the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 07 Aug 2019
| 07 Aug 2019
STEAD: a high-resolution daily gridded temperature dataset for Spain
Roberto Serrano-Notivoli
Santiago Beguería
Martín de Luis
Using 5520 observatories covering the whole territory of Spain (about 1 station per 90 km2 considering the whole period), a daily gridded maximum and minimum temperature was built covering a period from 1901 to 2014 in peninsular Spain and 1971 to 2014 in the Balearic and Canary Islands. A comprehensive quality control was applied to the original data, and the gaps were filled on each day and location independently. Using the filled data series, a grid of 5 km × 5 km spatial resolution was created by estimating daily temperatures and their corresponding uncertainties at each grid point. Four daily temperature indices were calculated to describe the spatial distribution of absolute maximum and minimum temperature, number of frost days and number of summer days in Spain. The southern plateau showed the maximum values of maximum absolute temperature and summer days, while the minimum absolute temperature and frost days reached their maximums at the northern plateau. The use of all the available information, the complete quality control and the high spatial resolution of the grid allowed for an accurate estimate of temperature that represents a precise spatial and temporal distribution of daily temperatures in Spain. The STEAD dataset is publicly available at https://doi.org/10.20350/digitalCSIC/8622 and can be cited as Serrano-Notivoli et al. (2019).
- Article
(5493 KB) - Full-text XML
-
Supplement
(2497 KB) - BibTeX
- EndNote





Despite a clear improvement over the last decades in meteorological measurement techniques, the inclusion of automated systems with near-real-time information submission or the increasing number of stations with a growing number of recorded variables, the existing climatic information is still unrepresentative in many territories. The low density of stations in isolated areas and the great variability in the number and location of observations over time represent a substantial problem. Despite these problems, or perhaps due to them, different teams dedicated a great deal of effort to creating reliable gridded climatic datasets covering large time periods. Between all the climate variables, temperature datasets are among the most popular, such as the CRUTEM dataset (1850–2017) (Jones et al., 2012), the dataset of Willmott and Matsuura (2001) covering the 1900–2014 period, WorldClim (1970–2000) (Fick and Hijmans, 2017), GISTEMP (1880–2017) (Hansen et al., 2010) or BEST (1850–2017) (Rohde et al., 2013). In this regard, temperature has been also widely studied in Spain, in terms of its spatio-temporal distribution (e.g. Peña-Angulo et al., 2016) and temporal trends (e.g. González-Hidalgo et al., 2015, 2018). Nevertheless, most of the existing works addressed coarse temporal scales or used individual stations for detailed regions (e.g. Villeta et al., 2018).
Monthly gridded datasets have enabled a better understanding of the climatic dynamics of the planet, especially as an element of quantification and validation of climate change, due to their ability to reproduce the mid-frequency variability of temperature. However, most of the methodologies used in those works are not suitable for addressing the variability of temperature at the daily scale, due to the higher spatial and temporal variability and because of the larger number of input stations required to build a reliable dataset. Although climate change with respect to temperature is often quantified in terms of changes in its mean values, most of the risks attributed to climate change are, however, related to temperature extremes that occur at shorter timescales, such as the daily scale. The study of climate change signals in temperature extremes is therefore still largely pending due to the absence of reliable daily datasets representative of most of the territories. This absence of daily gridded datasets, with several remarkable exceptions (e.g. Cornes et al., 2018; Lussana et al., 2018), is linked to (i) an absence of contrasted reconstruction methodologies owing to the different temporal and spatial structure of daily data in contrast to monthly or annual values and (ii) an absence of contrasted quality control protocols for daily time series.
In addition, the reliability of a dataset not only depends on the resolution but on the consistency of the data. Quality control processes are crucial to create trustworthy datasets, and, although the many existing approaches (e.g. Haylock et al., 2008; Klein-Tank et al., 2002; Klok and Klein-Tank, 2009) apply basic procedures, some others go beyond and check for spatial consistency (e.g. Lussana et al., 2018; Feng et al., 2004), which is recommended when using high-density networks.
The same problems intervene, though more severely, in global datasets. At the subregional and local scales, the understanding of high-resolution climatic variability is of key importance in a context of global change, and these datasets often are not adequate to address specific research questions such as extremes or small variations affecting other components of the natural system, due to a low spatial or temporal resolution.
Daily scale in temperature information is of key importance in many areas. The E-OBS dataset (Cornes et al., 2018), at a maximum spatial resolution of 0.1∘, is the best example of a daily gridded dataset for large international areas thanks to the integration of thousands of transboundary climate data. However, it does not pretend to be comprehensive for specific regions (Van Den Besselaar et al., 2015), and a deeper analysis with more information is required for higher spatial scales. The Spanish territory exhibits a great climatic variability with very different regimes in a relatively small area that leads to high risks such as increments in the frequency and magnitude of extreme events. Currently, there are only two daily gridded datasets available for Spain: E-OBS (the Spanish part of the European dataset) and Spain02 (Herrera et al., 2016). Although both of them have been checked for their reliability, and are useful for specific purposes, they have limitations that prevent several climatic analyses. For instance, in their construction they did not consider all the available information but only a few stations as basis for creating the grid (229 and 250, respectively), prioritizing the longest data series over a higher spatial density. This approach is suitable for wide-ranging temperature studies, yet insufficient when addressing small areas with great variability. The experience acquired in the SPREAD dataset (Serrano-Notivoli et al., 2017a) development set the basis for a solid and reliable daily gridded precipitation dataset creation. Using the same framework with a complete renewal of the core calculations, we developed a new methodology for daily temperature dataset reconstruction and grid creation.
This article introduces the STEAD (Spanish TEmperature At Daily scale) dataset, a new high-resolution daily gridded (maximum and minimum) temperature dataset for Spain covering the period 1901–2014 for peninsular Spain and 1971–2014 for the Balearic and Canary Islands. Based on the available quality-controlled temperature information in Spain (more than 5000 stations), we used the same spatial resolution as SPREAD, its corresponding precipitation dataset. We propose (1) a methodology for an exhaustive quality control and (2) a reconstruction methodology using all the available information and based on local regression models.
Section 2 describes the input data, and Sect. 3 explains the methodology used to apply the quality control, fill the gaps in the original series and apply the gridding process. Section 4 shows the results of the method applied to the Spanish temperature network as well as the validation of the reconstruction and gridding procedures. Also, a brief description of four climatic indices based on daily temperature is shown. Results are discussed in Sect. 5 and summarized in the conclusions at Sect. 7 after the specification of the availability of the dataset in Sect. 6.
We used 5520 observatories covering the whole territory of Spain, which was divided in three areas to compute the grid: (1) peninsular Spain (492 175 km2), with 5056 stations covering the period 1901–2014; (2) Balearic Islands (4992 km2), with 124 stations covering 1971–2014; and (3) Canary Islands (7493 km2), which covered 1971–2014 using 340 stations (Fig. 1 bottom panel). The data were sourced from the Spanish Meteorological Agency (AEMET) and from the Spanish Ministry of Environment and Agriculture (MAGRAMA). Daily maximum and minimum values of temperatures series were used from all the observatories.

Figure 1Location of the temperature stations and categorization by percentage of recorded data.
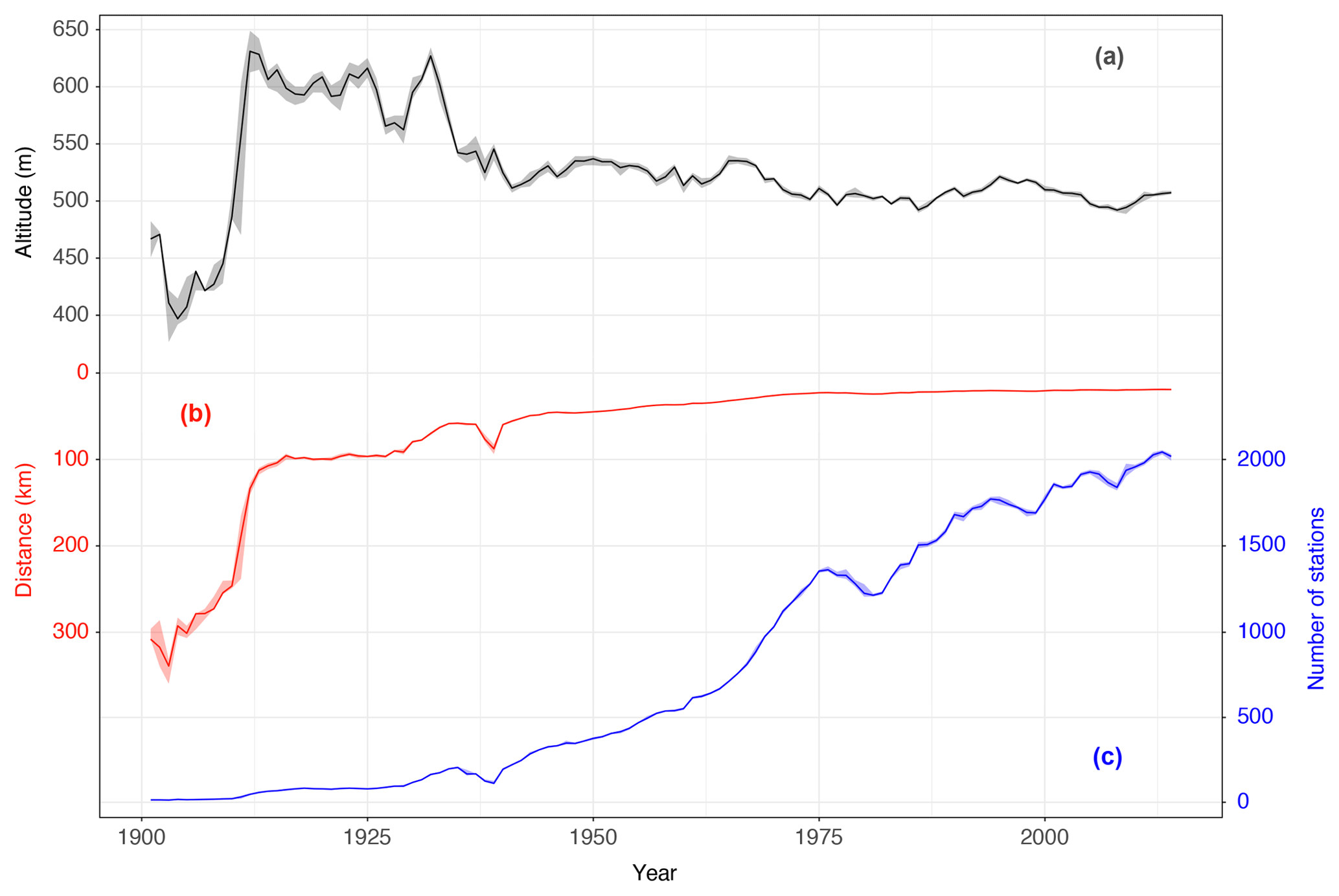
Figure 2Median altitude of the stations by year (a, black), median distance between stations (b, red) and median number of stations per year (c, blue). Coloured shadings indicate intervals between 25th and 75th percentiles.
The mean number of stations per year increased all over the studied period (Fig. 2b). The first years of the 20th century had only a few stations available (Brunet et al., 2006; González-Hidalgo et al., 2015) with a great distance between them. Then, the number increases with the break of the Spanish Civil War (1936–1939) until the decade of the 1990s. Until then, all the information sourced from AEMET, and from those, MAGRAMA stations began to register data until the end of the period (2014). As noted in González-Hidalgo et al. (2015), the mean distance between stations (65.9 km for the whole period) barely changed from the middle of the century as well as their mean elevation (between 500 and 550 m a.s.l.). Before that, the mean altitude experimented hard changes due to the removal or relocation of existing stations and new incorporations.
Furthermore, the first 40 years of the 20th century showed a high intra-annual variability in altitudes (Fig. 2, grey shaded areas) and, to a lesser extent, in distance between stations (Fig. 2, red shaded areas), being almost negligible in the number of stations (Fig. 2, blue shaded areas). This higher inter- and intra-annual variability in the first years than the rest of the period showed that the few available stations were very different between each other. The variability is reduced from 1950 onwards while the number of stations is increased.
