the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 15 Jul 2022
| 15 Jul 2022
EMO-5: a high-resolution multi-variable gridded meteorological dataset for Europe
Vera Thiemig
Goncalo N. Gomes
Jon O. Skøien
Markus Ziese
Armin Rauthe-Schöch
Elke Rustemeier
Kira Rehfeldt
Jakub P. Walawender
Christine Kolbe
Damien Pichon
Christoph Schweim
In this paper we present EMO-5 (“European Meteorological Observations”, spatial resolution of 5 km), a European high-resolution, (sub-)daily, multi-variable meteorological dataset built on historical and real-time observations obtained by integrating data from 18 964 ground weather stations, four high-resolution regional observational grids (i.e. CombiPrecip, ZAMG – INCA, EURO4M-APGD, and CarpatClim), and one global reanalysis (ERA-Interim/Land). EMO-5 includes the following at daily resolution: total precipitation, temperatures (minimum and maximum), wind speed, solar radiation, and water vapour pressure. In addition, EMO-5 also makes available 6-hourly precipitation and mean temperature data. The raw observations from the ground weather stations underwent a set of quality controls before SPHEREMAP and Yamamoto interpolation methods were applied in order to estimate for each 5×5 km grid cell the variable value and its affiliated uncertainty, respectively. The quality of the EMO-5 precipitation data was evaluated through (1) comparison with two regional high-resolution datasets (i.e. seNorge2 and seNorge2018), (2) analysis of 15 heavy precipitation events, and (3) examination of the interpolation uncertainty. Results show that EMO-5 successfully captured 80 % of the heavy precipitation events, and that it is of comparable quality to a regional high-resolution dataset. The availability of the uncertainty fields increases the transparency of the dataset and hence the possible usage. EMO-5 (version 1) covers the time period from 1990 to 2019, with a near real-time release of the latest gridded observations foreseen with version 2. As a product of Copernicus, the EU's Earth Observation Programme, the EMO-5 dataset is free and open, and can be accessed at https://doi.org/10.2905/0BD84BE4-CEC8-4180-97A6-8B3ADAAC4D26 (Thiemig et al., 2020).
- Article
(5429 KB) - Full-text XML
- BibTeX
- EndNote





Many environmental models rely heavily on the availability of meteorological data. Factors like the accessibility, quality, and spatio-temporal coverage as well as spatio-temporal resolution of these meteorological data influence and ultimately determine their modelling capacity. This is further intensified for environmental applications that run operationally and require quality-controlled, multi-variable meteorological data in near real-time. One prominent example that relies heavily on good-quality meteorological input data provided in near real-time is the European Flood Awareness System (EFAS), which is part of the Emergency Management Service (EMS) of Copernicus, the EU's Earth Observation Programme. EFAS provides a flood monitoring and forecast service for riverine and flash floods across the whole of Europe. The forecasts of EFAS are calculated using the semi-distributed hydrological rainfall-runoff model LISFLOOD (https://ec-jrc.github.io/lisflood/, last access: 27 June 2022), which relies heavily on quality-controlled, (sub-)daily meteorological information on precipitation, temperature, wind speed, solar radiation, and water vapour pressure for (a) model calibration and validation as well as for (b) the computation of initial conditions during the operational running. In 2006, during the set-up phase of EFAS for pre-operational running, there was an imminent need for a pan-European, quality-controlled, high-resolution, multi-variable, and near real-time as well as historical meteorological dataset. However, despite the existence of a fairly good coverage network of in situ stations across Europe, at that time there existed no overarching service that collected in near real-time all these meteorological in situ data across the entire European domain. For this reason, the Joint Research Centre started in 2006 with the collection, quality control, and gridding of real-time and historical (from 1970) meteorological data across Europe and neighbouring regions, a service that became known as the Copernicus EMS Meteorological Data Collection Centre (MDCC)in 2012.
The CEMS MDCC runs around the clock and produces daily near real-time meteorological grids which are used in the operational running of not only EFAS, but also by two other major CEMS services, namely the European Forest Fire Information System (EFFIS; https://effis.jrc.ec.europa.eu/, last access: 27 June 2022; San-Miguel-Ayanz et al., 2019) and the European Drought Observatory (EDO; https://edo.jrc.ec.europa.eu/, last access: 27 June 2022; Spinoni et al., 2016; Cammalleri et al., 2021). At the same time, the MDCC also collects historical data in an offline mode and feeds these data into the MDCC data collection for the production of historical meteorological grids. This is important as historical data (produced with the same method) are indispensable for calibration of the various models and indicators. While the service produces daily updated grids (EMO-5 operational grids), we have re-run our archive from 1990–2019 to produce a new long-term dataset, which we refer to as version 1 of the EMO-5 (EMO stands for “European Meteorological Observations”, whereas the 5 denotes the spatial resolution of 5 km). EMO-5 (version 1) comprises daily 5×5 km grids for six variables – precipitation, minimum and maximum air temperature, wind speed, solar radiation, and water vapour pressure – and additional 6-hourly grids for precipitation and mean air temperature. The underlying data come from a total of 26 data providers that contributed to the MDCC data collection by sharing data from a total of about 18 694 in situ stations across Europe as well as five gridded datasets over selected areas. The gridded datasets were added to the MDCC data collection in order to improve the quality of the resulting meteorological grids by increasing the information density over selected areas, mainly data-scarce areas and areas with complex topography.
During the past decade, many other observational meteorological data grids emerged, such as E-OBS (Haylock et al., 2008; Cornes et al., 2018) for the whole of Europe; seNorge2 and seNorge2018 for Norway (Lussana et al., 2018); SPREAD for Spain (Serrano-Notivoli et al., 2017); ZAMG-INCA for Austria (Haiden et al., 2011); CombiPrecip for Switzerland (Sideris et al., 2014); CarpatClim for Hungary, Serbia, Romania, Ukraine, Slovakia, Poland, Czech Republic, and Croatia (Antolović et al., 2013; Spinoni et al., 2015); EURO4M-APGD for the European Alps and adjacent flatland regions (Isotta et al., 2014); and SAFRAN for France, Spain, and Tunisia (Quintana-Seguí et al., 2008; Vidal et al., 2010; Quintana-Seguí et al., 2017; Tramblay et al., 2019). However, despite the availability of these datasets and the immense value each of them holds, EMO-5 represents a uniquely valuable resource due to a combination of its pan-European coverage, near real-time production, high temporal (6-hourly and daily) and spatial (5×5 km) resolution, large amount of input data (18 694 in situ stations and five high-resolution regional observational grids), seven different variables (i.e. precipitation; minimum, maximum, and mean air temperature; wind speed; solar radiation; and water vapour pressure), and a substantially long historical data record (from 1 January 1990). These characteristics combine to make EMO-5, to our knowledge, the most complete gridded multi-variable observational near real-time meteorological dataset covering the whole of Europe (and peripheral areas).
The aim of this paper is to present EMO-5 (version 1) and its potential usage, by providing an insight into its data sources, the applied methods, and the quality of the resulting dataset. In this paper, the evaluation of the resulting grid quality is focused mainly on the gridded precipitation data, as (a) precipitation is the most crucial driver for hydrological modelling (our main focus) and (b) the minimum and maximum temperatures of EMO-5 have already been investigated by Lavaysse et al. (2018; EMO-5 was referred to as LISFLOOD in their study). However, we invite the scientific community to expand the evaluation exercise beyond EMO-5 gridded precipitation to other variables and other validation approaches, including through various environmental applications.
Users should be aware that EMO-5 is prepared principally for near real-time rather than climatological applications. EMO-5 (version 1 as well as the operational grids) is an operational dataset based on the maximum amount of quality-controlled information available at any given time. Environmental applications, especially those with real-time, high spatial resolution, or multi-variable needs are likely to benefit from this dataset. Hence, by making the EMO-5 (version 1) data publicly available, we aim to support many other environmental applications and services that would benefit from using these data, such as e.g. hydrological, agricultural, or other environmental applications.
The remainder of this paper is organized as outlined in the following. The source data are described in Sect. 2. The entire workflow of the grid creation, including the quality control criteria applied during data collection and an evaluation of various interpolation methods, are described in Sect. 3. Data access information are given in Sect. 5. An evaluation of the grid quality for precipitation is described in Sect. 4, and finally, some conclusions are presented in Sect. 6, followed by a future outlook.
Table 1EMO-5 data provider (in bold the providers of gridded data).
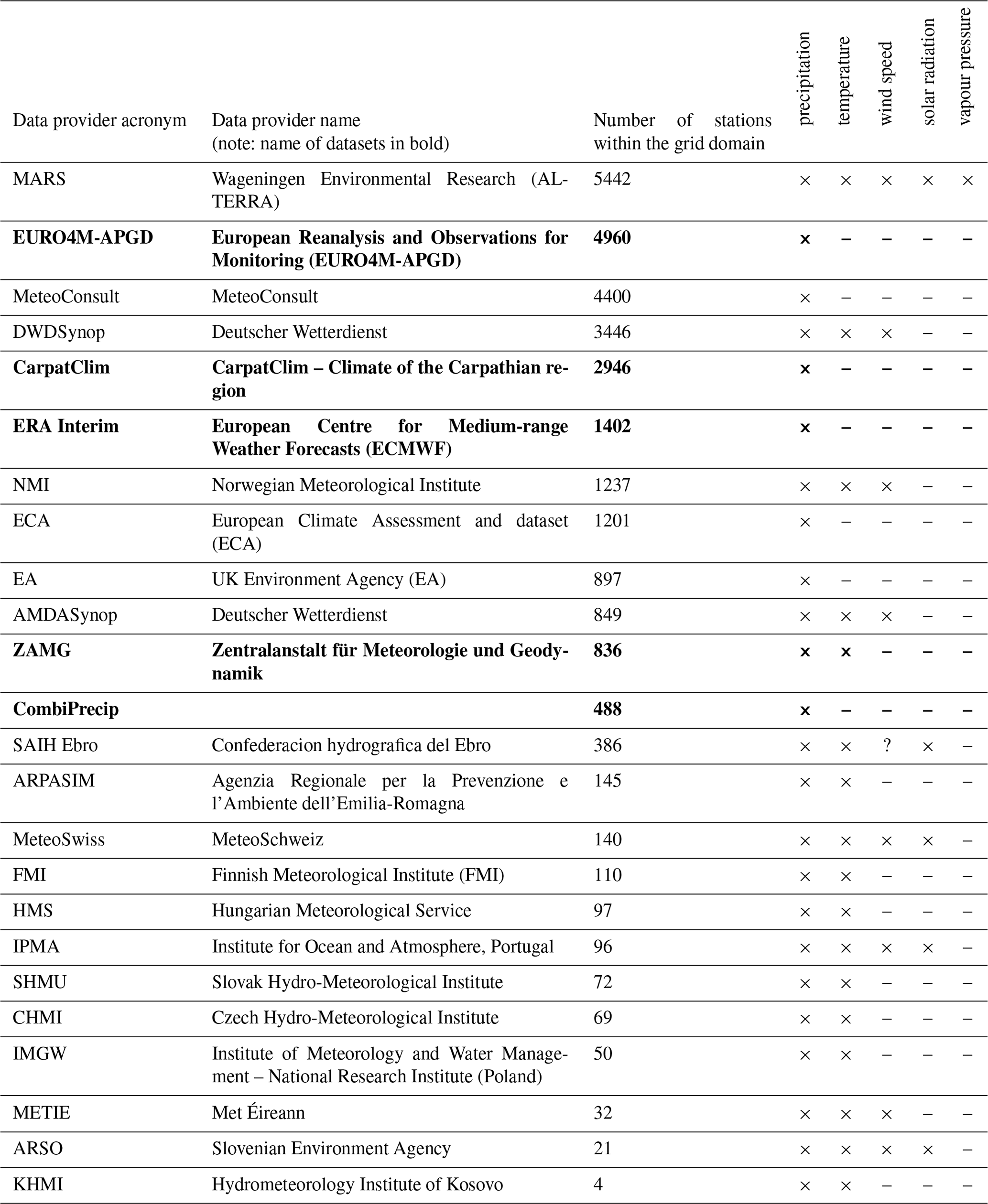
The meteorological data for EMO-5 (operational and version 1) come from 26 data providers (i.e. 21 station data providers plus 5 gridded dataset providers), mostly national meteorological services and a few international or regional bodies. Table 1 shows the full list of data providers contributing to EMO-5.
The MDCC collects historical (from 1970) and real-time observations obtained from 18 694 in situ meteorological stations across Europe and an additional 13 394 meteorological stations globally. It should be noted that while some stations measure multiple variables, others measure only one or two. Furthermore, some stations provided data for the entire period from 1970, while others provided data only for a limited time period. The MDCC collects 13 different meteorological variables: precipitation, 2 m air temperature (i.e. measured at 2 m above ground), daily minimum and maximum 2 m air temperature, 10 m wind speed (i.e. measured at 10 m above ground), 10 m wind direction, cloud cover, water vapour pressure, solar radiation, sunshine duration, relative air humidity, evaporation, and dew point temperature. Of these 13 variables, the following seven are used for EMO-5 (version 1): precipitation; minimum, maximum, and mean air temperatures; wind speed; water vapour pressure; and solar radiation.
