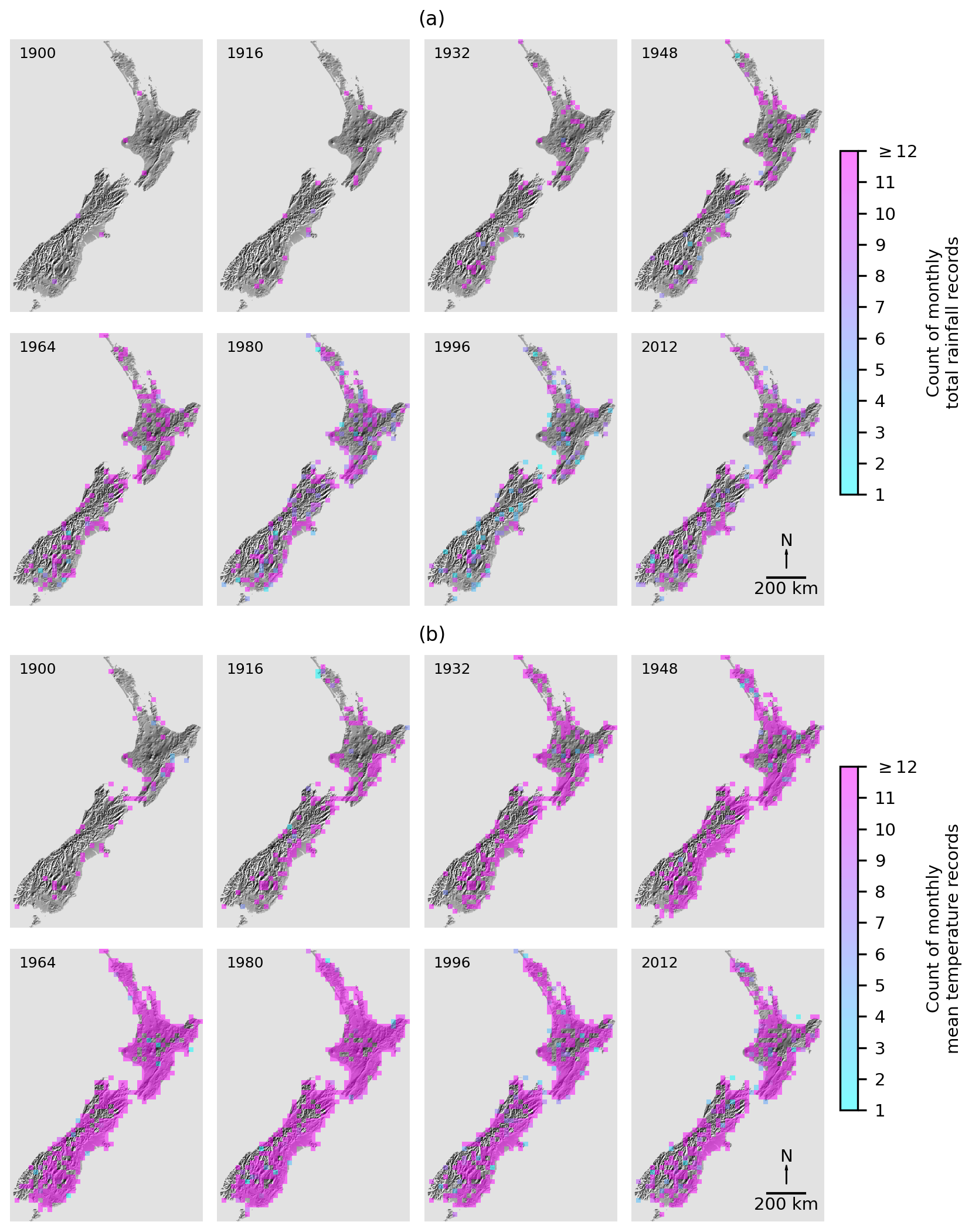
Figure 2A time series of the total number of monthly weather records for each year within 25 km ×25 km grid cells for (a) total rainfall and (b) mean air temperature (which are similar to mean daily maximum air temperature and mean daily minimum air temperature). Cells with ≥12 records will usually mean at least one weather station is present with records for all 12 months of the year, but in some instances many weather stations may be present, resulting in tens or hundreds of records per grid cell.
Climatologies that describe average weather patterns over several decades have underpinned successful previous rainfall interpolations in New Zealand (Tait et al., 2006). Therefore, we used a climatologically aided interpolation approach by interpolating monthly values as an anomaly from a climatic normal (Willmott and Robeson, 1995) as this technique has been successfully applied elsewhere (Abatzoglou et al., 2018; Harris et al., 2020b; Hofstra et al., 2008). The basic premise of climatologically aided interpolation is that rather than directly interpolating weather station data in each month, by using an underlying long-term climatology grid for that month, monthly anomalies can be calculated as the difference between the weather station value and the climatology grid value. These anomalies are then interpolated and added to the climatology grid to estimate how the conditions in that month deviated from the climatological normal. When compared to the same interpolation method using just weather station data, climatologically aided interpolation is advantageous in that it (i) has reduced errors, (ii) has errors that are insensitive to changes in the number of weather stations, and (iii) can indirectly account for topographic effects when climatologies with high spatial resolution are used (Willmott and Robeson, 1995). Openly available New Zealand climatology grids for the rainfall and temperature variables giving the average conditions over the 30-year period from 1950–1980 for each month at 100 m grid cell resolution (McCarthy et al., 2021; Leathwick et al., 2002) were used to produce 1 km2 grid cell resolution climatologies as the basis of the climatologically aided interpolation. These climatologies were developed from long-term weather station data interpolated using thin-plate splines using geographic variables of elevation, and in the case of rainfall an east–west topographic protection variable (Leathwick et al., 2002). Using these climatologies for our climatologically aided interpolations incorporates these geographic variables indirectly into our interpolations, and by having a climatology for each month, as opposed to a single climatology for a whole year, seasonal shifts in temperature and rainfall are also accounted for.
We selected natural neighbour (or Sibson) interpolation (Sibson, 1981) to interpolate the anomalies. Natural neighbour interpolation has been shown to perform well for interpolating rainfall and temperature data (Hofstra et al., 2008; Keller et al., 2015; Lyra et al., 2018). More specifically we chose to use natural neighbour interpolation because it is (i) an exact interpolator, meaning it will retain the original data values at locations with input data in the interpolated grid and will only interpolate within the range of the original data and so cannot produce wildly unrealistic interpolations; (ii) a local method, which interpolates for a location only using data from that location's immediate surrounds; (iii) spatially adaptive, so automatically adapting to localised data distribution and density; and (iv) not based on fitting statistical trends and so does not require large sample sizes (Etherington, 2020). These properties are desirable given our interpolations will need to adapt to the increasingly sparse and irregular data that occur further back in New Zealand history and which preclude using more complex interpolation methods that require more data. For example, when interpolating at higher elevations where there are fewer data, simpler methods can perform better than more complex methods (Stahl et al., 2006). Therefore, in choosing natural neighbour interpolation we do not suggest that it is universally the best interpolation method, but rather it was the most appropriate given our data situation and interpolation objectives.
