the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 19 Mar 2025
| 19 Mar 2025
Global projections of heat stress at high temporal resolution using machine learning
Pantelis Georgiades
Theo Economou
Yiannis Proestos
Jose Araya
Jos Lelieveld
Marco Neira
Climate change poses a significant threat to agriculture, with potential impacts on food security, economic stability, and human livelihoods. Dairy cattle, a crucial component of the livestock sector, are particularly vulnerable to heat stress, which can adversely affect milk production, immune function, and feed intake and, in extreme cases, lead to mortality. The Temperature Humidity Index (THI) is a widely used metric to quantify the combined effects of temperature and humidity on cattle. However, the THI was previously estimated using daily-level data, which do not capture the daily thermal load and cumulative heat stress, especially during nights when cooling is inadequate. To address this limitation, we developed a machine learning approach to temporally downscale daily climate data to hourly THI values. Utilizing historical ERA5 reanalysis data, we trained an XGBoost model and generated hourly THI datasets for 12 NEX-GDDP-CMIP6 climate models under two emission scenarios (SSP2-4.5 and SSP5-8.5) extending to the end of the century. These high-resolution THI data provide an accurate quantification of heat stress in dairy cattle, enabling improved predictions and management strategies to mitigate the impacts of climate change on this vital agricultural sector. The dataset created in this study is publicly available at https://doi.org/10.26050/WDCC/THI (Georgiades, 2024b).
- Article
(9739 KB) - Full-text XML
- BibTeX
- EndNote




Climate change, driven by anthropogenic greenhouse gas emissions, is a multifaceted challenge with profound implications for ecosystems and human societies alike (IPCC, 2023; Malhi et al., 2020). The agricultural sector, which has been the cornerstone of global food security and economic activities for the past centuries, is particularly vulnerable to climate change and variability (Abbass et al., 2022). Within this sector, livestock farming emerges as a critical area of concern due to its susceptibility to environmental stressors, making the assessment and management of climate impacts critical for sustaining agricultural productivity and livelihoods (Cheng et al., 2022; Escarcha et al., 2018).
Dairy farming, an integral component of the livestock industry, is particularly sensitive to climatic conditions. Economic losses due to heat stress in the United States alone are estimated at USD 1.5–1.7 billion per year, accounting for approximately 63.9 % of the national yearly losses of this economic sector (North et al., 2023; St-Pierre et al., 2003; Cartwright et al., 2023). Predictive models for the US forecast monetary losses as high as USD 2.2 billion by the end of the century (Mauger et al., 2014).
The effects of heat stress on cattle are determined by complex interactions between environmental factors (particularly temperature and humidity) and biological parameters. Modern-day breeds of dairy cattle are the result of intensive genetic selection, aimed primarily at increasing milk productivity. However, this increased productivity is genetically linked to physiological traits such as greater metabolic rates and increased feed intake, both of which augment endogenous heat generation in the animals, thereby making high-productivity breeds particularly susceptible to heat stress (Kadzere et al., 2002; Moore et al., 2023a).
Dairy cows depend on evaporative heat loss as their main thermoregulatory mechanism (Zhou et al., 2023). Therefore, when exposed to increased temperatures, they rely heavily on their ability to dissipate heat by either sweating or panting in order to regulate their body temperature. Water evaporation rates are negatively correlated with the relative humidity of the surrounding environment, so a cow's ability to regulate its body temperature is progressively diminished with increasing moisture in the air (Bohmanova et al., 2007). As a consequence, even moderate increases in temperature can have severe biological repercussions under high-humidity conditions. Heat stress has been linked to multiple deleterious effects in dairy cattle, including reductions in milk yield and quality; decreased reproductive success; decreased feed intake; body-weight loss; reduced immune function; altered behaviour; and, in extreme cases, mortality (Burhans et al., 2022; Cartwright et al., 2023; Kadzere et al., 2002; Polsky and von Keyserlingk, 2017).
The Temperature Humidity Index (THI) is a robust, non-invasive metric developed to quantify the levels of thermal stress caused by the combined effects of temperature and humidity on cattle. Its calculation requires meteorological data that are generally easy to access (i.e. air temperature and relative humidity), and their correlation with physiological parameters has been validated by a large body of literature (Bohmanova et al., 2007; Ravagnolo et al., 2000; Bouraoui et al., 2002; Brügemann et al., 2012; Igono et al., 1992; Bernabucci et al., 2014). For example, THI values above 68 have been associated with reductions in milk yield in dairy cows (Moore et al., 2023b; Collier et al., 2012; Zimbelman et al., 2009), and a recent systematic review of the scientific literature published during the last 2 decades about the effects of THI on dairy cattle found that values above 68.8 were associated with increased mortality and reduced fertility, in addition to reductions in milk production (North et al., 2023). The THI can also be used for the definition and classification of heatwaves in relation to their effect on cattle (Hahn et al., 1999, 2009), and it constitutes the basic metric for the Livestock Weather Safety Index, an early-warning system which provides specific THI thresholds for normal (THI ≤ 74), alert (THI 75–78), danger (THI 79–83), and emergency (THI ≥ 84) climatic conditions (Hahn et al., 2009).
In most of the available scientific literature, THI values are estimated using daily-level data (e.g. daily averages or daily extremes in temperature and humidity). The reason for this is twofold: on the one hand, working at finer temporal resolutions (e.g. hourly) generally requires the processing and storage of very large datasets, which can pose logistic and computational difficulties. On the other hand, data provided by climate projections of future scenarios are only available at daily or coarser temporal resolutions. Unfortunately, daily-level calculations can neither accurately estimate the daily thermal load caused by fluctuating climatic conditions across each day (e.g. diurnal vs nocturnal temperatures) nor capture cumulative effects over consecutive days, particularly during periods such as heatwaves, when night-time conditions might not allow for efficient heat dissipation (St-Pierre et al., 2003; Hahn, 1997; Hahn et al., 2009). This underscores the need for increasing the temporal resolution of climate projections in order to reflect the environmental stressors impacting dairy cattle, thereby allowing for improved forecasts of the potential impacts of climate change on this key economic sector.
Recent decades have seen significant advances in computational capabilities, allowing machine learning algorithms to improve the spatial and temporal resolution of climate data (Huntingford et al., 2019). These innovations enable the downscaling of global climate model outputs to produce high-resolution projections that better address the needs of agricultural planning and management. However, despite progress in spatial downscaling through traditional statistical methods (Nyeko-Ogiramoi et al., 2012; Tang et al., 2016) and artificial intelligence techniques (Rampal et al., 2022; Pour et al., 2016; Ashiotis et al., 2023), studies focused on temporal downscaling remain scarce. Most recent research has primarily concentrated on downscaling precipitation data with restricted spatial coverage, predominantly employing traditional statistical approaches rather than machine learning methodologies (Requena et al., 2021; Michel et al., 2021). A notable exception is the work by Wang et al. (2024), who demonstrated the capability of deep learning models to temporally downscale temperature data, albeit at a regional level.
Traditionally, two methodologies have been employed for temporal downscaling of climatic data: dynamical and statistical. Dynamical downscaling involves physical models but is often prohibitively expensive in terms of computational resources for long-term, global applications that require relatively high spatial resolution. In contrast, statistical methods are data-driven and focus on extrapolation using auxiliary parameters. Machine learning, as an advanced form of statistical downscaling, leverages large datasets to capture complex patterns and dependencies. Our analysis aims to provide improved estimates of both the duration and intensity of heat stress periods for cattle on an hourly basis, integrating data on expected diel fluctuations in Temperature Humidity Index (THI) values, using a highly scalable machine learning approach that accommodates multi-year, multi-model, and multi-scenario analyses. This need stems from the fact that previous work relied on daily-level data, which only allow for approximate estimations of these fluctuations through simplified mathematical models. For instance, St-Pierre et al. (2003) modelled the intensity of heat stress in the United States by assuming a perfect counter-cyclical relationship between temperature and humidity, with THI variations following an ideal sine wave pattern. While such idealized models can be useful in the absence of high-resolution temporal data, they often overlook the inherent complexities of climatic cycles, such as the influence of geographic diversity and seasonal variations.
Our study aims to bridge the gap between coarse-resolution climate projections and the fine-scale environmental data required for effective farm management under changing climatic conditions.
We utilized a well-established machine learning algorithm, specifically the “Extreme Gradient Boosting” (XGBoost) model, to temporally downscale daily climate projections to hourly THI values. We opted for the XGBoost model for its computational efficiency compared to random forest and other analogous algorithms, specifically for our application. Additionally, the implementation of random forest in Python does not support incremental learning, which was crucial for this study due to the vast number of data the model needed to process during training. Furthermore, the model was trained on CPU rather than GPU due to memory limitations of our available GPUs and the extensive nature of our dataset.
Our approach involves the training of the model using the ERA5 reanalysis dataset, which contains historical hourly data (Hersbach et al., 2020). The model was subsequently applied to generate hourly THI projections until the end of the century, based on bias-adjusted climate projections from the NASA NEX-GDDP-CMIP6 datasets (Thrasher et al., 2022). We developed data using 12 climate models and concentrated on two distinct Shared Socioeconomic Pathways (SSPs), SSP2-4.5 and SSP5-8.5, which represent moderate and high greenhouse gas emissions scenarios, respectively, aiming to capture a broad range of potential climatic outcomes.
2.1 Data
Two distinct sources for climate data were used in this study: ERA5 reanalysis and NEX-GDDP-CMIP6. Details on each one are provided below.
2.1.1 ERA5 reanalysis
The ERA5 reanalysis data, produced by the European Centre for Medium-Range Weather Forecasts (ECMWF) as part of the Copernicus Climate Change Service, combine historical observations and global estimates using forecasting models (Hersbach et al., 2020). This dataset is provided at a spatial resolution of 0.25° and hourly temporal resolution (atmosphere component). For the purposes of this study, we retrieved the variables t2m (temperature at 2 m) and d2m (dew point temperature at 2 m), for a time period spanning 1980 to 2020, from the “ERA5 hourly data on single levels from 1940 to present” entry available in the Copernicus Data Store (CDS), using the Python API.
We estimated the relative humidity variable using the Magnus formula (WMO, 2021), as follows:
where T and Td are the ambient and dew point temperature in degrees Celsius, respectively. e(Td) is the vapour pressure at temperature Td and es(T) the saturation vapour pressure at temperature T. Finally, the relative humidity can be calculated by taking the ratio of the two, as follows:
The ground truth THI values were derived from the ERA5 reanalysis dataset, as detailed in Sect. 2.2. This dataset represents the current state of the art for global atmospheric condition proxies, integrating sophisticated numerical model simulations with assimilated observational data. Its performance has been validated in the scientific literature (Bell et al., 2021; Tarek et al., 2020). Furthermore, Napoli (2020) demonstrated its capacity for estimating thermal stress and discomfort indices. Moreover, ERA5 offers a continuous global time series, which was crucial to our study.
2.1.2 NEX-GDDP-CMIP6
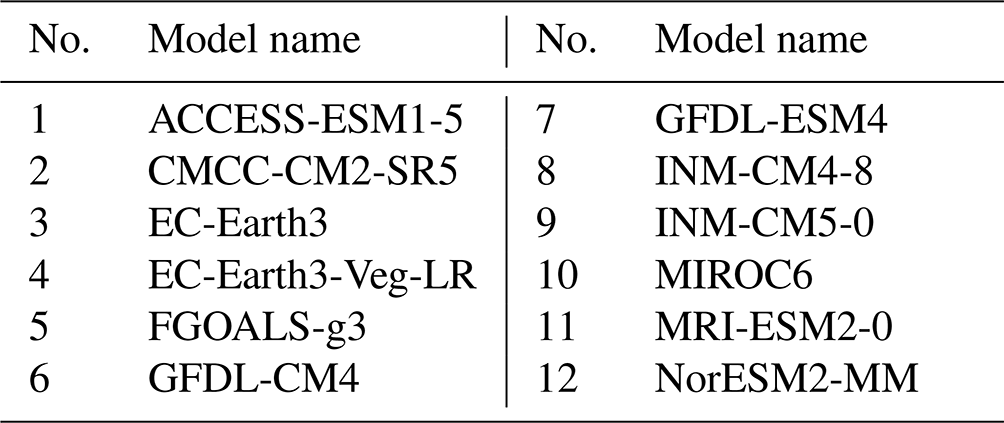
The NEX-GDDP-CMIP6 ensemble dataset comprises global downscaled climate change scenarios. These were derived from the general circulation model (GCM) runs conducted under the Coupled Model Intercomparison Project Phase 6 (CMIP6) (Thrasher et al., 2022). It includes global downscaled and bias-adjusted projections from ScenarioMIP model runs and features a 0.25° spatial resolution and daily temporal resolution. The data for 12 climate models and two greenhouse gas emissions scenarios (SSP2-4.5 and SSP5-8.5) were retrieved in netCDF format from the NCCS THREDDS data service. From these datasets, we utilized the daily average, minimum, and maximum temperatures, as well as the mean relative humidity variables. Table 1 presents the full list of NEX-GDDP-CMIP6 models used in this study to generate hourly THI projections until the end of the century.