Besides the actual in situ meteorological data, the station metadata including latitude, longitude, elevation, and (where available) instrument specifications, are collected. Data collection times depend on the data type (real-time or historical), the data availability, and the chosen data transfer method. In general, real-time data are collected in a 24/7 mode as soon as they become available, whereas historical data are collected mostly on an annual basis. Regarding temporal resolution, for all variables except precipitation, the highest resolution (from 10 min upwards) is preferred as it provides the possibility to aggregate the data to multiple levels, which is useful both in its own right and for the quality control, as it increases its robustness. For precipitation on the other hand, the longest reported totals are used to calculate the daily and 6-hourly totals. Naturally, the number of variables per station varies, as does the completeness of the data record per station.
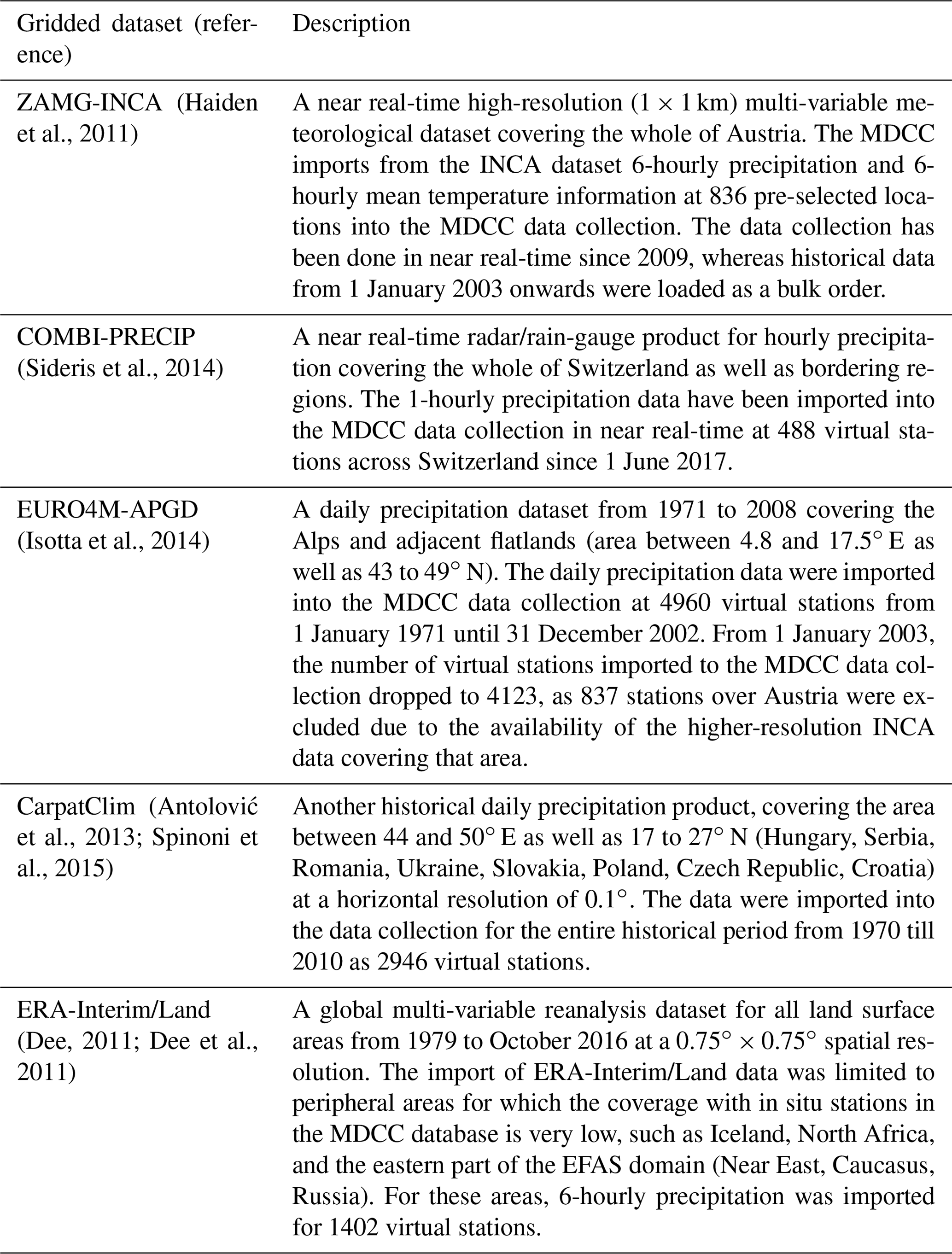
Ingesting information from high-resolution regional observational grids has been shown to improve the quality of the final grids, in particular over areas with complex topography and/or low station density (Gampe and Ludwig, 2017). For this reason, the MDCC also collects data from four high-resolution regional gridded datasets (namely CombiPrecip, ZAMG-INCA, EURO4M-APGD, and CarpatClim) as well as ERA-Interim/Land over areas with low station densities or with complex topography (see Fig. 1). For all regional observational gridded datasets with a spatial resolution higher than the one currently used in the European Flood Awareness System (implying all but CarpatClim), a regular subset of grid points with horizontal resolution of around 10×10 km was selected for integration into the MDCC data collection. The CarpatClim and ERA-Interim/Land datasets were imported at their original resolution. Each selected grid point is treated as a virtual station in the database. In total, 10 632 virtual stations were added to the database for EMO-5. The main characteristics of the five input meteorological data grids underlying EMO-5 are summarized in Table 2.
Table 2Overview of the five gridded meteorological datasets that form the input for EMO-5.
For each of the seven EMO-5 meteorological variables, the location (and hence density) of the input data as well as the record length per station and the number of input stations over time (1990–2019) are shown in Figs. 1 to 3, respectively. As can be expected, the number of available stations for each variable and grid realization is not constant over time or space. Jumps in the data coverage are caused by the integration of historical gridded datasets with fixed start and (partially) end dates, as well as the integration of historical data from data providers, beginning after 1990. This temporally and spatially inhomogeneous availability of stations leads to an inhomogeneous time series of grid-cell values, and therefore the EMO-5 dataset is not optimized for trend (or temporal) analyses, but ideally suited as input data for a wide range of environmental and hydrological model applications.
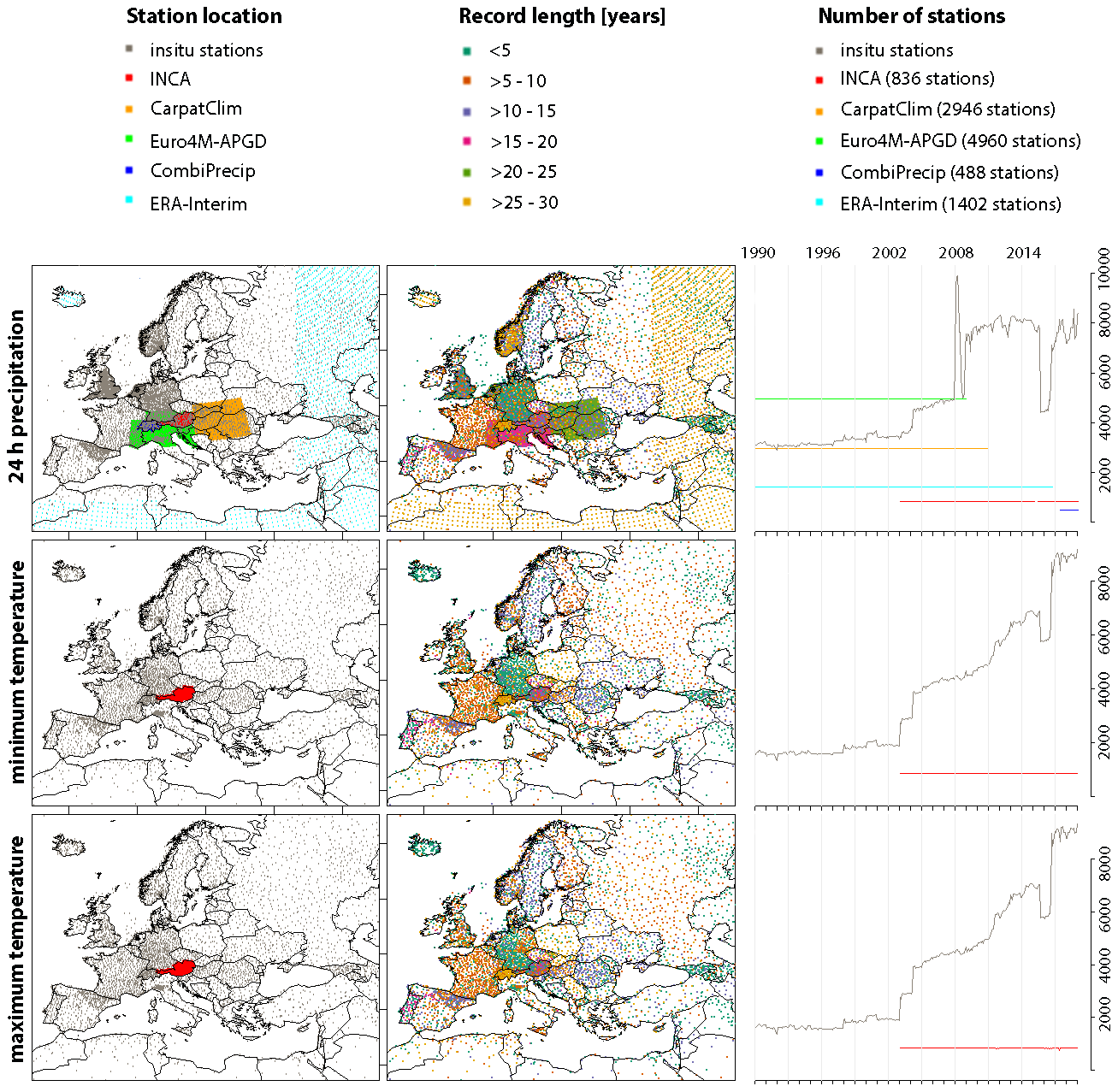
Figure 1Input data for daily EMO-5 precipitation and minimum and maximum temperature grids in terms of station locations, record lengths, and number of stations used.
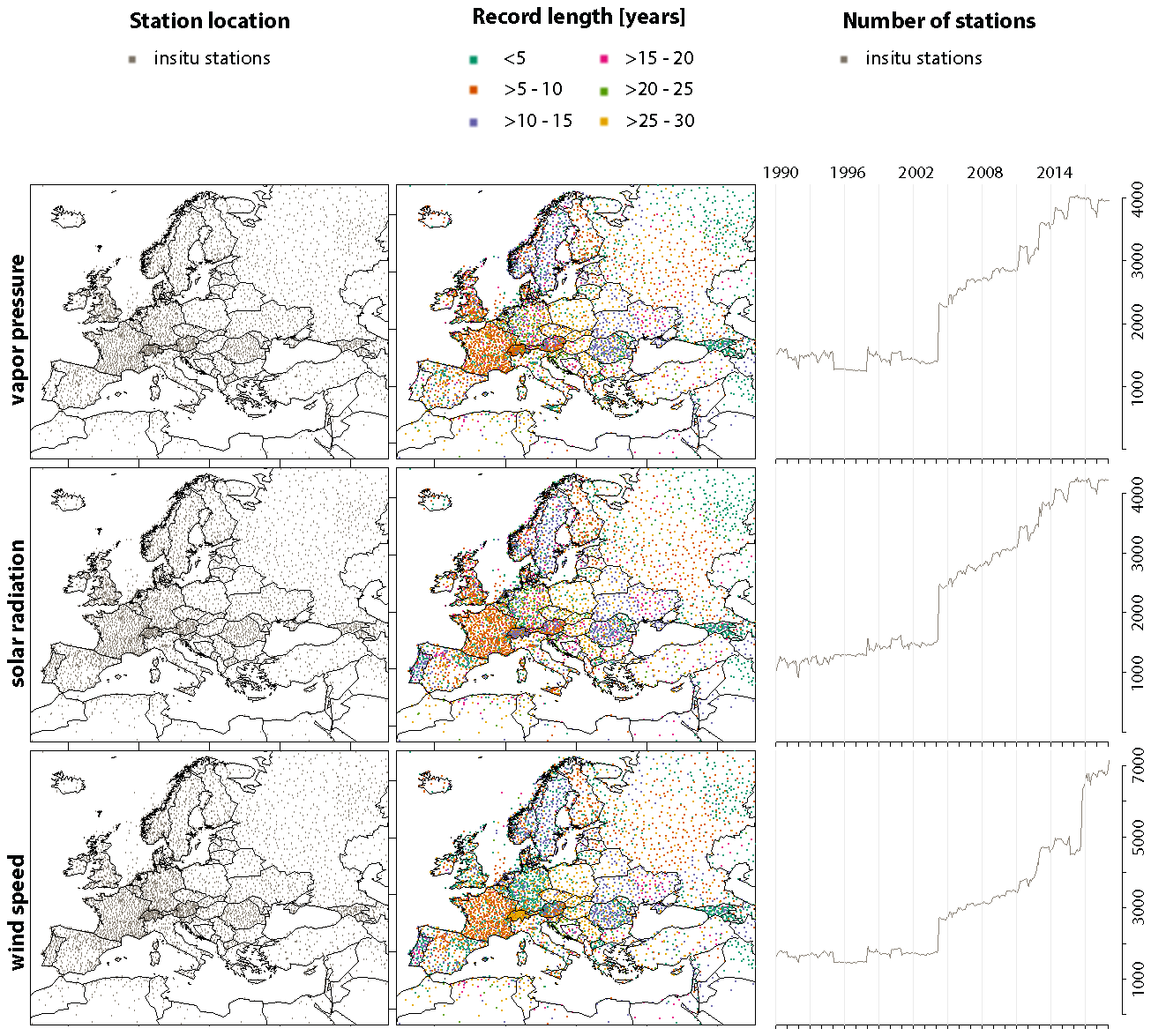
Figure 2Input data for daily EMO-5 vapour pressure, solar radiation, and wind speed grids in terms of station locations, record lengths, and number of stations used.