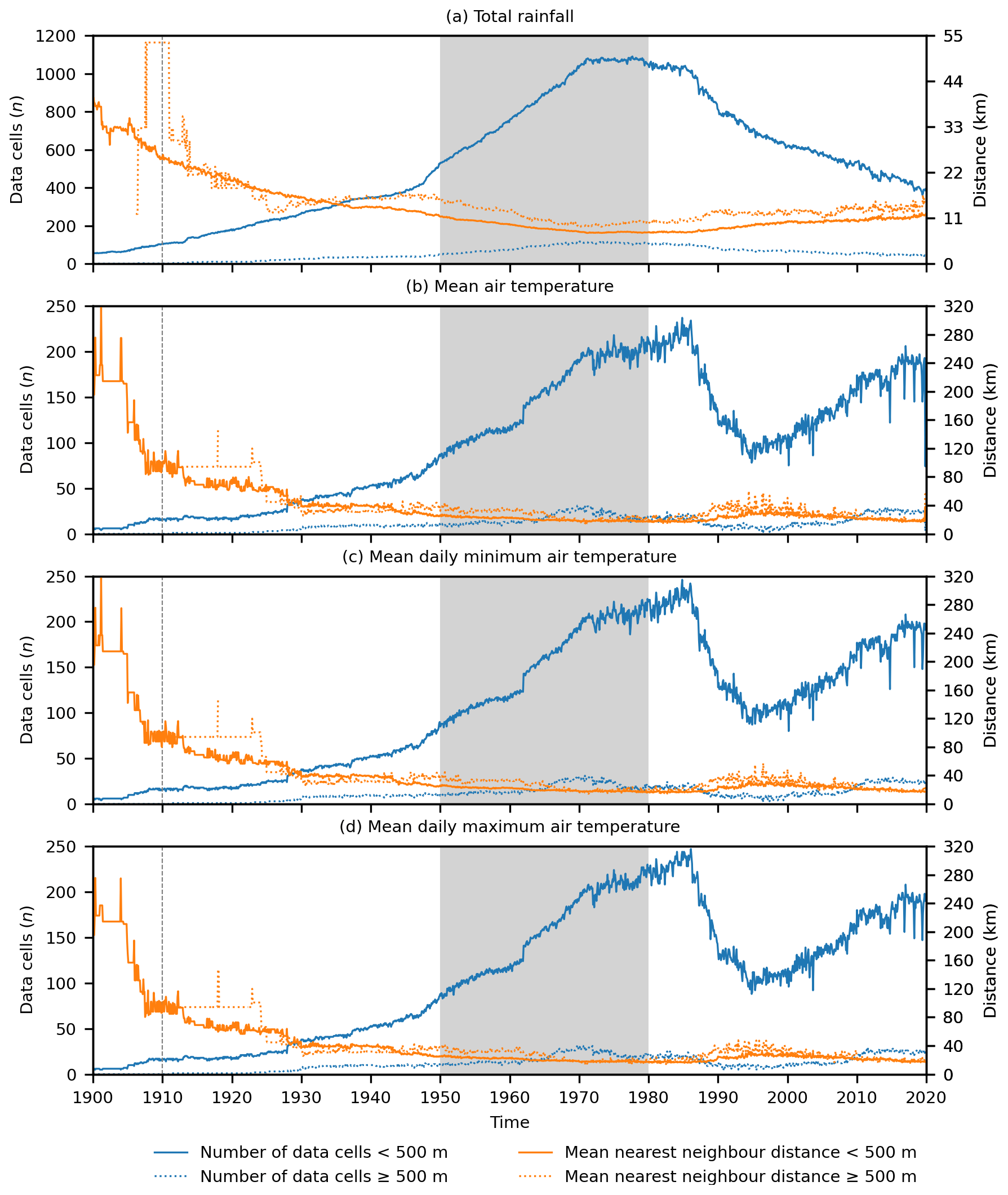
Figure 3Monthly time series of the number of data cells (which relates closely to the number of weather stations) and the mean nearest-neighbour distance of data cells contributing to climatologically aided natural neighbour interpolation across New Zealand at <500 m elevation and ≥500 m elevation for (a) total rainfall, (b) mean air temperature, (c) mean daily minimum air temperature, and (d) mean daily maximum air temperature. Missing data indicate an absence of data cells in an elevational category. The grey areas show the period (1950–1980) over which the climatologies used to aid interpolation apply, and the dashed lines indicate the temporal limit of reliable data.
We applied a discrete (or digital) form of natural neighbour interpolation (Park et al., 2006) that simultaneously calculates uncertainty as a cross-validation error-distance field (Etherington, 2020). This interpolation method works by defining a grid of cells for which interpolated values will be calculated. Data cells are first defined as those cells that contain weather station data. Where there are multiple weather stations within a single data cell the data cell is given the mean value of any weather stations it contains; therefore with discrete natural neighbour interpolation it is not the number of weather stations but rather the number of data cells that determines the amount of data available for the interpolation. The number of data cells and the spatial pattern of the data cells, as measured by mean nearest-neighbour distance (Clark and Evans, 1954), varied over time (Fig. 3). At elevations <500 m the number of data cells for all variables increases steadily over time with a peak around the 1980s followed by a decline that while continual for rainfall is then reversed for all temperature variables. While the number of data cells varies, the mean nearest-neighbour distance is reasonably constant over time, indicating that spatial coverage by the weather station network has been consistent despite variations in the number of data locations. Spatial coverage does decrease moving back through time, and that coverage was particularly poor for the temperature variables pre-1910. At elevations ≥500 m there are far fewer data cells at all points in time, and pre-1910 there were usually no data cells available for the temperature variables. However, the mean nearest-neighbour distance of the data cells at or above 500 m is similar to the data cells below 500 m. This difference in number of data cells but consistency in spatial pattern between the elevational regions suggests that data cells at or above 500 m tend to occur either along the edge of the region with elevations ≥500 m or are clustered within the region with elevations ≥500 m, which is consistent with the general pattern of all weather stations providing data (Fig. 1). Overall, these patterns in data cell numbers and spatial pattern indicate a need for caution in our interpolations in regions ≥500 m elevation and pre-1910.
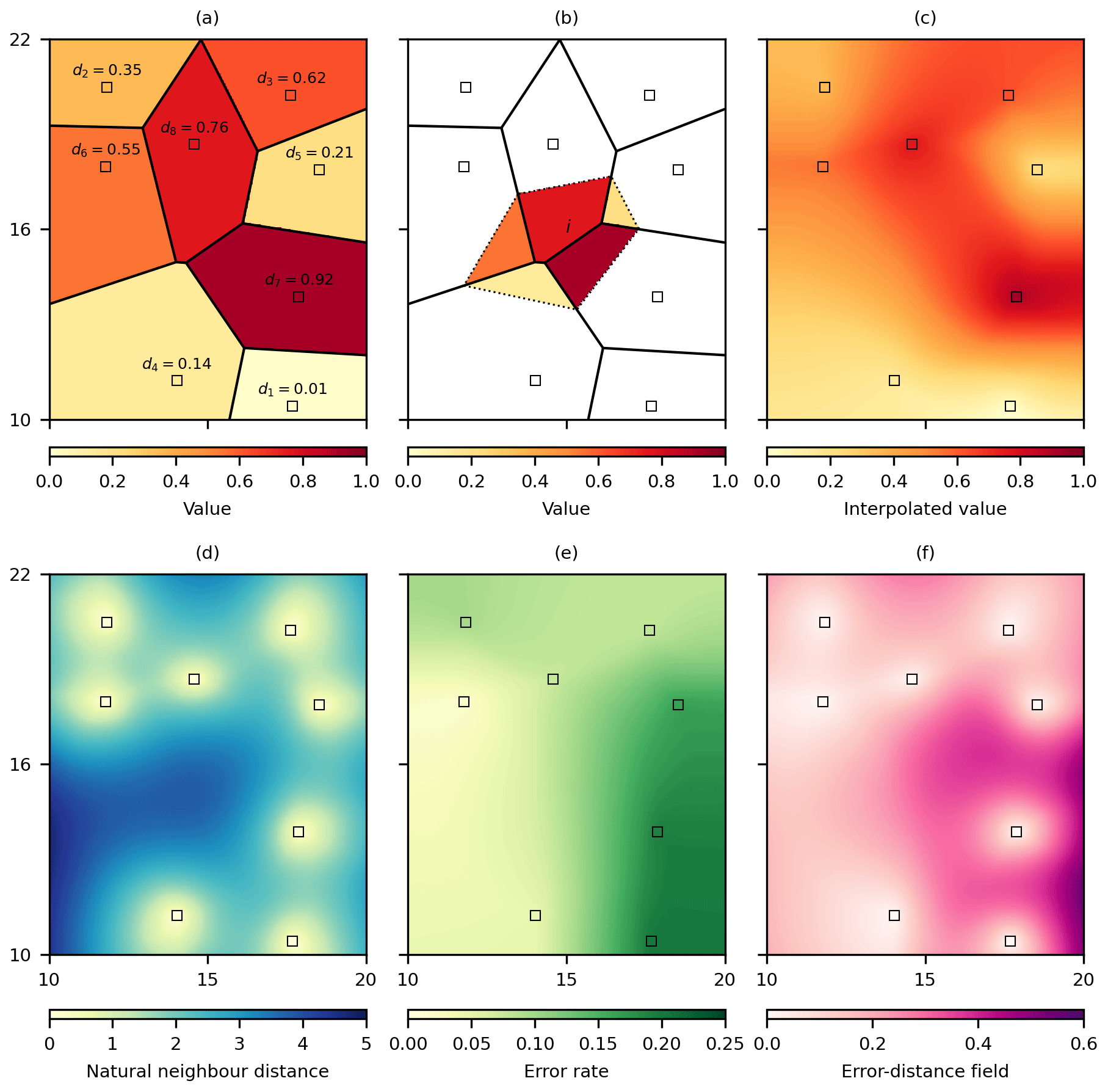
Figure 4A hypothetical example to illustrate discrete natural neighbour interpolation with a cross-validation error-distance field. Beginning with a set of data cells di, shown as squares, a grid of cells is defined and (a) each cell is given the value of the nearest data cell d, (b) for any interpolation cell i the interpolated value is the mean of cell values that are as close or closer to the interpolation cell than a data cell, which (c) when repeated for all grid cells produces a natural neighbour interpolation. Natural neighbour interpolation is also used to interpolate (d) the distances to the data cells and (e) the cross-validated error rate of each data cell. The interpolation uncertainty is then (f) the cross-validation error distance field that is the product of the natural neighbour distances and error rates (adapted from Etherington, 2020, https://creativecommons.org/licenses/by/4.0/, last access: 16 February 2021).