We used a 5 km × 5 km regular grid covering the whole peninsular Spain and the Balearic and Canary Islands to estimate maximum and minimum temperature values from the quality-controlled and serially complete original series. The predictor parameters (i.e. latitude, longitude, altitude and distance to the coast) for each grid point were computed as the median of all the possible values of those parameters, covering an area of 5 km × 5 km in which the grid point is the centroid. Despite the differences in the data availability through time, the methodological process creates spatial references that are standardized with the temporal structure of the series to avoid biases or incoherences. In this regard, the chosen spatial resolution accurately reflects the local characteristics of daily temperature in most of the temporal period, while the provided uncertainty values help to understand the reliability of the estimates when the original data have higher variability.
The first stage is a quality control of the original dataset to remove the most obvious wrong data. From this starting point the process (Fig. 3) is based on the computation of reference values (RVs), which are computed for each location and day and then compared with the original values to assess the quality of the data. After a process of standardization, new values are estimated for those days without observations (or removed in the quality control process) to obtain serially complete data series. In a final stage, the complete series are the basis to create new data series for specific pairs of coordinates that may or may not form a regular grid, including a measure of uncertainty for each location and day. The key stages of the methodological process (calculation of RVs, quality control, gap filling and gridding) are the same as that used to create the SPREAD dataset (Serrano-Notivoli et al., 2017a). However, the method basics are completely different since the RV creation has been refined, the quality control has been adapted to temperature data, and the gap filling and gridding processes include now an improved standardization procedure.
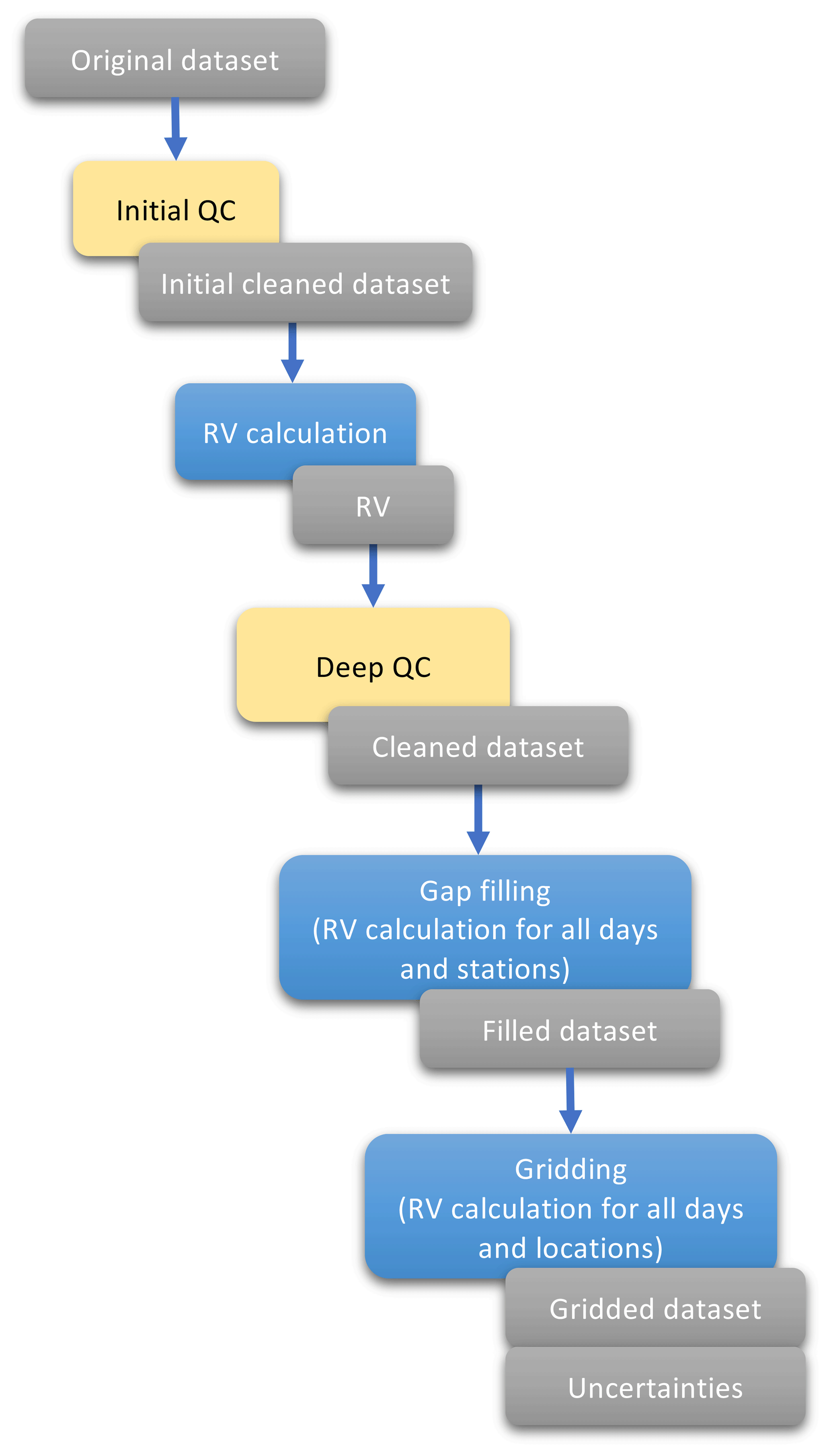
Figure 3Methodological protocol in a nutshell. Grey boxes represent products, yellow boxes are correction processes and blue boxes involve reference value (RV) calculations.
3.1 Initial quality control
The initial quality control (iQC) includes five basic criteria over maximum (Tmax) and minimum (Tmin) temperature: (i) internal coherence, (ii) removal of months containing less than 3 d of data, (iii) the removal of those days out of range considering Tmax ≥50 ∘C or Tmax ∘C and Tmin ≥40 ∘C or Tmin ∘C; (iv) removal of all days in a month with a standard deviation equal to zero (suspect repeated values in the series); and (v) removal of all days in a month if the sum of the differences between maximum and minimum temperatures is equal to zero (suspect duplicated values in TMAX and TMIN).
3.2 Reference values (RVs) as a key process for quality control and reconstruction
Further steps in the quality control and the reconstruction process are based on the computation of reference values (RVs). RVs are obtained by using a k-nearest neighbours regression approach, which is applied to maximum and minimum temperature and to each day and location independently. The RVs are estimated through the combined use of generalized linear mixed models (GLMMs) and generalized linear models (GLMs). The predictors (independent variables) were latitude, longitude, altitude and distance to the coast. The inclusion of these four independent variables and the building of independent models for each site and day considering only the neighbourhood of the site of interest allows for large flexibility and enables capturing local features that may not be captured using other methods which result in larger spatial and temporal regularization.
The methodological procedure is as follows: (i) rough monthly RV values are computed, which are average monthly estimates (i.e. a climatology), obtained using GLMMs and all the available data; (ii) then fine monthly RV, which are monthly time series of temperature, computed using GLMs and data from only the 15 nearest neighbours, and including the rough monthly RV obtained in the previous stage as a covariate; (iii) finally, daily RV values are computed using GLMs and data from the 15 nearest daily observations, plus the fine monthly RV of the corresponding month as an added covariate. The whole process is explained in detail in the following sections.
3.2.1 Rough monthly RV (rmRV)
Monthly time series of daily temperature means and standard deviations were computed. Only the months with complete daily observations were used to fit the model. We used latitude, longitude, altitude and distance to the coast as fixed factors and the year as random factor. The introduction of the year as random factor allows for isolating the fact that one particular year might be colder or warmer than the average on the whole dataset and thus eliminates the random variability arising from the fact that the time period with observed data changes from station to station. The model, fitted independently for each month of the year and for each one of the four dependent variables defined above, can be represented as
where y is a known vector of observations with mean E(y)=Xβ and variance var(y)=σ2; β is an unknown vector of fixed effects; b is an unknown vector of random effects, with mean E(b)=0 and variance–covariance matrix var(b)=G; and X and Z are known model matrices containing the values of the fixed and random variables for the observations y. The models were fit by the maximum likelihood method using the R package lme4 (Bates et al., 2015).
Once the model parameters β, b and σ are obtained, the best linear unbiased predictions (BLUPs) of the mean and standard deviation of daily temperature are calculated for each station (i), year (y) and month (m). At this stage a global model is fit, since all the data are used to fit the model and therefore the coefficients are assumed to be constant in space, an assumption that it is a rough simplification of reality. On the other hand, this configuration allowed us to include all the data for estimating the random year effect. The obtained estimates of mean and standard deviation for maximum and minimum temperature represent highly spatially regularized patterns of monthly temperature and do not consider local spatial variability in the influence of the covariates.
3.2.2 Fine monthly RV (fmRV)
In a second stage, monthly time series of the mean and standard deviation of daily temperature were computed again, but using a local (k-nearest neighbours) regression approach. For each station, the model was fit to data from the 15 nearest observations of each month plus the rmRV values calculated in the previous step. Inclusion of the latter as if they were legitimate observations incorporates a certain amount of spatial regularization that helps to alleviate a problem that may arise when using a purely local regression approach, i.e. an excess of spatial variability, especially in areas where the model extrapolates (in latitude, longitude, altitude or distance to the coast) with respect to the neighbouring locations. A generalized linear model was thus built for each station and month:
were y′ is the local neighbourhood dataset, including the rough monthly RV with mean ; β′ is an unknown vector of local fixed effects; X′ is a known model matrix containing the values of the covariates at the 15 neighbouring sites; and ϵ is an unknown random error, which in the case of the mean temperature was assumed to be normally distributed with zero mean, , and in the case of the temperature standard deviation was modelled as following a Poisson distribution, thus taking only positive values. The obtained estimates of mean and standard deviation for maximum and minimum temperature incorporate the local variability that was lacking in the estimations of the previous step.
An example of rmRV and fmRV for a specific month is shown in the Supplement (Fig. S2).
3.2.3 Daily RV (dRV)
In a third stage, daily maximum and minimum temperatures were predicted based on the 15 nearest observations and the fmRV for the corresponding month, using once again a GLM with Gaussian link:
where y′′ is the local daily neighbourhood dataset, including the fmRV with mean and variance ; β′′ is an unknown vector of daily local fixed effects; and X′ is a known model matrix containing the values of the covariates at the 15 neighbouring sites. The daily estimates of each station () are then standardized (Eq. 4) with the fmRV ( and ) data to keep an equivalent standard deviation as the monthly prediction:
3.3 Quality control
After the initial quality control and the RV calculation, we have the original dataset without the most obvious anomalies and an estimate for each observation. Clearly, the iQC is not enough to remove inconsistencies in temporal and spatial fields. Here a novel approach of an exhaustive quality control over daily temperature data based on paired comparisons between observations () and standardized predictions () is presented (Fig. 4). All stages of this process are carried out independently for maximum and minimum temperature. What we call deep quality control (dQC) considers similarities between observations and estimates through (i) a correlation analysis between daily observations and predictions at each analysed location, year and month and (ii) a quantification on how the differences between daily observed and predicted values (anomalies) are spatially and temporarily distributed.

The process is iterative, which means that when dQC finishes in the first run, and the suspect detected data are removed from the original dataset, the RVs are computed again over this dataset and the dQC runs again. This is iterated until dQC does not detect any suspect data.
3.3.1 Correlation analysis
This analysis is based on the correlation between observations and standardized predictions, and it is independent for each series of daily observations in each month. Considering a single site (i), month (m) and year (y), the correlation () between observed and predicted daily data is computed and then compared with the correlation of its 15 nearest stations in the same month and year (). The index ZCOR () is then computed as the number of standard deviations that the observed correlation deviates from the observed at their neighbours (Eq. 5):
At this point, the correlations and their deviations are used to remove all daily data from the site i and month m if
- a.
or,
- b.
and and ,
with p being the p value of . A negative indicates a lower observed correlation than the neighbours, and indicates that it is highly unlikely that the correlation is plausible in the referred spatial and temporal context.
This part of the quality control procedure aims to detect, amongst others, (partially) repeated sequences of data, duplicated months or sequences in consecutive years, shifted dates in series or, for instance, sequences of data extremely abnormal in their spatial context. All of these anomalies, which are hard to detect with classical approaches, can be potentially identified in this stage.
3.3.2 Daily differences
Using the differences between the observations and the standardized predictions (), two types of anomalies are computed.