Figure 3Input data for 6-hourly EMO-5 precipitation and temperature grids in terms of station locations, record lengths, and number of stations used.
All data collected by the MDCC are covered by the EEA-EUMETNET Public Duty License Agreement or the EEA non-EUMETNET Partner License Agreement, which means these data are shareable between the Copernicus services.
3.1 Quality control on input data
All data collected by the MDCC undergo an automatic quality control procedure, irrespective of whether or not they have already been checked by their specific data provider. The quality control is implemented based on five types of data validation rules:
-
Availability: check if value is present and timestamp correct.
-
Monthly statistics: check each value against statistical monthly data.
-
Cross validation: check each value against values from other parameters.
-
Minimum/maximum validation: check each value against minimum/maximum thresholds.
-
Rate of change validation: check the rate of change between two values against maximum thresholds.
The exact specification of the validation rules depends on the variable type as well as on the aggregation level, as summarized in Table 3.
Table 3Specifications for the validation rules as applied to the EMO-5 source data.
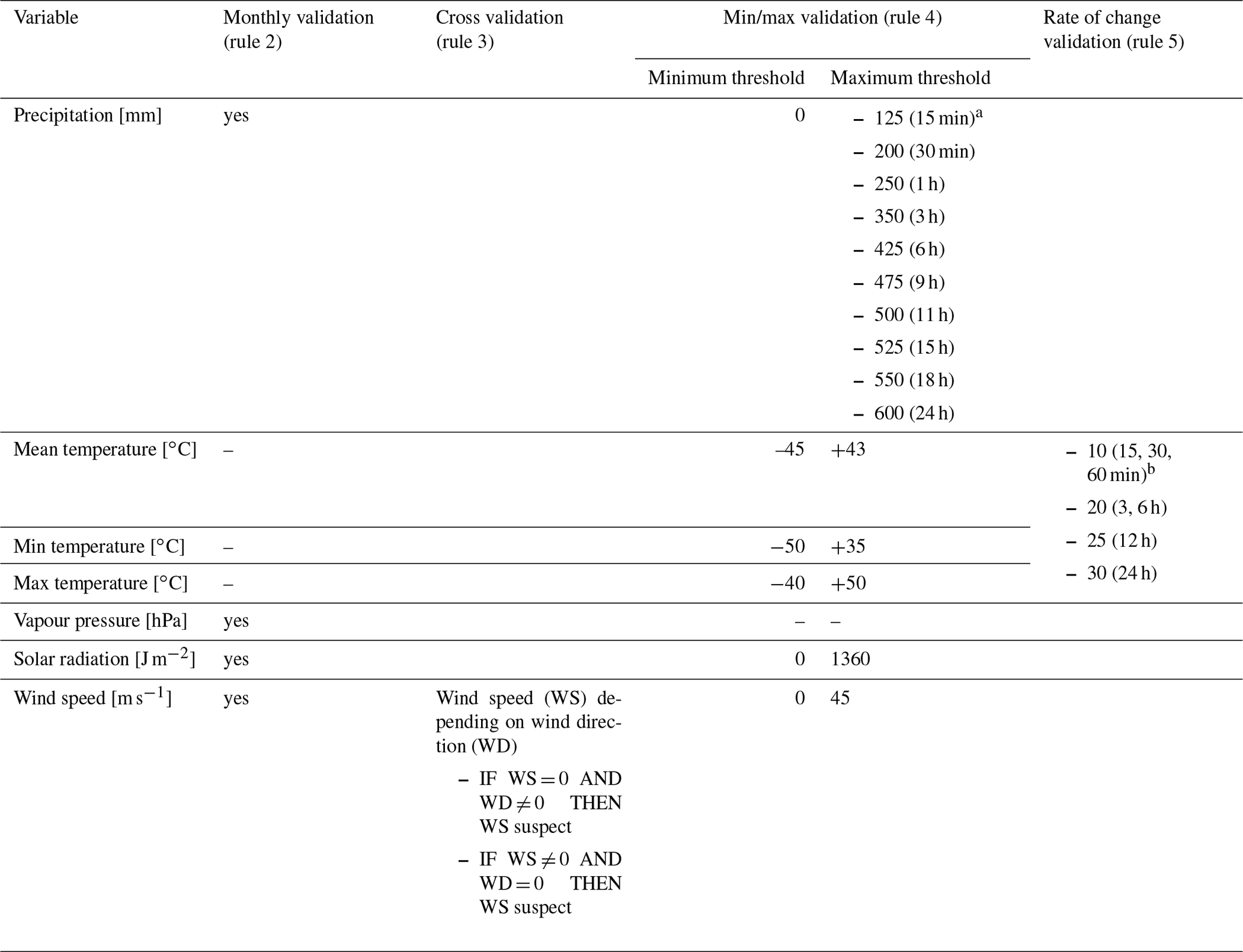
a The maximum threshold for precipitation depends on the aggregation interval. b The maximum change of temperature [K] depending on the observational interval (given in parenthesis).
A data value is flagged as “missing” if the value is not available, and as “suspect” if the timestamp has been corrected (rule 1). Observations are expected at timestamps according to WMO regulations (Manual on Codes, 2013), offsets up to 29 min are corrected. Some countries do not report 6-hourly, 12-hourly, or daily precipitations totals at 00:00, 06:00, 12:00, and 18:00 UTC, but at 03:00, 09:00, 15:00, and 21:00 UTC. These data are shifted by 3 h forward in time to match the expected reporting times. The error due to the time shift is smaller than the error that would occur if those data would be disaggregated to equally distributed hourly totals, and then accumulated to 6-hourly and daily totals afterwards. A value is also flagged as “suspect” if it fails the validation against the monthly statistics (rule 2) or the cross validation (rule 3). For the monthly statistics, the mean monthly minimum and maximum for each station are calculated with the available data and updated with an annual cycle. A data value is flagged as “rejected” if it falls outside of the defined minimum/maximum range (rule 4) or if the threshold for the maximum rate of change between two values has been exceeded (rule 5).
Table 4Overview of the three spatial interpolation schemes that were evaluated for the purposes of EMO-5.
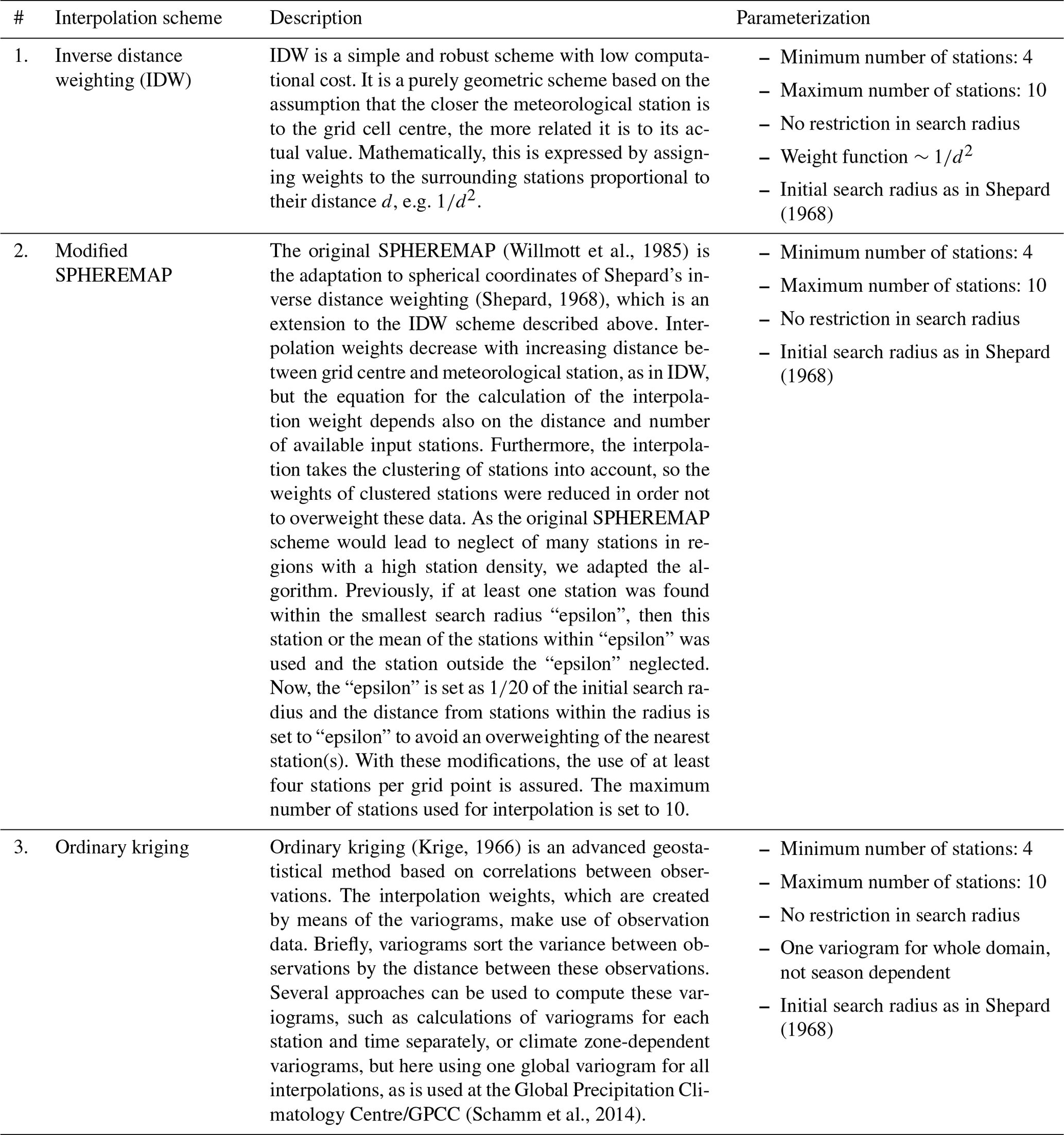
3.2 Choosing an optimal spatial interpolation scheme
As the primary usage of EMO-5 is to support an operational flood forecasting service, the data need to be delivered in a timely manner and at a good level of quality, while the operational framework needs to be robust and easy maintainable. Three spatial interpolation schemes – inverse distance weighting (IDW), modified SPHEREMAP, and ordinary kriging – were compared and evaluated in terms of reliability, specifically regarding uncertainty and computational cost. The three interpolation schemes are briefly described in Table 4.
The quality of each of the interpolation schemes was derived through a leave-one-out cross validation. This means that for each iteration of the interpolated field, one station was left out and then later on compared with its interpolated value. This was done for around 4000 randomly chosen stations evenly distributed over high and low station density areas, and the pairs of interpolated and real observations were used to compute the uncertainty estimates. A similar approach was applied by Hofstra et al. (2008) for the ECA&D dataset. The three tested interpolation schemes used the same setting, as far as possible. These identical settings were as follows: at least four and at maximum ten stations were used to compute the grid cell value and no restriction in the distance to find the nearest four neighbouring stations was applied. The initial search radius to find the nearest stations was calculated as described in Shepard (1968). Further scheme-dependent settings are mentioned in Table 4.
Three different measures of errors were calculated, namely mean error (ME), mean absolute error (MAE), and mean squared error (MSE), as each focuses on different aspects of uncertainties (Willmott and Matsuura, 2005).
Table 5Summary of the error measures for the three interpolation schemes based on the leave-one-out analysis (best values are in bold).
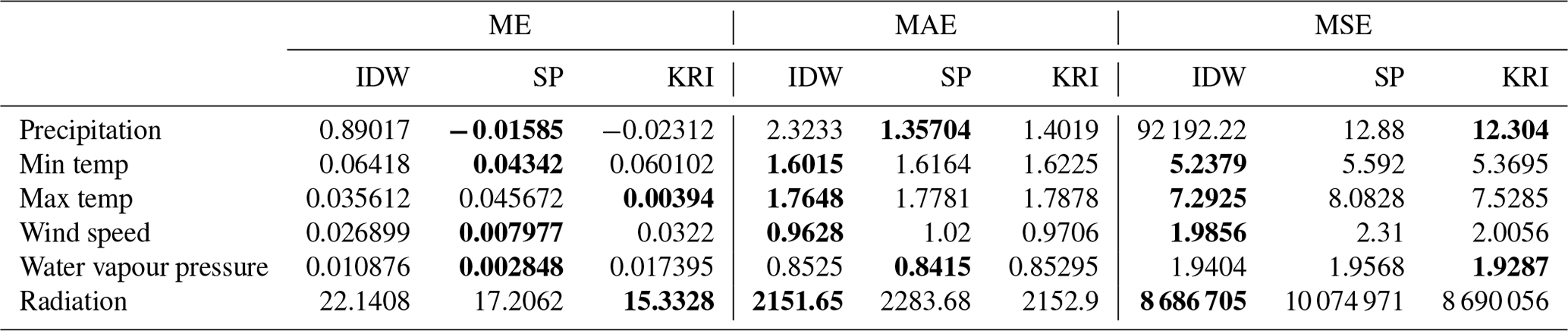
As is shown in Table 5, SPHEREMAP was found to be the best scheme regarding ME, but IDW outperforms both other schemes regarding MAE and MSE. The variance between observed and computed value (MSE) is lowest for IDW for four out of six parameters. Only kriging has lower variances for precipitation and vapour pressure. In addition, IDW has the lowest values for four out of six parameters regarding MAE. Here, SPHEREMAP performs a better interpolation for precipitation and vapour pressure. Regarding computation times, kriging needed around 700 s on average, SPHEREMAP around 550 s, and IDW around 470 s. It should be noted that oceans were not masked to speed up the computations.