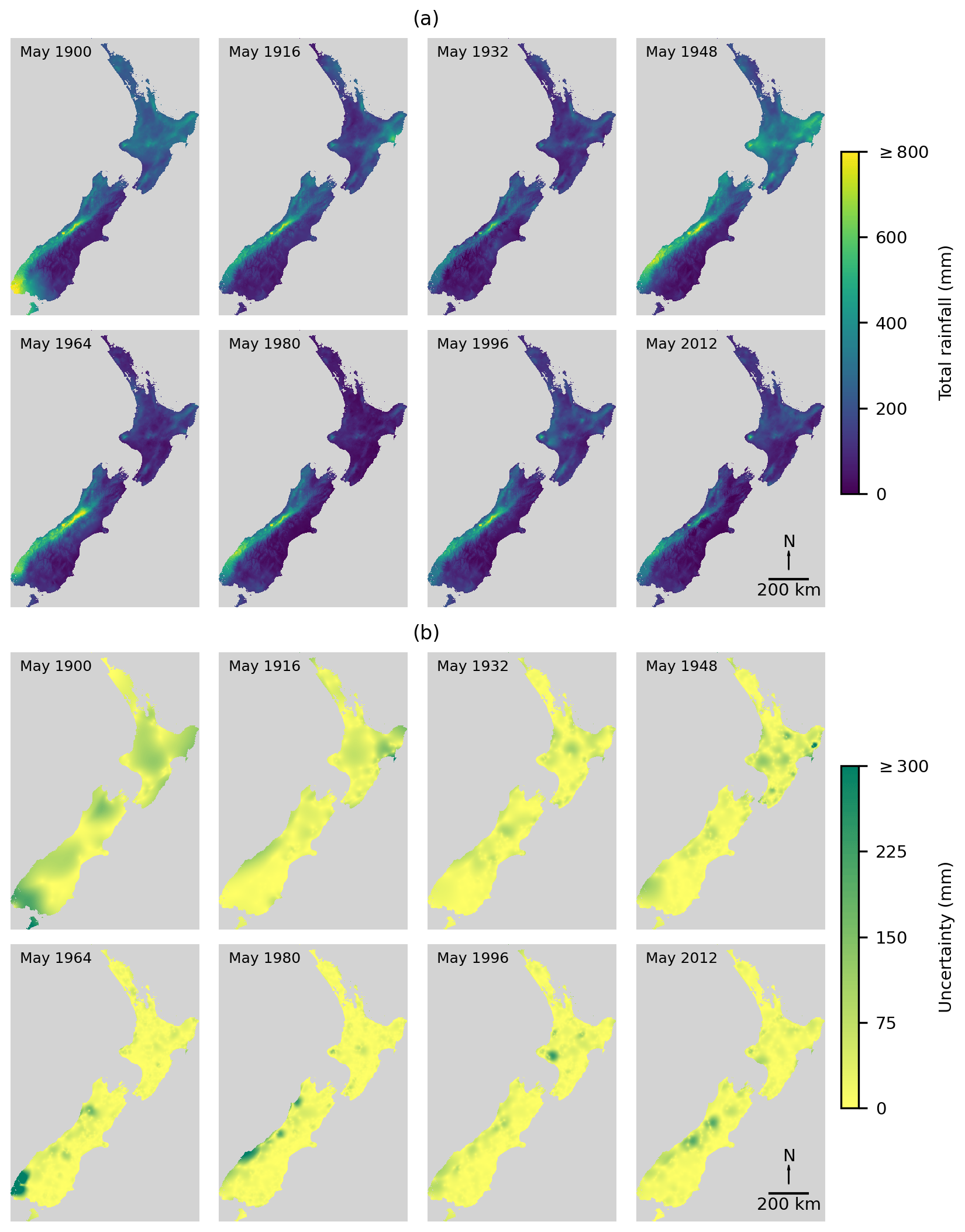
Figure 5Example time series of climatologically aided discrete natural neighbour interpolation of May (a) total rainfall with (b) the associated uncertainty of the interpolated rainfall estimates.
Once the data cells for each month are established, the discrete natural neighbour interpolation proceeds by assigning all other cells the value of the nearest data cell (Fig. 4a). The interpolated value for a grid cell is the mean of the grid cell values that are as close or closer to the interpolation cell than a data cell (Fig. 4b), which, when repeated across all grid cells, yields a smooth interpolation grid (Fig. 4c). A cross-validation error-distance field (Etherington, 2020) is then used to quantify the interpolation uncertainty. In essence uncertainty increases with distance from a data cell, with zero uncertainty at the data cells themselves where the underlying value is known and does not require interpolation. The rate at which uncertainty increases with distance from data cells is based on a cross-validation of the data cells that calculates the absolute interpolation error and distance to other data cells. This approach ultimately results in areas having greater uncertainty when they are more distant from data cells and are near data cells that would be harder to interpolate accurately when absent. Uncertainty is calculated using the discrete natural neighbour interpolation process to interpolate the distances to the data cells to produce natural neighbour distances (Fig. 4d) and to interpolate the cross-validated error rate, as the ratio of the cross-validated absolute error to natural neighbour distance, for each data cell (Fig. 4e). The product of the natural neighbour distances and cross-validated error rates produces a cross-validation error-distance field (Fig. 4f) that yields a grid of interpolation uncertainties in the same units as the interpolation and is highest in areas that are more distant from data cells and in areas where the variable being interpolated has higher spatial heterogeneity and therefore is harder to interpolate accurately when data are sparse (Etherington, 2020).
The resulting temperature and rainfall grids appeared to capture the heterogeneous and dynamic nature of the monthly temperature and rainfall variables and the uncertainty associated with the interpolation. For example, the May total rainfalls and uncertainties (Fig. 3) illustrate the dynamic nature of the monthly rainfall and the associated uncertainty. There are clear differences in total rainfall in May over time and shifts in the location of the wettest regions. Our emphasis on quantifying uncertainty is justified by the magnitude and location of uncertainty changing through time. This emphasises our view that global error estimates for large areas and timeframes are potentially unhelpful, as the degree of uncertainty can change rapidly over space and time, and so all interpolation estimates should be associated with an individual matching uncertainty estimate. We interpret this rapidly changing uncertainty to result primarily from the data limitations of interpolation, as higher uncertainty occurs in locations more distant from temperature or rainfall data whose location and abundance change over space and time (Figs. 2 and 3). However, uncertainty can be high in regions where temperature and rainfall data are available, which we interpret as arising from the spatial variability of individual monthly temperature and rainfall patterns, as when spatial variability of temperature and rainfall patterns increases over shorter distances, such as in mountainous terrain, interpolation becomes increasingly uncertain (Etherington, 2020).
The MAE provides a reasonable estimate of the actual error rates for discrete natural neighbour interpolation (Etherington, 2020). Therefore, even though each monthly temperature and rainfall grid has a matching uncertainty grid, we also used cross-validation to calculate the MAE for each monthly interpolation to validate the method and facilitate comparisons with other temperature and rainfall interpolations (Willmott and Matsuura, 2006).