-
Spatial anomaly. Each difference is compared with the differences of their 15 nearest stations (). The index is then computed as the number of standard deviations that the observed difference deviates from their neighbours (Eq. 6):
-
Temporal anomaly. Each difference is compared with the differences at the same station in the rest of the days of the same month and year (). The index is then computed as the number of standard deviations that the observed difference deviates from the rest of the days of the month in same station (Eq. 7):
The daily data from the site i and month m are removed if the absolute value of the mean of both spatial and temporal anomalies is higher than the value representing the probability of α<0.0001 (Eq. 8):
When the suspect data have been removed using the daily similarities and differences criteria, the RVs are computed again and the quality control process starts over. This procedure is repeated until no suspect data are detected and removed (see Fig. S6 in the Supplement).
3.4 Gap filling
Once the quality control process is finished, a final set of RVs are computed from the cleaned dataset for those locations and days with missing data. These RVs corresponding with days without observations will fill the gaps, completing the series of original debugged observations ().
3.5 Gridding and uncertainty
With the aim of obtaining a gridded product (a regularly distributed set of data series over space), new RVs are created for each location (id), month (m) and year (y) of the grid in three steps.
-
Grid fmRVs ( and ) are created using the filled dataset ().
-
Grid dRVs () are created using the original filled dataset () and the computed mean monthly references.
-
Finally, the estimates are standardized using the standard deviation monthly references (Eq. 9):
In addition to the estimates of temperature for each grid point (in the second step of gridding process), we computed their corresponding uncertainty, which was calculated as the standard error of the difference between the predicted and the observed values of the 15 neighbours in each day and location.
3.6 Validation
The validation process consisted in the comparison between the observations and the estimates computed for each one of those observations. The assessment was carried out through seven statistical and graphical analyses.
- i.
A graphical comparison and Pearson correlation coefficient calculation of the means of all the 5520 stations considered in the study. Also, the 95th percentile of maximum temperature and 5th percentile of minimum temperature were considered to ascertain the accuracy of the extremes' prediction.
- ii.
A graphical representation of the Pearson correlation frequencies, by month, to show the agreement between observations and estimates.
- iii.
A graphical representation of counts of temperature values, by categories based on absolute values. This is useful to show potential biases in specific ranges of temperature.
- iv.
A collection of statistical tests to compare observations and estimates by altitudinal ranges using daily values. The tests include the mean of observations (OBSm), the mean of estimates (PREDm), the mean absolute error (MAE), the mean error (ME), the ratio of means (RM) and the ratio of standard deviations (RSD).
- v.
Same as iv but by month instead of elevations.
- vi.
A graphical representation of the count of temperature differences between observations and estimates.
- vii.
A graphical representation of the temporal evolution of mean annual uncertainty.
3.7 Example of applications: daily spatial distribution and uncertainties of temperatures
Based on the gridded dataset created from the original data and with the described method, we computed four indices to show the potential applications of the grid: (1) the mean annual maximum value of daily maximum temperature, (2) the mean annual minimum value of daily minimum temperature, (3) the average annual count of days when daily minimum temperature is below 0 ∘C (frost days), and (4) the average annual count of days when daily maximum temperature is over 25 ∘C (summer days). All the indices were presented with their corresponding uncertainty estimate.
4.1 Quality control
Although the quality control was carried out separately, it removed approximately 7.4 % of the original daily values both in maximum and minimum temperatures (Table 1). The initial quality control process (iQC) removed a sum of 59 d out of range (less than 0.01 % of the total) and 1349 months (0.53 %) containing 4308 d (0.04 %) that did not fulfil the minimum standards set at the beginning (see Sect. 3.1). Furthermore, the deep quality control (dQC) removed between 4.5 % and 5.6 % of the months and days considering the similarities between the observations and the estimates, with the number of removed data being slightly higher in minimum temperatures. Most of the correlations in removed data were negative or very low (Fig. 5), which indicates that the observations were very different from the estimates built with their surrounding original values. The average correlations in removed data were negative both in maximum and minimum temperature, showing that the similarities were very low.
Table 1Number of removed days and complete months based on the quality control criteria.
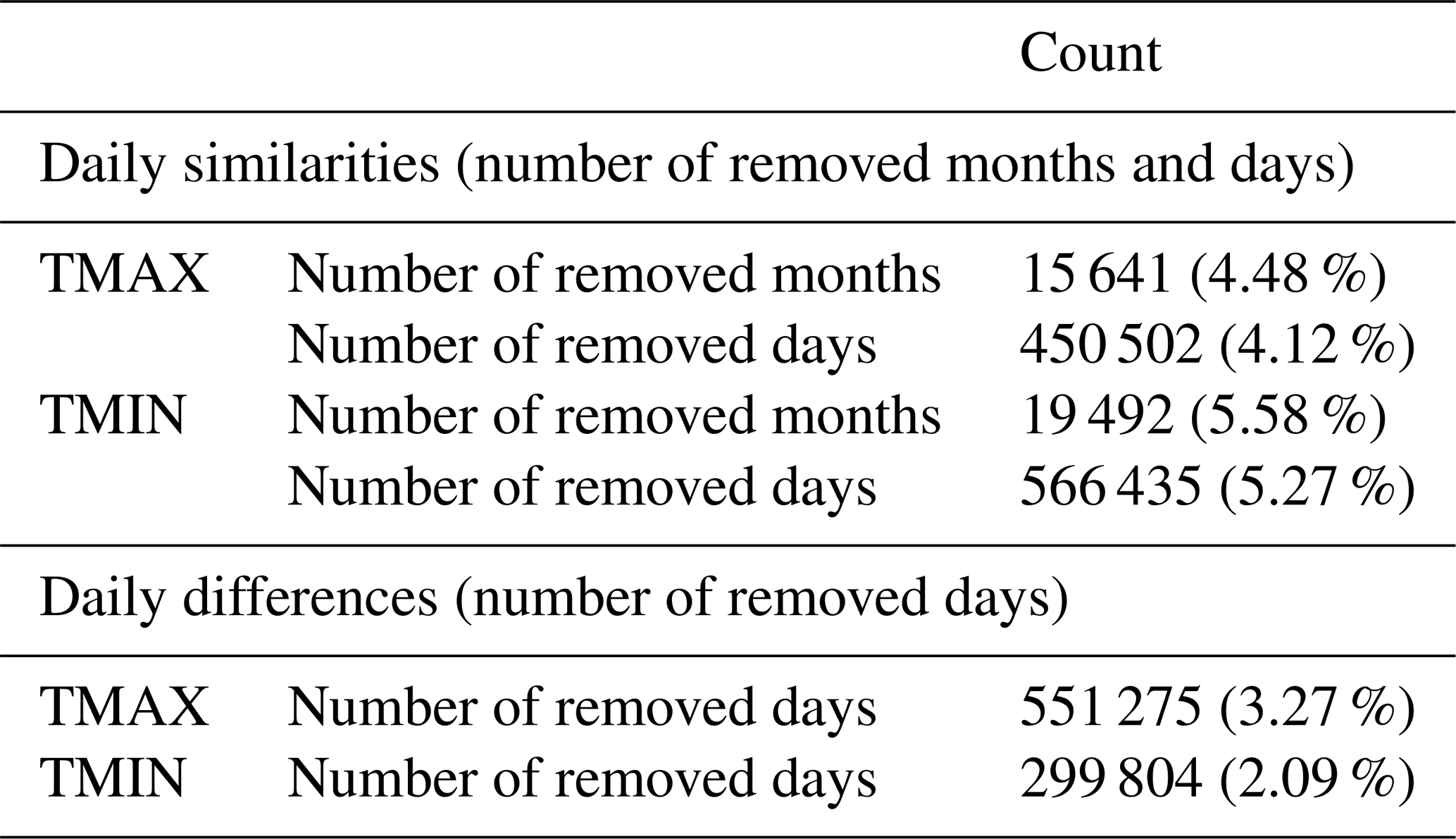

Figure 5Correlation frequencies between observations and estimates of removed data in the quality control process. Maximum (a) and minimum (b) temperatures are shown.
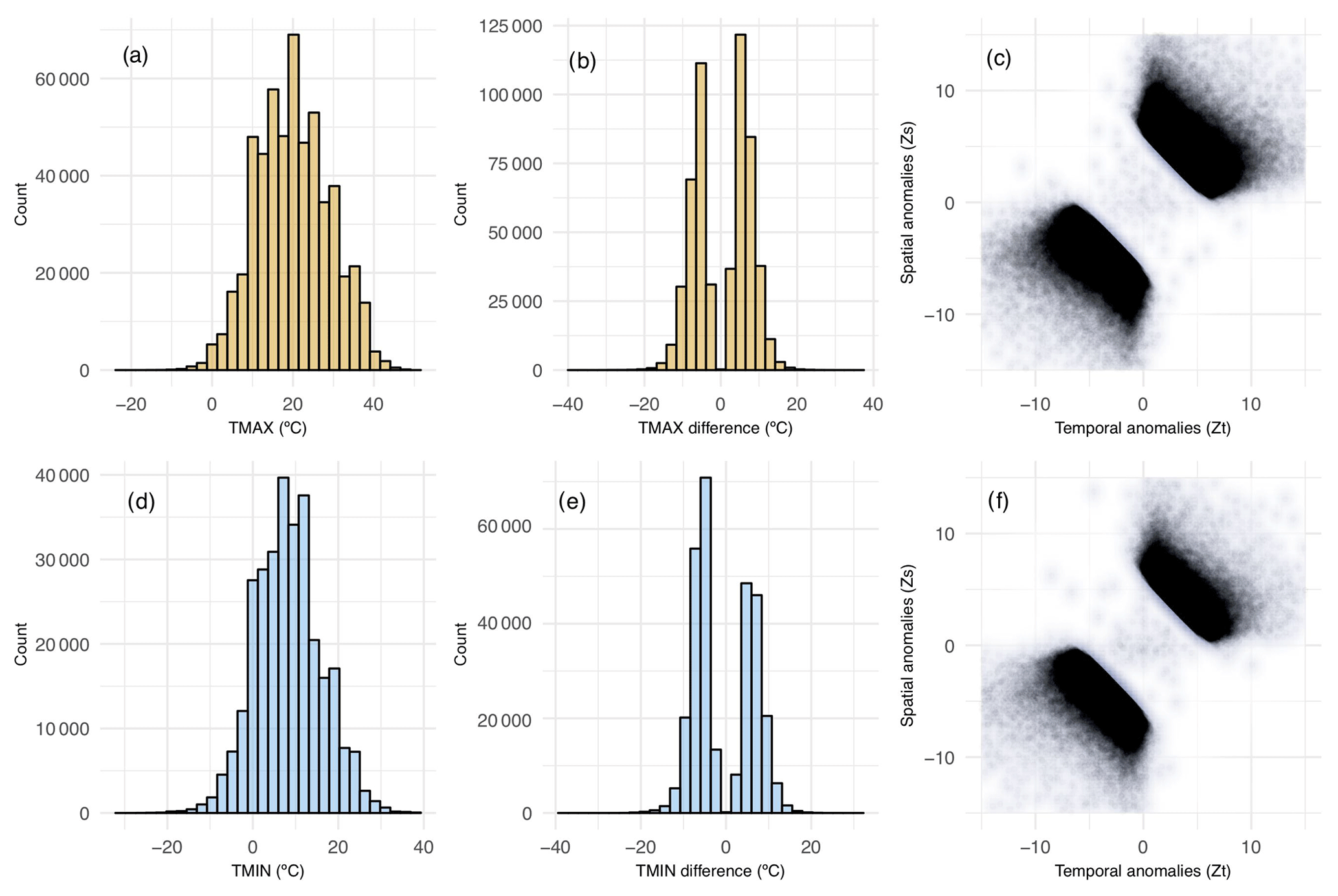
Figure 6Daily maximum (orange, a–c) and minimum (blue, d–f) temperature data removed by the quality control process. (a, d) Removed data by magnitude, (b, e) removed data by differences between observations and estimates, and (c, f) temporal anomalies (Zs) vs. spatial anomalies (Zs).
The number of removed days in maximum temperatures was higher when considering the daily spatio-temporal anomalies (Fig. 6a), without a significant bias in positive or negative differences (Fig. 6b), in contrast to minimum temperatures (Fig. 6e) where negative differences prevailed.