In favour of obtaining an operational framework that is maintainable, the decision was taken to choose only one interpolation scheme for all variables. The analysis of the error measures shows that none of the tested interpolation schemes outperforms the others in a consistent manner. However, working within an operational environment, the robustness of the system is crucial, and from that point of view, the automatic variogram fitting in kriging is a stability concern that was also observed by Ntegeka et al. (2013), and this was hence excluded for EMO-5. As SPHEREMAP shows the best performance for the critical parameter precipitation, it was ultimately chosen as the interpolation scheme to generate the grids of EMO-5.
There are many methods available to estimate the uncertainty (i.e. reliability) of the gridded values, such as the leave-one-out approach, ensemble creations, or the technique developed by Yamamoto (2000). Kriging itself provides an error estimation, but this depends only on the spatial distribution of the applied stations and not on the input data; therefore, this error estimation is not applicable here. As the computational time of the grids is highly relevant in order to produce the operational grids as input for emergency management applications, the technique developed by Yamamoto (2000) is used due to its low computational effort. Furthermore, this method takes into account the variability of the surrounding observations, unlike the common kriging uncertainty that only depends on the variogram and the spatial distribution of stations. This approach was also used, for example, for the E-OBS dataset (Haylock et al., 2008). Originally, it was developed for kriging schemes, but was adapted to the used modified SPHEREMAP scheme. Briefly, the method uses the interpolation weights to calculate a weighted variance between the gridded value and the input station data. This is zero if all input data are identical (e.g. areas with zero precipitation) and increases with increasing variance of the input data. This method does not need any additional information besides grid value, station values, and the interpolation weights.
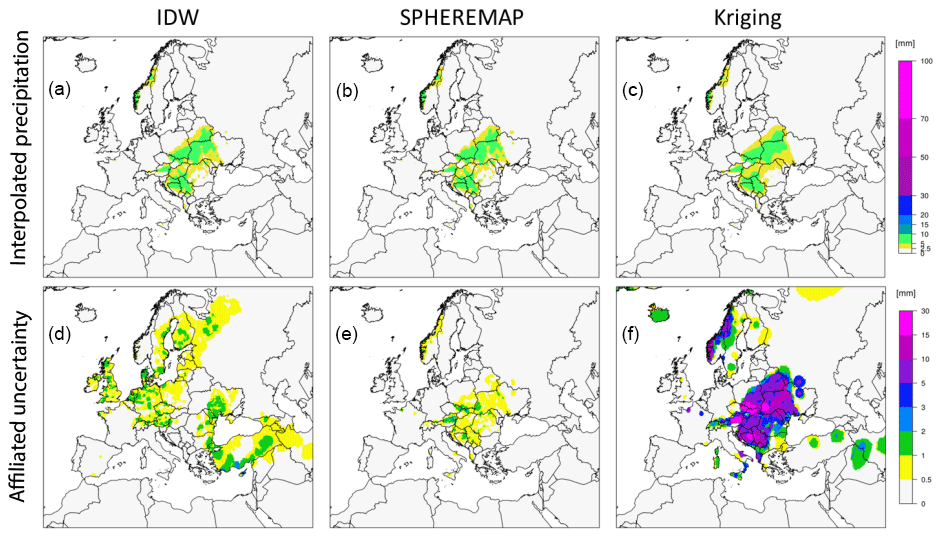
Figure 4Gridded daily precipitation data (a–c) and the corresponding uncertainty fields (d–f) for 15 May 2014 as an example for IDW (a, d), SPHEREMAP (b, e), and Kriging (c, f).
Uncertainty fields were calculated and analysed for each grid realization and interpolation method. Figure 4 shows the gridded daily precipitation data and the corresponding uncertainty fields (for 15 May 2014) as an example for IDW (left), SPHEREMAP (middle), and kriging (right).
The overall patterns for precipitation look very similar for the three interpolation approaches (Fig. 4, top row), with the only main difference being that kriging produces smoother patterns compared to IDW and SPHEREMAP. Comparing their affiliated uncertainty patterns (Fig. 4, bottom row), SPHEREMAP shows the lowest uncertainty, and unlike the other two interpolation schemes, the uncertainty signal of SPHEREMAP is geographically constrained to the regions with precipitation. Kriging shows extremely high gridding uncertainties, which we assume are due to a not well-fitted variogram.
The specific date (15 May 2014) is just one example that we selected from the comparison study of the interpolation methods, but it could have been any other day, since the results were generally the same, namely (1) kriging generated smoother variable fields than SPHEREMAP and IDW; and (2) SPHEREMAP showed overall the lowest and kriging the largest uncertainty. Further, the interpolation performance (meaning the stability of the algorithm in a near real-time setting) was considered, as the timely availability of the gridded meteorological data must be assured in order to guarantee the smooth operation of the flood forecasting system. Unlike for IDW or SPHEREMAP, this is an issue for kriging as it would require an automatic fitting of the variogram, which might go wrong in a near real-time operation. Based on the results of the uncertainty analysis and consideration of the interpolation performance, SPHEREMAP was chosen as the interpolation algorithm for EMO-5.
3.3 Grid creation
Moving from a large collection of in situ measurements to a European high-resolution, (sub-)daily, multi-variable meteorological dataset involves several processes and decisions, which are described in the following subsections.
3.3.1 Selection of stations
The number of stations used during gridding varies per variable and time step. This is due to the fact that for each grid creation, the stations in the EFAS meteorological database are filtered based on a number of criteria. A station passes the filtering process for a particular variable and time step if it fulfils all of the following criteria, in order to be used as input for gridding:
-
The data coverage of aggregated precipitation readings is 100 % for the entire period of the time step.
-
The data coverage for all remaining variables, such as temperature, wind speed, etc. is 95 % for daily data and 83 % for 6-hourly mean temperature.
-
The recorded values for that timestamp passed the data quality check (see Sect. 3.1), meaning that they were flagged as “good” or “suspect” (data with quality “rejected” are excluded from gridding).
For precipitation, not all station records that fulfil the above criteria are used in the interpolation. This is due to the fact that over time, there was an increasing number of stations that were reported redundantly by different data providers (e.g. SYNOP and national data), albeit sometimes with slightly different values or slightly different coordinates. Hence, they appeared as multiple stations in the database, while they were in fact one station with multiple records. Not removing these duplicate records would lead to multiple counting of the same station during the interpolation, with the result of overweighting of those stations in the grids and less reliable area mean grid-cell values. To correct this and to assure a gradual change between stations during the interpolation, redundant records were identified through a vicinity check. Records, i.e. stations, within a vicinity of 500 m to each other were identified and merged into one record, i.e. virtual station. The coordinates of the virtual station were taken from the first station of this cluster, while the value was computed as the average of all duplicate records. This reduced the total number of records used per grid realization by an average of 3.4 %. Figure 1 shows the number of stations used during the grid creation.
Another filter that was implemented for precipitation at the level of the interpolation was a distance filter for ERA-Interim/Land data. The reason for this is that ERA-Interim/Land was used with the intention of filling the spatial gaps where no observations were available. However, with time, the station density in those areas increased and therefore the need to integrate ERA-Interim/Land stations decreased. For this reason, all ERA-Interim/Land values that were less than 100 km away from a valid in situ station measurement were disregarded. Figure 1 shows how many of the 1402 existing virtual ERA-Interim stations were actually used for gridding.
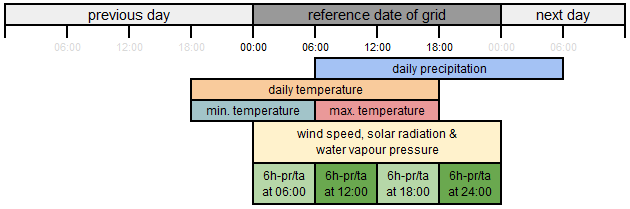
3.3.2 Aggregation or reference period
Figure 5 shows the aggregation (i.e. reference period) for the different variables. Daily precipitation is accumulated from the current day at 06:00:01 until the next day at 06:00:00 (“current day” is the reference date of grid). In accordance with the WMO guidelines (World Meteorological Organization, 2019), the minimum nighttime temperature measured between 18:00:01 on the previous day until 06:00:00 on the current day is taken as the minimum temperature of the current day and the maximum daytime temperature measured between 06:00:01 and 18:00:00 is used as the maximum temperature of the current day. All the other daily parameters such as wind speed, solar radiation, and vapour pressure are averaged over 00:00:01 of the current day to 00:00:00 of the next day. For 6-hourly temperature, this depends on the data provider: if only 6-hourly instantaneous temperature readings are delivered, then those are used; otherwise temperature is averaged for 00:00:01–06:00:00, 06:00:01–12:00:00, 12:00:01–18:00:00, and 18:00:01–24:00 (see Sect. 3.3.5). The same time intervals are used to aggregate 6-hourly precipitation reported at 06:00, 12:00, 18:00, and 24:00, respectively. Note that the timestamp of the EMO-5 grids refers to the end of the reference period, meaning that, for instance, the daily precipitation of 22 February 2021 covers the time period between 21 February 2021, 06:00:01, and 22 February 2021, 06:00:00.
3.3.3 Land–sea mask
A land–sea mask is used to exclude sea surfaces from the gridding procedure, as EMO-5 originates from the need for near real-time information on observed meteorological conditions over land surface areas. The land–sea mask is not used to define stations to be excluded from gridding.
3.3.4 Implications of altitude for temperature and water vapour pressure
In areas with strong orographic changes, neighbouring stations are likely to be at various altitudes, and hence the representativeness of their measurement for neighbouring areas is limited depending on the altitude change in the surrounding area (due to adiabatic processes). If station values were blindly used during the interpolation, an error would be introduced. This can be easily avoided by considering elevation information while interpolating. As SPHEREMAP does not take any auxiliary information into account, all recorded temperature and water vapour pressure values are brought to sea level before interpolation. This is done based on altitude information obtained from a 1×1 km digital elevation model (Arnal et al., 2019), through accounting for the adiabatic change of 0.006 Kelvin per height metre for temperature and 0.00025 hPa per height meter for water vapour pressure. The interpolation runs at sea level and afterwards, temperature and water vapour pressure information are brought back to the mean elevation of the respective 5×5 km grid cell by taking the parameter-specific correction factors into account.
3.3.5 Mean temperature
Where 6-hourly temperature averages are available, these have been used both for the 6-hourly dataset and for the daily averages, aggregating the four 6-hourly observations. However, for many stations we did not have sub-daily temperature observations, particularly for the data from the 1990s. There are also many stations in the dataset that have frequent observations between 06:00 and 18:00, enough for the 6-hourly daytime, but not for the nighttime period. This is particularly the case for observational data received from the MARS Meteorological Database of the European Commission's Joint Research Centre (Toreti et al., 2019). If data from other providers are not available at any station suffering from this issue, we have estimated the missing 6-hourly temperature based on the daily minimum and maximum temperatures. This was done based on the method described as the “Sin(14R-1)” method in Chow and Levermore (2007), with some small modifications as follows.
For all stations where minimum and maximum temperatures are available, we fitted sinusoidal curves after estimating at what time of day the extremes most likely occurred. Similar to Chow and Levermore (2007), we assumed that the minima occur 1 h before sunrise, a value we computed with the function “getSunlightTimes” of the “suncalc” package (Thieurmel and Elmarhraoui, 2019) in the R programming language. However, we restricted the earliest time of the minimum temperature to occur not before 04:00 UTC in summer, with a correction for longitude. The latest time for the minimum was set at 10:00 UTC in winter, also corrected for longitude. While the Sin(14R-1) method assumes that the maximum temperature occurs at 14:00, we let the peak time range between 14:00 and 16:00 UTC, where it will be closer to 16:00 when sunset is late.
As some of the stations with missing 6-hourly data have stations with high-resolution observations nearby, we only included the estimated values for stations where the distance to a high-resolution neighbour is at least 10 km. This value was chosen by analysing the mean square error for simulated temperatures at stations where we have 6-hourly averages and a variogram analysis of the 6-hourly data series. Requiring a mean square error of around 5.5 K2 roughly corresponds to a distance of about 10 km in the variogram. Beyond this distance, it is likely that the errors from simulation are smaller than the spatial interpolation error. The number of extra stations is highest for the period 1990–1995, with around 500–600 stations with estimated 6-hourly temperatures. This can be compared with the approximately 1000 stations with 6-hourly temperature, as seen in Fig. 3. The number is then reduced to approximately 50–150 stations for most of the remaining period, but increases above 200 again for 2019 (mainly because of stations in Iceland).