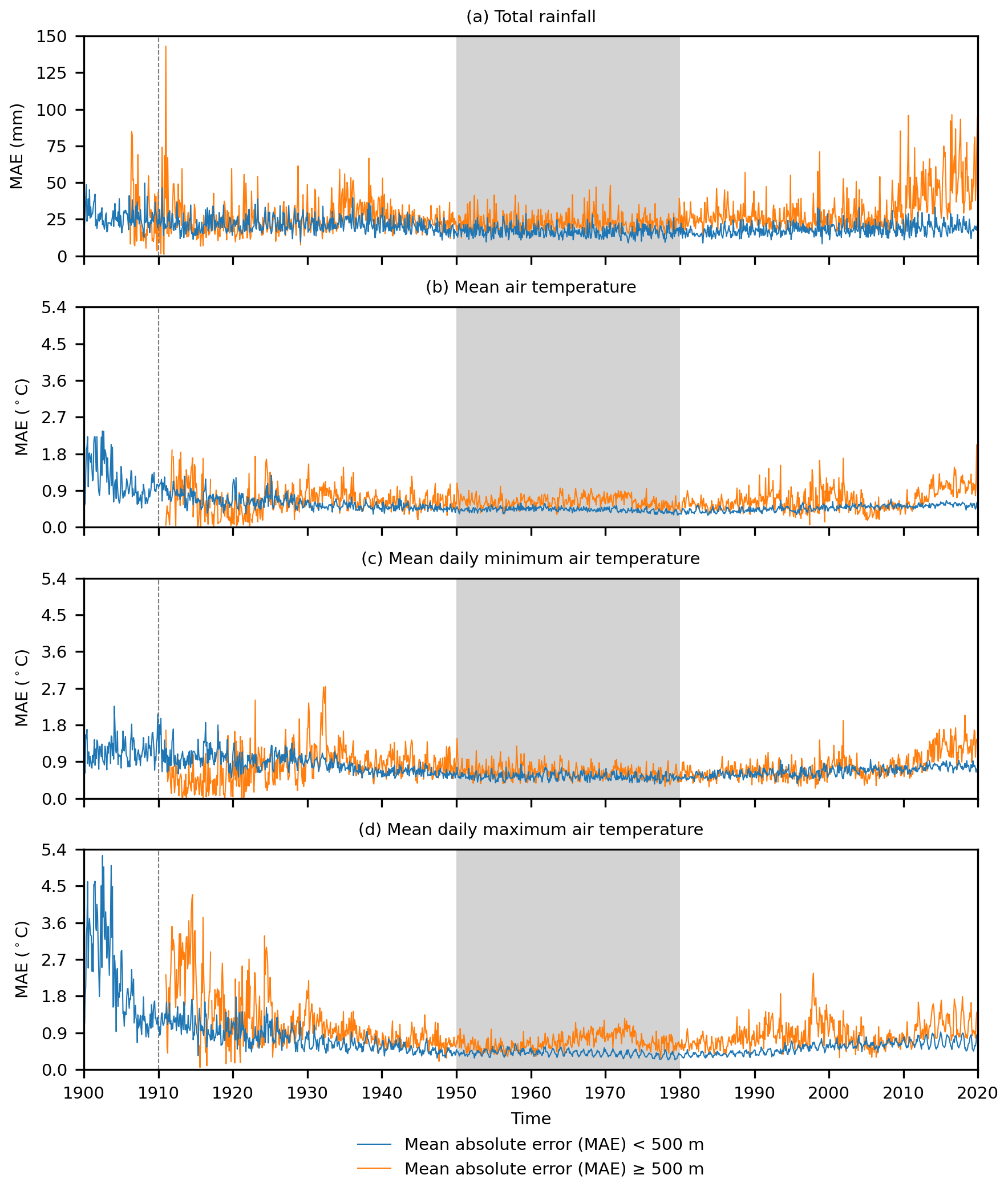
Figure 6Monthly time series of the cross-validated mean absolute error (MAE) of climatologically aided natural neighbour interpolation across New Zealand at <500 m elevation and ≥500 m elevation for (a) total rainfall (mm), (b) mean air temperature (∘C), (c) mean daily minimum air temperature (∘C), and (d) mean daily maximum air temperature (∘C). The grey areas show the period (1950–1980) over which the climatologies used to aid interpolation apply, and the dashed lines indicate the temporal limit of reliable data.
While the number of data cells (which equates closely to the number of weather stations) used during interpolation varied over time, the distance between data cells remained reasonably constant (Fig. 3). This consistency of spacing between data cells may explain why the MAEs associated with all the temperature and rainfall variables remained reasonably constant around 18 mm for total rainfall below 500 m and 24 mm for rainfall above 500 m and around 0.5 ∘C for all temperature variables below 500 m and 0.7 ∘C for all temperature variables above 500 m (Fig. 6). As might be expected, MAEs were lowest when interpolating data during 1950–1980, which is the period the climatologies aiding the interpolation were created for, and at lower elevations for which there are more data (Fig. 3). There was also an increase in MAE for some variables moving away from the 1950–1980 climatology period that becomes more pronounced pre-1910 as weather station data availability becomes extremely limited, resulting in as few as 53 to 104 rainfall and 3 to 17 temperature data cells across New Zealand in each month, with no data cells for temperature variables above 500 m pre-1910. We conclude that the data are most reliable from 1910 to 2019, representing the 4 decades either side of the 1950–1980 climatologies used in the interpolations. Similar patterns to the MAE are seen using the RMSE (Fig. S1 in the Supplement), and actual and estimated values are strongly positively correlated (Fig. S2); thus, while these metrics are sensitive to outliers, we include them as additional information given their use in other temperature and rainfall interpolation evaluations (Hofstra et al., 2008).

Figure 7Monthly time series of the cross-validated mean absolute error (MAE) of climatologically aided natural neighbour uncertainty across New Zealand at <500 m elevation and ≥500 m elevation for (a) total rainfall (mm), (b) mean air temperature (∘C), (c) mean daily minimum air temperature (∘C), and (d) mean daily maximum air temperature (∘C). The grey areas show the period (1950–1980) over which the climatologies used to aid interpolation apply, and the dashed lines indicate the temporal limit of reliable data.
We used the same cross-validation MAE approach to evaluate how well the estimated uncertainty matched the cross-validated absolute errors (Fig. 7). Again, performance was best during the 1950–1980 climatology period, with some variables showing more pronounced decreases in performance moving away from this time period. The uncertainty error was around 28 mm for total rainfall below 500 m and 35 mm for rainfall above 500 m, but there was a less pronounced difference between different elevations for temperature, with all temperature variables at both elevations having an error of around 1 ∘C. Similar patterns to the MAE are seen using the RMSE (Fig. S3) with a positive relationship between actual errors and estimated uncertainties (Fig. S4).
When using interpolated temperature and rainfall data, users need to be able to make decisions specific to their requirements (de Vos et al., 2020). Therefore, in HOTRUNZ we have endeavoured to match every interpolation with an individual measure of uncertainty in the relevant units. However, we recognise that it is unusual for historical temperature and rainfall data to be presented alongside such detailed uncertainty estimates. These uncertainty estimates provide a new and possibly challenging analytical opportunity; therefore we demonstrate how potential data users could incorporate the uncertainty data into an analytical workflow and visualise the results.