Table 1List of NEX-GDDP-CMIP6 models used in this study to generate hourly THI predictions.
2.2 Feature selection
The Temperature Humidity Index is not a directly measured physical quantity but rather a calculated metric derived from temperature and relative humidity (Cheng et al., 2022). In this study, we used the ERA5 reanalysis dataset to compute THI values, which was the target variable for our machine learning models. THI values were calculated using a computational approach that preserved the spatial and temporal resolution of the original ERA5 data, 0.25° and hourly, respectively.
The computation of hourly THI values from the ERA5 dataset was performed using the following formula:
where T denotes the temperature in degrees Celsius (°C), and RH represents the relative humidity in percent (%) (Yeck, 1971). This approach ensures that our derived THI values are systematically calculated across the entire spatial and temporal domain of the ERA5 dataset, providing a consistent and comprehensive representation of thermal comfort conditions.
To ensure compatibility with the variables available in the NEX-GDDP-CMIP6 datasets, we generated features from the hourly ERA5 dataset as follows:
-
daily minimum, maximum, and average temperature;
-
daily average THI, calculated using the daily average temperature and average relative humidity;
-
daily average relative humidity.
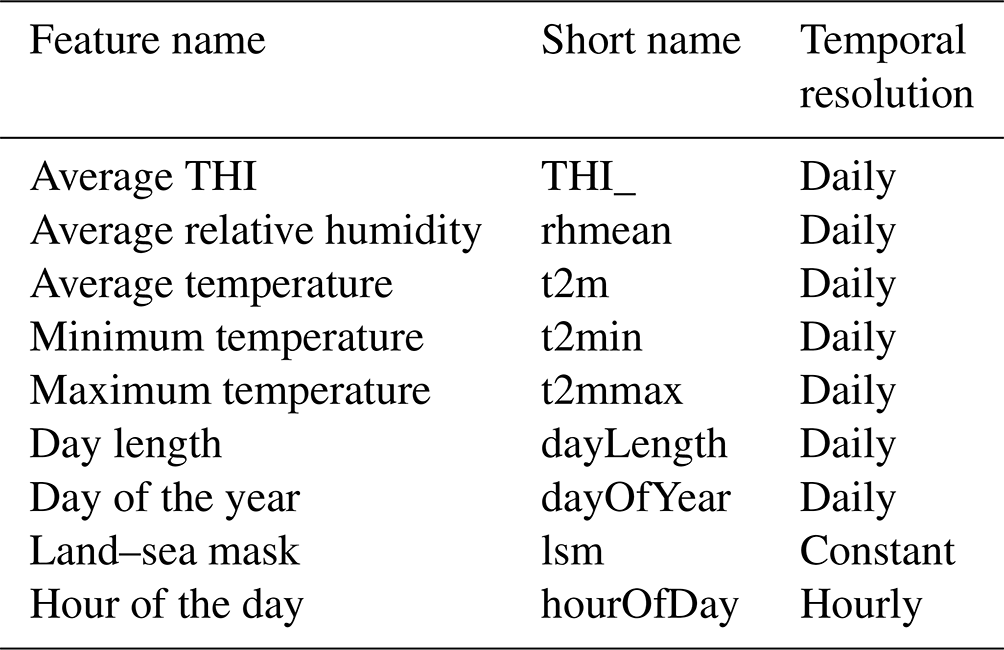
Lastly, we included the “hour of the day” and “day of the year” features to account for diurnal and seasonal variations of THI and the land–sea mask – ranging from 0 (sea) to 1 (land) – to differentiate between terrestrial and maritime environments.
2.3 Data workflow
This section outlines the utilization of ERA5 reanalysis data and CMIP6 projections in constructing the input variables for this study. Figure 1 provides a high-level overview of the data pipeline procedures employed to train and implement a machine learning model that temporally downscales daily data to hourly THI values.
To allow for a one-to-one relationship between the hourly ERA5 and daily CMIP6 data, daily features were constructed from ERA5, which are also available in the projection datasets, namely daily average relative humidity and temperature and daily maximum and minimum temperature. For each day the daily averaged relative humidity and temperature were used to calculate the daily averaged THI. These features were used with no modification from the CMIP6 dataset.
Subsequently, to build the training set, we calculated two additional features, based on the location of each grid cell (long, lat) and the date; namely the length of the day (number of hours for each grid cell that experienced sunshine for each day) and the day of the year (1–366 to account for leap years). The day length was calculated using the Brock model (Brock, 1981). In this model, the day length is defined at the point where the centre of the sun is even with the horizon. The declination of the Earth is calculated by (Forsythe et al., 1995)
where J is the day of the year. The sunrise–sunset hour angle is calculated as
where L is the latitude. Finally, day length (D) is calculated by
The hourly THI value, calculated from hourly relative humidity and temperature, was used as the target variable for the model during training (depicted in red in Fig. 1).
To establish a one-to-one relationship between the hourly ERA5 data and the daily CMIP6 data, daily features were constructed from the ERA5 dataset that are also available in the projection datasets. These features include daily average relative humidity, daily average temperature, and daily maximum and minimum temperatures. For each day, the daily averaged relative humidity and temperature were used to calculate the average THI. These features were used without modification from the CMIP6 dataset, as they are available on a daily temporal resolution already. To construct the training set, we calculated the two additional features, day length and day of the year.
Furthermore, these daily values were combined with a land–sea mask for each grid cell to account for the distinction between coastal and land-locked grid cells. An additional feature, the hour of the day (ranging from 0 to 23), was also included to create the hourly training set. The resulting hourly dataset was utilized to train the model for predicting hourly THI, with the hourly THI serving as the target variable for this analysis.
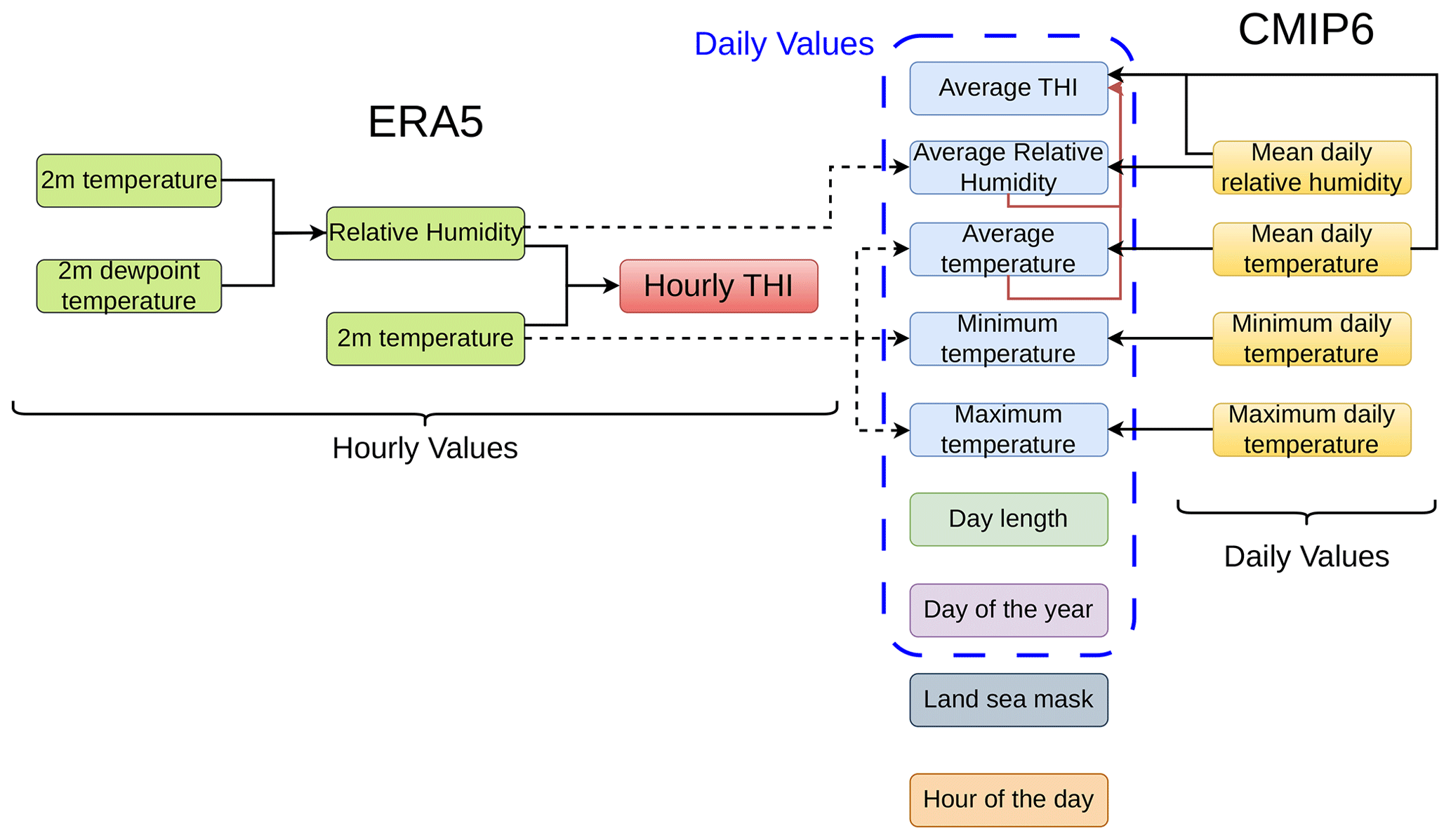
Figure 1High-level overview of the data workflow employed in this study to temporally downscale daily data to hourly THI values. On the left, the data originating from the ERA5 data are presented, whereas on the right, the CMIP6 data are presented. The column in the middle represents the feature set employed in the study to train and perform inference procedures.
Similarly, for inference, the daily CMIP6 data were combined with features representing day length, day of the year, land–sea mask, and hour of the day to construct the hourly datasets utilized in the inference procedures. Table 2 shows the features used for each time step and their respective temporal resolution.
Table 2Feature set and temporal resolution of each feature. This represents the input variables used in each time step (hourly) of the model to temporally downscale daily data to hourly THI values.
2.4 Model training
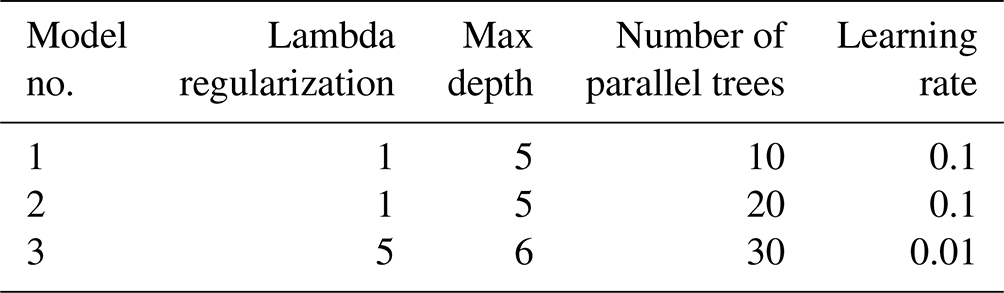
An XGBoost regressor model was employed to perform the temporal downscaling from daily to hourly resolution. Three models of increasing complexity were trained to explore the trade-off between model performance and computational efficiency. The parameters of each of these models are presented in Table 3.
Table 3The parameters of the three XGBoost models trained to temporally downscale daily climate data to hourly THI values.
The selection of the predictive model was partially influenced by the necessity for an approach capable of incremental learning. This requirement was dictated by the sheer volume of the training data, which precluded the possibility of training on the entire dataset simultaneously, due to technical limitations. The xgboost library, implemented in Python, was chosen for its ability to accommodate this need as well as the well-established accuracy and speed compared to other ensemble learning models (Chen and Guestrin, 2016; Sheik et al., 2024). The framework facilitated the training of the model in monthly increments, commencing from the year 1980 and concluding in 2017. To ensure the continuity and assess the model's performance over time, checkpoints were stored at the end of each training increment (monthly). The first month of 2018 was used as a test set throughout the training procedures. Finally, the models were trained on a single compute node, which was equipped with two AMD EPYC/Milan 64-core CPUs and 256 GB of RAM. During both the training and inference phases, each model was configured to utilize 128 parallel processes, optimizing computational efficiency. In total, the models were trained on approximately 130 billion examples; areas comprised entirely of sea or ocean were omitted.
2.5 Model evaluation
The performance of the trained models was assessed using ground truth data derived from the ERA5 dataset for the period spanning February 2018 until December 2020, which was not seen by the model during training. This evaluation phase aimed to establish the models' predictive accuracy and their ability to generalize to unseen data. Model performance was quantitatively evaluated using standard statistical metrics, including the mean error (ME), mean squared error (MSE), mean absolute error (MAE), and coefficient of determination (R2).