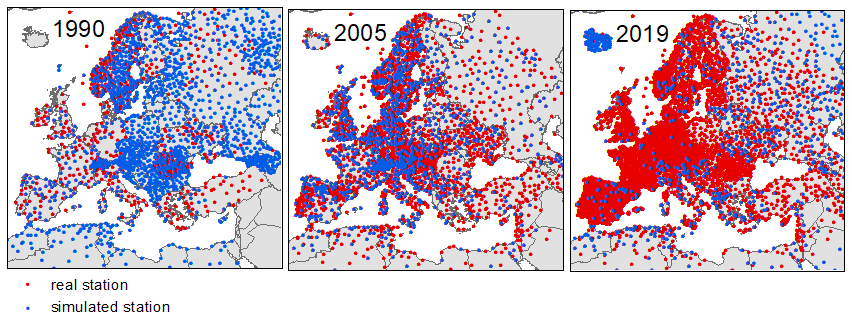
Figure 6Coverage of existing and simulated stations used for the 6-hourly temperature fields for 1990, 2005, and 2019.
Figure 6 shows the available stations for 3 different years (i.e. 1990, 2005, and 2019) for the 00:00 and 12:00 observations. The red dots show where we have 6-hourly temperature data, whereas the blue dots show where we have been able to add simulated 6-hourly temperature data based on the minimum – maximum observations. We can see that the simulated data cover much of Europe in 1990, whereas this drops in later years. For the most recent years, most of the extra stations were added in North-East Russia, some around the Mediterranean, and a large number in Iceland, where we have access to many more stations with minimum – maximum observations than 6-hourly data. For 1990, we can also see a rather big difference between the data from nighttime (top) and daytime (bottom), where we have 6-hourly data from many more stations during the day than during the night.
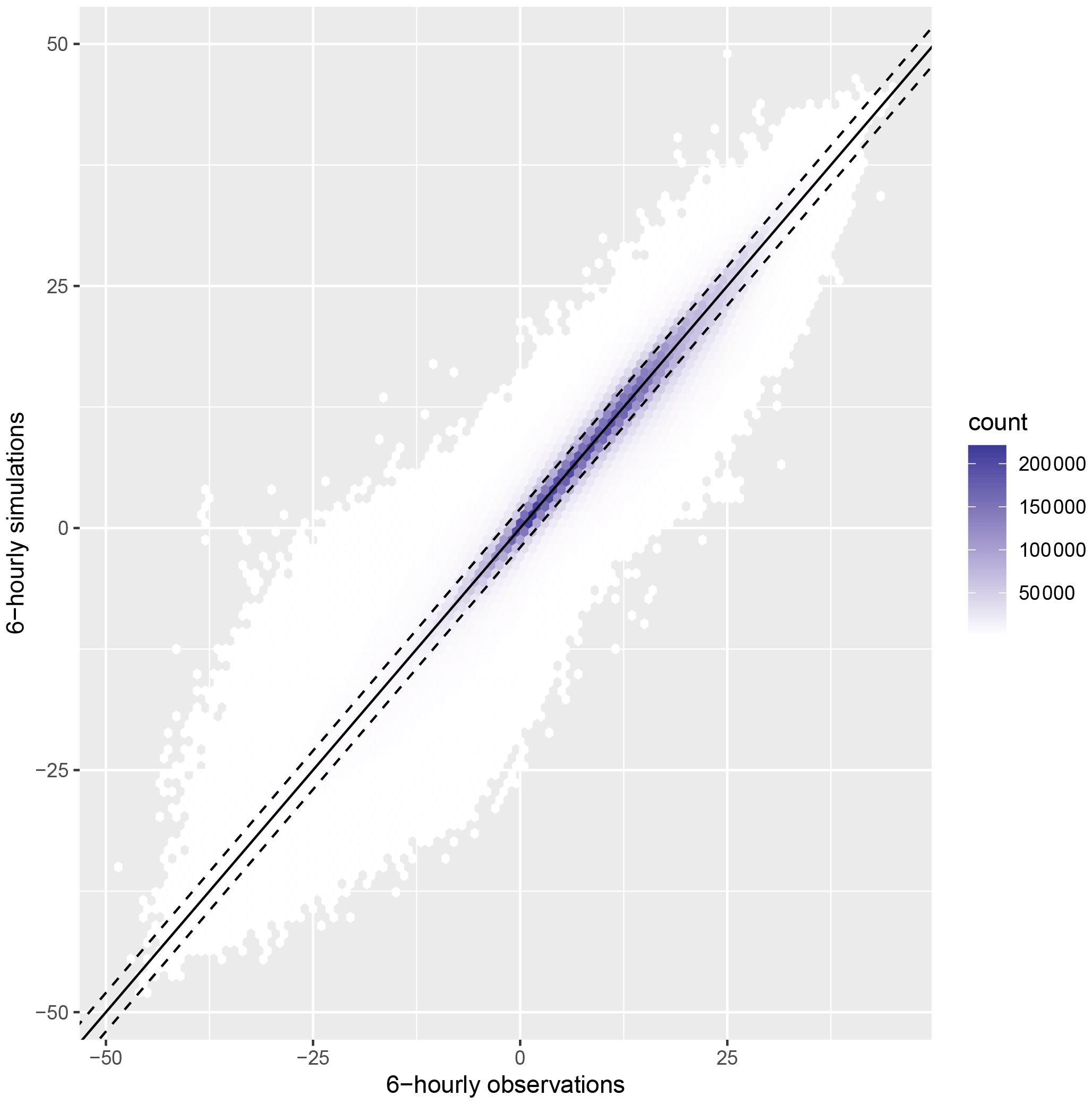
The goodness of this approximation was analysed in a simple cross validation procedure. We picked around 800 stations that already had 6-hourly observations from the start of the period (1990). For these stations, we compared the 6-hourly observations with the simulated 6-hourly dataset based on maximum and minimum temperatures. A hexbin plot is shown in Fig. 7, where darker colours indicate a high number of observed and simulated temperature values. The line shows where simulations are equal to the observations, whereas the dashed lines indicate where the simulated values are 2∘ higher or lower than the observations. We can see that a large majority of the simulated values are within 2∘ of the observations, although there are cases with larger deviations.
The correlation between observations and simulations ranges from 0.91–0.99. The simulated values are on average unbiased, with mean and median around 0.1∘ below the observations. However, when looking at the simulated temperatures for different times of the day, it can be noted that the method has a tendency to underestimate the average night temperature and overestimate the afternoon temperature. The mean and median of the underestimation is 1.8∘ for the night temperature and the overestimation 1.5∘ for the afternoon, i.e. the simulated 6 h periods are slightly more extreme than the observations. The root mean squared error (RMSE) for each station ranged from 1 to 4∘, with mean and median RMSE of 2.2∘. The difference was seen as acceptable for our purposes, and is quite similar to what was observed by e.g. Luedeling (2018).
3.3.6 Historical batch creation versus near real-time creation
The amount of station data available for gridding differs if these are created in near real-time or once in a batch for a given historical time period, with more stations available for the latter. This is due to the latency in data availability from climatological stations, which do not report in real-time mode but are included in historical data deliveries. The earliest station data are available and transferred into the MDCC database about 0.5 h after the observational time, whereas all near real-time reporting stations, including corrections, are acquired within 5 d after the observational time. To account for the incremental filling of the database in the near real-time grid production, at every grid production cycle, grids of day −6 (i.e. 6 d ago) to day −2 are produced (where “today” is defined as “day −0”) and overwrite those previously produced. In this way, the latest grids always contain the highest amount of information available at any given moment.
This incremental gridding strategy is not necessary if one would like to generate grids for a historical period, as the gridding is executed once in a batch process considering all the information available in the database at that given moment. The recreation of grids is performed according to need. Once a year, all grids of the previous year are reproduced to account for the delivery of historical data from the data providers. The recreation of the whole time series is much rarer, and only happens after larger changes, for example after the change of the interpolation algorithm or the resolution (spatial or temporal), or the integration of larger amounts of historical data.
The EMO-5 (version 1) dataset was produced for the time period from 1990 to 2019. In order to have a dataset that is consistent over time, it was reproduced in a batch process for the entire time period using the modified SPHEREMAP algorithm and also for both temporal resolutions (6-hourly and daily).
The quality of the EMO-5 precipitation data is evaluated in this section through (1) examination of the interpolation uncertainty, (2) comparison with two regional high-resolution datasets (i.e. seNorge2 and seNorge2018), and (3) analysis of 15 heavy precipitation events.
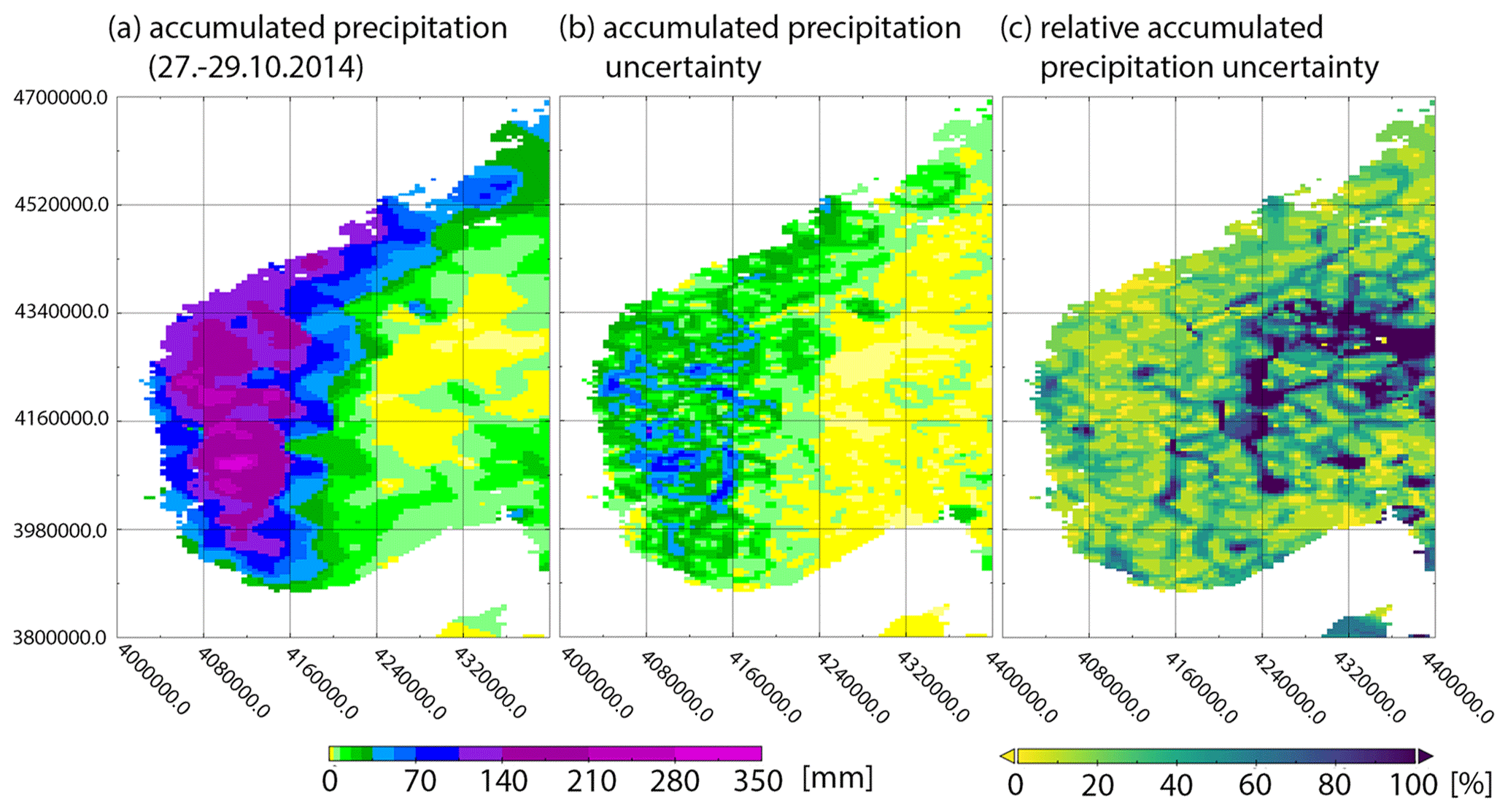
Figure 8Example of interpolated precipitation totals and associated uncertainty for extreme event no. 3 in Sect. 4.3. (a) Accumulated precipitation totals from 27–29 October 2014 (3 d), (b) accumulated uncertainty of the interpolated precipitation totals, and (c) the percentage of the accumulated uncertainty in relation to the accumulated precipitation totals.
4.1 Interpolation Uncertainty
As interpolated grid values represent a “best guess”, it is of paramount importance to provide information on reliability. EMO-5 therefore contains, for each variable and time step, two fields – the interpolated value and an interpolation uncertainty, created with the methods described in Sect. 3.2.
An example of the associated interpolation uncertainty for the interpolated precipitation totals for extreme event number 3 (see Sect. 4.3 below) is shown in Fig. 8. The highest accumulated precipitation totals are around 300 mm and the estimated accumulated interpolation uncertainty is up to 100 mm. In the largest parts of the extreme event area, the estimated accumulated precipitation uncertainty is around 25 mm, which is less than 20 % of the accumulated precipitation total. Obviously, the highest estimated uncertainties are not located at the highest totals, but rather at the slopes of the highest rainfall areas. It is worth mentioning that the estimated interpolation uncertainty in the precipitation-free areas is roughly zero.
