the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 01 Jun 2026
| 01 Jun 2026
OneDZ: a global detrital zircon database and implications for constructing giant geoscience database
Rong Chai
Jianghai Yang
Weiwei Xue
Yingdi Pan
Taiyang Li
Can Fang
Anlin Ma
Hu Huang
Qianqian Guo
Wentao Yang
Lisha Hu
Liang Qi
Guohui Chen
Gaoyuan Sun
Shijie Zhang
Tao Deng
Kuizhou Li
Jiaopeng Sun
Biao Gao
The amount of detrital zircon U-Pb geochronology data and Lu-Hf isotopic data has doubled in the past two decades with the continuous improvement of analytical methods, and has developed into the most closely integrated research field in earth science with big data methods. However, how to effectively construct giant databases in geoscience has become a challenge. Here, we present OneDZ, a global comprehensive detrital zircon U-Pb geochronology and Lu-Hf isotope database, which includes diverse samples with data source, location, stratigraphy, depositional age, and various elemental and isotopic information. OneDZ collected corresponding regions, stratigraphic and lithological information to facilitate quick access for users. Comparing with current zircon databases, until now, OneDZ complies 2 550 738 grains of detrital zircon U-Pb and 297 527 grains of detrital zircon Lu-Hf records from 275 971 publications. Furthermore, the construction of OneDZ leverages artificial intelligence (AI) and programming scripts and offers insights into managing large-scale unstructured data in geosciences. This paper further discusses the perspective of applying big data methods in the research of zircon-related areas. This database exemplifies the power of big data in Earth sciences, providing a platform for investigating zircon data in deep time. It serves as a springboard for research, offering new insights in understanding Earth's past, present, and future. The database (Li et al., 2026) is freely available via Zenodo at https://doi.org/10.5281/zenodo.19690702.
- Article
(29838 KB) - Full-text XML
-
Supplement
(1441 KB) - BibTeX
- EndNote




The advent of high-precision U-Pb geochronology has revolutionized our understanding of Earth history. Isotope-dilution thermal-ionization mass spectrometry (ID-TIMS; Krogh, 1973) remains the benchmark for highest accuracy and precision (≤ 0.1 %), but its destructive, time-intensive protocol limits statistical throughput for large detrital suites. Laser-ablation inductively-coupled-plasma mass spectrometry (LA-ICP-MS) and secondary-ion mass spectrometry (SIMS) now provide rapid, in-situ analyses with 1 %–3 % precision, which is ideal for analyzing the hundreds to thousands of concordant ages required for robust detrital zircon provenance and maximum depositional-age studies (e.g. Compston et al., 1984; Fedo et al., 2003; Jackson et al., 2004; Gehrels, 2014; Schaltegger et al., 2015; Horstwood et al., 2016). Together, these complementary techniques extend high-precision geochronology from single crystals to entire sedimentary systems. Zircon, a robust and ubiquitous mineral found throughout the continental crust, serves as a reliable recorder of geological events due to its high closure temperature and resistance to weathering and metamorphism (Pupin, 1980). Primary zircons from magmatic or metamorphic rocks are commonly fragmented, transported, and ultimately deposited as detrital zircons.
Typical analyses of detrital zircons include U-Pb and Lu-Hf isotopic systems. Chemical formula of detrital zircon can be represented as [ZrSiO4]. The ionic radius of [Zr4+] is 0.87 Å, which can be easily replaced by [U4+] and [Th4+] because of similar ionic radius of 1.05 and 1.10 Å (Jaffey et al., 1971). Two isotopes of [U4+] (238U and 235U) generate 206Pb and 207Pb isotopes following the decay processes: 238U →206Pb + 8α+ 6β− (half-life: 4468 million years, Jaffey et al., 1971), 235U →207Pb + 7α + 4β− (half-life: 703.8 million years, Jaffey et al., 1971) and 232Th →208Pb + 6α + 4β− (half-life: 1400 million years, Jaffey et al., 1971). Based on triple decay processes, the detrital zircon ages can be obtained via consisted 206Pb 238U, 207Pb 235U and 208Pb 232Th decayed ages.