2.5.1 Implementation details
The data manipulation and the feature engineering were performed using Python 3.11, utilizing the xarray, numpy, and pandas libraries. The input variables were scaled to the 0–1 range using the MinMaxScaler method from the scikit-learn library, and the xgboost library was used to implement training and inference procedures for temporally downscaling daily climatic variables to hourly THI values.
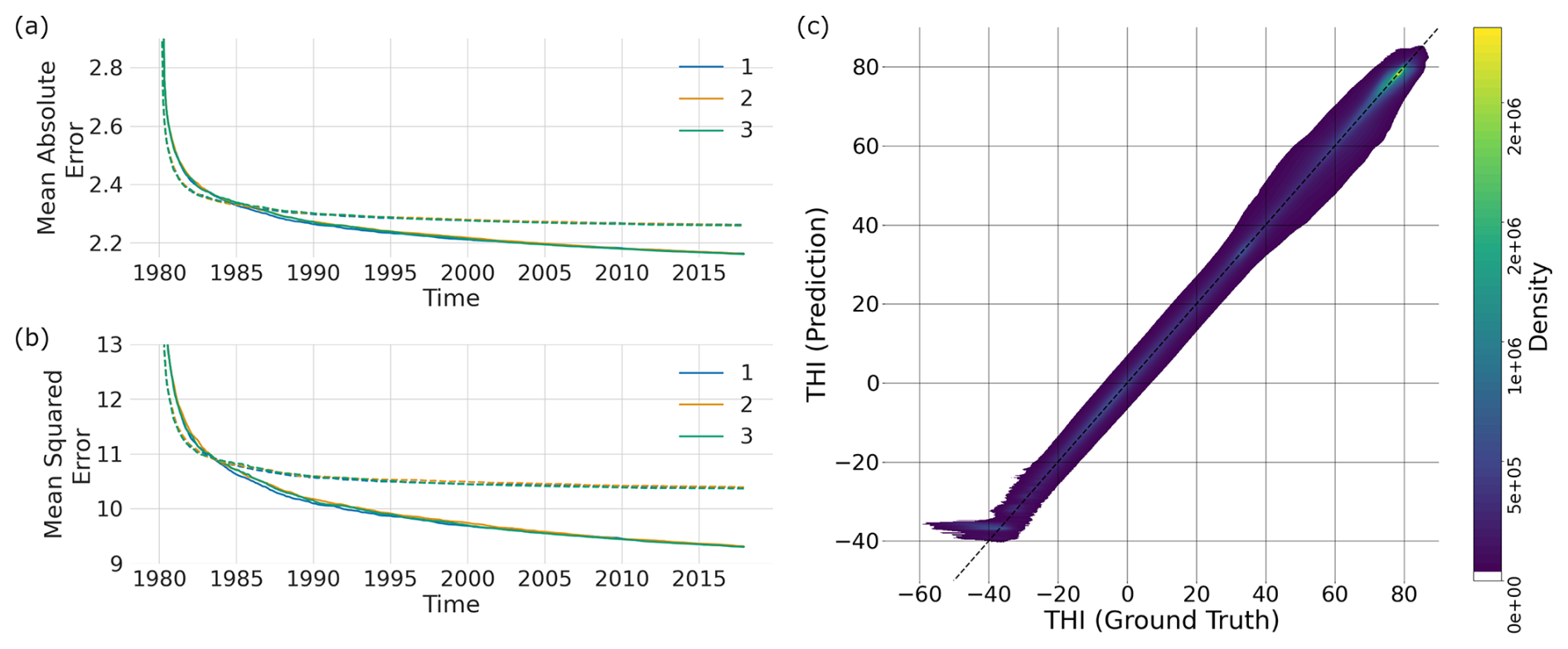
Figure 2Evolution of MAE and MSE throughout the training process for three distinct XGBoost models, each represented by a different colour. On the left, the MAE (a) and MSE (b) metrics over training epochs, conducted on a monthly basis from January 1980 to December 2017, are shown. Solid lines depict the metrics evaluated on the training set in each epoch, while dashed lines represent the MAE and MSE evaluated on the test set at each epoch. Panel (c) displays a density plot of the predictions from Model 1 versus the ground truth for the validation dataset (2018–2020), where the diagonal line indicates the optimal prediction performance.
Table 4MAE, MSE and R2 performance metrics evaluated on the last epoch during the training process, the test set for the three models (data from January 2018), and the validation set (February 2018–December 2020). Furthermore, the total training time and the time needed by the models to perform inference on a single year are presented. The best metric in each category is denoted in bold.

For the XGBoost regression model, we used the xgb.Booster() method, with each training epoch – corresponding to a month in the ERA5 dataset – for 10 boosting rounds. The XGBoost model's hyperparameters were primarily kept at their default values due to the computational constraints of training on such an extensive dataset. Specifically, we used gamma=0 (minimum loss reduction required to make a further partition on a leaf node), and both subsample and colsample_bytree were set to 1.0, meaning all data points and features were used for building each tree. The L2 regularization parameter (lambda) was set to 1.0, while L1 regularization (alpha) was kept at 0. For tree construction, we employed the “hist” tree method with a “depthwise” growth policy and 256 bins for feature discretization. The model used a single tree per iteration (num_parallel_tree=1), with the squared error as the objective function. The model was trained incrementally using 1 month of data at a time from the ERA5 dataset, spanning the time period from January 1980 to December 2017. Data from January 2018 served as the test set to evaluate performance during training in each epoch. These parameter choices balanced model complexity with computational efficiency, as the incremental training approach already imposed significant computational demands.
An early stopping mechanism was applied during each training epoch to prevent over-fitting; the training process terminated if the error on the test set did not improve for three consecutive boosting rounds. To reduce storage requirements, data for each epoch were constructed in memory at runtime, bypassing the need for permanent storage of monthly datasets.
This design resulted in progressively longer training times as epochs progressed since each new boosting round effectively added additional estimators to the model, increasing both the training complexity and the inference computational cost. This incremental training approach was essential to handle the large volume of data and to allow periodic checkpoint saves.
2.5.2 Applicability to high-spatial-resolution data
To evaluate the applicability of the trained model to higher spatial resolutions, we used data from ERA5-Land (Muñoz-Sabater et al., 2021), a dataset that provides global coverage at approximately 9 km spatial resolution and hourly temporal resolution. Our model had no exposure to ERA5-Land data during training. To assess performance in data with a different spatial resolution compared to the training data, we utilized global data from 2018 to generate hourly THI predictions using our model trained on coarser ERA5 data. These predictions were then validated against reference ground truth THI values computed directly from ERA5-Land data, following the procedures described above.
3.1 Model training and evaluation
Consistent with the methodologies put forth in the Methods section, this study included the training of three XGBoost regression models, each varying in complexity, to establish the optimal parameterization for the prediction of hourly Temperature Humidity Index (THI) values from daily climatic input. Figure 2 illustrates the progression of two key performance indicators, MAE and MSE, throughout the training phases. These metrics were computed at the end of each training epoch, corresponding to monthly intervals spanning January 1980 to December 2017. The evaluation was carried out using a test dataset, which included global data from January 2018, to validate the predictive accuracy and generalization capability.
Furthermore, the right panel of Fig. 2 presents a ground truth versus prediction plot for Model 1's inference on the validation set (February 2018–December 2020). We employed a density plot instead of a scatter plot to facilitate visualization of the clustering behaviour within the large dataset (approximately 10 billion data points). As evident, the model demonstrates good performance, with the majority of points concentrated near the diagonal, representing optimal prediction. However, a potential limitation is observed at the lower end of the Thermal Humidity Index (THI) range. Here, the model appears to exhibit a prediction floor around THI. It is important to note that these low THI values are of minimal interest for heat stress studies, as they primarily correspond to regions such as Antarctica, which are normally devoid of human and livestock populations.
Following the approach outlined in the Methods section, the training process for the models was executed incrementally, with the dataset being segmented into monthly intervals. This approach facilitated the storage of checkpoints at the conclusion of each epoch, allowing for a systematic evaluation and resumption of the training process without loss of progress.
The performance metrics of the three models were found to be closely comparable across the evaluation criteria. Both the MAE and MSE demonstrated a continuous decrease throughout the training epochs, albeit at a diminished rate of reduction as the training progressed. It is noteworthy that these metrics were also assessed using a test set that was not seen by the model during the training phase, ensuring the evaluation of the model's predictive capability on unseen data. As the complexity of the models increased, notably, Model 3 required a substantially longer duration for training compared to its counterparts. Furthermore, an observable convergence between the curves representing MSE and MAE was observed, in both the training and test sets, indicating a stabilization in the models' performance over time. Table 4 shows the performance metrics of the three models across the training and test sets, as well as the total training time and time needed to perform inference on a single year and scenario. Lastly, the metrics obtained from the validation set were closely comparable across all three models, with MAE reaching ∼ 3.4, MSE ∼ 19, and R2 ∼ 0.94.
To further assess the comparative performance of the three trained models, we performed inference using data from 2018 to 2020 (ERA5 reanalysis) to evaluate the precision of the THI predictions relative to the ground truth. Figure 3 displays THI predictions at six randomly selected grid points and time intervals, representing diverse climatic conditions: permanent frost regions from Antarctica (top row), moderate climate (middle row), and two hot climate regions (bottom row). In the two examples from Antarctica, the model was found to have a lower limit in its prediction window close to −40 THI units. Across the rest of the examples, the outputs from all three models closely followed the real THI fluctuations during the 10 d periods shown. In the examples of THI originating from colder regions of the world (middle row of panels), the THI prediction captures the average trend well, but the finer scale fluctuations are less well represented. Additionally, the predictions generated by the three models were nearly identical, as shown in Fig. 3.
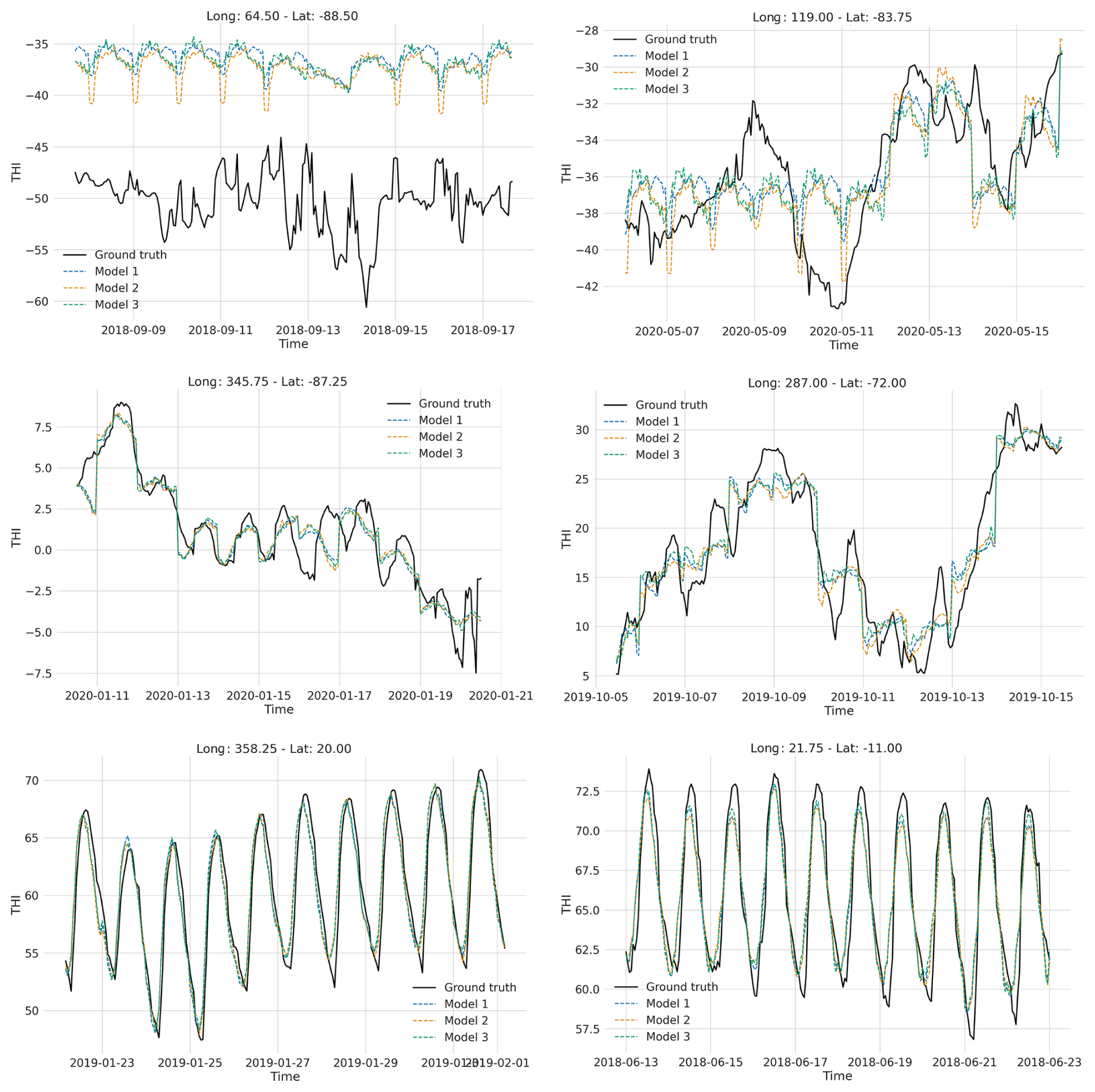
Figure 3Comparative visualization of hourly THI calculations using ERA5 reanalysis data (ground truth) and the outputs from the three XGBoost models, each differentiated by unique colours. The six-panel display (3×2 arrangement) showcases THI profiles across varying climatic conditions: the top row of panels presents examples from the South Pole, where a prediction minimum of THI units was found in days with 0 h of sunshine; the middle row illustrates moderate climate conditions; and the bottom row of panels depicts examples from warm climate regions. This arrangement provides a comprehensive overview of the models' performance and accuracy in replicating ground truth THI values across a spectrum of environmental conditions. This comparison explains the density q–q plot further.