The removed values do not necessarily correspond with climatic extremes but with values that are out of the spatio-temporal context of its neighbouring observations. The fact that the maximum frequency of removed data matches with the average of maximum and minimum temperatures (Fig. 6a and d) suggests that there is no bias in the suspect data detection, and, indeed, the deletions are due to errors in the original data (which we intend to detect) and not to climatic extremes. Furthermore, when looking at the removed data by differences between observations and estimates (Fig. 6b and e), it is noted that the maximum frequency of deletions corresponds to differences near ±10 ∘C, which is not unusual if we think that, probably, those removals are due to recording or transcription errors, related to missing decimals.
Despite the fact that the magnitudes of some of the removed data do not represent anomalous values (Fig. 6c and f), they correspond to significant anomalies in their spatial and temporal context. Beyond the magnitude in absolute terms, the differences between observations and estimates suggest, with an α<0.0001, that those values are very unlikely to be representative in their spatio-temporal context.
Using the reconstructed series, we built a 5 km × 5 km spatial resolution gridded dataset of maximum and minimum temperature. The values were estimated for the 1901–2014 period in peninsular Spain and for the 1971–2014 period in the Balearic and Canary Islands. A measure of uncertainty was added to each day and grid point of the dataset.
4.2 Quality-controlled dataset: observations–estimates comparison
Daily temperatures were estimated at the same location and days as the original data series but without considering the original values in each case using a leave-one-out cross-validation (LOO-CV). The comparison between the estimated temperatures and the observations showed very high correlation considering the average by stations for maximum (Fig. 7a) and minimum temperatures (Fig. 7c) (Pearson correlation coefficients of 0.97 and 0.96 respectively) as well as the extremes, considering the 95th percentile of maximum temperature (Fig. 7b) with a Pearson correlation of 0.95 and the 5th percentile of minimum temperature (Fig. 7d) with 0.96.
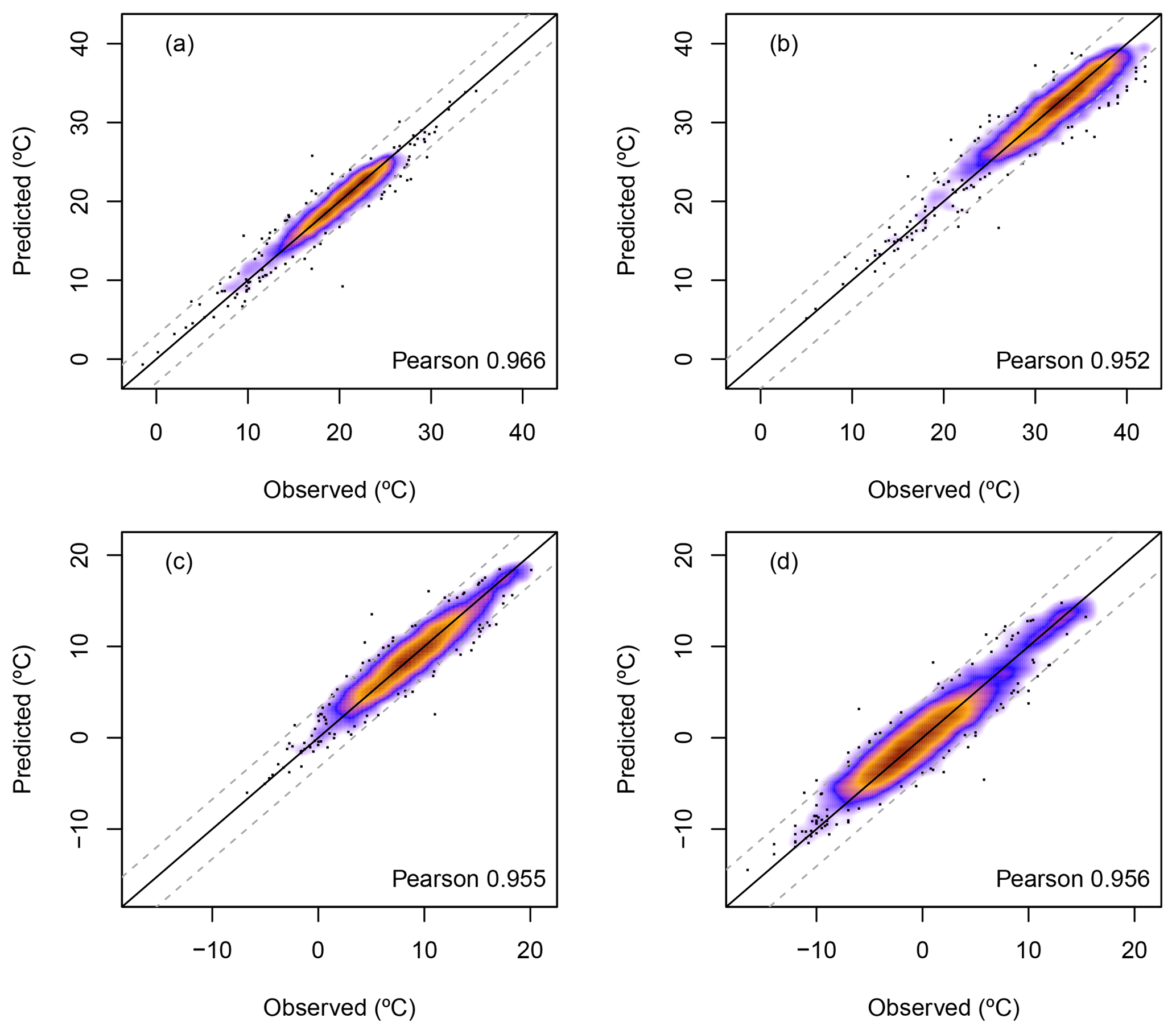
Figure 7Comparison between observations and estimates, by stations (n=5520), of the mean maximum temperatures (a) and their 95th percentiles (b), and comparison of the mean minimum temperatures (c) and their 5th percentiles (d). Dashed lines represent ±1 standard deviation of the data.
The mean Pearson correlations between the daily observations and the estimates, by month, were 0.87 and 0.82 in maximum and minimum temperature, respectively (Fig. 8). However, more than 80 % of the months in maximum temperature and more than 68 % in minimum temperature have a correlation higher than 0.8. Low correlations (Pearson <0.5) represented 3 % and 5 % of the months in maximum and minimum temperature, respectively.
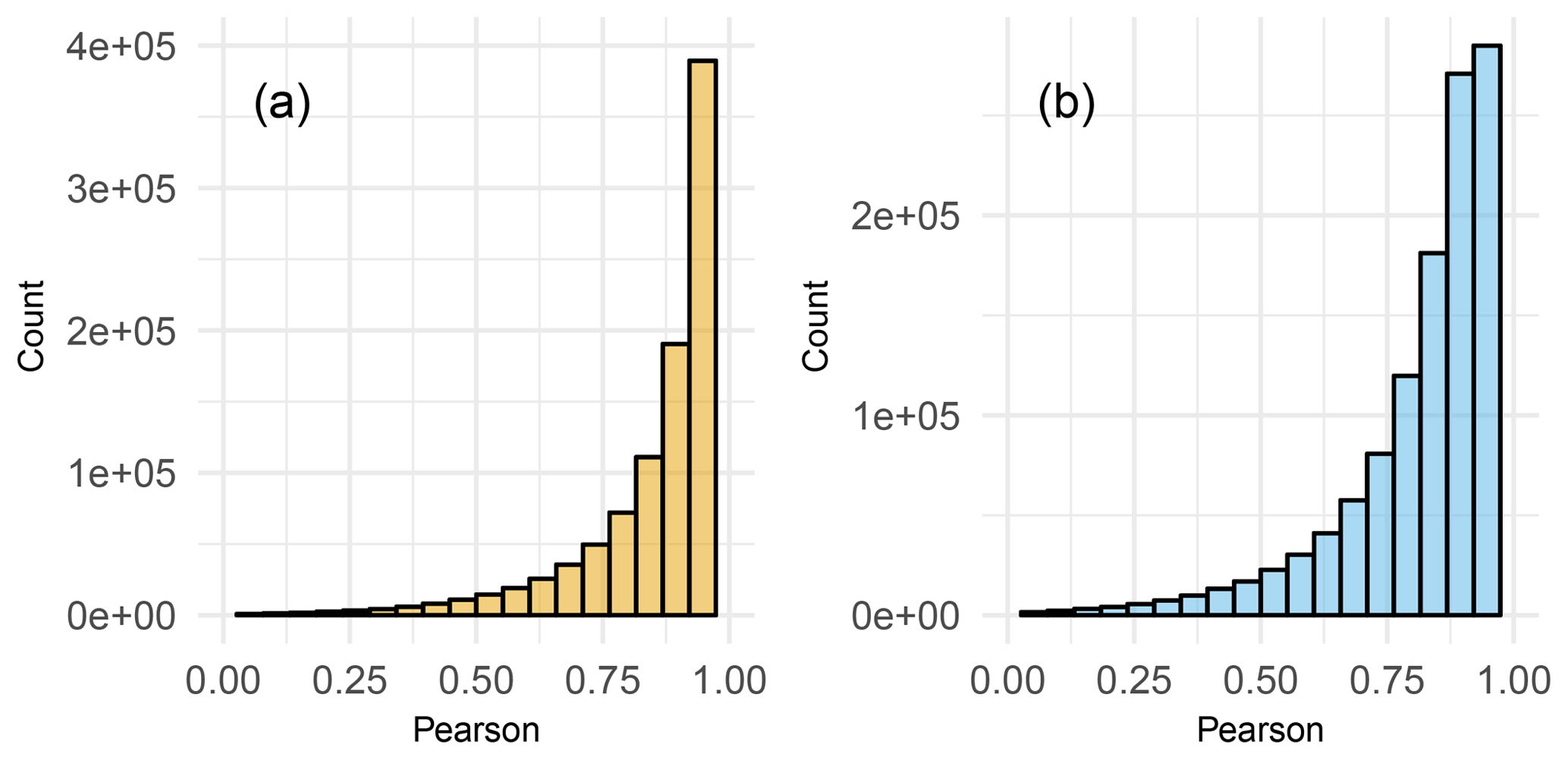
Figure 8Correlation frequencies between daily observations and estimates, by month, in the final dataset. Maximum (orange) and minimum (blue) temperatures are shown.
The frequency of observed temperature and their estimates (Fig. 9) showed a good general agreement. Although maximum temperature was slightly overestimated in lower values (from 0 to 10 ∘C), it was slightly underestimated in higher ones (from 20 to 35 ∘C). The greater differences in minimum temperature were found in low values (an overestimation from −5 to 0 ∘C) and in mid-values (an underestimation from 10 to 20 ∘C).
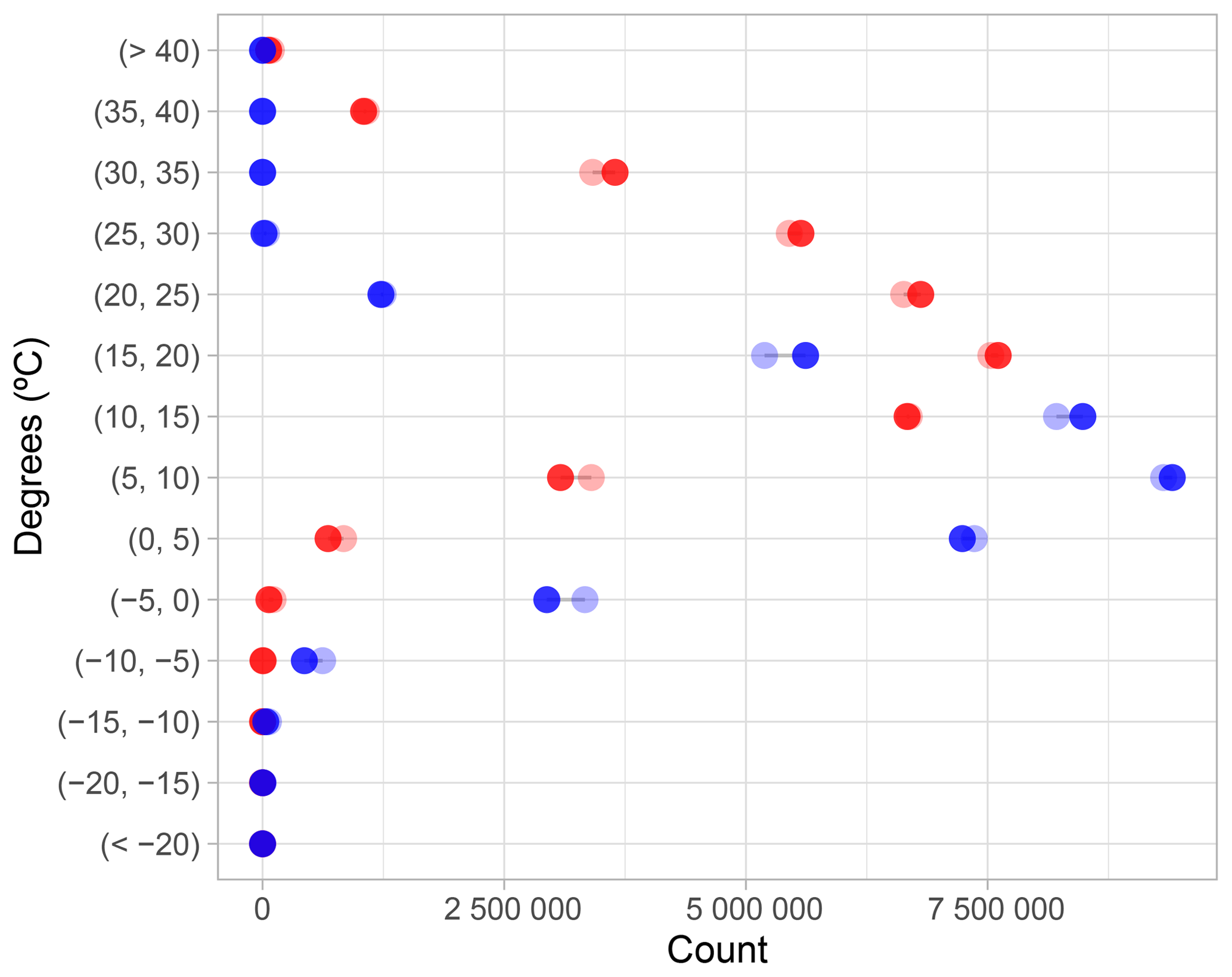
Figure 9Comparison of frequencies by categories between observed (solid) and predicted (transparent) maximum (red) and minimum (blue) temperatures.