In addition to U-Pb geochronology, the Lu-Hf isotopic system has become an indispensable tool for understanding crustal evolution and mantle differentiation (Patchett and Tatsumoto, 1981; Patchet, 1983). The [Lu3+] is the heaviest rare earth element (REE) and are easily enriched in detrital zircon. The 176Lu decays to 176Hf via 176Lu →176Hf (half-life: 37.1 billion years, Kinny and Mass, 2003). Except for the geochronological applicat ion, the Lu-Hf isotopic data can be used to gain the original information (Scherer et al., 2001; Söderlund et al., 2004). The Lu-Hf isotopic data are noted by ε units by εHf(0)=10 000 × [(176Hf 177Hf)sample (176Hf 177Hf)] and εHf(t) = 10 000 ×{[(176Hf 177Hf)sample−(176Lu 177HfHf 177HfLu 177Hf. t is the crystallization age. 176Hf 177Hf and 176Lu 177Hf can be measured from detrital zircons. λ is the decay constant and equals to 1.867 × 10−5 million years (Söderlund et al., 2004). CHUR denotes the isotopic results of the chondritic uniform reservoir.
In the past two decades, it is estimated that millions U-Pb geochronological data of detrital zircons have been internationally reported. As the amount of data increases, it's possible to use detrital zircon data with big data methods for analyzing significant scientific problems. For instance, the compilation of detrital zircon big data is used for the reconstruction of continental arcs (McKenzie et al., 2016; Cao et al., 2017), tectonic history (Cawood et al., 2012; Barham et al., 2022; Zhang, 2023; Odlum et al., 2024), crustal evolution (Cheng, 2017; Barham et al., 2019; Cawood, 2020), paleo-geographic (Xue et al., 2023; Jian et al., 2022) and provenance analysis (Wang et al., 2024). Along with data-driven analysis, several analytical tools (Ludwig, 2003; Vermeesch, 2018; Saylor and Sundell, 2016; Sharman et al., 2018) and professional databases have been established (Voice et al., 2011; Puetz and Condie, 2019; Martin et al., 2022; Puetz et al., 2024b; Wu et al., 2023). However, the existing databases are not primarily designed for the needs of sedimentological researches and the reported data are usually mixed with magmatic and metamorphic rocks. With the rapid accumulation of detrital zircon data, existing databases are difficult to effectively cover detrital zircon data in sedimentary rocks.
Current database compilations in the Earth sciences predominantly emphasize data dissemination while offering limited discussion of the procedural challenges inherent to data construction. Previous databases typically report compiled datasets directly while neglecting the complexities of data collection and processing (Voice et al., 2011; Puetz and Condie, 2019; Martin et al., 2022; Puetz et al., 2024b; Wu et al., 2023; Table 1), an omission that has caused database growth to lag substantially behind the rate of scientific publication. Consequently, the construction of large-scale geoscience databases, particularly for detrital zircon data, urgently necessitates a shift from manual curation toward systematic, automated collection methodologies, especially as established repositories such as EarthChem, GEOROC, EarthBank, and Geochron, despite providing user-friendly web interfaces for data querying and submission, still require contributors to manually extract and reformat data from original publications into standardized templates, a time-consuming bottleneck that continues to impede data contribution. To address these challenges, we established OneDZ, a comprehensive database of detrital zircon U-Pb geochronological and Lu-Hf isotopic data covering global English and Chinese literature through 2022. Inspired by the emerging “literature-as-datasets” paradigm utilizing large language models (LLMs), we experimentally deployed multiple automated LLM-driven agents for data collection, enabling users to contribute through original PDF files or DOI information alone.
Table 1Construction methods comparison of three typical zircon databases.
Currently OneDZ encompasses 2 550 738 U-Pb and 297 527 Lu-Hf records from approximately 275 971 publications. Furthermore, we implemented a dual-track quality assurance system in which automated agent-based extraction and verification facilitate rapid data proliferation, while expert inspection ensures reliability, with 1 414 062 U-Pb records and all Lu-Hf records having been manually verified by specialists. Data in OneDZ spans nearly the entire history of earth's sediments, offering valuable insights into the timing and nature of geological events. The compilation includes data from various analytical techniques, host rock lithologies, stratigraphic information, and other original records. OneDZ records the lithology, stratigraphic, spatial, and testing information of detrital zircons as much as possible. In the compilation of OneDZ, Python scripts were developed for systematic data cleaning, format standardisation, and quality control, ensuring that the final dataset is internally consistent and ready for immediate reuse. The enormous volume of data also makes OneDZ a valuable resource for discussing data analysis methods in Earth science. OneDZ provides a foundation for research in multiple aspects, including data provision, data harmonisation, and discussion and analysis of data analysis methods in earth science.