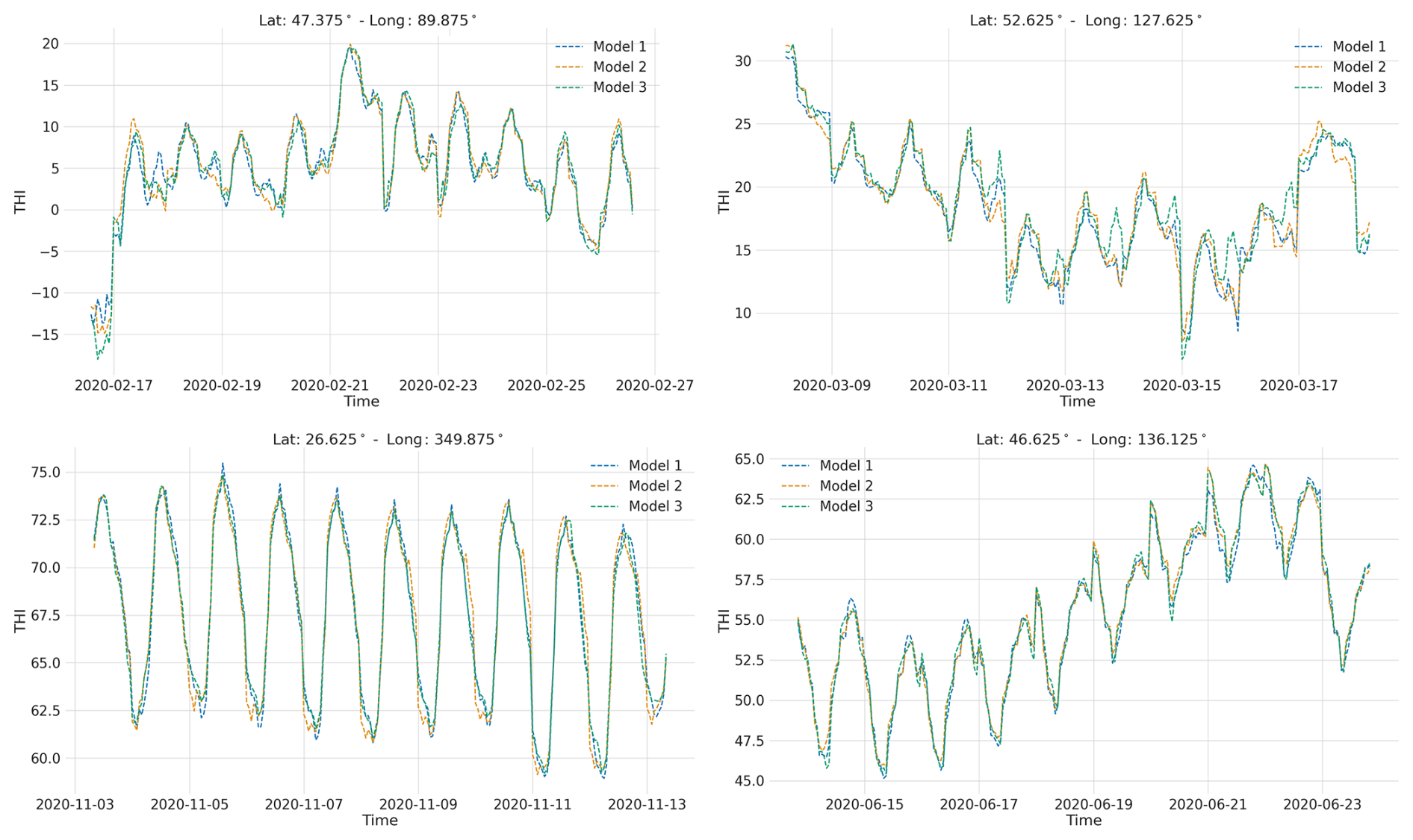
Figure 4Comparative visualization of the THI profiles from the three models' predictions from the ACCESS-ESM1-5 model (SSP2-45 scenario) for the year 2020. The four panels show four randomly selected grid points, and the prediction from each model is colour-coded.
The outputs from the three models on ERA5 data align well with the ground truth THI, especially in mild and hot environments. To evaluate the similarity of their performance on CMIP6 future projection data, we conducted inference using a single year of data from the ACCESS-ESM1-5 model (year 2020 under scenario SSP2-4.5) for all three models. Figure 4 presents the THI outputs at four randomly selected geographical locations and time points over a 10 d period. The outputs from all models closely match each other, corroborating their consistency. Combined with the previously obtained performance metrics, this indicates that the three models exhibit similar performance on both ERA5 and CMIP6 data. Consequently, we opted for the simplest model (Model 1) due to its significant computational cost savings compared to the other models. The marginal improvements in performance metrics did not justify the additional tens of thousands of CPU hours required for the more complex models, given the close similarity in their outputs.
To assess model performance, we employed global maps at randomly chosen time points from the validation set. These maps show the Temperature Humidity Index (THI) using both ground truth data and the chosen model's predictions, along with their difference. Representative examples are shown in Fig. 5. Deviations from the ground truth are evident in various regions across the globe at these hourly time points.
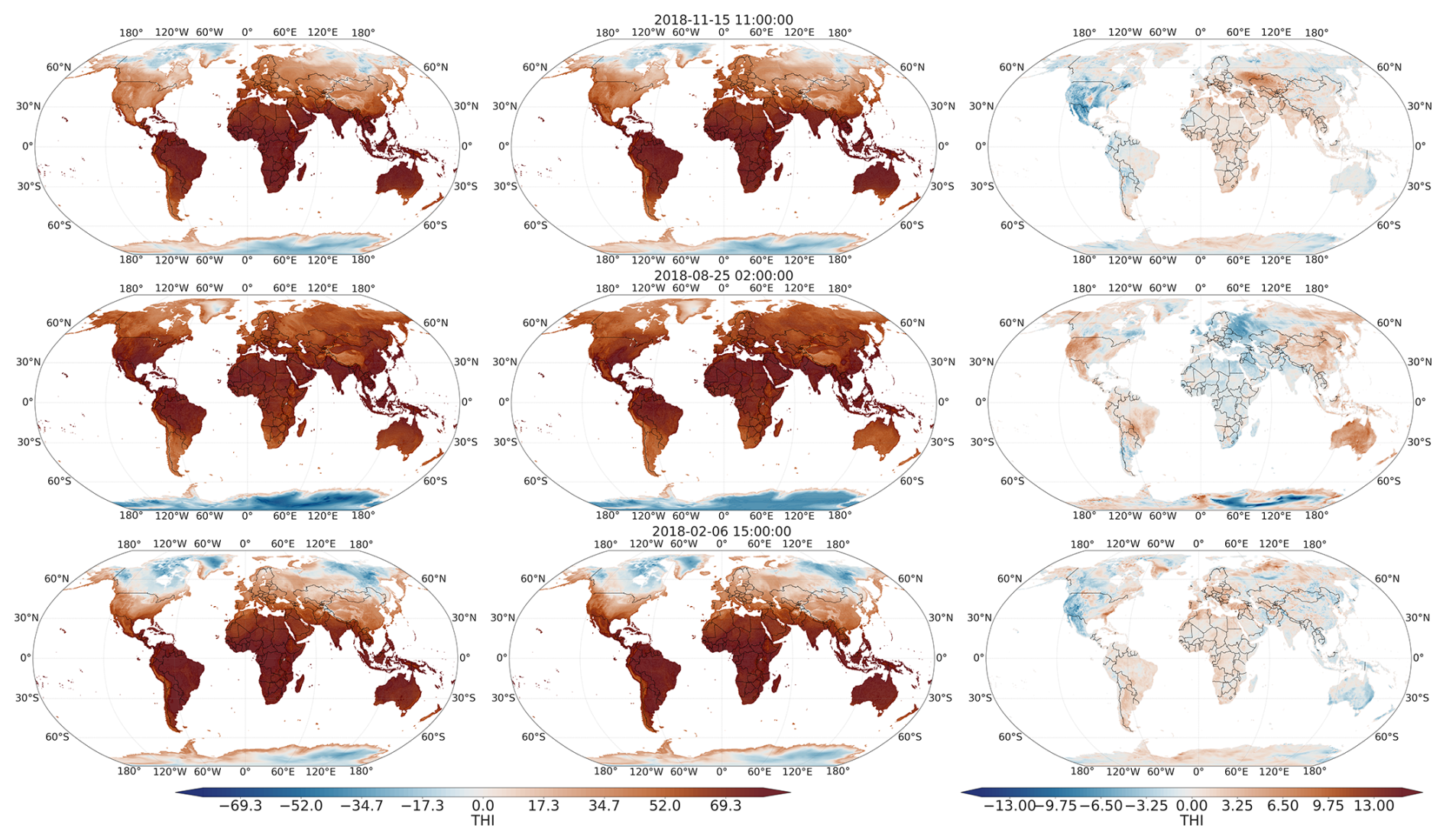
Figure 5Comparison of ground truth THI and model predictions for three randomly selected hourly time points. The first column displays the ground truth THI values calculated from ERA5 data for three randomly selected time points within the evaluation period. The second column shows the corresponding THI predictions from our model. The third column illustrates the differences between the ground truth and the model predictions (ground truth − prediction).
In addition, to further assess the performance of the trained model on a spatial level, we constructed maps of ME, MAE, and MSE, using the evaluation set put aside during training. These maps are presented in Fig. 6. The ME metric allowed us to quantify whether there was any systematic overestimation or underestimation in specific areas of the world. As observed, there is significant overestimation of THI in a large portion of Antarctica. This overestimation is not of concern for the scope of this study, as Antarctica is an region with no risk of heat stress for humans or livestock. Due to the low relevance of heat stress in this uninhabited region and to optimize computational resources, Antarctica was excluded from further inference procedures. This was not found in the North Pole regions, as it was excluded from training and evaluation procedures due to the absence of land at latitudes higher than 83° N. We attribute this overestimation to the length of the day feature, as this was only observed in months were there was no sunlight in the specific region. A month-by-month figure of ME is presented in Appendix C.
The spatial distribution of mean absolute error (MAE) indicates that the model performs well in equatorial regions, accurately predicting hourly THI values with MAEs around 1 THI unit. However, MAE values are higher in some mountainous regions, such as the western United States, Tibet, and Mongolia, where they range from 4 to 6 THI units. This discrepancy is further highlighted in the mean squared error (MSE), which reaches values between 25 and 35 in these areas. Since the model shows minimal mean error (ME) in these regions, it effectively captures the average THI conditions but struggles with the larger diurnal temperature variations typical of high altitudes (Pepin and Seidel, 2005).
This altitude-dependent performance if clearly demonstrated in the kernel density estimation (KDE) plot, presented in the bottom panel of Fig. 6, which shows a strong relationship between MAE and elevation. The KDE plot shows that the vast majority of predictions at low altitudes (below 500 m) cluster around the model's mean MAE of around 2–3 THI units, an indication of consistent performance in lowland areas. There is however a positive relationship between MAE and elevation, evident by the positive gradient of the linear regression fit. While the model may have slight inaccuracies in capturing THI at specific hours, there is no indication of a systematic bias across the dataset. These findings suggest that, overall, the model's hourly predictions are robust.