Table 2The leave-one-out cross-validation (LOO-CV) statistics showing the goodness of fit between maximum and minimum temperature observations and estimates of monthly aggregates. MAE: mean absolute error (∘C); ME: mean error (∘C); RM: ratio of means; RSD: ratio of standard deviations; Pearson: Pearson correlation coefficient. Results were constrained to two decimal digits.
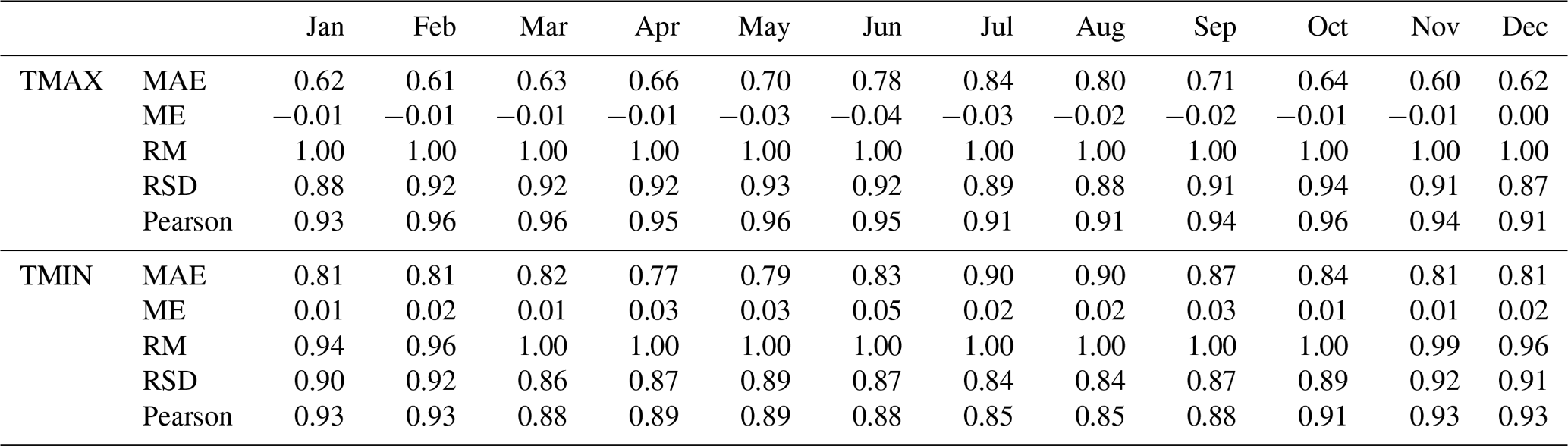
With regard to monthly aggregates (Table 2), the ratio of means (RM) was 1 in all cases in TMAX, showing a similarity in the means between observed and estimated temperature, while the coldest months (November to February) showed a slight underestimation in TMIN. A bias in variance estimation was observed with ratios of standard deviation (RSD) under 0.95 in all months in TMAX and under 0.93 in TMIN. However, ME values were very low in both cases and ME values were near zero in all cases. Pearson correlations between observations and estimates were over 0.90 in all months in TMAX and ranged from 0.85 in July and August to 0.93 from November to February in TMIN.
Table 3The leave-one-out cross-validation (LOO-CV) statistics showing the goodness of fit between observations and estimates of daily maximum and minimum temperature separated by altitudes (m a.s.l.). N: number of stations; OBSm: mean observed temperature (∘C); PREDm: mean predicted temperature (∘C); MAE: mean absolute error (∘C); ME: mean error (∘C); RM: ratio of means; RSD: ratio of standard deviations. Results were constrained to two decimal digits.
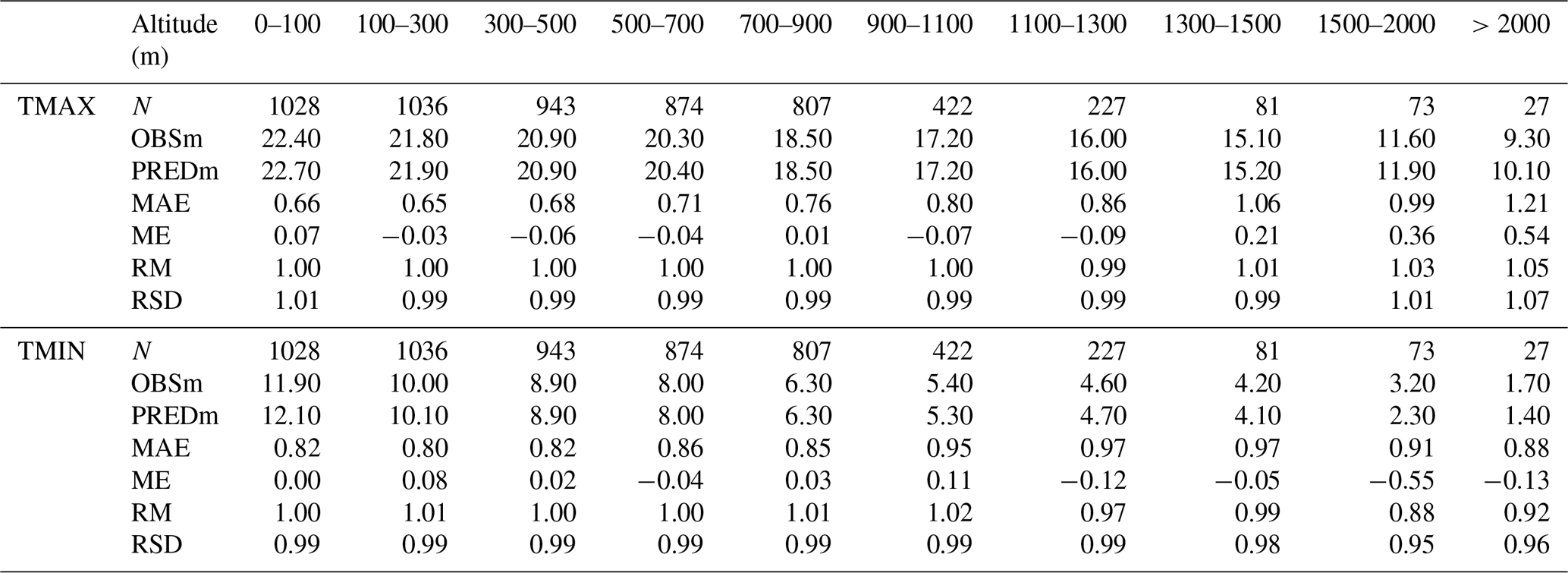
The number of stations decreases as the elevation increases (Table 3). In Spain, only 1.8 % of temperature stations are over 2000 m a.s.l. while 37.40 % are below 300 m a.s.l. This great difference, also shown in precipitation (Serrano-Notivoli et al., 2017a), necessarily affects the estimation of the variable. A slight underestimation was observed in TMIN from 1300 to 2000 m a.s.l., and an overestimation was observed in TMAX from 1500 m a.s.l. The figures showed also a good agreement at all elevation ranges, with the largest differences at high elevations (slight overestimation in TMAX and underestimation in TMIN). The MAE values were increased along with the elevation in TMAX from 0.65 to 1.21, while in TMIN they were more constant. The ME also experimented with an increase in the elevation in TMAX, but in TMIN all the values were near zero.
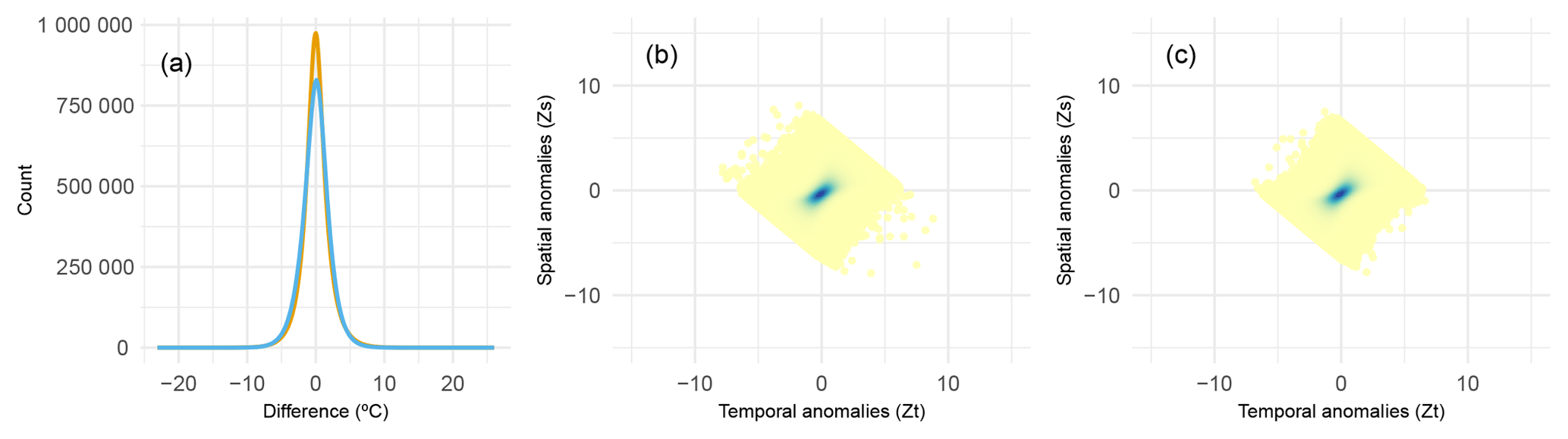
Figure 10Comparison of observations and estimates in the final dataset. (a) Maximum (orange line) and minimum (blue line) temperature differences between observations and estimates; (b, c) temporal anomalies (Zs) vs. spatial anomalies (Zs) of the final dataset.
Approximately, 70 % of the differences between observations and estimates both in TMAX and TMIN were lower than 1 ∘C (Fig. 10a), which assures the feasibility of the predicted series. Also, most of the spatial and temporal anomalies (approximately 80 %) were lower than 1 (Fig. 10b and c).