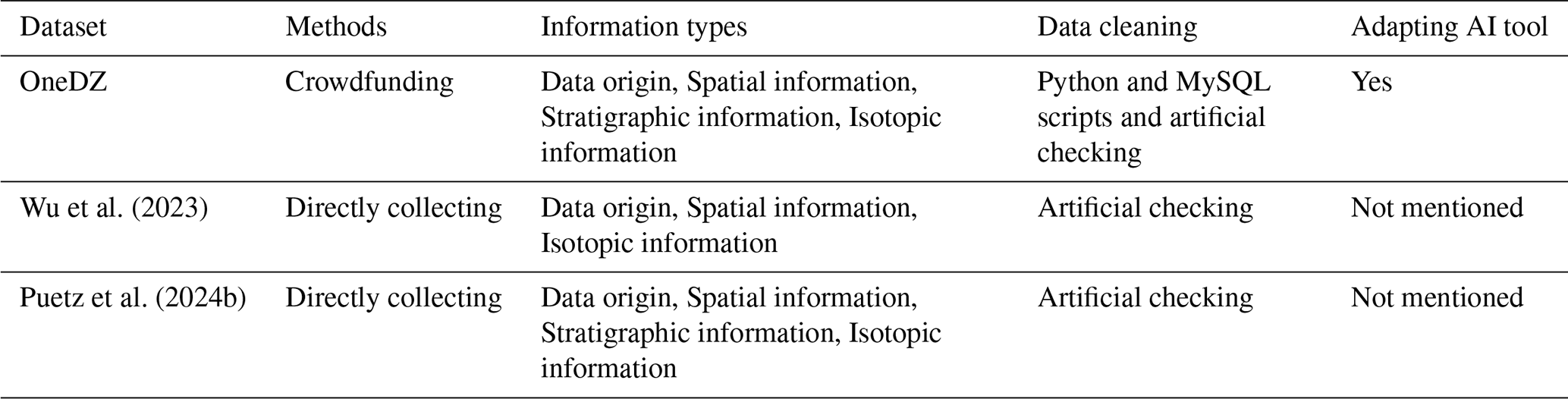
One of the most unique features in OneDZ is the systematic construction workflow (Fig. 1). Firstly, the knowledge graph (Hu et al., 2023) was adopted and guided the header design by identifying the most frequent words related to detrital zircon. With the knowledge graph, the words to describe the sample location, sedimentary or stratigraphic descriptions and the isotopic results are the most relevant information associated with detrital zircon studies. Previous research rarely summarized the difficulties in collecting data sources. Guo et al. (2024) summarized current geoscience data compilation challenges include non-repeatability, uncertainty, multi-dimensionality, computational complexity, and frequent updates, which pose significant obstacles to the efficient collection and management of geological information. In practice, constantly switching potential literature search engines and manually downloading potential articles one by one actually occupies the main time of database construction. In this project, AI-assisted tools, including DataExpo and GPT Agent (Sect. S1 in the Supplement) and large language model, were employed to check specific online resources like Pangea (https://pangaea.de/, last access: 31 December 2022), Google Scholar, and CNKI to search potential papers containing data and capture meta data from PDF files. Following the AI tools, manual verification was conducted, and publication information were passed to several volunteering experts based on their interest regions. These experts extracted and cleaned data using the computer-vision tool, DeepShovel (Zhang et al., 2022a, b, 2023b), and Python/SQL scripts. These validated data were imported into the OneDZ database. Table 1 provides a detailed comparison with other detrital-zircon databases.