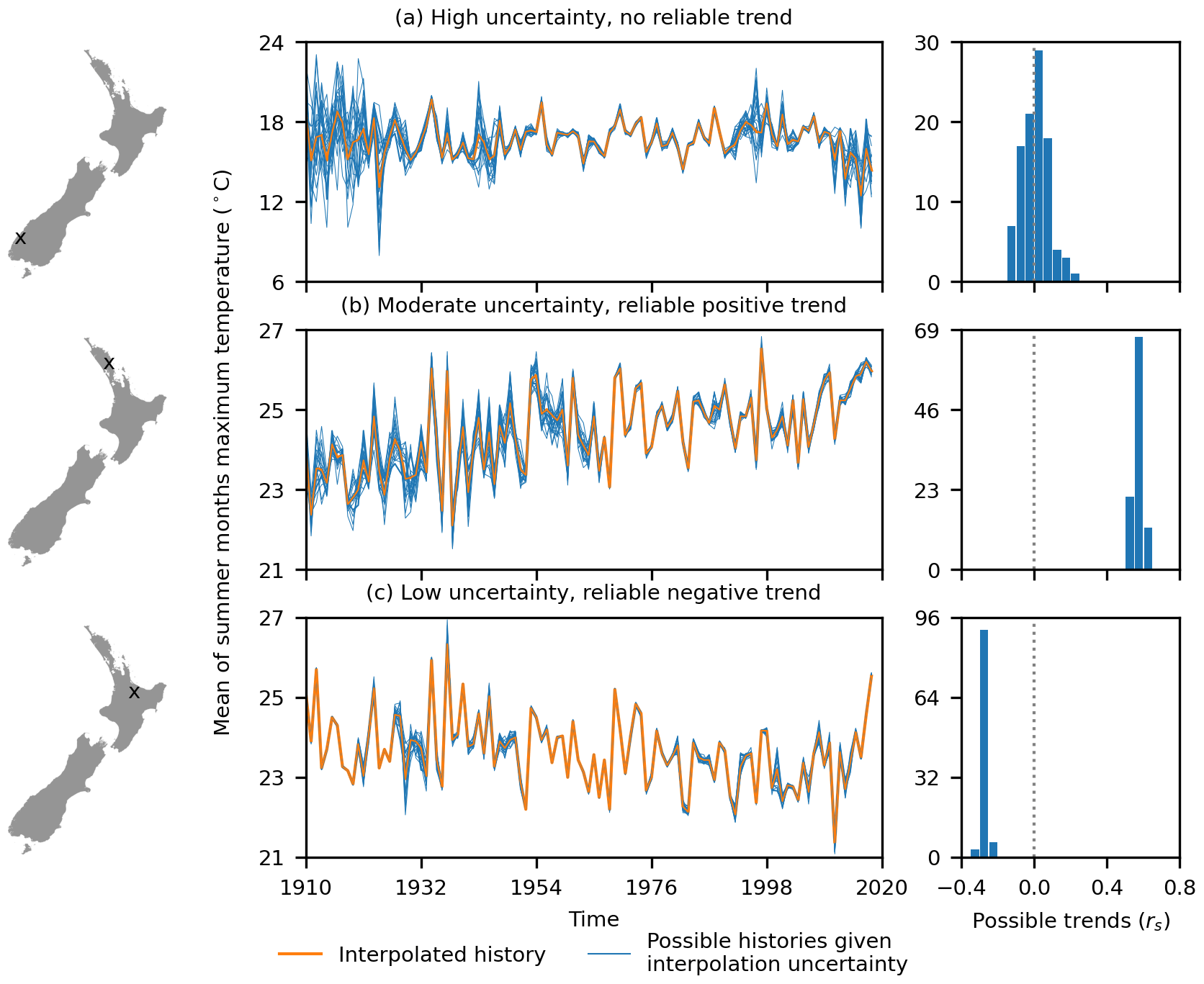
Figure 8Examples of mean of summer month (December, January, and February) maximum temperature trend analysis that incorporates interpolation uncertainty for three locations in New Zealand. The distribution of trends for the 100 possible histories are shown as Spearman's rank (rs) correlations between temperature and time for locations with (a) high uncertainty, resulting in a wide variety of possible histories with positive and negative trends and hence no reliable trend, (b) moderate uncertainty resulting in some variation in possible histories but all showing a consistent positive trend, and (c) low uncertainty resulting in consistent possible histories and a confident negative trend. For each location, the weather history for the interpolated values is shown along with the first 20 of 100 possible weather histories that are within the range of uncertainty for the interpolated value for each month.
A simple example of temperature and rainfall time-series analysis would be to use a Spearman rank (rs) correlation (Gregory, 1978; Spearman, 1904) to detect the directionality of any trends in temperature and rainfall patterns over time (Girardin and Wotton, 2009). To incorporate uncertainty into this process, we adopt a Monte Carlo approach in which we produce many equally possible temperature and rainfall histories by randomly sampling each month's temperature and rainfall as a random value from a probability distribution. For our example analysis we simply use a uniform distribution with a range equal to the interpolation uncertainty (limiting rainfall to a minimum of 0 mm). Many trends can then be calculated, with their distribution used to infer the reliability of the analysis. For a location with high uncertainty, the possible temperature and rainfall histories can vary widely around the single interpolated temperature and rainfall history, resulting in a wide distribution of possible trends (Fig. 8a). In other instances, the trend may be stronger than the uncertainty, meaning that while the strength of the trend varies, its direction can be clearly established (Fig. 8b). At locations where there is little uncertainty and hence minimal variation in possible temperature and rainfall histories, the trend can be established precisely (Fig. 8c).
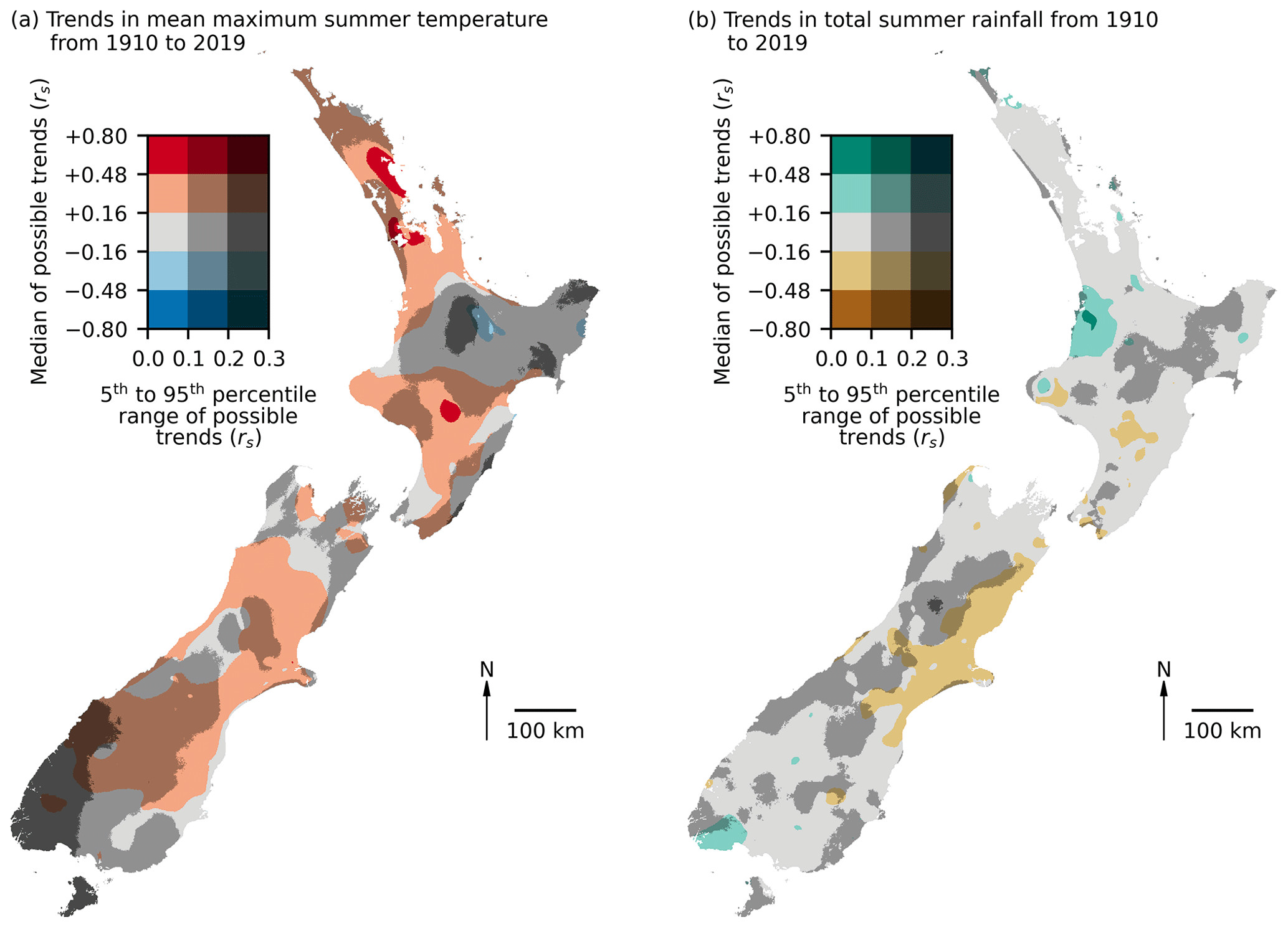
Figure 9Spatial uncertainty analysis for the summer months (December, January, and February) trends in (a) mean maximum temperature, and (b) total rainfall across New Zealand. Trends were calculated as a Spearman's Rank (rs) between temperature or rainfall and time from 1910 to 2019 for 100 possible histories that were within the range of uncertainty for the interpolated values for each month. The median rs value is visualised as a diverging colour scheme indicating positive or negative trends in temperature and rainfall. Uncertainty is visualised by the 5th to 95th percentile range of rs values as a measure of uncertainty such that darker shades of each colour indicate areas with greater uncertainty.