4.2 Comparison against a regional high-resolution grid
We compared EMO-5 with two Norwegian datasets in order to assess its quality. One is the dataset “seNorge2” (Lussana et al., 2018) and the other is the subsequent dataset “seNorge2018” (https://doi.org/10.5281/zenodo.2082320, Lussana, 2018). The area covered by these two datasets consists of the Norwegian mainland and a strip of the neighbouring countries Sweden, Finland, and Russia (Lussana, 2018).
The covered area is very challenging for raster data generation, with large differences in orography, strong precipitation, and large small-scale precipitation differences (e.g. due to the orography). Both seNorge datasets are based on station data from the Norwegian Climate Database (https://frost.met.no, last access: 15 September 2021) and outside Norway on the European Climate Assessment dataset (Klein Tank et al., 2002). For the seNorge2 dataset the raw data are used, while for the seNorge2018 dataset an undercatch correction is applied, which has a large impact, especially in the winter months when snow is detected. The data are on a regular grid with 1 km grid spacing for the periods 1957–2015 for seNorge2 and 1957–2017 for seNorge2018. Both datasets have daily values from 06:00 to 06:00 UTC. An extra interpolation based on nearest neighbour is used to identify the precipitation days per grid point, or otherwise to set the grid values to zero. The interpolation procedure for the precipitation values for both datasets is based on an optimal interpolation procedure with a background field. The seNorge2 dataset uses the station data as a background field, while seNorge2018 uses the monthly values of the ERA-Interim analysis with 2.5∘ resolution. For the actual interpolation, a cascade of decreasing scales is used and the station height is taken into account. The differences are mainly seen in mountainous regions with sparse station coverage. Since the optimal interpolation procedure requires a normal distribution, a Box–Cox transformation is applied to the seNorge2018 dataset (Lussana et al., 2019).
For comparison with EMO-5, the period 1990–2015, which is common to all datasets, is used. The day definition (from 06:00 to 06:00 UTC) is the same for all three datasets. To obtain the same spatial projection, the seNorge datasets were reshaped to the 5 km resolution of EMO-5. For this purpose, the bilinear interpolation method was applied, which uses a weighted average of the four nearest grid points. The study area of this analysis can be seen in Fig. 9.
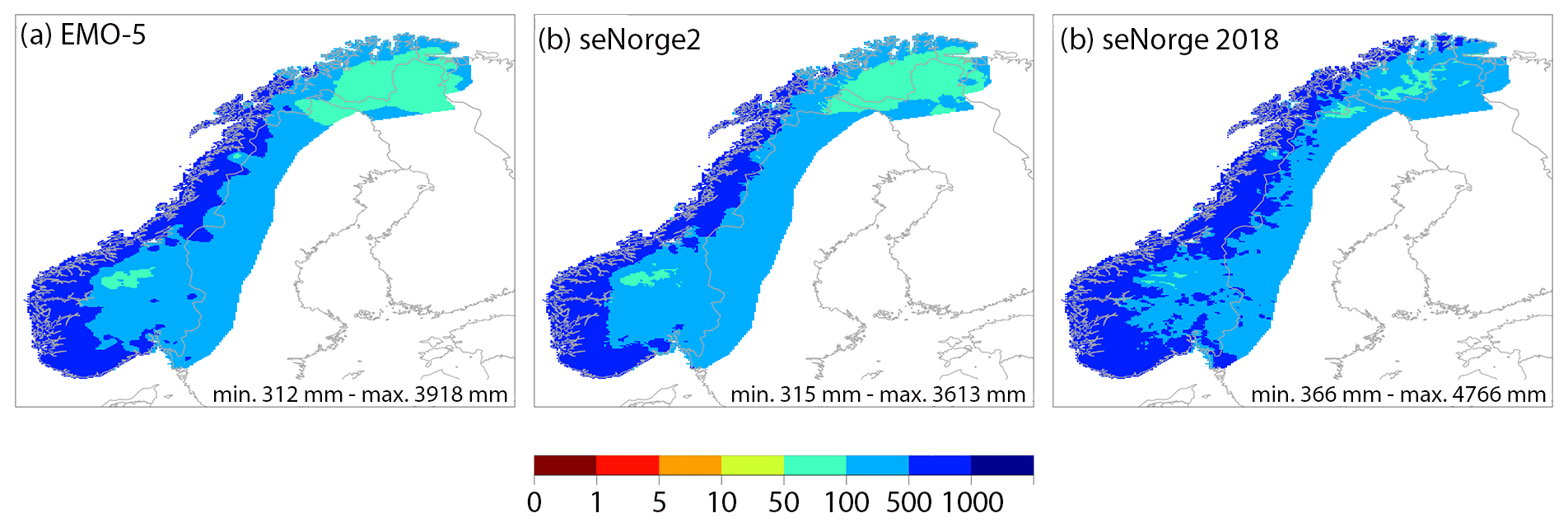
Figure 9Mean annual precipitation [mm] for the (a) EMO-5, (b) seNorge2, and (c) seNorge2018 datasets for the joint period 1990–2015. The seNorge data are bi-linearly interpolated to the coarser EMO-5 resolution. EMO-5 was cropped to the same spatial extent as the seNorge datasets.
The differences in annual precipitation, as well as the differences in the distributions of seasonal precipitation, and the distributions of extremes represented by the precipitation indices adopted from the CCl/WCRP/JCOMM Expert Team on Climate Change Detection and Indices (2001) (ETCCDI) set by Peterson et al. (2001, Appendix A) are presented below.
As can be seen in Fig. 9, the data have a similar spatial structure, with seNorge2018 showing heavier precipitation. This is more clearly visible in the direct comparison in Fig. 10.
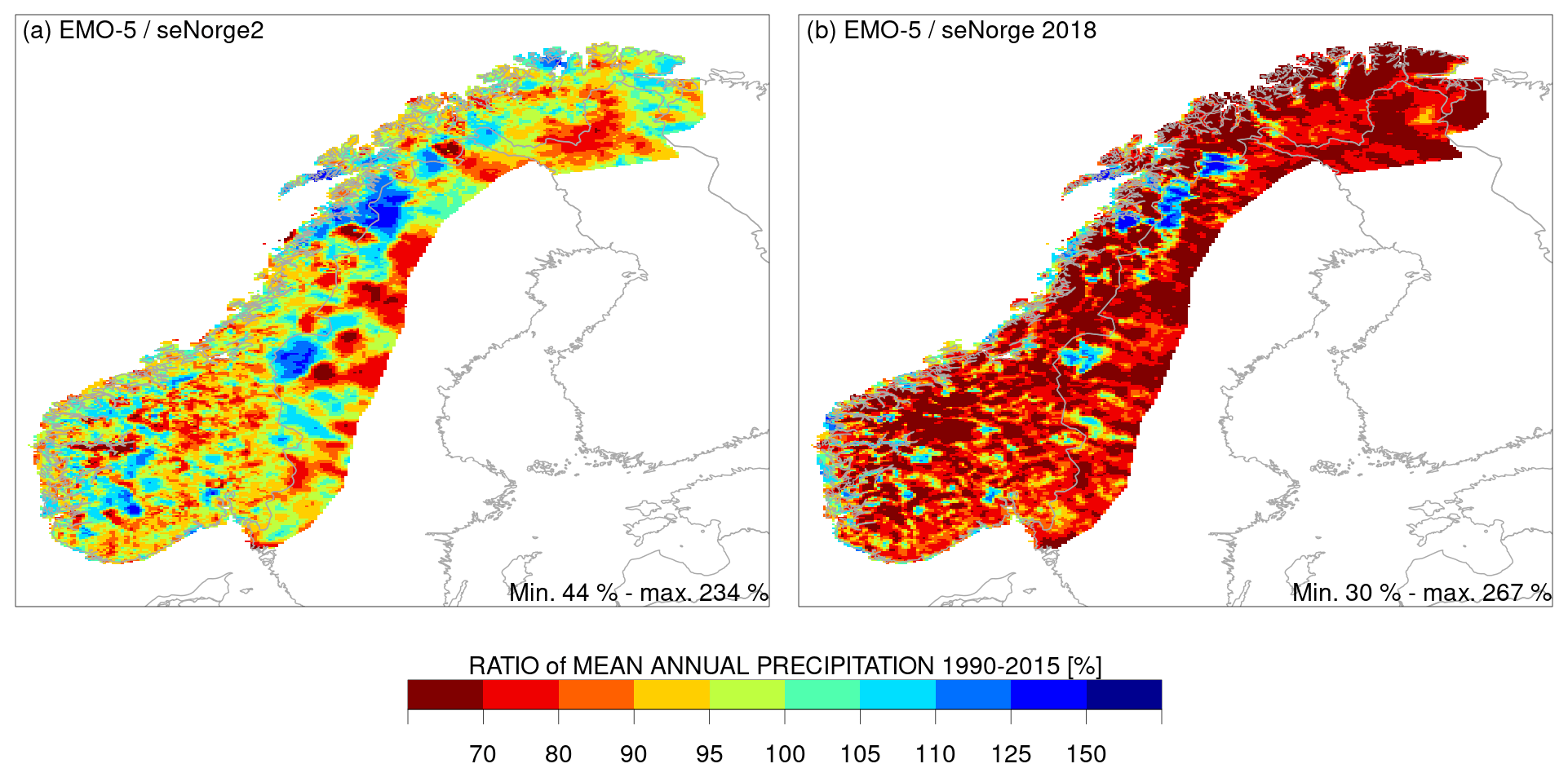
Figure 10Based on Fig. 8 data. Ratio of seNorge2 (a) and seNorge2018 (b) to EMO-5 [%].
Table 6Overview of EMO-5, seNorge2, and seNorge2018 datasets based on the common period 1990–2015 [mm]. The order of calculation is first to calculate the parameters (mean, maximum) for the grids, followed by the mean over the resulting grid.

Figure 10 shows that EMO-5 and seNorge2 have very similar magnitudes of values. The differences between the two datasets are very small scale, especially in the southwest and northeast. This could indicate orographic effects, as the seNorge interpolation methods include elevation as a parameter. Large structures can be found in the centre of the area, which could indicate fundamental data differences. In comparison with seNorge2018, the high precipitation values of seNorge2 are again evident . This is unsurprising, due to the undercatch correction in this dataset. However, the presence of two conspicuous blue-coloured areas shows that EMO-5 is characterized by higher precipitation than seNorge2018. The seasonal differences are listed in Table 6 (differences in the values shown in Table 6 and Fig. 10 are due to a slightly different procedure to derive the maximum).
The average annual mean precipitation of EMO-5 is 2 % higher compared to the one of seNorge2, and 17 % lower compared to seNorge2018. In the average maximum precipitation per grid, EMO-5 shows 106 % of the seNorge2 precipitation and 86 % of the seNorge2018 precipitation. EMO-5 is thus substantially closer to seNorge2 in mean grid precipitation than the two seNorge datasets are to each other (see Table 6).

Figure 11Quantile plot of (a) seasonal precipitation, where each point represents the sum of a grid value over 3 months and (b) extreme value indices (ETCCDI) values, but these correspond to the maximum of the entire time series. Each plot shows seNorge2 (•) and seNorge2018 (⧫) values on the x axis and EMO-5 values on the y axis in mm. For a better visual overview, the highest 0.01 % of the data have not been shown.
The comparison of seasonal precipitation in Fig. 11a shows that the individual months are very different. There are very large differences, especially with respect to intense precipitation. These are distinctly higher in EMO-5 than in the seNorge datasets, an exception being autumn. In this case, the distributions of seNorge2018 and EMO-5 agree very well. Large EMO-5 data values are rare, only 1523 values (or 0.06 %) are above 1500 mm and 212 values ( %) are above 2000 mm. The reason is probably data errors, as these values can be located in a few small locations in the study area. For the benefit of visual comparability, the highest 0.01 % of the values are omitted in Fig. 11.
The probability distribution of the smaller values, on the other hand, shows very good agreement with seNorge2, while seNorge2018 shows larger values, especially in spring and winter. The comparison of the two seNorge datasets shows significantly higher values for seNorge2018, especially in spring and winter. In summer, the seNorge datasets are very similar. The latter finding can be explained very well by the fact that the undercatch correction has less impact in summer. The results look more diverse when considering the extremes on a daily basis (see Fig. 11b). The maximum extreme value indices are calculated over the entire time period for each grid point. Again, as in Fig. 11a, the highest 0.01 % of the respective values are not shown. This concerns, for example, the high values of the consecutive dry days (CDD) – up to 1400 d without precipitation – in the EMO-5 dataset. These unrealistic values can be limited to a small region in the northeast. The high values for the consecutive wet days (CWD) can be attributed to two points in the centre and one in the south of the study area. Otherwise, the extra interpolation for the yes–no decision for precipitation days in the seNorge datasets could have an influence on the distributions of the CDD and CWD indices. The simple daily intensity index (SDII) shows similar distributions to the totals in Fig. 11a. SeNorge2 and EMO-5 agree very well, while seNorge2018 shows much higher values. The number of precipitation days above 10 mm and above 20 mm (not shown) shows a good agreement between seNorge2 and EMO-5, similar to SDII, with a slightly better agreement at r10. The maximum 5 d totals show a strikingly different picture. Here, EMO-5 agrees very well with seNorge2018, while seNorge2 shows significantly lower values.