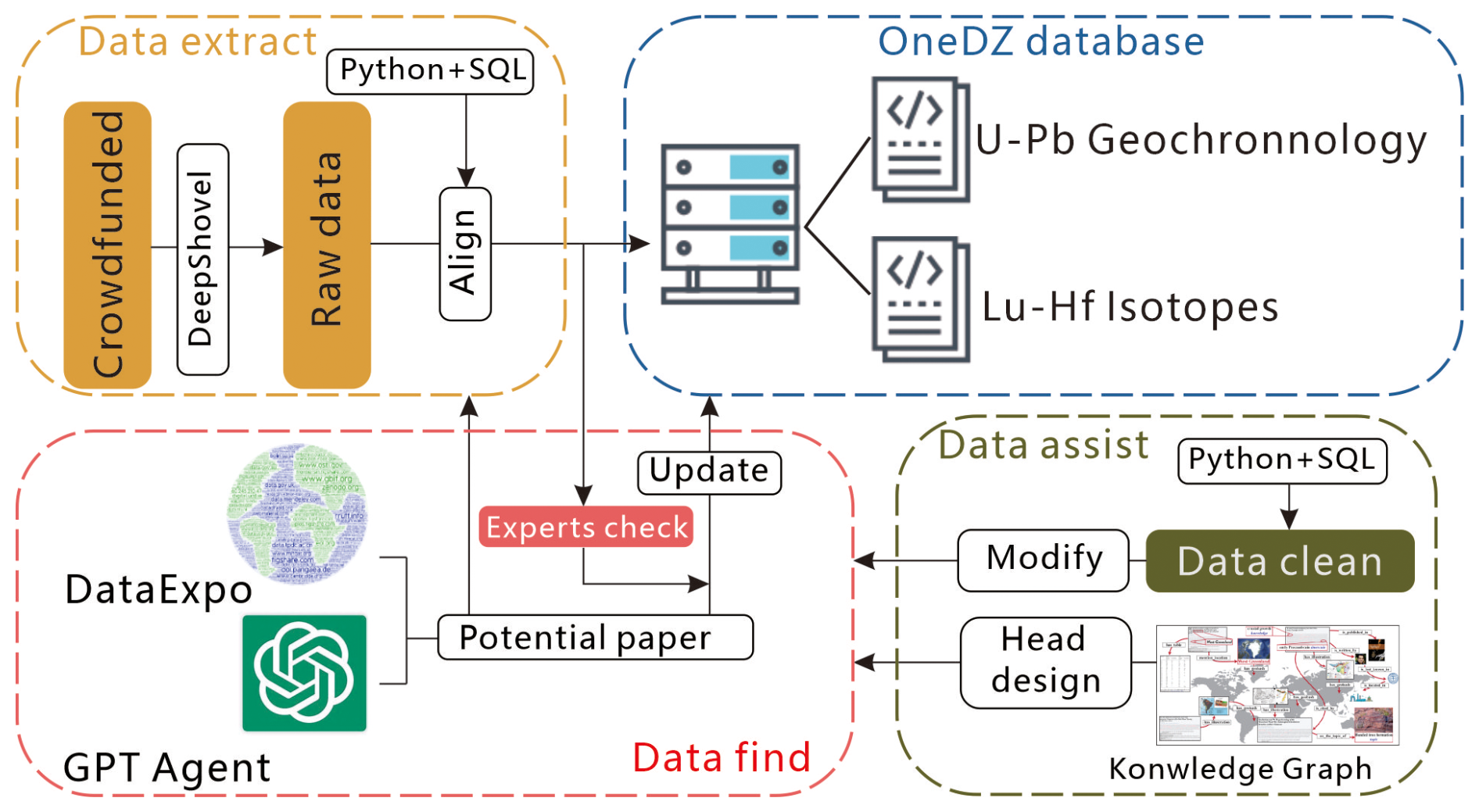
Figure 1Workflow of constructing the OneDZ database (DataExpo was adopted from Lu et al., 2023, the DeepShovel tool was developed by Zhang et al., 2022a, b 2023b, and the knowledge graph was based on Deng et al., 2021).
2.1 Crowdfunded construction
In the era of data explosion, crowdfunding has become an efficient method for building mega databases. Inspired by this cooperative construction, the OneDZ database was established by dividing different regions and quickly organizing a group of experts in detrital zircons. The crowdfunding approach ensures that each scientist is familiar with the contributed data, maximizing efficiency and accuracy within the same framework following a standard. This method also facilitates dynamic database updates and promotes sustained growth in data volume. The crowdfunded construction is anchored by several regional detrital zircon databases mainly in China which published in a special issue of the journal of Geosciences Data Journal (see Yang et al., 2023), including those from the North China Block (Yang et al., 2023; Dong et al., 2023), the Eastern Central China Orogenic Belt (Chai et al., 2023), the Songpan-Ganzi and Western Qinling terranes (Pan and Hu, 2023), the Central Asian Orogenic Belt (Wang et al., 2023), South China (Luo et al., 2023; Xia et al., 2023), the Qilian-Qaidam-Kunlun collage (He et al., 2023), the South China Sea (Huang and Hu, 2023), the Tarim-West Kunlun-Pamir-Tajik-Tianshuihai terranes (Zhang et al., 2023a), the Middle East (Chen et al., 2023a; Sun and Chen, 2023), and samples from Quaternary sediments (Chen et al., 2023b). However, the experts-driven crowdfunding could not ensure collecting all data. Therefore, for publications after 2022, a new approach was applied, where everyone can just offer PDF files (or even just the DOI information) and the specific number would be extract by AI agent. This method lowers the technical threshold for data collecting.