If this trend analysis with uncertainty process is repeated for every location, spatial trends can be analysed. The challenge is then how to visualise the spatial pattern of uncertainty. Based on guidance relating to the cartographic visualisation of uncertainty (Kaye et al., 2012; Retchless and Brewer, 2016), we selected a diverging colour scheme to show trends as the median rs of the possible temperature and rainfall histories. To mask locations of increasing uncertainty, we used a value-by-alpha approach (Roth et al., 2010) that overlays a black mask that is increasingly opaque in locations of increasing uncertainty that is measured as the 5th to 95th percentile range of the rs of the possible temperature and rainfall histories. The resulting map indicates that in some regions there are clear trends in temperature and rainfall patterns over time, but in other regions the uncertainty is too large to reliably make inferences from them (Fig. 9). Areas of high uncertainty are not randomly distributed and are instead concentrated in areas with higher elevations and those with lower or more distant data availability (Fig. 1). However, the exceptions to these general patterns again highlight the importance of providing specific uncertainty data for all interpolations. So, while our evaluation indicates that areas ≥500 m elevation are generally less accurate than areas <500 m elevation (Fig. 6), users of HOTRUNZ should refer to the individual uncertainty data associated with their specific locations of interest because general rules may not always apply.
The results from our trend analysis (Fig. 9) clearly demonstrate that it is possible to produce a long-term history of interpolated temperature and rainfall and emphasise the importance of quantifying the uncertainty of all interpolations. Of course, the approach we have used here is simply trying to illustrate the potential of the uncertainty data and should not be interpreted as the best or only analytical approach. It is obviously impossible for us to give guidance on how to incorporate uncertainty into all possible applications, but the Monte Carlo approach we present could be adapted to many situations. For example, the trend analysis shown here could be extended for those users interested in comparing long-term environmental data to weather data to identify associations between an environmental process and temperature and rainfall (Girardin and Wotton, 2009).
We have stressed the importance of quantifying uncertainty when interpolating rainfall and temperature variables and have applied a novel approach that matches every interpolation estimate with an associated measure of uncertainty in the variables' units. However, while uncertainty in geographical information results from a combination of geographical abstraction, data acquisition, and geoprocessing (Zhang and Goodchild, 2002) our measure of uncertainty only captures the uncertainty associated with geoprocessing. Therefore, while the quantified uncertainty should alert potential users of locations where the interpolation is likely to be less reliable, potential users will still need to apply their own assessment regarding uncertainty associated with geographical abstraction and data acquisition. For example, we have used a geographical abstraction based upon 1 km2 grid cells, but for some applications this abstraction may be too coarse, creating uncertainty about patterns at finer scales. Similarly, while we deliberately excluded unreliable weather station data, the amount of data varies through space and time, and uncertainty associated with interpolations will generally be higher in locations where there are fewer data and the spatial pattern of the variable being interpolated is more complex (Etherington, 2020).
While temperature and rainfall are key environmental variables influencing many ecological and physical processes, other variables could similarly be explored for different contexts. Climatologies also exist for solar radiation, humidity, pressure deficit, and wind speed (McCarthy et al., 2021) for which matching monthly statistics from weather station data are available (NIWA, 2020); expanding the variable coverage to include these variables could be a useful addition to any future version of the dataset.
Some aspects of the temporal and spatial scales of HOTRUNZ could be improved in subsequent refinements of this dataset. One limitation is that the monthly temporal resolution does not capture extreme but short-duration weather events. For example, in July of 1996 there was an extreme cold snap that had significant effects on vegetation in southern New Zealand (Bannister, 2003) but is not evident in our data that average minimum temperatures over the whole month. We only had access to monthly climatologies on which to base our interpolations, but if openly available weekly, or even daily, climatologies were created then it would be possible to interpolate historical weather at a finer temporal resolution to better capture extreme weather events of short durations.
While improving temporal resolution would require the creation of new climatologies, the spatial resolution could be improved up to 100 m with the climatologies used here. This improvement could be beneficial in the mountainous areas of New Zealand where temperatures can vary considerably within the 1 km resolution of our grids. Future improvements in temporal and spatial resolution would benefit from a more efficient computational workflow. Our computational workflow limited our processing to a 1 km resolution, but future versions could either leverage high-performance computing or, to maintain a high degree of openness, continue to use desktop computing but with discrete natural neighbour interpolation leveraging the power of graphics processing units that are well suited to this method (Park et al., 2006).
We believe there is little point in extending the temporal extent of the dataset. The growth of MAE associated with the reduction of temperature and rainfall data pre-1910 (Fig. 4) indicates the available weather station data are insufficient to reliably estimate historical temperature and rainfall using our approach before the 20th century. While there are sources of additional temperature and rainfall data held in archives (Lorrey and Chappell, 2016) palaeo-environmental techniques may provide a better option for longer-term temperature and rainfall information (Cook et al., 2006; Duncan et al., 2010). There was a subtle increase in MAE towards the present that may be a function of a reduction in weather station data, particularly rainfall data, and perhaps a growing temporal mismatch between the 1950–1980 climatologies used to aid the interpolation (Fig. 6). This indicates that continuing to use interpolation methods may become less feasible in the future. More recent climatologies could be produced to provide more temporally relevant climate data, but satellite data may provide a more useful data source for more recent temperature and rainfall history (Funk et al., 2015). We believe our interpolation approach is most valid for the pre-satellite era and that by producing data that span part of the satellite era we provide a useful overlap for comparative purposes that could allow for a transition between historical temperature and rainfall data sources.
All HOTRUNZ analyses were conducted using an open-source software Python computational framework (https://www.python.org/, last access: 17 June 2022; Pérez et al., 2011) in conjunction with the gdal (https://gdal.org, last access: 17 June 2022; GDAL/OGR contributors, 2021), pyproj (https://doi.org/10.5281/zenodo.3783866; Snow et al., 2020), NumPy (https://numpy.org/, 17 June 2022; Harris et al., 2020a), SciPy (https://scipy.org/, last access: 17 June 2022; Virtanen et al., 2020), numba (https://numba.pydata.org/, last access: 7 June 2022; Lam et al., 2015), and Matplotlib (https://matplotlib.org/, last access: 17 June 2022; Hunter, 2007) packages. All the resulting code used to process data and plot figures presented here (Etherington, 2021) is openly available under an MIT Licence from the Manaaki Whenua – Landcare Research DataStore https://doi.org/10.7931/yk7g-vz81.
The resulting HOTRUNZ data (Etherington et al., 2021) are openly available in non-proprietary file formats under a Creative Commons by Attribution 4.0 Licence and are archived at the Manaaki Whenua – Landcare Research DataStore https://doi.org/10.7931/zmvz-xf30.
We present HOTRUNZ as a, rather than the, history of New Zealand temperature and rainfall; it would be possible to repeat the process using equally defensible quantitative methods and obtain different results. Likewise, changes in the spatial or temporal resolution will result in different patterns; however, there is no single best resolution as this will vary depending on the desired application. Nevertheless, as HOTRUNZ matches the highest available spatial and temporal extent and resolution of any currently available open-access grids (Table 1), we believe that in creating HOTRUNZ we have significantly improved the ability for environmental and ecological scientists in New Zealand to understand how changing temperature and rainfall patterns have affected various environmental and ecological processes. Even with the spatially and temporally complex patterns of uncertainty, which are sometimes large, it is still possible to find consistent trends in temperature and rainfall (Fig. 9). We hope our efforts to produce interpolation estimates with associated uncertainty, and examples of how to build that uncertainty into any analyses, will encourage the quantification and visualisation of uncertainty in weather and climate datasets elsewhere.