In summary, the agreement between the seNorge2 and EMO-5 datasets is very good, despite the very different interpolation methods. The influence of the undercatch correction used in the seNorge2018 dataset is substantially larger. In particular, the lower precipitation values seem to match very well in seNorge2 and EMO-5. This is also evident in the extreme value indices based on low values, especially r10. The ratio of the annual values clearly shows the different representation of the orographic structure due to the orography-dependent interpolation in the seNorge datasets. The large differences in the extremes with very few values are mainly due to isolated data errors in the EMO-5 data. However, the differences in the isolated grid points do not appear to be caused by single extremely high daily values, as these would otherwise show in indices such as maximum consecutive 5-day precipitation (RX5day). Instead, smaller but longer-lasting errors seem to cause these discrepancies. These then affect statistics that use all values over a period of time, such as the seasonal totals or indices like CWD and CDD.
4.3 Heavy precipitation events
As well as the timeliness of EMO-5, also the capability to capture heavy precipitation events is of great importance for EFAS. In this section, we evaluate semi-quantitatively the ability of EMO-5 to capture heavy precipitation events. We first randomly selected 15 flood events that were caused by heavy precipitation from http://www.floodlist.com (last access: 27 June 2022). Affiliated precipitation information was then extracted and verified through visual inspection of the respective EMO-5 image.

Figure 12Semi-qualitative evaluation of 15 high-intensity precipitation events through comparing information reported on FloodList (on the left) with the footage of the 6-hourly and daily precipitation grids (sums and maximum; base map from © OpenStreetMap contributors 2020. Distributed under the Open Data Commons Open Database License (ODbL) v1.0).
Figure 12 shows for each of the 15 selected flood events the related precipitation information as published on Floodlist (on the left-hand side) and as seen in the EMO-5 dataset (all four maps). The information regarding the observed precipitation as published on Floodlist ranges from a qualitative indication, such as “heavy precipitation between those dates” (events 2, 3, 4, 11, and 14) to precise quantitative statements such as “x amount of precipitation between those dates” (events 1, 5–10, 12, 13, and 15). When the original data source of the observed precipitation was mentioned on Floodlist, then it is also cited here. For all the other cases, the value should just be used as an indication.
Regarding EMO-5, we present here the sum of daily and 6-hourly precipitation maps covering the dates as specified on Floodlist, as well as the maximum daily and 6-hourly precipitation values within that time frame. In order to cover a full calendar day, it was necessary to sum up two daily precipitation maps. This is due to the fact that the aggregation or reference period of the daily precipitation maps is not in line with a calendar day, but covers the period from 06:00:01 of the previous day until 06:00:00 of the current day (see Sect. 3.3.2). Hence, there is always one more daily map than the number of calendar days to cover. This was not necessary for the 6-hourly maps, as four 6-hourly maps cover precisely one calendar day. This also explains why in Fig. 12 the sum of daily precipitation is generally higher than the sum of the 6-hourly precipitation. This should not be a problem, as the aim of this comparison is to evaluate the performance of daily and 6-hourly precipitation against the reported information, and not to compare the 6-hourly with the daily totals.
For 13 out of the 15 selected events, EMO-5 shows greater precipitation amounts over the event duration, ranging between 119 mm (event 5) and 350 mm (event 9), with 270 and 255 mm being the maximum observed precipitation values within a daily and a 6-hourly period, respectively. The only event clearly missed is event 6, where hardly any precipitation was captured by EMO-5. This event was caused by a cloud burst, and hence was a very local extreme event. It is likely that it was missed as no in situ station exists directly at the specific location in EMO-5.
For the nine events with concrete specifications on precipitation amounts, EMO-5 captures the precipitation amounts of three events (Events 5, 8, and 15) in accordance with the media reports, overestimates the amount for one event (event 9), and underestimates the reported amounts for five events (Events 6, 7, 10, 12, and 13) . Three out of the five underestimated precipitation events (events 6, 10, and 12) were also caused by cloud bursts, and hence were short and high-intensity events that are difficult to reproduce in a temporally aggregated and spatially interpolated dataset, especially if the full amount of precipitation was not captured by any in situ station, due to the positioning of stations.
EMO-5 (Thiemig et al., 2020) is a Copernicus product and as such free and open to everyone. It can be accessed through the Data Catalogue of the European Commission's Joint Research Centre at https://doi.org/10.2905/0BD84BE4-CEC8-4180-97A6-8B3ADAAC4D26.
The repository contains a CF-1.6-compliant NetCDF stack files for each variable, as well as a README file with detailed product specifications, which are briefly summarized in Table 7.
EMO-5 is a European high-resolution (5×5 km), (sub-)daily, multi-variable, multi-decadal meteorological dataset based on quality-controlled observations coming from almost 30 000 stations (18 964 in situ and 10 632 virtual stations) across Europe, and is produced in near real-time. The EMO-5 (version 1) covers precipitation, temperature (minimum and maximum), wind speed, solar radiation, and water vapour pressure – all at a daily resolution – and, in addition, 6-hourly data for precipitation and mean temperature. Version 1 covers the time period from 1990 onwards and is freely available. In this paper, we have provided insight into the source data, the applied methods, and the quality assessment of EMO-5 version 1 (the latter just for precipitation).
EMO-5 grids are produced by means of a modified SPHEREMAP algorithm, which is a geometric scheme taking the distance, clustering, and gradient into account. The decision to use this method was made after a comparison of three interpolation schemes. An algorithm was developed to identify stations provided independently by different data providers and replace them by a merged station.
Each EMO-5 grid realization is accompanied by a corresponding estimate of the interpolation uncertainty, which is based on the approach of Yamamoto (2000). This takes the difference between the gridded value and the station data as well as the interpolation weights into account. Therefore, the estimated uncertainty at each grid cell differs from day to day. The highest uncertainties of the gridded data are at steep gradients between regions with high and low precipitation totals, reflecting the uncertainty in the estimation of the spatial extension of such an event.
The quality of the precipitation product was evaluated through comparison against regional high-resolution datasets (seNorge2 and seNorge2018) over Norway as well as against 15 media reports of extreme precipitation events that caused flooding across Europe.
The comparison of EMO-5 (version 1) against two regional high-resolution datasets over Norway showed that EMO-5 and seNorge2 are more similar to each other than the Norwegian datasets are. The good agreement is despite their very different interpolation methods, and is particularly evident for lower precipitation values and mean annual means, while differences can be detected in the seasonality and extreme values. The latter issue is suspected to be caused by longer-lasting data errors of very few isolated stations used in the EMO-5 dataset. The reason for seNorge2018 being substantially different to both EMO-5 and seNorge2 is likely due to the undercatch correction that is applied only to seNorge2018. It is recommended to broaden this comparison to other high-resolution datasets before drawing general conclusions. However, the comparison done here has shown that EMO-5 can be comparable in terms of quality to a regional high-resolution dataset.
The semi-quantitative evaluation of EMO-5's capacity to capture heavy precipitation events has shown that in 80 % of cases, EMO-5 captures the events qualitatively, meaning that the EMO-5 grids covering the event show large amounts of precipitation, which is particularly important for applications such as flood modelling that rely heavily on forcing data to be able to capture these events. As expected for gridded datasets, even if EMO-5 mostly captures heavy precipitation events, it tends to underestimate the observed precipitation amount at stations. This is not a surprising finding, as especially convective events are often short and local. This makes it very difficult to capture the maximum precipitation amount of these events, unless an in situ station is in the direct location of the event and captures it.
The presented EMO-5 (version 1) is the result of an operational real-time service, which utilizes the maximum amount of valid information available for every grid realization. This is very different to climate datasets, which need to be of sufficient length, consistency, and continuity to determine climate variability and climate change. EMO-5 favours the maximum amount of available information over long-term product homogeneity and is therefore not suitable for climate studies, i.e. trend analysis. However, EMO-5 is suitable for environmental applications which do not have this homogeneity requirement, but value a dataset that uses the maximum amount of information available for each grid realization.
Further, there might be some reservations towards using the EMO-5 minimum nighttime and maximum daytime temperature as the daily minimum and maximum temperatures, respectively. To recall, the daily minimum and maximum temperatures in EMO-5 are calculated following the WMO guideline (WMO-No. 306), which assumes the minimum temperature to occur between 18:00 and 06:00, and the maximum temperature between 06:00 and 18:00. However, particularly in the winter half-season and at higher latitudes, the daily temperature maxima or minima sometimes occur outside these windows. For this reason, some datasets, such as E-OBS, calculate the daily minimum and maximum temperature over the full 24 h period. Lavaysse et al. (2018), who investigated the minimum and maximum temperatures of EMO-5 (referred to as LISFLOOD in their paper) and E-OBS with regards to their suitability in the frame of temperature extremes in Europe (heat- and cold waves), came to the conclusion that the two observational datasets showed only minor differences in heat- and cold wave occurrences and intensity, which, according to Lavaysse, is probably due to the good agreement in representing both the minimum and maximum temperature.
Looking ahead, as part of the operational Copernicus EMS, the number of stations (historical and near real-time) that are used for gridding in EMO-5 will be continuously increased, through adding new data providers and the integration of new, high-resolution regional observational grids, where available. In addition, to improve the current quality control framework, new data validation rules, such as spatial comparison with neighbouring stations or additional statistical checks, will be implemented. Finally, as it is foreseen to increase the spatial resolution of EFAS from the current 5 km grid to a 1 arcmin grid (approximately equal to 1.8 km at the Equator), EMO-5 will also increase the spatial resolution in its next version.
Lastly, the CEMS Meteorological Data Collection Centre publishes an annual report on the CEMS meteorological data collection every year, with updated information on, for example, data providers and provision, database, post-processing, improvements to the dataflow, and post-processing and gap analysis. All reports can be found on the EFAS website, while last years report is referenced here: Rehfeldt et al. (2021).
MZ, ARS, KR, JPW, CK, and DP are the core team of the CEMS Meteorological Data Collection Centre (MDCC), which is managed overall by CS. Their work is the foundation for the creation of EMO-5, as they run the daily operation of the historical and near real-time data collection, the design and operation of the data validation, and the data gridding method. GNG supports the operation of this service at all levels and created the actual EMO-5 dataset. KR, CK, ARS, and MZ implemented and evaluated the interpolation method used for EMO-5, which MZ has documented in Sects. 3.2 and 4.1. PS is the project coordinator of the flood forecast and monitoring component of CEMS and is supported by VT, who have as such guided the CEMS Meteorological Data Collection Centre from the start, including all its evolutions since, and sparked the idea of EMO-5. ER single-handedly led the comparison of EMO-5 against the seNorge datasets, as she has documented in Sect. 4.2. JOS selected, implemented, and documented the methodology for the computation of the mean temperature (Sect. 3.3.5) and provided scientific support on the entire methodology. VT was in charge of the overall coordination of the article, carried out the analysis in Sect. 4.3, and is main writer of the paper, with valuable support on technical details from all co-authors.
The contact author has declared that neither they nor their co-authors have any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Our sincere gratitude goes to all the data providers who shared and continue to share their (station) data with the CEMS Meteorological Data Collection Centre (CEMS MDCC). A full list can be found on the EFAS website under https://www.efas.eu/en/share-your-data-efas (last access: 27 June 2022). The CEMS MDCC is funded by the Copernicus Programme, and runs as part of the Copernicus Emergency Management Service (CEMS). We would furthermore like to thank the Copernicus in situ cross coordination action implemented by the European Environmental Agency for its support in setting up in situ data licenses for meteorological data, and lastly Niall McCormick (JRC) for English proofreading and Christel Prudhomme (ECMWF), Carlo Buontempo (C3S), and Andrea Toreti (JRC MARS) for reviewing.
This paper was edited by Qingxiang Li and reviewed by two anonymous referees.
Antolović, I., Mihajlović, V., Rančić, D., Mihić, D., and Djurdjević, V.: Digital Climate Atlas of the Carpathian Region, Adv. Sci. Res., 10, 107–111, https://doi.org/10.5194/asr-10-107-2013, 2013.
Arnal, L., Asp, S.-S., Baugh, C., de Roo, A., Disperati, J., Dottori, F., Garcia, R., Garcia-Padilla, M., Gelati, E., Gomes, G., Kalas, M., Krzeminski, B., Latini, M., Lorini, V., Mazzetti, C., Mikulickova, M., Muraro, D., Prudhomme, C., Rauthe-Schöch, A., Rehfeldt, K., Salamon, P., Schweim, C., Skoien, J.O., Smith, P., Sprokkereef, E., Thiemig, V., Wetterhall, F., and Ziese, M.: EFAS upgrade for the extended model domain – technical documentation, EUR 29323 EN, Publications Office of the European Union, Luxembourg, ISBN 978-92-79-92881-9, https://doi.org/10.2760/806324, JRC111610, 2019.
Cammalleri, C., Arias-Muñoz, C., Barbosa, P., de Jager, A., Magni, D., Masante, D., Mazzeschi, M., McCormick, N., Naumann, G., Spinoni, J., and Vogt, J.: A revision of the Combined Drought Indicator (CDI) used in the European Drought Observatory (EDO), Nat. Hazards Earth Syst. Sci., 21, 481–495, https://doi.org/10.5194/nhess-21-481-2021, 2021.