2.2 Facility from AI tools
One of the fundamental challenges in compiling large geoscience datasets lies in data collection. Although the crowdfunded approach ensures that geologists participating in database development are experts in their research area, their expertise does not guarantee familiarity with every publication. To find potential metadata, this study introduced a data parsing system integrated with deep learning technology. The data parsing tool is named DataExpo (Lu et al., 2023) and employs deep learning for metadata extraction (Figs. S1–S2), performing automatic semantic tagging, classification, and structured information extraction from web pages. DataExpo automatically crawls web pages related to detrital zircon research. Using a multidimensional web page ranking strategy, retrieval results for different queries are sorted. Finally, based on natural language processing (NLP) and convolutional neural networks (CNNs), DataExpo adjusts the ranking of retrieval results and determines whether to push them to experts. Another AI tool, AI Agent, was created through prompt engineering to analyze characters from specific websites and find potential titles about detrital zircons. Details on using DataExpo and GPT Agent in the OneDZ database construction are provided in Sect. S1.
In addition to integrating data sources, data extraction poses another major challenge. While most online articles store data in Excel tables as attachments, a considerable number of detrital zircon data is stored in the main text in the article either in table or in text form. To accelerate construction, the interactive computer-vision AI tool DeepShovel (Zhang et al., 2022a, b, 2023b) was utilized to automatically split tables via optical character recognition. Details on using DeepShovel can be found in Fig. S3. To attract more data contribution and lowers the technical requirements, automatic data collecting tool from large-language model agent was applied. After receiving the contributed PDF file, the multi-modal agent automatically extracts the metadata and saves as json files. Then another data-checking agent would automatically check the data quality. At last, an independent agent would evaluate each item. Only items with over 60 % information were provided would be sent to experiencing manual checking.
2.3 Automatic data process
In the era of exponential data growth, the construction of domain-specific earth-science databases is becoming the norm. Yet existing zircon and broader geoscience repositories overwhelmingly emphasize data quality, while the critical step of data cleaning has received little systematic attention. In the construction of large scientific databases, beyond ensuring the quality of the original data, it is also essential to trace and maintain the quality of different versions of data formed during the database construction process, a procedure known as data cleaning. Hellerstein (2008, 2013) and Chu et al. (2016) identified the key steps in the data cleaning process including (1) Data review and understanding; (2) Missing value processing; (3) Outlier detection and handling; (4) Data format and type conversion; (5) Data consistency and normalization; (6) Data de-duplication. Following the standard data cleaning process, Python scripts were designed for detecting missing key items, checking for conflicting content, detecting format anomalies, and eliminating duplicate data entries (see Sect. S2 and Fig. S4 in the Supplement for details).
The OneDZ dataset is distributed as flat CSV files with a uniform, standardised column schema to maximise interoperability and ease of reuse. Each row represents a single detrital zircon analysis, and columns are organised into thematic groups: bibliographic metadata, sample location and stratigraphy, depositional age constraints, analytical method details, isotopic ratios and their uncertainties, calculated ages, and elemental concentrations (Fig. 2). All U-Pb records follow a single 64-column schema, while Lu-Hf records follow a 33-column schema (see README file in the Zenodo repository for the complete field dictionary). This flat-file structure ensures that users can load, filter, and analyse the data with any standard statistical software (e.g., R, Python, Excel, Matlab) without requiring database connectivity or knowledge of relational table structures.