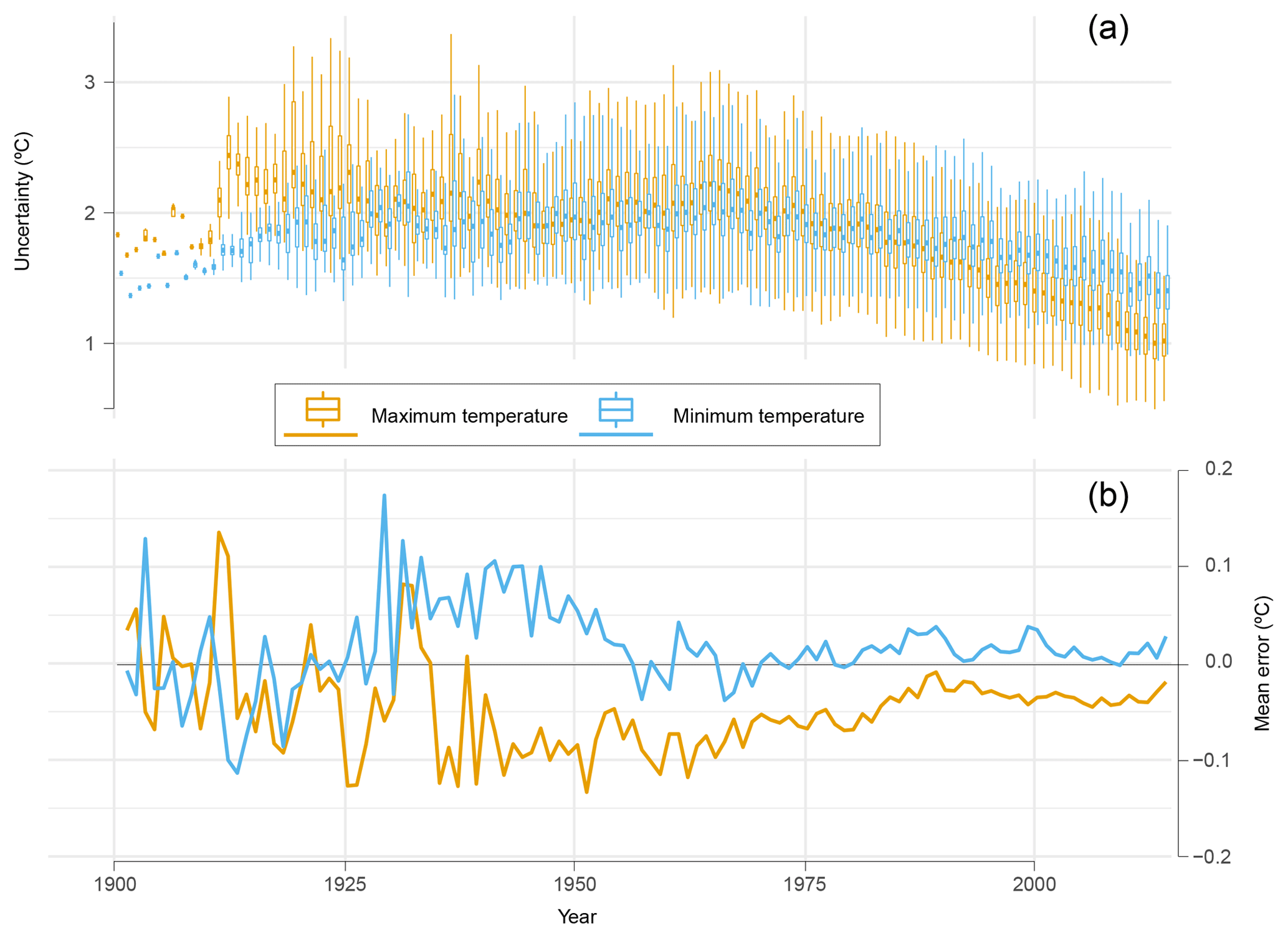
Figure 11Annual evolution of median daily uncertainty (a) and mean error (b) of maximum and minimum temperature in peninsular Spain.
The uncertainty of the estimates showed a decreasing temporal evolution (Fig. 11a) from the 1960s, while a positive trend was found in the first half of the period, especially in the first 15 years, coinciding with the moment of less observations and higher distance between them (see Fig. 2b, c). The values in maximum temperature were lower than the minimum temperature until the 1950s, and then they were similar during a couple of decades until they converged at the end of 1980s, when they diverged and the uncertainty in maximum temperature decreased at a higher rate than the minimum temperature. Likewise, the annual mean error (Fig. 11b) showed a great variability until the end of the 1940s, with similar values in TMAX and TMIN, when they separate, with TMAX being greater than TMIN in the rest of the series. Since the 1970s, an approach between the two series is shown, being nearer to zero TMAX than TMIN, which is always in negative values.
4.3 Spatial distribution and uncertainty of daily maximum and minimum temperature
The mean annual absolute daily maximum temperature (Fig. 12a) showed a great variability, with the highest values (>44 ∘C) in the central part of the Guadalquivir valley and widespread areas with values over 40 ∘C in the southern half of Iberian Peninsula (IP), the lowest areas of the Ebro Valley and inner areas of larger islands, reflecting a continentality effect. The lowest values were found at the highest elevations as the Pyrenees and the Iberian range and also at the northern IP. In this case, the uncertainty was inverse to the spatial distribution of the variable (Fig. 12b), with higher values in the north and at the highest elevations in the Canary Islands and lower values in areas where maximum temperature is higher. On the other hand, the mean annual absolute daily minimum temperature presented a completely different spatial distribution (Fig. 12c) especially in southern part of the IP, where there was a southwest–northeast gradient interrupted by high elevations of the Sierra Nevada and Cazorla. The northern half of the IP showed a similar pattern to the previous index, with coldest temperatures ( ∘C) coinciding with lower values of maximum temperature. The uncertainty of this variable (Fig. 12d) was lower than the previous one, with almost all the Spanish territory below 1 ∘C. The lowest values were found at the northwestern IP and the highest ones in coastal areas of Mallorca.
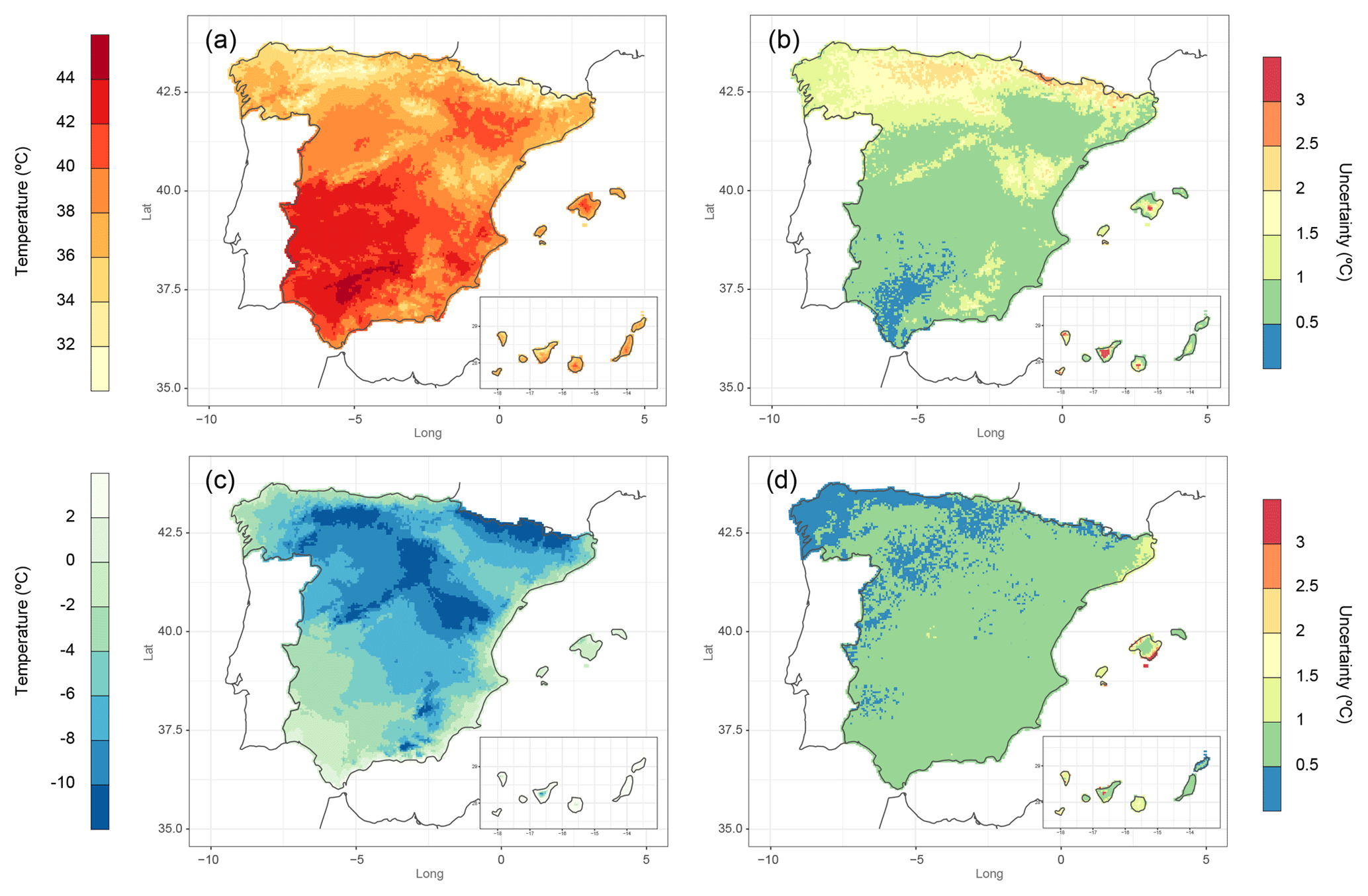
Figure 12Mean annual (1981–2010) values for (a) absolute daily maximum temperature, (c) absolute daily minimum temperature and their corresponding uncertainty (b, d, respectively).
4.4 Spatial distribution and uncertainty of frost days and tropical nights
The mean annual number of frost days (Fig. 13a) varied from less than 10 in coastal areas of the IP and in all the Balearic and Canary Islands to more than 200 at the highest elevations of the Pyrenees. Between these extremes, a similar increasing gradient such as the minimum temperature was found in the southern part of the IP and in the Ebro Valley, while the northern plateau was dominated by a range of 50–100 d. The spatial distribution of the uncertainty (Fig. 13b) coincided with the variable with the highest values where the number of frost days was higher. However, some exceptions were found: one at the northeastern IP, with a high uncertainty of the relatively low number of frost days; and another at the high elevations of the Pyrenees, where the uncertainty was low with regard to the high number of days. Low values of uncertainty in the Balearic and Canary Islands are due to the few frost days per year.
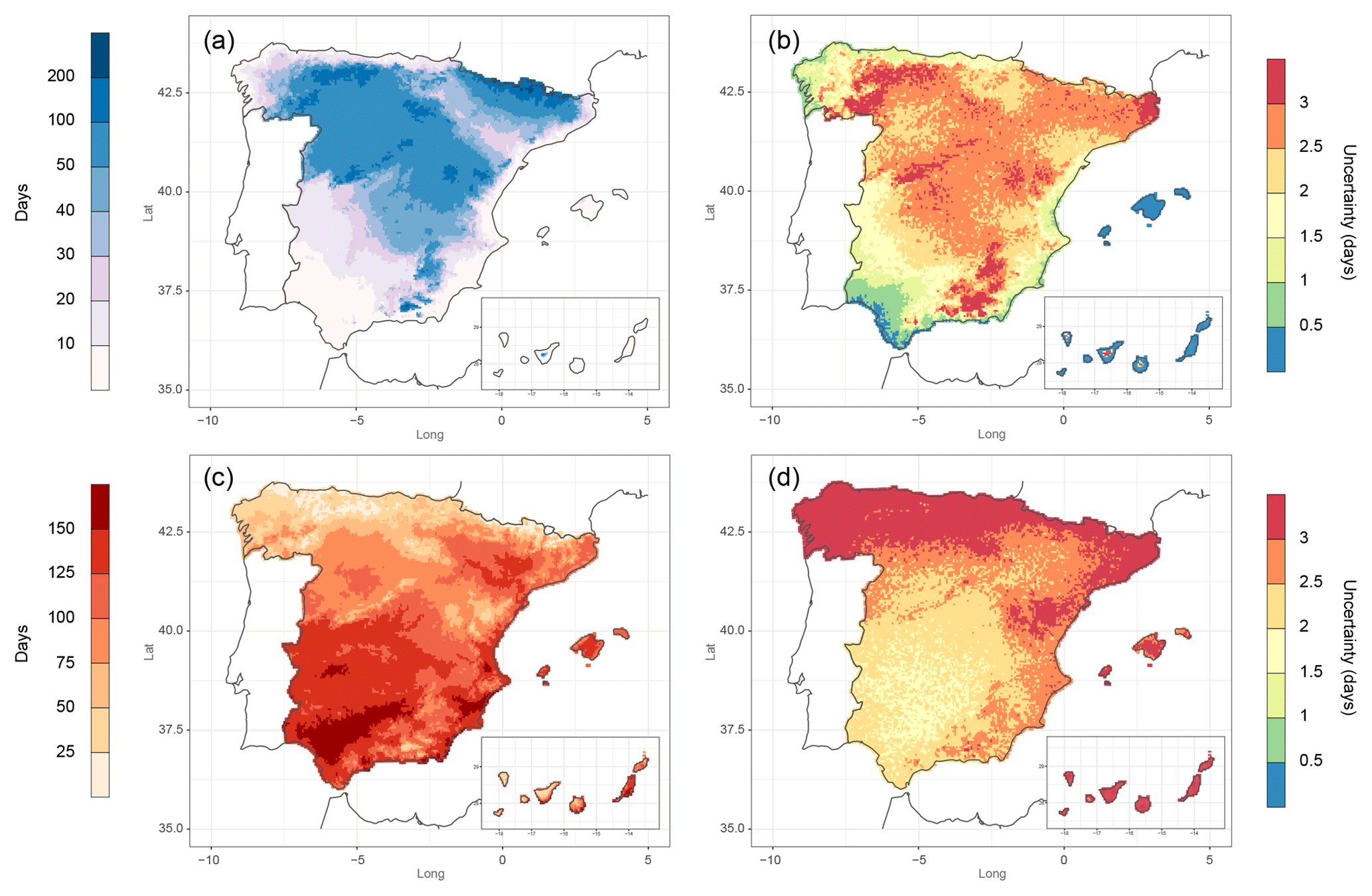
Figure 13Mean annual (1981–2010) values for (a) number of frost days, (c) number of summer days and their corresponding uncertainty (b, d, respectively).