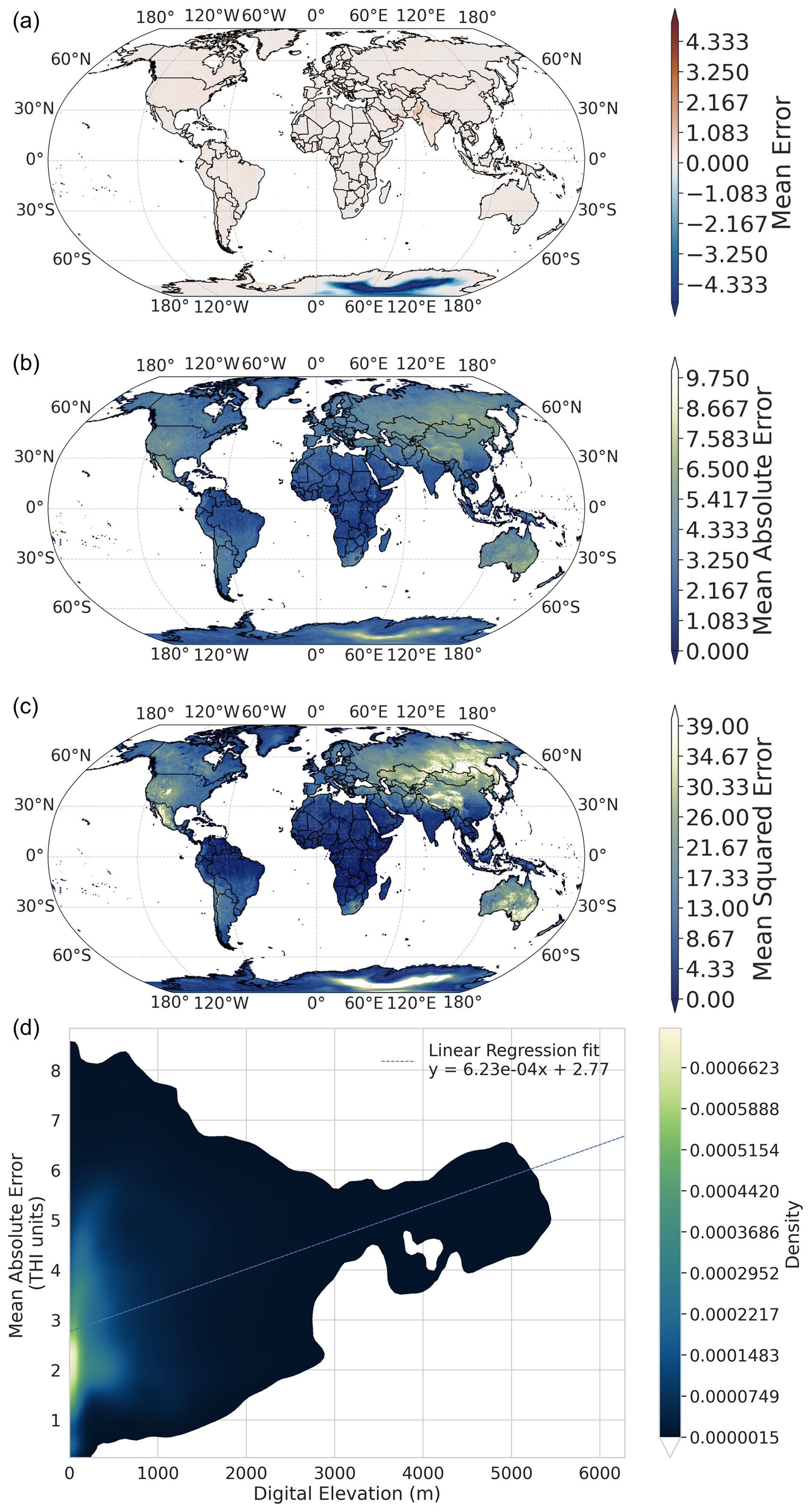
Figure 6Spatial and altitudinal distribution of model performance metrics obtained from the evaluation set (February 2018 to December 2020). Panel (a) shows the ME, an indicator of systematic bias in the THI predictions. Panel (b) shows MAE, an indicator of the average magnitude of prediction errors, and panel (c) shows MSE, which emphasizes larger prediction discrepancies. Panel (d) shows the relationship between MAE and altitude is presented as a kernel density estimation plot. The dashed line represents a linear regression fit between the two.
Lastly, we explored the applicability of the trained model on a different dataset with similar hourly temporal resolution but higher spatial resolution, namely ERA5-Land, which is available at a 9 km resolution (Muñoz-Sabater et al., 2021). When evaluating the model's performance on ERA5-Land data, we calculated the mean absolute error (MAE), mean squared error (MSE), and R2 values by comparing the model's predictions against THI values derived directly from the ERA5-Land dataset (shown in Appendix B). These performance metrics were found to be closely aligned with those obtained on the original ERA5 data, demonstrating the model's consistency when applied to datasets with finer spatial resolution.
Notably, the model exhibited a similar overestimation of THI values in Antarctica on ERA5-Land as it did on ERA5. Furthermore, the spatial distribution of errors remained consistent with that observed on the ERA5 data. Detailed results of this analysis are presented in Appendix B.
3.2 THI projections
Building upon these findings, we employed Model 1 for inference using 12 GDDP NASA-NEX CMIP6 models under two distinct climate scenarios: SSP2-4.5 (representing a moderate stabilization emission scenario) and SSP5-8.5 (representing a business-as-usual scenario with rising emissions until the end of the century). The implicit assumption in this approach is that the diel cycle of the THI does not alter significantly under climate change scenarios. Utilizing all combinations of climate models and scenarios, we generated datasets spanning the period 2020 to 2100. These datasets are publicly available at https://doi.org/10.26050/WDCC/THI for further investigation and use in climate change impact studies (Georgiades, 2024b).
To address the uncertainties inherent in long-term climate projections, especially those extending to the end of the century, we employed an ensemble approach that incorporates outputs from 12 climate models. Each model is based on varying assumptions, parameterizations, and computational algorithms, which result in different projections of future conditions. By including this range of models, we capture a broad spectrum of potential climate outcomes, thereby accounting for the variability and uncertainty characteristic of long-term projections. This approach allows for the construction of projection intervals that provide a probabilistic range of possible scenarios, rather than relying on a single deterministic outcome. This ensemble method, widely adopted in climate science, allows us to average or analyse the full set of outputs, offering robust estimates that reflect a range of plausible future conditions.
3.3 Limitations
One limitation of the model, evident from the spatial distribution of MAE and MSE, is the reduced accuracy in regions with complex topography, such as certain mountainous areas, where MAE and MSE values are higher when compared to equatorial regions, even though the average THI is captured well (ME is close to 0). This discrepancy likely originates from the unique microclimates and larger diurnal variations often observed at higher altitudes (Pepin and Seidel, 2005). This limitation may lead to over- or underestimation of THI values in mountainous terrain, affecting the precision of heat stress predictions for livestock in these areas.
Additionally, our model relies on daily climate projections that are temporally downscaled to an hourly resolution. While effective for capturing broad diurnal trends, this approach may not fully account for short-term extreme weather events or rapidly changing temperature and humidity conditions, especially in regions prone to sudden weather shifts.
To address these limitations, more advanced machine learning techniques could be employed, including deep learning models designed to capture complex temporal and spatial dependencies, such as transformer-based models and convolutional neural networks (Vaswani et al., 2023; Ashiotis et al., 2023). These architectures are capable of modelling intricate patterns and variability within climate data, potentially improving prediction accuracy in regions with complex topography and variable climate conditions. However, implementing these models would require significantly greater computational resources.
Code to reproduce the results presented in this paper is available in the public GitHub repository at https://github.com/pantelisgeor/Temperature-Humidity-Index-ML (last access: 27 January 2025) (https://doi.org/10.5281/zenodo.14747375, Georgiades, 2024a). The code provided is written in Python, and the workload can be executed by running a series of bash scripts, as documented in the repository description. The code is provided under an MIT licence, which allows for users to freely use and modify the code.
The data produced in this study are available at https://doi.org/10.26050/WDCC/THI (Georgiades, 2024b) in NetCDF format, with an hourly temporal resolution and 0.25° spatial resolution. The datasets are published under a CC BY 4.0 licence.
Climate change, driven by anthropogenic emissions, entails a significant risk to ecosystems and societies worldwide. One of the anticipated consequences is rising global temperatures. The agricultural sector, vital for global food security and economies, is particularly vulnerable. Dairy farming, a crucial sub-sector, faces significant economic challenges due to heat stress impacting dairy cattle and associated impacts from the exposure to heat and humidity anomalies. Heat stress in dairy cows is commonly quantified using the Thermal Humidity Index (THI), a simple metric requiring only temperature and humidity data. Previous work utilized daily THI values, lacking the necessary granularity to capture the crucial intraday climatic variability for accurate heat load estimation.
To address this limitation, we trained a machine learning model (XGBoost regressor) on global hourly historical reanalysis data (ERA5) to effectively downscale daily climate variables to hourly THI values. Our models demonstrably performed well against ground truth data from an independent validation period. The implicit assumption in this approach is that the diel cycle of the THI does not alter significantly under climate change scenarios.
Leveraging the good performance and agreement between the three models, we employed the most computationally efficient model to generate global hourly THI projections until the end of the century. This involved utilizing 0.25° GDDP NASA-NEX CMIP6 data with 12 climate models and two emission scenarios (SSP2-4.5 and SSP5-8.5).
The generated hourly THI datasets hold significant potential to contribute towards the optimization of heat stress management in the dairy industry. These datasets can empower stakeholders with the ability to create highly accurate and geographically specific heat stress risk assessments. This information can then be used to develop targeted mitigation strategies, allowing farmers, agricultural communities, and organizations to proactively manage heat stress and optimize animal well-being and production efficiency. Furthermore, incorporating these datasets into climate change adaptation plans allows policymakers and the dairy cattle sector to develop long-term strategies for ensuring the sustainability of the dairy industry in the face of a changing climate. Ultimately, this research paves the way for a more resilient and sustainable future for dairy farming.
To aid our choice of predictive algorithm, we conducted a comparison between the XGBoost and random forest regression algorithms, utilizing their respective implementations in Python's xgboost and scikit-learn libraries. For a fair comparison, we applied identical values for parameters that were analogous between the two models.
-
Number of estimators: 50.
-
Maximum depth: 20.
-
Loss function: root mean squared error (RMSE).
-
Features in each tree: square root of the number of features.
-
Number of cores for parallelization: 128.
Both models were trained using global data from January 2000 and evaluated using data from January 2018. Table A1 presents the time taken in minutes for each model to train and evaluate 1 month's worth of data (∼ 290 million data points), along with the memory utilization during training. It is noted that the times reported here exclude data loading and feature construction processes and only include the training and inference procedures for the two models. Comparing these figures, it is evident that, in the current application, the XGBoost algorithm is more efficient in both compute time and memory utilization.
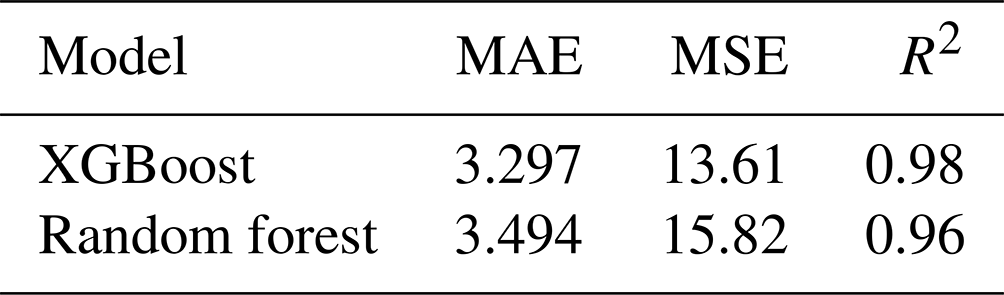
Next, we compared the predictive power of the two trained models, using global data for January 2018. Both models were used to predict the hourly THI values for this time period and compared to ground truth (THI values calculated using the ERA5 data). Table A2 presents the MAE, MSE, and R2 metrics obtained from evaluating the two models' predictions for the month of January 2018 against the ground truth THI calculated using the ERA5 data. In all three metrics, the XGBoost model outperformed the random forest model.
Figure A1 displays a 2×2 grid of predictions generated by the XGBoost and random forest models against the ground truth THI values, derived from the ERA5 dataset, for four randomly selected locations. As shown, XGBoost performs slightly better compared to the random forest model. Finally, an important reason behind our decision to carry out this study using the XGBoost model was the need for incremental learning, which the random forest implementation lacks. Given the extensive data volume and the necessity for checkpoint saves, the XGBoost algorithm was ultimately chosen.