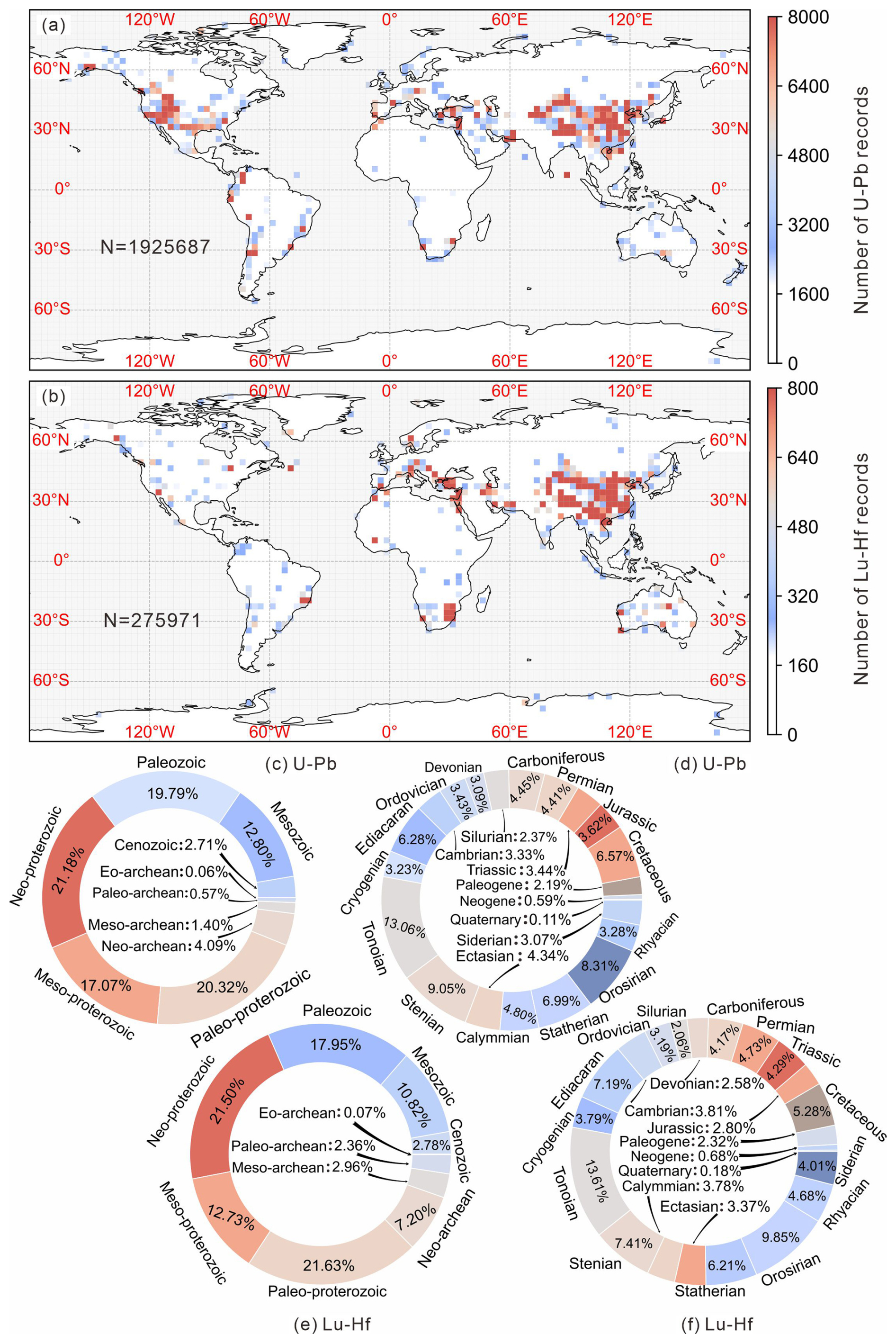
Figure 2Spatial and temporal distributions of U-Pb and Lu-Hf isotopic records. (a) Kernel density estimate map of U-Pb records (the spatial resolution is 1° × 1°); (b) Kernel density estimate map of Lu-Hf records (the spatial resolution is 1° × 1°); (c) Era-based distribution of U-Pb samples; (d) Period-based distribution of U-Pb samples; (e) Era-based distribution of Lu-Hf samples; (f) Period-based distribution of Lu-Hf samples.
In the OneDZ dataset we have compiled 2 550 738 detrital zircon grains (1 414 062 after expert verification) with U-Pb ages and 297 527 grains with Lu-Hf isotope data. From multiple dimensions such as region, literature, and samples, OneDZ is currently the most comprehensive compilation for global detrital zircon data records (Table 2). The U-Pb geochronological data are spatially distributed across 142 geographic regions (Fig. 3a). The Lu-Hf data are primarily distributed across China, South Africa, India, and Australia (Fig. 3b). Periodic statistics indicate that ancient zircons (over 1000 Ma) predominantly contribute to this dataset in both U-Pb and Lu-Hf data (Fig. 3c–f). The content and completeness of sample metadata, spatial data, and stratigraphic information in OneDZ are summarized in Tables 3–6 (expressed as the ratio of valid entries to total entries).
Table 2Data comparison of three typical zircon databases.

Note: the bolded number represents the largest number in different items. Only statistic the detrital zircon from Wu et al. (2023) and Puetz et al. (2024b).
Figure 3Visualizations of the spatial, temporal and strata information in U-Pb dataset. (a–b) Major geographic/geological description; (c–d) Minor geographic/geological description; (e–f) Group-Formation-Member records; (g–h) Locality/Sedimentary profile.