The mean annual number of summer days (Fig. 13c) showed a similar spatial pattern to the maximum temperature but with a stronger effect of the orography. The highest values were found in the Guadalquivir valley with more than 150 d, as well as in southern part of the Mediterranean coast and eastern Canary Islands. The lowest number of summer days (<25) coincided with the highest elevations of the central and Iberian range, Pyrenees and Sierra Nevada. Also, the area all along the Cantabric coast showed values lower than 75 summer days. The uncertainty related to this index (Fig. 13d) was higher than the frost days, with a clear gradient from less than 2 d in the central southern IP to more than 3 d in the northern IP, the Iberian range, the Canary Islands and most of the inner areas of the Balearic Islands. Although the occurrence of summer days in both groups of islands is relatively high, they obtained considerable values of uncertainty due to the high variability of temperatures between stations in these small areas.
This work introduces two important novelties with regard to high-resolution climatic analysis: (i) a new methodology to reconstruct in situ temperature data series over time and space, and (ii) a new daily gridded temperature dataset for Spain.
The method, which is based on reference values (RVs) computed from nearest observations instead of the reference series (RS), follows the protocol developed for precipitation reconstruction in Serrano-Notivoli et al. (2017b). However, we included the distance to the coast as a source of variation of the local models in addition to the three used in the previous work (altitude, latitude and longitude). This parameter has been proven to be important for temperature estimation (Fick and Hijmans, 2017) and lets the models be more flexible.
One of the most valuable keys of the approach presented here is the use of all the available climatic information, which is crucial for a high-resolution output due to the observation network density having a major influence on gridded dataset results, controlling the skill of the final estimate of the variable (Hofstra et al., 2008). This is especially true in high percentiles, with a disproportionate effect in extreme values and, therefore, in extreme indices (Hofstra et al., 2010). Hence, a method using all the information instead of longest data series seems appropriate. Indeed, there are several temperature estimation methods in the literature, and the choice of one or another is not a trivial matter since the gridded dataset will be built from estimates. The inference or interpolation of any climatic variable in different locations from the recording sites always implies some kind of variation in final estimates regarding the observations. The aim is, therefore, to use an approach minimizing these errors. Previous comparisons of interpolation methods do not conclude on any definitive one. For instance, Shen et al. (2001) make a review of daily interpolation methods reporting that almost all of them smooth the data, and Jarvis and Stuart (2001) did not find large differences between them either. However, Hofstra et al. (2008) accept as more appropriate a global kriging for their work at the European scale and others such as Jeffrey et al. (2001) use simpler methods such as thin splines.
In this work, we use GLMMs and GLMs as a general approach to the daily temperature estimation, using as support monthly estimates based on daily data of months with complete observations. This part gives consistency to all of the temporal structure of the data series, as in similar approaches used in previous works (e.g. Jones et al., 2012). On the other hand, the use of regressions in temperature estimation is not new. For example, several works establish that regression models are more reliable than other interpolation methods for monthly temperatures (Kurtzman and Kadmon, 1999; Güler and Kara, 2014). Li et al. (2018) built a high-resolution grid for urban areas in the USA using geographically weighted regressions (GWR) and reported Pearson correlations between 0.95 and 0.97, similarly to the present work. However, Hofstra et al. (2008) found that, for the European scale, daily temperature regressions worked worse than other interpolation methods.
The present work constitutes a novelty regarding previous methodological approaches mainly due to the fact that (i) all the available information is used, with the longer series supported by shorter ones; and (ii) it includes a comprehensive iterative quality control checking the spatial and temporal consistency of the data until no suspect values are detected. In addition to the developed validation process, the results in the form of spatial coherence show that the method is able to reproduce realistic climatic situations. The new approach to the quality control detects a number of suspect data in line with previous research, assuring the deletion of anomalies in a spatial and a temporal dimension. Although many works dedicate little effort to this part of the reconstruction, it is one of the most important ones since it will have a decisive weight in the final result. For instance, Jeffrey et al. (2001) simply remove those data exceeding a fixed threshold with regard to the residuals of the splines; and in ECA&D (Klok and Klein-Tank, 2009) the quality tests are absolute, without a comparison with neighbouring data series. Nevertheless, a similar approach to our spatial check of quality was developed in Estévez et al. (2018) but comparing nearest stations in all their data series instead of daily individual data. They used the spatial regression test (SRT) following You et al. (2008) and Hubbard and You (2005). Others such as Durre et al. (2010) also applied spatial consistency checks to test if temperature data lie significantly outside their neighbours. They flagged as suspect 0.24 % of all the (worldwide) data considering temperature, precipitation, snowfall and snow depth, a quite low figure.
One of the key elements in any gridded dataset creation is to provide an uncertainty value, which informs about the reliability of the data and should be a standard to all the climatic information. The uncertainty values presented in this work come from each of the individual models for each time step and location; therefore it apprises the changes in the reliability of the day-to-day data. Now, several datasets provide this kind of information, though it can be obtained from different methods. For example, Cornes et al. (2018) applied a smart calculation of the uncertainty using 100-member ensemble realizations for each day; Stoklosa et al. (2015) and Di Luzio et al. (2008) used PRISM (Parameter–Elevation Regressions on Independent Slopes Model) to compute uncertainty in two ways: (i) a leave-one-out cross-validation (LOO-CV) as we do in the present work, and (ii) modelling the uncertainty – which could lead to a propagation of the errors – using the prediction intervals of their weighted linear regression. In all cases the method is valid because the goal is to extract the potential bias for each considered time step.
Concerning to the new dataset, although some previous works created daily temperature datasets for Spain, only a few are gridded (only Herrera et al., 2016, built one for the whole peninsular Spain and the Balearic Islands), and none of them are dedicated to analysing the spatial distribution of daily temperature indices but rather the trends (e.g. El-Kenawy et al., 2011; Fonseca et al., 2016). We show here only four examples of the capabilities of the STEAD dataset in the research of temperatures in Spain. The northern half of the IP showed a stronger influence of orography and Atlantic influences, just like in annual precipitation and maximum precipitation in 1 and 5 d (SPREAD, Serrano-Notivoli et al., 2017a), showing a potential covariability with other precipitation indices or temporal scales (Sánchez-Rodrigo, 2018, 2014; Fernández-Montes et al., 2016). Besides, the availability of maximum and minimum temperature (STEAD) and precipitation (SPREAD) at same temporal (daily) and spatial (5 km × 5 km) scale opens up possibilities of new prospective research in many fields such as agricultural climatology, natural hazards, paleoclimatic reconstructions or hydrological modelling, amongst others.
In our attempt to create a useful reconstruction and gridding methodology, some of the stages of the method imply arbitrary decisions that could be changed based on user-defined options. For instance, we use 15 neighbouring observations to build the model but there is not an objective number. We are building these models with four cofactors, which need certain degrees of freedom. An increase in the neighbours could lead to a loss of local representativeness but also a gain of statistical robustness and lower influence of anomalous data.
With respect to the quality control process, the initial thresholds were set at the beginning only to remove outliers that are sometimes included in the original datasets (e.g. −999 or unreal such as 54 354, which is one of the removed values in this work) but that sometimes have a meaning to identify specific situations or local codes. There are a lot of sources and types of errors such as repeated series, duplicities or coding errors that we try to identify through a simple collection of criteria. For example, we use the correlation between series and the differences between observations and estimates to remove data based on probability thresholds that we defined based on our experience, but maybe others could be useful depending on the dataset.
The effort of this research has been mainly dedicated to create an accurate estimate of temperature using all the available information and providing a validation as complete and transparent as possible, as well as afford an uncertainty measure tailored for each value allowing the assessment of data in each day and location.
The STEAD dataset is freely available in the web repository of the Spanish National Research Council (CSIC). It can be accessed through https://doi.org/10.20350/digitalCSIC/8622 and cited as Serrano-Notivoli et al. (2019). The data are arranged in 12 files (daily maximum and minimum temperature estimations and their uncertainties for peninsular Spain and the Balearic Islands and Canary Islands) in NetCDF format that allow for easy processing in scientific analysis software (e.g. R, Python, …) and GIS (list of compatible software at https://www.unidata.ucar.edu/software/, last access: 25 July 2019).
We present a new high-resolution daily maximum and minimum temperature dataset for Spain (STEAD). Using all the available daily temperature data (5520 stations, representing about 1 station per 90 km2 considering the whole period), a 5 km × 5 km spatial resolution grid was created. The original data were quality-controlled and the missing values were filled based on the monthly estimates and using the 15 nearest observations. A serially complete dataset was obtained for all stations from 1901 to 2014 for peninsular Spain and from 1971 to 2014 for the Balearic and Canary Islands. Based on this dataset, daily temperatures were calculated for each grid node, resulting in a high-resolution gridded dataset that we used to compute four daily temperature indices: mean annual absolute maximum and minimum temperatures, mean annual number of frost days and mean annual number of summer days.
The spatial distribution of mean annual maximum and minimum temperatures showed a strong relationship with the altitude (decreasing along with the elevation) and with the distance to the coast, revealing a high effect of continentality with increased values of the indices in both inner mainland Spain and its islands. The mean annual number of frost days was higher in the northern half of peninsular Spain and in high-elevation areas of the south, while the mean number of summer days obtained the highest values at the south, in the Guadalquivir valley and the southern Mediterranean coast, progressively decreasing to the north.
The use of all the available information in combination with a methodology based on local variations of temperature over a high-resolution grid provided a daily dataset that is able to reproduce the high spatial and temporal variability.
The supplement related to this article is available online at: https://doi.org/10.5194/essd-11-1171-2019-supplement.
MdL designed the methodological approach in collaboration with RSN, who applied it to the reconstruction of the climate data and the development of the gridded dataset. SB contributed to the validation process and the climatic analysis of the results. RSN prepared the manuscript with contributions from all co-authors.
The authors declare that they have no conflict of interest.
The authors thank the Spanish Meteorological Agency (AEMET) for the data.
This research has been supported by the Ministerio de Economía y Competitividad (grant nos. CGL2015-69985-R and CGL2017-83866-C3-3-R) and the Ministerio de Ciencia e Innovación (grant no. FJCI-2017-31595).
This paper was edited by Scott Stevens and reviewed by three anonymous referees.
Bates, D., Mächler, M., Bolker, B. M., and Walker, S. C.: Fitting Linear Mixed-Effects Models Using lme4, J. Stat. Softw., 67, 1–48, https://doi.org/10.18637/jss.v067.i01, 2015.