The supplement related to this article is available online at: https://doi.org/10.5194/essd-14-2817-2022-supplement.
TRE, GLWP, and JMW conceived and developed the idea. TRE developed the code and performed the data processing. TRE, GLWP, and JMW wrote the manuscript.
The contact author has declared that neither they nor their co-authors have any competing interests.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work was supported by the Strategic Science Investment Funding for Crown Research Institutes from the New Zealand Ministry of Business, Innovation and Employment's Science and Innovation Group and The University of Auckland Faculty Research Development Fund (grant no. 3702237).
This paper was edited by Alexander Gruber and reviewed by three anonymous referees.
Abatzoglou, J. T., Dobrowski, S. Z., Parks, S. A., and Hegewisch, K. C.: TerraClimate, a high-resolution global dataset of monthly climate and climatic water balance from 1958–2015, Scientific Data, 5, 170191, https://doi.org/10.1038/sdata.2017.191, 2018.
Bannister, P.: Are frost hardiness ratings useful predictors of frost damage in the field? A test using damage records from the severe frost in South Otago and Southland, New Zealand, July 1996, New. Zeal. J. Bot., 41, 555–569, https://doi.org/10.1080/0028825X.2003.9512869, 2003.
Clark, P. J. and Evans, F. C.: Distance to nearest neighbor as a measure of spatial relationships in populations, Ecology, 35, 445–453, 1954.
Cook, E. R., Buckley, B. M., Palmer, J. G., Fenwick, P., Peterson, M. J., Boswijk, G., and Fowler, A.: Millennia-long tree-ring records from Tasmania and New Zealand: a basis for modelling climate variability and forcing, past, present and future, J. Quat. Sci., 21, 689–699, https://doi.org/10.1002/jqs.1071, 2006.
de Vos, M. G., Hazeleger, W., Bari, D., Behrens, J., Bendoukha, S., Garcia-Marti, I., van Haren, R., Haupt, S. E., Hut, R., Jansson, F., Mueller, A., Neilley, P., van den Oord, G., Pelupessy, I., Ruti, P., Schultz, M. G., and Walton, J.: Open weather and climate science in the digital era, Geosci. Commun., 3, 191–201, https://doi.org/10.5194/gc-3-191-2020, 2020.
Duncan, R. P., Fenwick, P., Palmer, J. G., McGlone, M. S., and Turney, C. S. M.: Non-uniform interhemispheric temperature trends over the past 550 years, Clim. Dynam., 35, 1429–1438, https://doi.org/10.1007/s00382-010-0794-2, 2010.
Etherington, T. R.: Discrete natural neighbour interpolation with uncertainty using cross-validation error-distance fields, Peer. J. Comput. Sci., 6, e282, https://doi.org/10.7717/peerj-cs.282, 2020.
Etherington, T. R.: Code for A History of Open Temperature and Rainfall with Uncertainty in New Zealand (HOTRUNZ), DataStore [code], https://doi.org/10.7931/yk7g-vz81, 2021.
Etherington, T. R., Perry, G. L. W., and Wilmshurst, J. M.: Data for A History of Open Temperature and Rainfall with Uncertainty in New Zealand (HOTRUNZ), DataStore [data set], https://doi.org/10.7931/zmvz-xf30, 2021.
Fick, S. E. and Hijmans, R. J.: WorldClim 2: new 1 km spatial resolution climate surfaces for global land areas, Int. J. Climatol., 37, 4302–4315, 10.1002/joc.5086, 2017.
Foley, A. M.: Uncertainty in regional climate modelling: a review, Prog. Phys. Geogr., 34, 647–670, 10.1177/0309133310375654, 2010.
Funk, C., Verdin, A., Michaelsen, J., Peterson, P., Pedreros, D., and Husak, G.: A global satellite-assisted precipitation climatology, Earth Syst. Sci. Data, 7, 275–287, https://doi.org/10.5194/essd-7-275-2015, 2015.
GDAL/OGR Geospatial Data Abstraction software Library: https://gdal.org (last access: 17 June 2022), 2021.
Girardin, M. P. and Wotton, B. M.: Summer moisture and wildfire risks across Canada, J. Appl. Meteorol. Climatol., 48, 517–533, https://doi.org/10.1175/2008JAMC1996.1, 2009.
Gordo, O. and Sanz, J. J.: Phenology and climate change: a long-term study in a Mediterranean locality, Oecologia, 146, 484–495, https://doi.org/10.1007/s00442-005-0240-z, 2005.
Gregory, S.: Statistical Methods and the Geographer, 4th edn., Longman, London, 240 pp., ISBN 0-582-48186-4, 1978.
Harris, C. R., Millman, K. J., van der Walt, S. J., Gommers, R., Virtanen, P., Cournapeau, D., Wieser, E., Taylor, J., Berg, S., Smith, N. J., Kern, R., Picus, M., Hoyer, S., van Kerkwijk, M. H., Brett, M., Haldane, A., del Río, J. F., Wiebe, M., Peterson, P., Gérard-Marchant, P., Sheppard, K., Reddy, T., Weckesser, W., Abbasi, H., Gohlke, C., and Oliphant, T. E.: Array programming with NumPy, Nature, 585, 357–362, https://doi.org/10.1038/s41586-020-2649-2, 2020a.
Harris, I., Osborn, T. J., Jones, P., and Lister, D.: Version 4 of the CRU TS monthly high-resolution gridded multivariate climate dataset, Sci. Data, 7, 109, https://doi.org/10.1038/s41597-020-0453-3, 2020b.
Hofstra, N., Haylock, M., New, M., Jones, P., and Frei, C.: Comparison of six methods for the interpolation of daily, European climate data, J. Geophys. Res., 113, D21110, 10.1029/2008JD010100, 2008.
Hunter, J. D.: Matplotlib: a 2D graphics environment, Comput. Sci. Engin., 9, 90–95, https://doi.org/10.1109/MCSE.2007.55, 2007.
Karger, D. N., Conrad, O., Böhner, J., Kawohl, T., Kreft, H., Soria-Auza, R. W., Zimmermann, N. E., Linder, H. P., and Kessler, M.: Climatologies at high resolution for the earth's land surface areas, Sci. Data, 4, 170122, 10.1038/sdata.2017.122, 2017.
Kaye, N. R., Hartley, A., and Hemming, D.: Mapping the climate: guidance on appropriate techniques to map climate variables and their uncertainty, Geosci. Model Dev., 5, 245–256, https://doi.org/10.5194/gmd-5-245-2012, 2012.
Keller, V. D. J., Tanguy, M., Prosdocimi, I., Terry, J. A., Hitt, O., Cole, S. J., Fry, M., Morris, D. G., and Dixon, H.: CEH-GEAR: 1 km resolution daily and monthly areal rainfall estimates for the UK for hydrological and other applications, Earth Syst. Sci. Data, 7, 143–155, https://doi.org/10.5194/essd-7-143-2015, 2015.
Lam, S. K., Pitrou, A., and Seibert, S.: Numba: A LLVM-Based Python JIT Compiler, Proceedings of the Second Workshop on the LLVM Compiler Infrastructure in HPC, 7, 1–6, 10.1145/2833157.2833162, 2015.
Leathwick, J., Morgan, F., Wilson, G., Rutledge, D., McLeod, M., and Johnson, K.: Land environments of New Zealand: a technical guide, Ministry for the Environment, Wellington, 237 pp., 2002.
Lorrey, A. M. and Chappell, P. R.: The ”dirty weather” diaries of Reverend Richard Davis: insights about early colonial-era meteorology and climate variability for northern New Zealand, 1839–1851, Clim. Past, 12, 553–573, https://doi.org/10.5194/cp-12-553-2016, 2016.
Lyra, G. B., Correia, T. P., de Oliveira-Júnior, J. F., and Zeri, M.: Evaluation of methods of spatial interpolation for monthly rainfall data over the state of Rio de Janeiro, Brazil, Theor. Appl. Climatol., 134, 955–965, https://doi.org/10.1007/s00704-017-2322-3, 2018.