3.1 Reference information
The reference information in OneDZ includes the principal investigator, publication year, journal name, volume, pagination, article title, and a direct weblink to the original publications. Figure S5 provides a temporal overview of the geographic distribution of these scholarly works. OneDZ aggregates a comprehensive total of 742 832 papers from 1995 to 2022 (Fig. S5a), which includes 52 604 English-language papers and 203 326 Chinese-language papers in the U-Pb datasets. For the Lu-Hf datasets, the compilation consists of 65 420 English-language papers and 8762 Chinese-language papers from 2004 to 2022 (Fig. S5b). Additionally, publicly available master's and doctoral dissertations have been incorporated into the dataset. To ensure accessibility and inclusivity, Chinese-language papers on detrital zircons have been meticulously translated into English. In the U-Pb age dataset, journals such as Precambrian Research, Geological Society of American Bulletin, and Gondwana Research predominantly contribute to the database (Fig. S6a–b). The Lu-Hf analyses in OneDZ are drawn entirely from the same journal pool that provided the U-Pb data (Fig. S6c–d). Comparing with previous databases (Puetz et al., 2024b; Wu et al., 2023), OneDZ surpasses existing repositories in volume and in journal diversity (Fig. S6a–b).
3.2 Sample, spatial and strata information
OneDZ contains the published sample ID, country or state, region, continent, major and minor geographic or geological description of the sediments. In geological research, geological bodies, sedimentary basins, or specific strata are usually studied as research objects. Recording the samples position solely based on spatial coordinates cannot meet the needs of scientific research. While relying exclusively on high-precision latitude–longitude coordinates is insufficient for rigorous spatial analyses, such attributes are nevertheless the only consistently available resource in most databases and thus remain the primary handle for sample positioning. The decimal format of latitude and longitude coordinates has been considered the most suitable recording format in the previous zircon databases (Puetz et al., 2021, 2024a, b). However, a considerable number of research papers report coordinates in the DMS (Degree-Minute-Second) format. To expedite the standardization of these diverse DMS notations into a decimal format, we have crafted and implemented a Python code snippet, as detailed in Sect. S3. Another challenge arises from the absence of coordinate reports in some papers. Traditionally, papers lacking specific coordinates have been excluded from databases. However, directly exclusion could exacerbate the spatio-temporal bias. To enhance the data richness, a spatial coordinate estimation method was applied during the database construction process. This method, based on a plane graph and implemented in Python, swiftly estimates coordinates for articles missing these details while striving to maintain accuracy (Sect. S3).
Given the significance of detrital zircons in geological research, the strata information schema within our database has been designed to encapsulate a wide array of sedimentary data. It documents the strata age according to the period-epoch-stage stratigraphic system, as well as the maximum, estimated, and minimum depositional ages. Further details regarding the stratigraphic data points are outlined in Table 4.
Table 3Data specifications of the reference information (the proportion was calculated by number of valid items divided the number of total items).
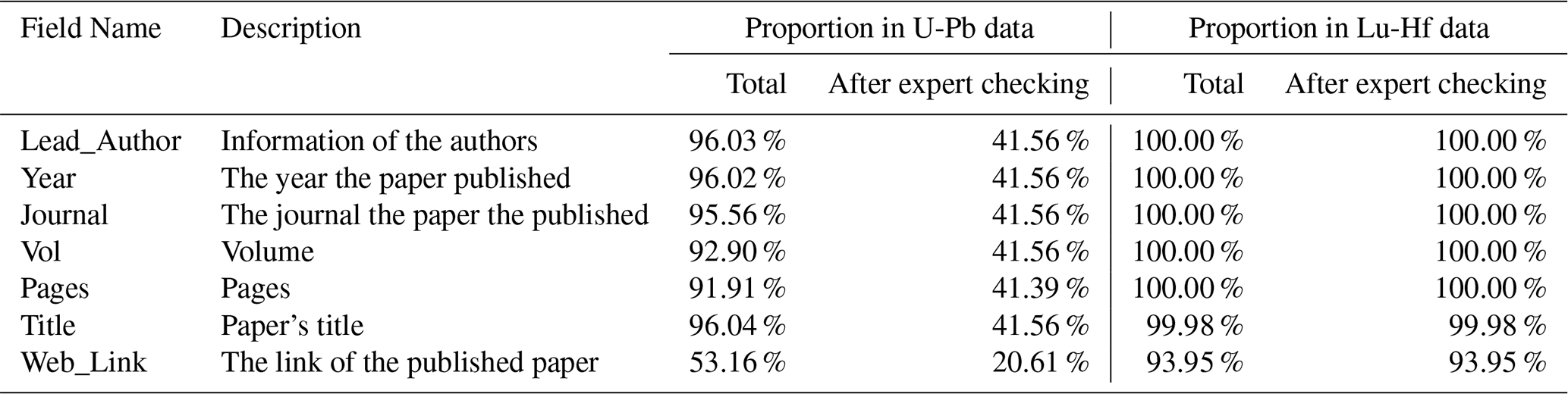
Table 4Data specifications of the sample, spatial and strata information (the proportion was calculated by number of valid items divided the number of total items).