Brunet, M., Saladie, O., Jones, P., Sigro, J., Aguilar, E., Moberg, A., Lister, D., Walther, A., Lopez, D., and Almarza, C.: The development of a new dataset of Spanish daily adjusted temperature series (SDATS) (1850–2003), Int. J. Climatol., 26, 1777–1802, https://doi.org/10.1002/joc.1338, 2006.
Cornes, R. C., van der Schrier, G., van den Besselaar, E. J., and Jones, P. D.: An ensemble version of the E-OBS temperature and precipitation data sets, J. Geophys. Res.-Atmos., 123, 9391–9409, https://doi.org/10.1029/2017JD028200, 2018.
Di Luzio, M., Johnson, G. L., Daly, C., Eischeid, J. K., and Arnold, J. G.: Constructing Retrospective Gridded Daily Precipitation and Temperature Datasets for the Conterminous United States, J. Appl. Meteorol. Clim., 47, 475–497, https://doi.org/10.1175/2007JAMC1356.1, 2008.
Durre, I., Menne, M. J., Gleason, B. E., Housgon, T. G., and Vose, R. S.: Comprehensive Automated Quality Assurance of Daily Surface Observations, J. Appl. Meteorol. Clim., 49, 1615–1633, https://doi.org/10.1175/2010JAMC2375.1, 2010.
El Kenawy, A., López-Moreno, J. I., and Vicente-Serrano, S. M.: Recent trends in daily temperature extremes over northeastern Spain (1960–2006), Nat. Hazards Earth Syst. Sci., 11, 2583–2603, https://doi.org/10.5194/nhess-11-2583-2011, 2011.
Estévez, J., Gavilán, P., and García-Marín, A. P.: Spatial regression test for ensuring temperature data quality in southern Spain, Theor. Appl. Climatol., 131, 309–318, https://doi.org/10.1007/s00704-016-1982-8, 2018.
Feng, S., Hu, Q., and Qian, W.: Quality control of daily meteorological data in China, 1951–2000: A new dataset (2004), Int. J. Climatol., 24, 853–870, https://doi.org/10.1002/joc.1047, 2004.
Fernández-Montes, S., Gómez-Navarro, J. J., Sánchez-Rodrigo, F., García-Valero, J. A., and Montávez, J. P.: Covariability of seasonal temperature and precipitation over the IberianPeninsula in high-resolution regional climate simulations (1001–2099), Global Planet. Change, 151, 122–133, https://doi.org/10.1016/j.gloplacha.2016.09.007, 2016.
Fick, S. and Hijmans, R. J.: WorldClim 2: New 1-km spatial resolution climate surfaces for global land areas, Int. J. Climatol., 37, 4302–4315, https://doi.org/10.1002/joc.5086, 2017.
Fonseca, D., Carvalho, M. J., Marta-Almeida, M., Melo-Gonçalves, P., and Rocha, A.: Recent trends of extreme temperature indices for the Iberian Peninsula, Phys. Chem. Earth, 94, 66–76, https://doi.org/10.1016/j.pce.2015.12.005, 2016.
González-Hidalgo, J. C., Peña-Angulo, D., Brunetti, M., and Cortesi, N.: MOTEDAS: a new monthly temperature database for mainland Spain and the trend in temperature (1951–2010), Int. J. Climatol., 35, 4444–4463, https://doi.org/10.1002/joc.4298, 2015.
González-Hidalgo, J. C., Salinas, C., Peña-Angulo, D., and Brunetti, M.: A moving windows visual approach to analysing spatial variation in temperature trends on the Spanish mainland 1951–2010, Int. J. Climatol., 38, 1678–1691, https://doi.org/10.1002/joc.5288, 2018.
Güler, M. and Kara, T.: Comparison of Different Interpolation Techniques for Modelling Temperatures in Middle Black Sea Region, Journal of Agricultural Faculty of Gaziosmanpasa University, 31, 61–71, https://doi.org/10.13002/jafag714, 2014.
Hansen, J., Ruedy, R., Sato, M., and Lo, K.: Global surface temperature change, Rev. Geophys., 48, RG4004, https://doi.org/10.1029/2010RG000345, 2010.
Haylock, M. R., Hofstra, N., Klein Tank, A. M. G., Klok, E. J., Jones, P. D., and New, M.: A European daily high-resolution gridded data set of surface temperature and precipitation for 1950–2006, J. Geophys. Res.-Atmos., 113, D20119, https://doi.org/10.1029/2008JD010201, 2008.
Herrera, S., Fernández, J., and Gutierrez, J. M.: Update of the Spain02 gridded observational dataset for EURO-CORDEX evaluation: assessing the effect of the interpolation methodology, Int. J. Climatol., 36, 900–908, https://doi.org/10.1002/joc.4391, 2016.
Hofstra, N., Haylock, M., New, M., Jones, P., and Frei, C.: Comparison of six methods for the interpolation of daily, European climate data, J. Geophys. Res., 113, D21110, https://doi.org/10.1029/2008JD010100, 2008.
Hofstra, N., New, M., and McSweenwy, C.: The influence of interpolation and station network density on the distributions and trends of climate variables in gridded daily data, Clim. Dynam., 35, 841–858, https://doi.org/10.1007/s00382-009-0698-1, 2010.
Hubbard, K. G. and You, J.: Sensitivity Analysis of Quality Assurance Using the Spatial Regression Approach – A Case Study of the Maximum/Minimum Air Temperature, J. Atmos. Ocean. Tech., 22, 1520–1530, https://doi.org/10.1175/JTECH1790.1, 2005.
Jarvis, C. H. and Stuart, N.: A Comparison among Strategies for Interpolating Maximum and Minimum Daily Air Temperatures. Part II: The Interaction between Number of Guiding Variables and the Type of Interpolation Method, J. Appl. Meteorol., 40, 1075–1084, https://doi.org/10.1175/1520-0450(2001)040<1075:ACASFI>2.0.CO;2, 2001.
Jeffrey, S. J., Carter, J. O., Moodie, K. B., and Beswick, A. R.: Using spatial interpolation to construct a comprehensive archive of Australian climate data, Environ. Modell. Softw., 16, 309–330, https://doi.org/10.1016/S1364-8152(01)00008-1, 2001.
Jones, P. D., Lister D. H., Osborn T. J., Harpham C., Salmon M., and Morice C. P.: Hemispheric and large-scale land surface air temperature variations: An extensive revision and an update to 2010, J. Geophys. Res., 117, D05127, https://doi.org/10.1029/2011JD017139, 2012.
Klein-Tank, A. M. G., Wijngaard, J. B., Können, G. P., Böhm, R., Demarée, G., Gocheva, A., Mileta, M., Pashiardis, S., Hejkrlik, L., Kern-Hansen, C., Heino, R., Bessemoulin, P., Müller-Westermeier, G., Tzanakou, M., Szalai, S., Pálsdóttir, T., Fitzgerald, D., Rubin, S., Capaldo, M., Maugeri, M., Leitass, A., Bukantis, A., Aberfeld, R., van Engelen, A. F. V., Forland, E., Mietus, M., Coelho, F., Mares, C., Razuvaev, V., Nieplova, E., Cegnar, T., López, J. A., Dahlström, B., Moberg, A., Kirchhofer, W., Ceylan, A., Pachaliuk, O., Alexander, L. V., and Petrovic, P.: Daily dataset of 20th-century surface air temperature and precipitation series for the European Climate Assessment, Int. J. Climatol., 22, 1441–1453, https://doi.org/10.1002/joc.773, 2002.
Klok, E. and Klein-Tank, A.: Updated and extended European dataset of daily climate observations, Int. J. Climatol., 29, 1182–1191, https://doi.org/10.1002/joc.1779, 2009.
Kurtzman, D. and Kadmon, R.: Mapping of temperature variables in Israel: A comparison of different interpolation methods, Clim. Res., 13, 33–43, 1999.
Li, X., Zhou, Y., Asrar, G. R., and Zhu, Z.: Developing a 1 km resolution daily air temperature dataset for urban and surrounding areas in the conterminous United States, Remote Sens. Environ., 215, 74–84, https://doi.org/10.1016/j.rse.2018.05.034, 2018.
Lussana, C., Tveito, O. E., and Uboldi, F.: Three-dimensional spatial interpolation of 2 m temperature over Norway, Q. J. Roy. Meteor. Soc., 144, 344–364, https://doi.org/10.1002/qj.3208, 2018.
Peña-Angulo, D., Brunetti, M., Cortesi, N., and González-Hidalgo, J. C.: A new climatology of maximum and minimum temperature (1951–2010) in the Spanish mainland: a comparison between three different interpolation methods, Int. J. Geogr. Inf. Syst., 30, 1–24, https://doi.org/10.1080/13658816.2016.1155712, 2016.
Rohde, R., Muller, R. A., Jacobsen, R., Perlmutter, S., Rosenfeld, A., Wurtele, J., Curry, J., Wickham, C., and Mosher, S.: Berkeley Earth Temperature Averaging Process, Geoinfor Geostat: An Overview, 1, 1–13, https://doi.org/10.4172/2327-4581.1000103, 2013.
Sánchez-Rodrigo, F.: On the covariability of seasonal temperature and precipitation in Spain, 1956–2005, Int. J. Climatol., 35, 3362–3370, https://doi.org/10.1002/joc.4214, 2014.
Sánchez-Rodrigo, F.: Coherent variability between seasonal temperatures and rainfalls in the Iberian Peninsula, 1951–2016, Theor. Appl. Climatol., 135, 473–490, https://doi.org/10.1007/s00704-018-2400-1, 2018.
Serrano-Notivoli, R., Beguería, S., Saz, M. Á., Longares, L. A., and de Luis, M.: SPREAD: a high-resolution daily gridded precipitation dataset for Spain – an extreme events frequency and intensity overview, Earth Syst. Sci. Data, 9, 721–738, https://doi.org/10.5194/essd-9-721-2017, 2017a.
Serrano-Notivoli, R., De Luis, M., Saz, M. A. and Begueriìa, S.: Spatially-based reconstruction of daily precipitation instrumental data series, Clim. Res., 73, 167–186, https://doi.org/10.3354/cr01476, 2017b.
Serrano-Notivoli, R., De Luis, M., and Beguería., S.: STEAD (Spanish TEmperature At Daily scale) [Dataset], https://doi.org/10.20350/digitalCSIC/8622, 2019.
Shen, S., Dzikowski, P., Guilong, L., and Griffith, D.: Interpolation of 1961–97 Daily Temperature and Precipitation Data onto Alberta Polygons of Ecodistrict and Soil Landscapes of Canada, J. Appl. Meteorol., 40, 2162–2177, https://doi.org/10.1175/1520-0450(2001)040<2162:IODTAP>2.0.CO;2, 2001.
Stoklosa, J., Daly, C., Foster, S. D., Ashcroft, M. B., and Warton, D. I.: A climate of uncertainty: accounting for error in climate variables for species distribution models, Methods Ecol. Evol., 6, 412–423, https://doi.org/10.1111/2041-210X.12217, 2015.
Van Den Besselaar, E. J. M., Klein Tank, A. M. G., Van Der Schrier, G., Abass, M. S., Baddour, O., Van Engelen, A. F. V., Freire, A., Hechler, P., Laksono, B. I., Iqbal, Jilderda, R., Kamga Foamouhoue, A., Kattenberg, A., Leander, R., Martínez Güingla, R., Mhanda, A. S., Nieto, J. J., Sunaryo, Suwondo, A., Swarinoto, Y. S., and Verver, G.: International climate assessment & dataset: Climate services across borders, B. Am. Meterol. Soc., 96, 16–21, https://doi.org/10.1175/BAMS-D-13-00249.1, 2015.
Villeta, M., Valencia, J. L., Sa'a, A., and Tarquis, A. M.: Evaluation of extreme temperature events in northern Spain based on process control charts, Theor. Appl. Climatol., 131, 1323–1335, https://doi.org/10.1007/s00704-017-2038-4, 2018.
Willmott, C. J. and Matsuura, K.: Terrestrial Air Temperature and Precipitation: Monthly and Annual Time Series (1950–1999), available at: http://climate.geog.udel.edu/~climate/html_pages/README.ghcn_ts2.html (last access: 25 July 2019), 2001.
You, J., Hubbard, K. G., and Goddard S.: Comparison of methods for spatially estimating station temperatures in a quality control system, Int. J. Climatol., 28, 777–787, https://doi.org/10.1002/joc.1571, 2008.