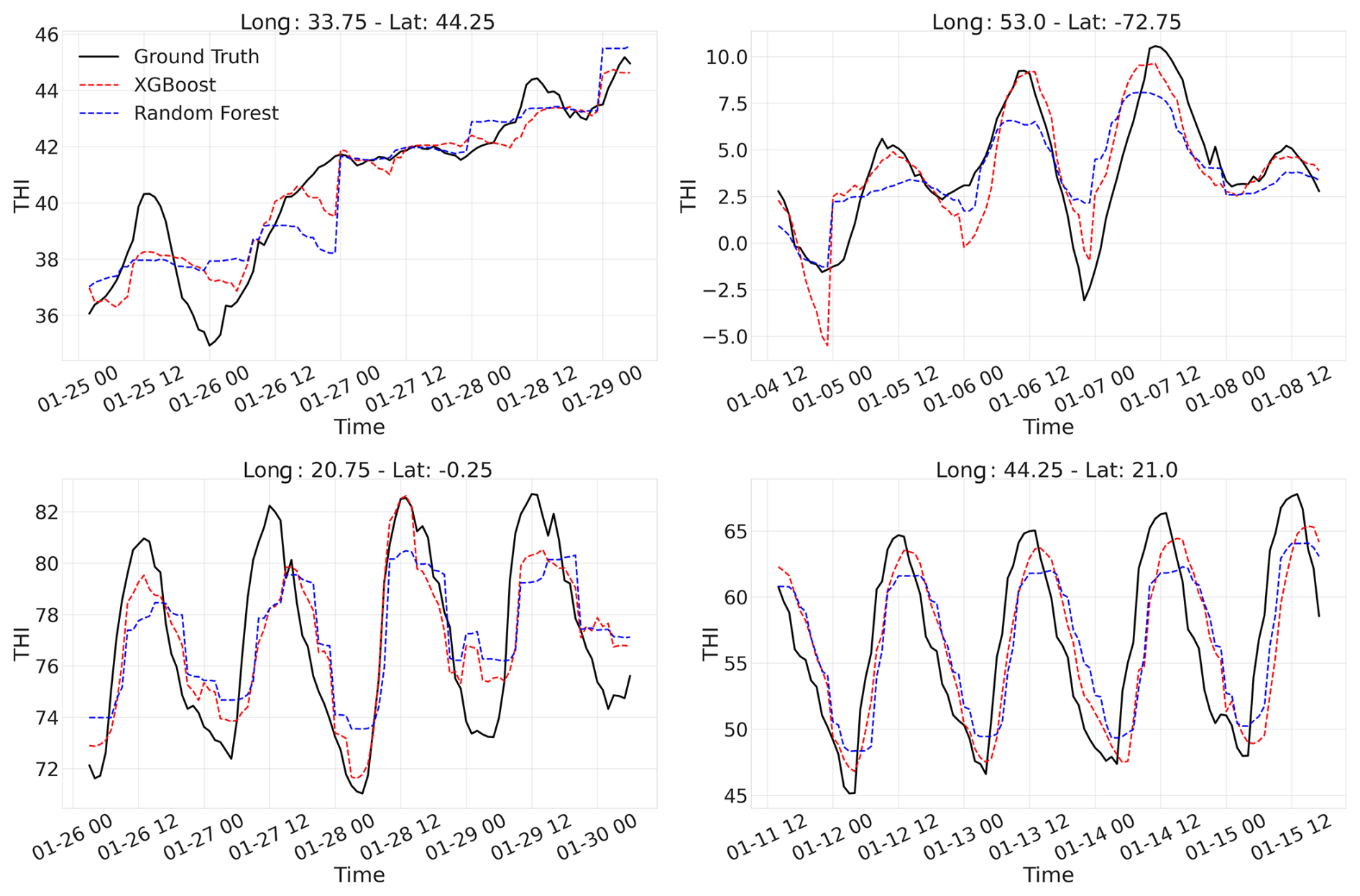
Figure A1Comparative time series plots of four randomly chosen locations between the predictions made by the XGBoost and the random forest against the ground truth THI values. The predictions shown here are from January 2018.
Table A1Time taken for training and inference procedures and memory utilization during training for the XGBoost and random forest models.
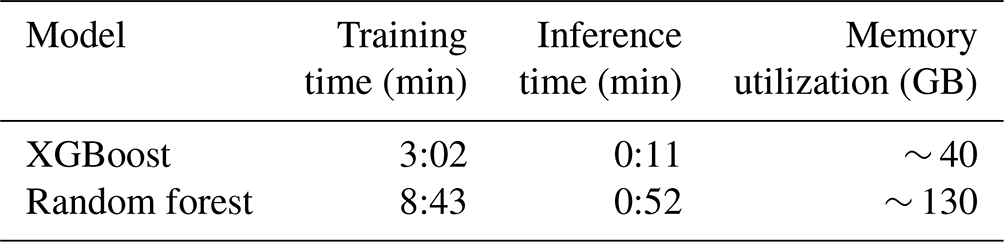
Table A2The MAE, MSE, and R2 metrics obtained from comparing the two model predictions for January 2018 against the ground truth THI, calculated using the ERA5 data.
To evaluate the applicability of the trained model on input data with higher spatial resolution than ERA5, we utilized the ERA5-Land dataset for the year 2018. This dataset offers a spatial resolution of ∼ 9 km and an hourly temporal resolution. The methods for feature construction employed in this experiment were identical to those used for the ERA5 dataset.
Table B1 presents the evaluation metrics obtained from comparing the model predictions and THI ground truth values, calculated using the ERA5-Land dataset for year 2018. Finally, Fig. B3 displays the spatial distribution of ME, MAE, and MSE for the model predictions against ground truth THI values, evaluated using the ERA5-Land dataset.
Table B1Evaluation metrics obtained using the trained model and ERA5-Land data for the year 2018.

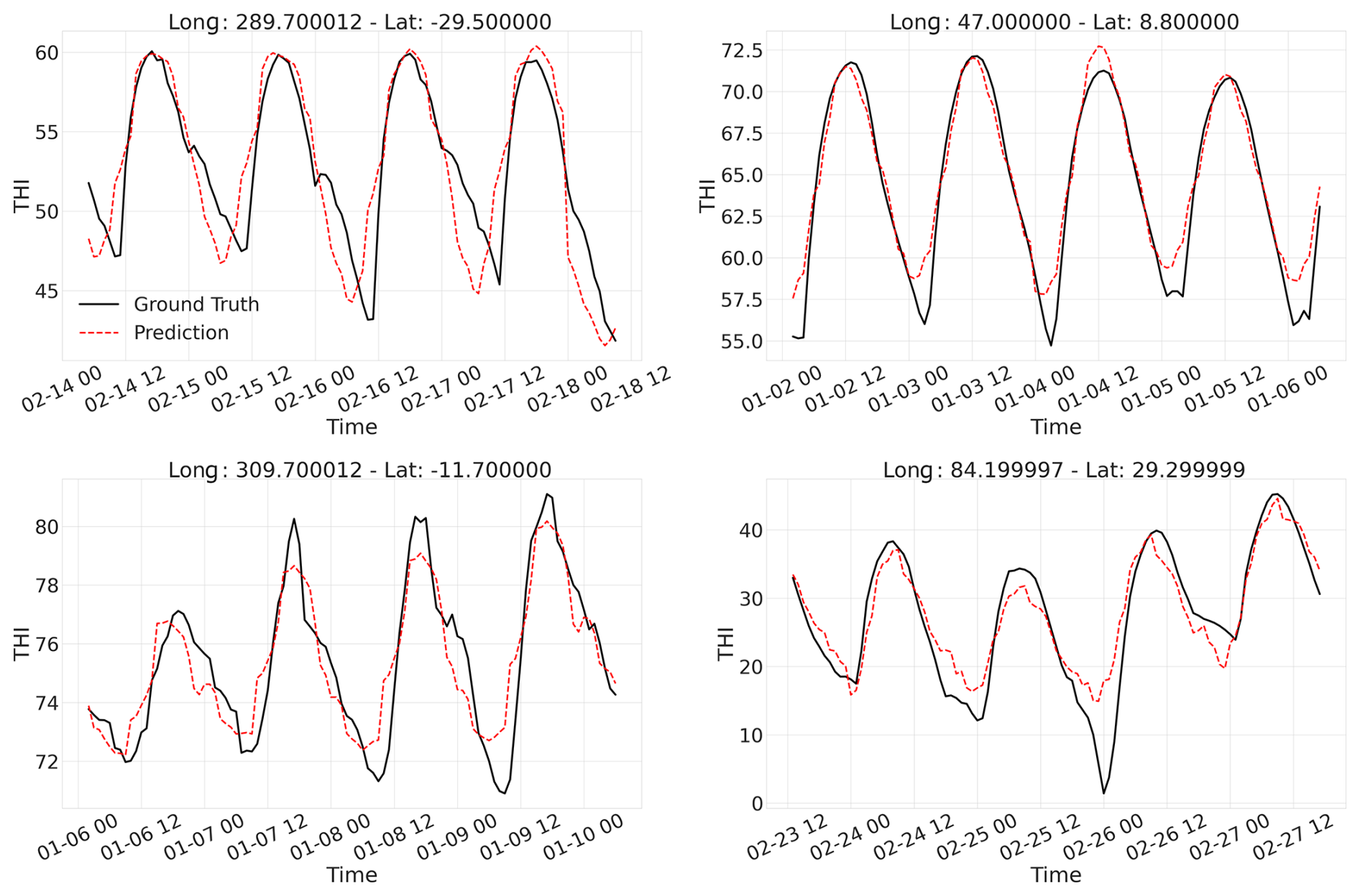
Figure B1Ground truth (THI derived from ERA5-Land data) and model prediction examples for the year 2018.
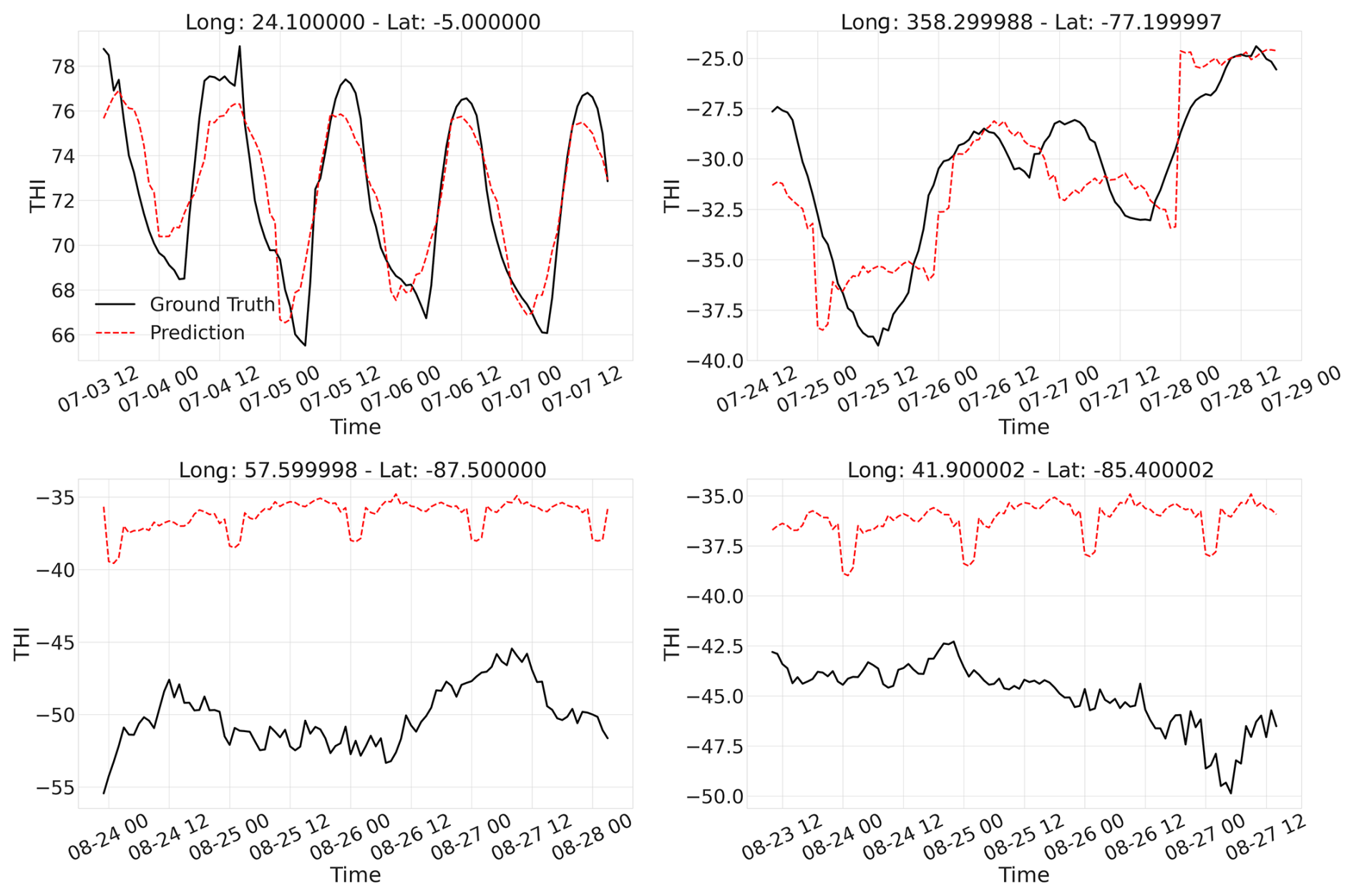
Figure B2Examples of ground truth (THI derived from ERA5-Land data) and model predictions for the year 2018. The bottom panel presents cases from Antarctica, where the model approaches a predictive limit of −40 THI units, comparable to the inference results obtained using ERA5 data.