McCarthy, J. K., Leathwick, J. R., Roudier, P., Barringer, J. R. F., Etherington, T. R., Morgan, F. J., Odgers, N. P., Price, R. H., Wiser, S. K., and Richardson, S. J.: New Zealand Environmental Data Stack (NZEnvDS): A standardised collection of spatial layers for environmental modelling and site characterisation, N. Z. J. Ecol., 45, 3440, https://doi.org/10.20417/nzjecol.45.31, 2021.
Muñoz Sabater, J.: ERA5-Land monthly averaged data from 1981 to present, Copernicus Climate Change Service (C3S) Climate Data Store (CDS), [data set], https://doi.org/10.24381/cds.68d2bb30, 2019.
NIWA: NIWA's National Climate Database on the Web, cliflo [data set], https://cliflo.niwa.co.nz/, last access: 15 June 2020.
Park, S. W., Linsen, L., Kreylos, O., Owens, J. D., and Hamann, B.: Discrete Sibson interpolation, IEEE Trans. Visual. Comput. Graph., 12, 243–253, https://doi.org/10.1109/TVCG.2006.27, 2006.
Pérez, F., Granger, B. E., and Hunter, J. D.: Python: an ecosystem for scientific computing, Comput. Sci. Eng., 13, 13–21, https://doi.org/10.1109/MCSE.2010.119, 2011.
Remesan, R., Bellerby, T., and Frostick, L.: Hydrological modelling using data from monthly GCMs in a regional catchment, Hydrol. Proc., 28, 3241–3263, https://doi.org/10.1002/hyp.9872, 2014.
Retchless, D. P. and Brewer, C. A.: Guidance for representing uncertainty on global temperature change maps, Int. J. Climatol., 36, 1143–1159, https://doi.org/10.1002/joc.4408, 2016.
Roth, R. E., Woodruff, A. W., and Johnson, Z. F.: Value-by-alpha maps: an alternative technique to the cartogram, Cartogr. J., 47, 130–140, https://doi.org/10.1179/000870409x12488753453372, 2010.
Sibson, R.: A brief description of natural neighbour interpolation, in: Interpreting Multivariate Data, edited by: Barnett, V., Wiley, Chichester, 21–36, 374 pp., ISBN 0-471-28039-9, 1981.
Snow, A. D., Whitaker, J., Cochran, M., Van den Bossche, J., Mayo, C., de Kloe, J., Karney, C., Ouzounoudis, G., Dearing, J., Lostis, G., Heitor, Filipe, May, R., Itkin, M., Couwenberg, B., Berardinelli, G., The Gitter Badger, Eubank, N., Dunphy, M., Brett, M., Raspaud, M., Aurélio da Costa, M., Evers, K., Ranalli, J., de Maeyer, J., Popov, E., Gohlke, C., Willoughby, C., Barker, C., and Wiedemann, B. M.: pyproj4/pyproj: 2.6.1 Release, [code], https://doi.org/10.5281/zenodo.3783866, 2020.
Spearman, C.: The proof and measurement of association between two things, Am. J. Psychol., 15, 72–101, https://doi.org/10.2307/1412159, 1904.
Stahl, K., Moore, R. D., Floyer, J. A., Asplin, M. G., and McKendry, I. G.: Comparison of approaches for spatial interpolation of daily air temperature in a large region with complex topography and highly variable station density, Agr. Forest Meteorol., 139, 224–236, https://doi.org/10.1016/j.agrformet.2006.07.004, 2006.
Stewart, S. B., Elith, J., Fedrigo, M., Kasel, S., Roxburgh, S. H., Bennett, L. T., Chick, M., Fairman, T., Leonard, S., Kohout, M., Cripps, J. K., Durkin, L., and Nitschke, C. R.: Climate extreme variables generated using monthly time-series data improve predicted distributions of plant species, Ecography, 44, 626–639, https://doi.org/10.1111/ecog.05253, 2021.
Tait, A. and Macara, G.: Evaluation of interpolated daily temperature data for high elevation areas in New Zealand, Weather Climate, 34, 36–49, https://doi.org/10.2307/26169743, 2014.
Tait, A., Henderson, R., Turner, R., and Zheng, X. G.: Thin plate smoothing spline interpolation of daily rainfall for New Zealand using a climatological rainfall surface, Int. J. Climatol., 26, 2097–2115, https://doi.org/10.1002/joc.1350, 2006.
Tait, A., Sturman, J., and Clark, M.: An assessment of the accuracy of interpolated daily rainfall for New Zealand, J. Hydrol. (New Zealand), 51, 25–44, 2012.
Virtanen, P., Gommers, R., Oliphant, T. E., Haberland, M., Reddy, T., Cournapeau, D., Burovski, E., Peterson, P., Weckesser, W., Bright, J., van der Walt, S. J., Brett, M., Wilson, J., Millman, K. J., Mayorov, N., Nelson, A. R. J., Jones, E., Kern, R., Larson, E., Carey, C. J., Polat, İ., Feng, Y., Moore, E. W., VanderPlas, J., Laxalde, D., Perktold, J., Cimrman, R., Henriksen, I., Quintero, E. A., Harris, C. R., Archibald, A. M., Ribeiro, A. H., Pedregosa, F., van Mulbregt, P., Vijaykumar, A., Bardelli, A. P., Rothberg, A., Hilboll, A., Kloeckner, A., Scopatz, A., Lee, A., Rokem, A., Woods, C. N., Fulton, C., Masson, C., Häggström, C., Fitzgerald, C., Nicholson, D. A., Hagen, D. R., Pasechnik, D. V., Olivetti, E., Martin, E., Wieser, E., Silva, F., Lenders, F., Wilhelm, F., Young, G., Price, G. A., Ingold, G.-L., Allen, G. E., Lee, G. R., Audren, H., Probst, I., Dietrich, J. P., Silterra, J., Webber, J. T., Slavič, J., Nothman, J., Buchner, J., Kulick, J., Schönberger, J. L., de Miranda Cardoso, J. V., Reimer, J., Harrington, J., Rodríguez, J. L. C., Nunez-Iglesias, J., Kuczynski, J., Tritz, K., Thoma, M., Newville, M., Kümmerer, M., Bolingbroke, M., Tartre, M., Pak, M., Smith, N. J., Nowaczyk, N., Shebanov, N., Pavlyk, O., Brodtkorb, P. A., Lee, P., McGibbon, R. T., Feldbauer, R., Lewis, S., Tygier, S., Sievert, S., Vigna, S., Peterson, S., More, S., Pudlik, T., Oshima, T., Pingel, T. J., Robitaille, T. P., Spura, T., Jones, T. R., Cera, T., Leslie, T., Zito, T., Krauss, T., Upadhyay, U., Halchenko, Y. O., and Vázquez-Baeza, Y.: SciPy 1.0: fundamental algorithms for scientific computing in Python, Nat. Methods, 17, 261–272, https://doi.org/10.1038/s41592-019-0686-2, 2020.
Willmott, C. J. and Robeson, S. M.: Climatologically aided interpolation (CAI) of terrestrial air temperature, Int. J. Climatol., 15, 221–229, 1995.
Willmott, C. J. and Matsuura, K.: On the use of dimensioned measures of error to evaluate the performance of spatial interpolators, Int. J. Geogr. Inf. Sci., 20, 89–102, https://doi.org/10.1080/13658810500286976, 2006.
Zhang, J. and Goodchild, M.: Uncertainty in Geographical Information, Taylor & Francis, London, 266 pp., ISBN 0-415-24334-3, 2002.
- Abstract
- Introduction
- Weather and climatology data
- Interpolation with uncertainty
- Interpolation evaluation
- Using the uncertainty data
- Limitations and future recommendations
- Code availability
- Data availability
- Conclusions
- Author contributions
- Competing interests
- Disclaimer
- Financial support
- Review statement
- References
- Supplement
- Abstract
- Introduction
- Weather and climatology data
- Interpolation with uncertainty
- Interpolation evaluation
- Using the uncertainty data
- Limitations and future recommendations
- Code availability
- Data availability
- Conclusions
- Author contributions
- Competing interests
- Disclaimer
- Financial support
- Review statement
- References
- Supplement