CCl/WCRP/JCOMM Expert Team on Climate Change Detection and Indices: Climate Change Indices – Definitions of the 27 core indices, http://etccdi.pacificclimate.org/list_27_indices.shtml, last access: 8 March 2021.
Chow, D. H. C. and Levermore, G. J.: New algorithm for generating hourly temperature values using daily maximum, minimum and average values from climate models, Building Services Engineering Research and Technology, 28, 237–248, https://doi.org/10.1177/0143624407078642, 2007.
Cornes, R. C., van der Schrier, G., van den Besselaar, E. J. M., and Jones, P. D.: An Ensemble Version of the E-OBS Temperature and Precipitation Data Sets, J. Geophys. Res.-Atmos., 123, 9391–9409, https://doi.org/10.1029/2017JD028200, 2018.
Dee, D.: ERA-Interim, ECMWF, https://www.ecmwf.int/en/forecasts/datasets/reanalysis-datasets/era-interim (last access: 17 February 2021), 2011.
Dee, D. P., Uppala, S. M., Simmons, A. J., Berrisford, P., Poli, P., Kobayashi, S., Andrae, U., Balmaseda, M. A., Balsamo, G., Bauer, P., Bechtold, P., Beljaars, A. C. M., Berg, L. van de, Bidlot, J., Bormann, N., Delsol, C., Dragani, R., Fuentes, M., Geer, A. J., Haimberger, L., Healy, S. B., Hersbach, H., Hólm, E. V., Isaksen, L., Kållberg, P., Köhler, M., Matricardi, M., McNally, A. P., Monge-Sanz, B. M., Morcrette, J.-J., Park, B.-K., Peubey, C., Rosnay, P. de, Tavolato, C., Thépaut, J.-N., and Vitart, F.: The ERA-Interim reanalysis: configuration and performance of the data assimilation system, Q. J. Roy. Meteorol. Soc., 137, 553–597, https://doi.org/10.1002/qj.828, 2011.
Gampe, D. and Ludwig, R.: Evaluation of Gridded Precipitation Data Products for Hydrological Applications in Complex Topography, Hydrology, 4, 53, https://doi.org/10.3390/hydrology4040053, 2017.
Haiden, T., Kann, A., Wittmann, C., Pistotnik, G., Bica, B., and Gruber, C.: The Integrated Nowcasting through Comprehensive Analysis (INCA) System and Its Validation over the Eastern Alpine Region, Weather Forecast., 26, 166–183, https://doi.org/10.1175/2010WAF2222451.1, 2011.
Haylock, M. R., Hofstra, N., Tank, A. M. G. K., Klok, E. J., Jones, P. D., and New, M.: A European daily high-resolution gridded data set of surface temperature and precipitation for 1950–2006, J. Geophys. Res.-Atmos., 113, https://doi.org/10.1029/2008JD010201, 2008.
Hofstra, N., Haylock, M., New, M., Jones, P., and Frei, C.: Comparison of six methods for the interpolation of daily, European climate data, J. Geophys. Res.-Atmos., 113, D21110, https://doi.org/10.1029/2008JD010100, 2008.
Isotta, F. A., Frei, C., Weilguni, V., Tadić, M. P., Lassègues, P., Rudolf, B., Pavan, V., Cacciamani, C., Antolini, G., Ratto, S. M., Munari, M., Micheletti, S., Bonati, V., Lussana, C., Ronchi, C., Panettieri, E., Marigo, G., and Vertačnik, G.: The climate of daily precipitation in the Alps: development and analysis of a high-resolution grid data set from pan-Alpine rain-gauge data, Int. J. Climatol., 34, 1657–1675, https://doi.org/10.1002/joc.3794, 2014.
Klein Tank, A. M., Wijngaard, J. B., Können, G. P., Böhm, R., Demarée, G., Gocheva, A., Mileta, M., Pashiardis, S., Hejkrlik, L., Kern-Hansen, C., Heino, R., Bessemoulin, P., Müller-Westermeier, G., Tzanakou, M., Szalai, S., Pálsdóttir, T., Fitzgerald, D., Rubin, S., Capaldo, M., Maugeri, M., Leitass, A., Bukantis, A., Aberfeld, R., van Engelen, A. F., Forland, E., Mietus, M., Coelho, F., Mares, C., Razuvaev, V., Nieplova, E., Cegnar, T., Antonio López, J., Dahlström, B., Moberg, A., Kirchhofer, W., Ceylan, A., Pachaliuk, O., Alexander, L. V., and Petrovic, P.: Daily data set of 20th-century surface air temperature and precipitation series for the European Climate Assessment, Int. J. Climatol., 22, 1441–1453, 2002.
Krige, D. G.: Two-dimensional weighted moving average trend surfaces for ore-evaluation, J. S. Afr. I. Min. Metall., 66, 13–38, 1966.
Lavaysse, C., Cammalleri, C., Dosio, A., van der Schrier, G., Toreti, A., and Vogt, J.: Towards a monitoring system of temperature extremes in Europe, Nat. Hazards Earth Syst. Sci., 18, 91–104, https://doi.org/10.5194/nhess-18-91-2018, 2018.
Luedeling, E.: Interpolating hourly temperatures for computing agroclimatic metrics, Int. J. Biometeorol., 62, 1799–1807, https://doi.org/10.1007/s00484-018-1582-7, 2018.
Lussana, C.: seNorge_2018 daily total precipitation amount 1957–2017, the Norwegian Meteorological Institute, Zenodo, https://doi.org/10.5281/zenodo.2082320, 2018.
Lussana, C., Saloranta, T., Skaugen, T., Magnusson, J., Tveito, O. E., and Andersen, J.: seNorge2 daily precipitation, an observational gridded dataset over Norway from 1957 to the present day, Earth Syst. Sci. Data, 10, 235–249, https://doi.org/10.5194/essd-10-235-2018, 2018.
Lussana, C., Tveito, O. E., Dobler, A., and Tunheim, K.: seNorge_2018, daily precipitation, and temperature datasets over Norway, Earth Syst. Sci. Data, 11, 1531–1551, https://doi.org/10.5194/essd-11-1531-2019, 2019.
Manual on Codes: Volume 1, ISBN 978-92-63-10306-2, 2013.
Ntegeka, V., Salamon, P., Gomes, G., Sint, H., Lorini, V., Zambrano-Bigiarini, M., and Thielen, J.: EFAS-Meteo: A European daily high-resolution gridded meteorological data set for 1990–2011, JRC Technical Reports, EUR26408, https://doi.org/10.2788/51262, 2013.
Peterson, T., Folland, C., Gruza, G., Hogg, W., Mokssit, A., and Plummer, N.: Report on the activities of the working group on climate change detection and related rapporteurs, World Meteorological Organization, Geneva, Collection(s) and Series: WMO/TD- No. 1071, WCDMP- No. 47, 2001.
Quintana-Seguí, P., Moigne, P. L., Durand, Y., Martin, E., Habets, F., Baillon, M., Canellas, C., Franchisteguy, L., and Morel, S.: Analysis of Near-Surface Atmospheric Variables: Validation of the SAFRAN Analysis over France, J. Appl. Meteorol. Climatol., 47, 92–107, https://doi.org/10.1175/2007JAMC1636.1, 2008.
Quintana-Seguí, P., Peral, C., Turco, M., Llasat, M. C., and Martin, E.: Meteorological Analysis Systems in North-East Spain: Validation of SAFRAN and SPAN, J. Environ. Inform., 27, 116–130, 2017.
Rehfeldt, K., Schirmeister, Z., Pichon, D., Rauthe-Schöch, A., Schweim, C., Walawender, J., Ziese M., Gomes, G., Thiemig, V., and Salamon, P.: The CEMS Meteorological Data Collection Centre – Annual report 2020, European Commission, JRC126414, 2021.
San-Miguel-Ayanz, J., Durrant, T., Boca, R., Libertà, G., Branco, A., de Rigo, D., Ferrari, D., Maianti, P., Artés Vivancos, T., Oom, D., Pfeiffer, H., Nuijten, D., Leray, T., and Moffat, A. J.: Forest Fires in Europe, Middle East and North Africa 2018, EUR 29856 EN, ISBN 978-92-76-11234-1, https://doi.org/10.2760/1128, 2019.
Schamm, K., Ziese, M., Becker, A., Finger, P., Meyer-Christoffer, A., Schneider, U., Schröder, M., and Stender, P.: Global gridded precipitation over land: a description of the new GPCC First Guess Daily product, Earth Syst. Sci. Data, 6, 49–60, https://doi.org/10.5194/essd-6-49-2014, 2014.
Serrano-Notivoli, R., Beguería, S., Saz, M. Á., Longares, L. A., and de Luis, M.: SPREAD: a high-resolution daily gridded precipitation dataset for Spain – an extreme events frequency and intensity overview, Earth Syst. Sci. Data, 9, 721–738, https://doi.org/10.5194/essd-9-721-2017, 2017.
Shepard, D. B.: A two-dimensional interpolation function for irregularly-spaced data, Proceedings of the 1968 23rd ACM national conference, https://doi.org/10.1145/800186.810616, 1968.
Sideris, I. V., Gabella, M., Erdin, R., and Germann, U.: Real-time radar–rain-gauge merging using spatio-temporal co-kriging with external drift in the alpine terrain of Switzerland, Q. J. Roy. Meteor. Soc., 140, 1097–1111, https://doi.org/10.1002/qj.2188, 2014.
Spinoni, J., Szalai, S., Szentimrey, T., Lakatos, M., Bihari, Z., Nagy, A., Németh, Á., Kovács, T., Mihic, D., Dacic, M., Petrovic, P., Kržič, A., Hiebl, J., Auer, I., Milkovic, J., Štepánek, P., Zahradnícek, P., Kilar, P., Limanowka, D., Pyrc, R., Cheval, S., Birsan, M.-V., Dumitrescu, A., Deak, G., Matei, M., Antolovic, I., Nejedlík, P., Štastný, P., Kajaba, P., Bochnícek, O., Galo, D., Mikulová, K., Nabyvanets, Y., Skrynyk, O., Krakovska, S., Gnatiuk, N., Tolasz, R., Antofie, T., and Vogt, J.: Climate of the Carpathian Region in the period 1961–2010: climatologies and trends of 10 variables, Int. J. Climatol., 35, 1322–1341, https://doi.org/10.1002/joc.4059, 2015.
Spinoni, J., Naumann, G., Vogt, J., and Barbosa, P.: Meteorological Droughts in Europe: Events and Impacts – Past Trends and Future Projections, Publications Office of the European Union., https://doi.org/10.2788/450449, 2016.
Thiemig, V., Ramos Gomes, G. N., Skøien, J. O., Ziese, M., Rauthe-Schöch, A., Rustemeier, E., Rehfeldt, K., Walawender, J., Kolbe, C., Pichon, D., Schweim, C., and Salamon, P.: EMO-5: A high-resolution multi-variable gridded meteorological data set for Europe (1990–2019), European Commission, Joint Research Centre (JRC) [data set], https://doi.org/10.2905/0BD84BE4-CEC8-4180-97A6-8B3ADAAC4D26, 2020.
Thieurmel, B. and Elmarhraoui, A.: R-package suncalc: Compute Sun Position, Sunlight Phases, Moon Position and Lunar Phase, https://CRAN.R-project.org/package=suncalc, last access: 12 February 2021, 2019.
Toreti, A., Maiorano, A., De Sanctis, G., Webber, H., Ruane, A. C., Fumagalli, D., Ceglar, A., Niemeyer, S., and Zampieri, M.: Using Reanalysis in Crop Monitoring and Forecasting Systems, Agric. Syst., 168, 144–153, https://doi.org/10.1016/j.agsy.2018.07.001, 2019.
Tramblay, Y., Feki, H., Quintana-Seguí, P., and Guijarro, J. A.: The SAFRAN daily gridded precipitation product in Tunisia (1979–2015), Int. J. Climatol., 39, 5830–5838, https://doi.org/10.1002/joc.6181, 2019.
Vidal, J.-P., Martin, E., Franchistéguy, L., Baillon, M., and Soubeyroux, J.-M.: A 50-year high-resolution atmospheric reanalysis over France with the Safran system, Int. J. Climatol., 30, 1627–1644, https://doi.org/10.1002/joc.2003, 2010.
Willmott, C. J. and Matsuura, K.: Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance, Climate Res., 30, 79–82, https://doi.org/10.3354/cr030079, 2005.
Willmott, C., Rowe, C., and Philpot, W.: Small-Scale Climate Maps: A Sensitivity Analysis of Some Common Assumptions Associated with Grid-Point Interpolation and Contouring, American Cartographer, 12, 5–16, https://doi.org/10.1559/152304085783914686, 1985.
World Meteorological Organization (WMO): Manual on Codes Volume I.1 Annex II to the WMO Technical Regulations Part A – Alphanumeric Codes, (WMO No.306, Part I.1 Part A), 2011 edition, updated in 2019, 480 pp., ISBN 978-92-63-10306-2, Geneva, Switzerland, 2019.
Yamamoto, J. K.: An Alternative Measure of the Reliability of Ordinary Kriging Estimates, Math. Geol., 32, 489–509, https://doi.org/10.1023/A:1007577916868, 2000.