Figure B3Spatial distribution of ME (a), MAE (b), and MSE (c) as evaluated from ERA5-Land for the year 2018.
We further examined the systematic overestimation of the THI in Antarctica by calculating the mean error (ME) globally for each month of the year, as shown in Fig. C1. The results indicate that ME is minimal during months with non-zero sunlight, while significant THI overestimation occurs from March through October in Antarctica, coinciding with periods of continuous darkness at latitudes approaching −90°, as shown in Fig. C2.
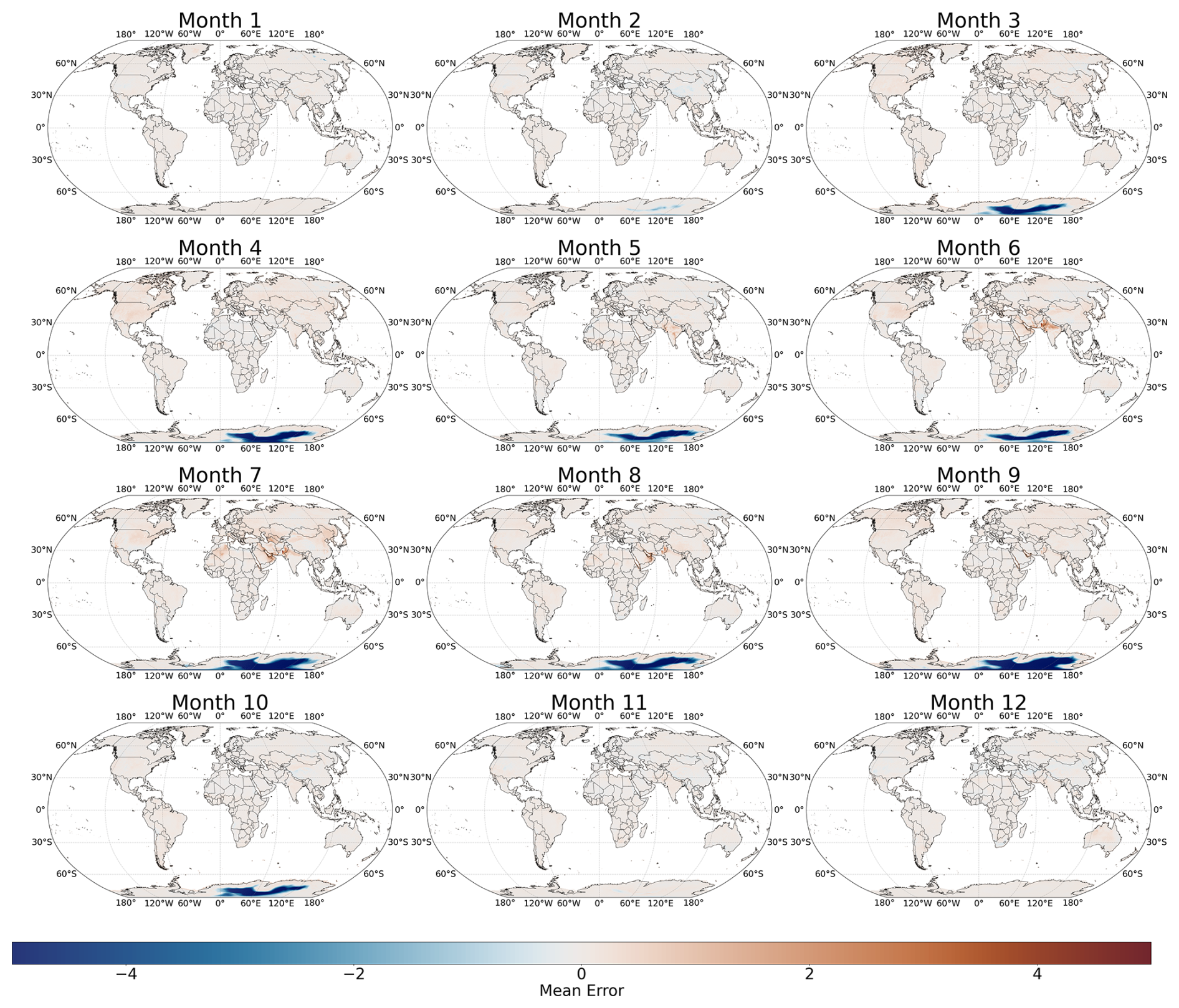
Figure C1Evolution of ME in Antarctica for each month of the year between ground truth THI, calculated from ERA5, and the trained model prediction.
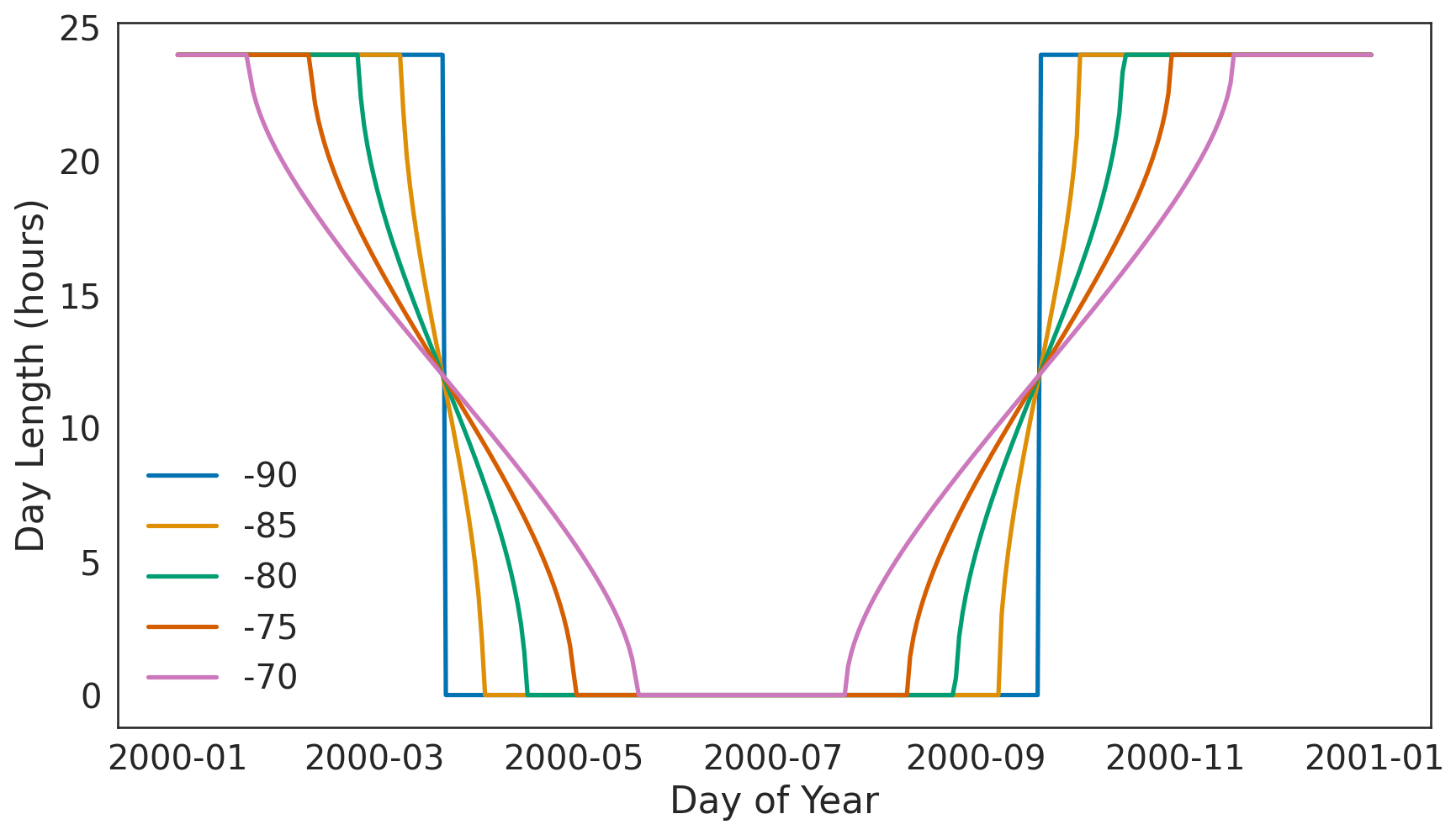
Figure C2Number of hours of sunshine experienced by areas at latitudes ranging from −70 to −90° throughout a year.
PG: conceptualization, data curation, format analysis, methodology, software, validation, and original draft preparation. TE: methodology and review and editing. YP: data curation, software, resources, and review and editing. JA: data curation, software, and review and editing. JL: review and editing. MN: conceptualization, methodology, validation, and original draft preparation.
The contact author has declared that none of the authors has any competing interests.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
We would like to acknowledge the High Performance Computing Facility of the Cyprus Institute for their support in the computational and storage needs for this study.
This research was supported by the EMME-CARE project that has received funding from the European Union's Horizon 2020 Research and Innovation programme, under grant agreement no. 856612, as well as matching co-funding by the government of Cyprus. This research was also supported by the PREVENT project that has received funding from the European Union's Horizon Europe Research and Innovation programme under grant agreement no. 101081276 and the European High Performance Computing Joint Undertaking (JU) and Germany, Bulgaria, Austria, Croatia, Cyprus, Czech Republic, Denmark, Estonia, Finland, Greece, Hungary, Ireland, Italy, Lithuania, Latvia, Poland, Portugal, Romania, Slovenia, Spain, Sweden, France, Netherlands, Belgium, Luxembourg, Slovakia, Norway, Türkiye, Republic of North Macedonia, Iceland, Montenegro, and Serbia under grant agreement no. 101101903.
This research has been supported by Horizon 2020 (grant no. 856612), the HORIZON EUROPE Reforming and enhancing the European Research and Innovation system (grant no. 101081276), and the European High Performance Computing Joint Undertaking (grant no. 101101903).
This paper was edited by Jing Wei and reviewed by three anonymous referees.
Abbass, K., Qasim, M. Z., Song, H., Murshed, M., Mahmood, H., and Younis, I.: A review of the global climate change impacts, adaptation, and sustainable mitigation measures, Environ. Sci. Pollut. Res., 29, 42539–42559, https://doi.org/10.1007/s11356-022-19718-6, 2022. a
Ashiotis, G., Georgiades, P., Christoudias, T., and Nicolaou, M. A.: Toward Explainable and Transferable Deep Downscaling of Atmospheric Pollutants, IEEE Geosci. Remote Sens. Lett., 20, 1–5, https://doi.org/10.1109/lgrs.2023.3329710, 2023. a, b
Bell, B., Hersbach, H., Simmons, A., Berrisford, P., Dahlgren, P., Horányi, A., Muñoz‐Sabater, J., Nicolas, J., Radu, R., Schepers, D., Soci, C., Villaume, S., Bidlot, J., Haimberger, L., Woollen, J., Buontempo, C., and Thépaut, J.: The ERA5 global reanalysis: Preliminary extension to 1950, Q. J. Roy. Meteor. Soc., 147, 4186–4227, https://doi.org/10.1002/qj.4174, 2021. a
Bernabucci, U., Biffani, S., Buggiotti, L., Vitali, A., Lacetera, N., and Nardone, A.: The effects of heat stress in Italian Holstein dairy cattle, J. Dairy Sci., 97, 471–486, https://doi.org/10.3168/jds.2013-6611, 2014. a
Bohmanova, J., Misztal, I., and Cole, J.: Temperature-Humidity Indices as Indicators of Milk Production Losses due to Heat Stress, J. Dairy Sci., 90, 1947–1956, https://doi.org/10.3168/jds.2006-513, 2007. a, b
Bouraoui, R., Lahmar, M., Majdoub, A., Djemali, M., and Belyea, R.: The relationship of temperature-humidity index with milk production of dairy cows in a Mediterranean climate, Animal Res., 51, 479–491, https://doi.org/10.1051/animres:2002036, 2002. a
Brock, T. D.: Calculating solar radiation for ecological studies, Ecological Modelling, 14, 1–19, https://doi.org/10.1016/0304-3800(81)90011-9, 1981. a
Brügemann, K., Gernand, E., König von Borstel, U., and König, S.: Defining and evaluating heat stress thresholds in different dairy cow production systems, Arch. Anim. Breed., 55, 13–24, https://doi.org/10.5194/aab-55-13-2012, 2012. a
Burhans, W., Rossiter Burhans, C., and Baumgard, L.: Invited review: Lethal heat stress: The putative pathophysiology of a deadly disorder in dairy cattle, J. Dairy Sci., 105, 3716–3735, https://doi.org/10.3168/jds.2021-21080, 2022. a
Cartwright, S. L., Schmied, J., Karrow, N., and Mallard, B. A.: Impact of heat stress on dairy cattle and selection strategies for thermotolerance: a review, Front. Veterinary Sci., 10, https://doi.org/10.3389/fvets.2023.1198697, 2023. a, b
Chen, T. and Guestrin, C.: XGBoost: A Scalable Tree Boosting System, arXiv [preprint], https://doi.org/10.48550/ARXIV.1603.02754, 2016. a
Cheng, M., McCarl, B., and Fei, C.: Climate Change and Livestock Production: A Literature Review, Atmosphere, 13, 140, https://doi.org/10.3390/atmos13010140, 2022. a, b
Collier, R. J., Hall, L. W., Rungruang, S., and Zimbleman, R. B.: Quantifying heat stress and its impact on metabolism and performance, Department of Animal Sciences University of Arizona, 68, 1–11, 2012. a
Escarcha, J., Lassa, J., and Zander, K.: Livestock Under Climate Change: A Systematic Review of Impacts and Adaptation, Climate, 6, 54, https://doi.org/10.3390/cli6030054, 2018. a
Forsythe, W. C., Rykiel, E. J., Stahl, R. S., Wu, H.-i., and Schoolfield, R. M.: A model comparison for daylength as a function of latitude and day of year, Ecol. Model., 80, 87–95, https://doi.org/10.1016/0304-3800(94)00034-F, 1995. a
Georgiades, P.: Temperature-Humidity-Index-ML: Global Projections of Heat-Stress at High Temporal Resolution Using Machine Learning (THI), Zenodo [code], https://doi.org/10.5281/zenodo.14747375, 2024a. a
Georgiades, P.: Temperature Humidity Index GDDP-NEX-CMIP6 ML projections, World Data Center for Climate (WDCC) at DKRZ [data set], https://doi.org/10.26050/WDCC/THI, 2024b. a, b, c
Hahn, G., Mader, T., Gaughan, J., Hu, Q., and Nienaber, J.: Heat waves and their impacts on feedlot cattle, ICB11, 1, 1999. a
Hahn, G., Gaugthan, J., Mader, T., and Eigenberg, R.: Thermal Indices and Their Applications for Livestock Environments, in: Livestock Energetics and Thermal Environmental Management, edited by: DeShazer, J., chap. 5, American Society of Agricultural and Biological Engineers, St. Joseph, MI, USA, https://doi.org/10.13031/2013.28298, 2009. a, b, c
Hahn, G. L.: Dynamic responses of cattle to thermal heat loads, J. Animal Sci., 77, 10, https://doi.org/10.2527/1997.77suppl_210x, 1997. a
Hersbach, H., Bell, B., Berrisford, P., Hirahara, S., Horányi, A., Muñoz‐Sabater, J., Nicolas, J., Peubey, C., Radu, R., Schepers, D., Simmons, A., Soci, C., Abdalla, S., Abellan, X., Balsamo, G., Bechtold, P., Biavati, G., Bidlot, J., Bonavita, M., De Chiara, G., Dahlgren, P., Dee, D., Diamantakis, M., Dragani, R., Flemming, J., Forbes, R., Fuentes, M., Geer, A., Haimberger, L., Healy, S., Hogan, R. J., Hólm, E., Janisková, M., Keeley, S., Laloyaux, P., Lopez, P., Lupu, C., Radnoti, G., de Rosnay, P., Rozum, I., Vamborg, F., Villaume, S., and Thépaut, J.: The ERA5 global reanalysis, Q. J. Roy. Meteor. Soc., 146, 1999–2049, https://doi.org/10.1002/qj.3803, 2020. a, b
Huntingford, C., Jeffers, E. S., Bonsall, M. B., Christensen, H. M., Lees, T., and Yang, H.: Machine learning and artificial intelligence to aid climate change research and preparedness, Environ. Res. Lett., 14, 124007, https://doi.org/10.1088/1748-9326/ab4e55, 2019. a
Igono, M. O., Bjotvedt, G., and Sanford-Crane, H. T.: Environmental profile and critical temperature effects on milk production of Holstein cows in desert climate, Int. J. Biometeorol., 36, 77–87, https://doi.org/10.1007/bf01208917, 1992. a
IPCC: Climate Change 2022 – Impacts, Adaptation and Vulnerability: Working Group II Contribution to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change, Cambridge University Press, ISBN 9781009325844, https://doi.org/10.1017/9781009325844, 2023. a
Kadzere, C., Murphy, M., Silanikove, N., and Maltz, E.: Heat stress in lactating dairy cows: a review, Livest. Prod. Sci., 77, 59–91, https://doi.org/10.1016/s0301-6226(01)00330-x, 2002. a, b
Malhi, Y., Franklin, J., Seddon, N., Solan, M., Turner, M. G., Field, C. B., and Knowlton, N.: Climate change and ecosystems: threats, opportunities and solutions, Philos. T. Roy. Soc. B, 375, 20190104, https://doi.org/10.1098/rstb.2019.0104, 2020. a
Mauger, G., Bauman, Y., Nennich, T., and Salathé, E.: Impacts of Climate Change on Milk Production in the United States, Prof. Geogr., 67, 121–131, https://doi.org/10.1080/00330124.2014.921017, 2014. a
Michel, A., Sharma, V., Lehning, M., and Huwald, H.: Climate change scenarios at hourly time‐step over Switzerland from an enhanced temporal downscaling approach, Int. J. Climatol., 41, 3503–3522, https://doi.org/10.1002/joc.7032, 2021. a
Moore, S. S., Costa, A., Penasa, M., Callegaro, S., and De Marchi, M.: How heat stress conditions affect milk yield, composition, and price in Italian Holstein herds, J. Dairy Sci., 106, 4042–4058, https://doi.org/10.3168/jds.2022-22640, 2023a. a
Moore, S. S., Costa, A., Penasa, M., Callegaro, S., and De Marchi, M.: How heat stress conditions affect milk yield, composition, and price in Italian Holstein herds, J. Dairy Sci., 106, 4042–4058, 2023b. a
Muñoz-Sabater, J., Dutra, E., Agustí-Panareda, A., Albergel, C., Arduini, G., Balsamo, G., Boussetta, S., Choulga, M., Harrigan, S., Hersbach, H., Martens, B., Miralles, D. G., Piles, M., Rodríguez-Fernández, N. J., Zsoter, E., Buontempo, C., and Thépaut, J.-N.: ERA5-Land: a state-of-the-art global reanalysis dataset for land applications, Earth Syst. Sci. Data, 13, 4349–4383, https://doi.org/10.5194/essd-13-4349-2021, 2021. a, b
Napoli, C. D.: Thermal comfort indices derived from ERA5 reanalysis, Climate Data Store [data set], https://doi.org/10.24381/CDS.553B7518, 2020. a
North, M. A., Franke, J. A., Ouweneel, B., and Trisos, C. H.: Global risk of heat stress to cattle from climate change, Environ. Res. Lett., 18, 094027, https://doi.org/10.1088/1748-9326/aceb79, 2023. a, b
Nyeko-Ogiramoi, P., Willems, P., Ngirane-Katashaya, G., and Ntegek, V.: Nonparametric Statistical Downscaling of Precipitation from Global Climate Models, InTech, ISBN 9789535101352, https://doi.org/10.5772/32910, 2012. a
Pepin, N. C. and Seidel, D. J.: A global comparison of surface and free‐air temperatures at high elevations, J. Geophys. Res.-Atmos., 110, D03104, https://doi.org/10.1029/2004jd005047, 2005. a, b
Polsky, L. and von Keyserlingk, M. A.: Invited review: Effects of heat stress on dairy cattle welfare, J. Dairy Sci., 100, 8645–8657, https://doi.org/10.3168/jds.2017-12651, 2017. a
Pour, S. H., Shahid, S., and Chung, E.-S.: A Hybrid Model for Statistical Downscaling of Daily Rainfall, Procedia Eng., 154, 1424–1430, https://doi.org/10.1016/j.proeng.2016.07.514, 2016. a
Rampal, N., Gibson, P. B., Sood, A., Stuart, S., Fauchereau, N. C., Brandolino, C., Noll, B., and Meyers, T.: High-resolution downscaling with interpretable deep learning: Rainfall extremes over New Zealand, Weather and Climate Extremes, 38, 100525, https://doi.org/10.1016/j.wace.2022.100525, 2022. a
Ravagnolo, O., Misztal, I., and Hoogenboom, G.: Genetic Component of Heat Stress in Dairy Cattle, Development of Heat Index Function, J. Dairy Sci., 83, 2120–2125, https://doi.org/10.3168/jds.s0022-0302(00)75094-6, 2000. a
Requena, A. I., Nguyen, T.-H., Burn, D. H., Coulibaly, P., and Nguyen, V.-T.-V.: A temporal downscaling approach for sub-daily gridded extreme rainfall intensity estimation under climate change, J. Hydrol., 35, 100811, https://doi.org/10.1016/j.ejrh.2021.100811, 2021. a
Sheik, S., Mohammed, R., Teeparthi, K., and Raghuvamsi, Y.: Machine Learning-Based Prediction of Intergranular Corrosion Resistance in Austenitic Stainless Steels Exposed to Various Heat Treatments, Journal of The Institution of Engineers (India): Series D, https://doi.org/10.1007/s40033-024-00675-y, 2024. a
St-Pierre, N., Cobanov, B., and Schnitkey, G.: Economic Losses from Heat Stress by US Livestock Industries, J. Dairy Sci., 86, E52–E77, https://doi.org/10.3168/jds.s0022-0302(03)74040-5, 2003. a, b, c
Tang, J., Niu, X., Wang, S., Gao, H., Wang, X., and Wu, J.: Statistical downscaling and dynamical downscaling of regional climate in China: Present climate evaluations and future climate projections, J. Geophys. Res.-Atmos., 121, 2110–2129, https://doi.org/10.1002/2015jd023977, 2016. a
Tarek, M., Brissette, F. P., and Arsenault, R.: Evaluation of the ERA5 reanalysis as a potential reference dataset for hydrological modelling over North America, Hydrol. Earth Syst. Sci., 24, 2527–2544, https://doi.org/10.5194/hess-24-2527-2020, 2020. a
Thrasher, B., Wang, W., Michaelis, A., Melton, F., Lee, T., and Nemani, R.: NASA Global Daily Downscaled Projections, CMIP6, Sci. Data, 9, 262, https://doi.org/10.1038/s41597-022-01393-4, 2022. a, b
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., and Polosukhin, I.: Attention Is All You Need, arXiv [preprint], https://doi.org/10.48550/arXiv.1706.03762, 2023. a
Wang, L., Li, Q., Peng, X., and Lv, Q.: A Temporal Downscaling Model for Gridded Geophysical Data with Enhanced Residual U-Net, Remote Sens., 16, 442, https://doi.org/10.3390/rs16030442, 2024. a
WMO: Guide to instruments and methods of observation. Wmo.int, World Meteorological Organization (WMO), https://library.wmo.int/idurl/4/68695 (last access: 5 June 2024), 2021. a
Yeck, R. G.: A Guide to Environmental Research on Animals, National Academy of Sciences, National Academies Press, ISBN 0309018692, 9780309018692, 1971. a
Zhou, M., Groot Koerkamp, P., Huynh, T., and Aarnink, A.: Evaporative water loss from dairy cows in climate-controlled respiration chambers, J, Dairy Sci,, 106, 2035–2043, https://doi.org/10.3168/jds.2022-22489, 2023. a
Zimbelman, R., Rhoads, R., Rhoads, M., Duff, G., Baumgard, L., and Collier, R.: Re-Evaluation of the Impact of Temperature Humidity Index (THI) and Black Globe Humidity Index (BGHI) on Milk Production in High Producing Dairy Cows, in: Proceedings of the Southwest Nutrition Conference, Tucson, 26–27 Feburuary 2009, 158–169, 2009. a
- Abstract
- Introduction
- Methodology
- Results
- Code and data availability
- Conclusions
- Appendix A: XGBoost and random forest comparison
- Appendix B: Applicability to high-spatial-resolution data
- Appendix C: Antarctica
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Methodology
- Results
- Code and data availability
- Conclusions
- Appendix A: XGBoost and random forest comparison
- Appendix B: Applicability to high-spatial-resolution data
- Appendix C: Antarctica
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References