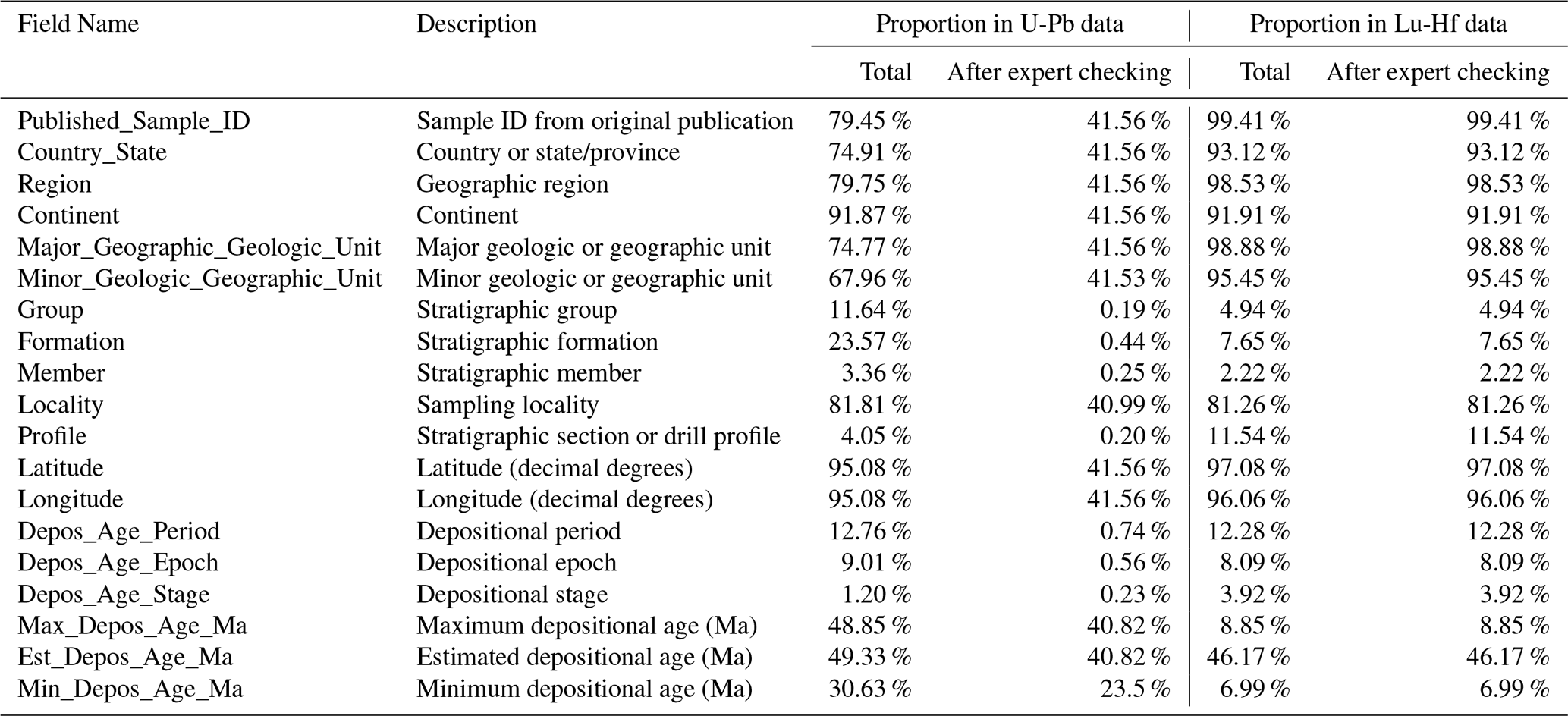
Although maximizing the utilization of research papers can mitigate spatial bias to a certain extent, the spatial-strata information visualized in both the U-Pb and Lu-Hf (Figs. 2–4) datasets continues to exhibit significant spatial skew. A majority of the records are concentrated in East Asia, with a particular focus on China.
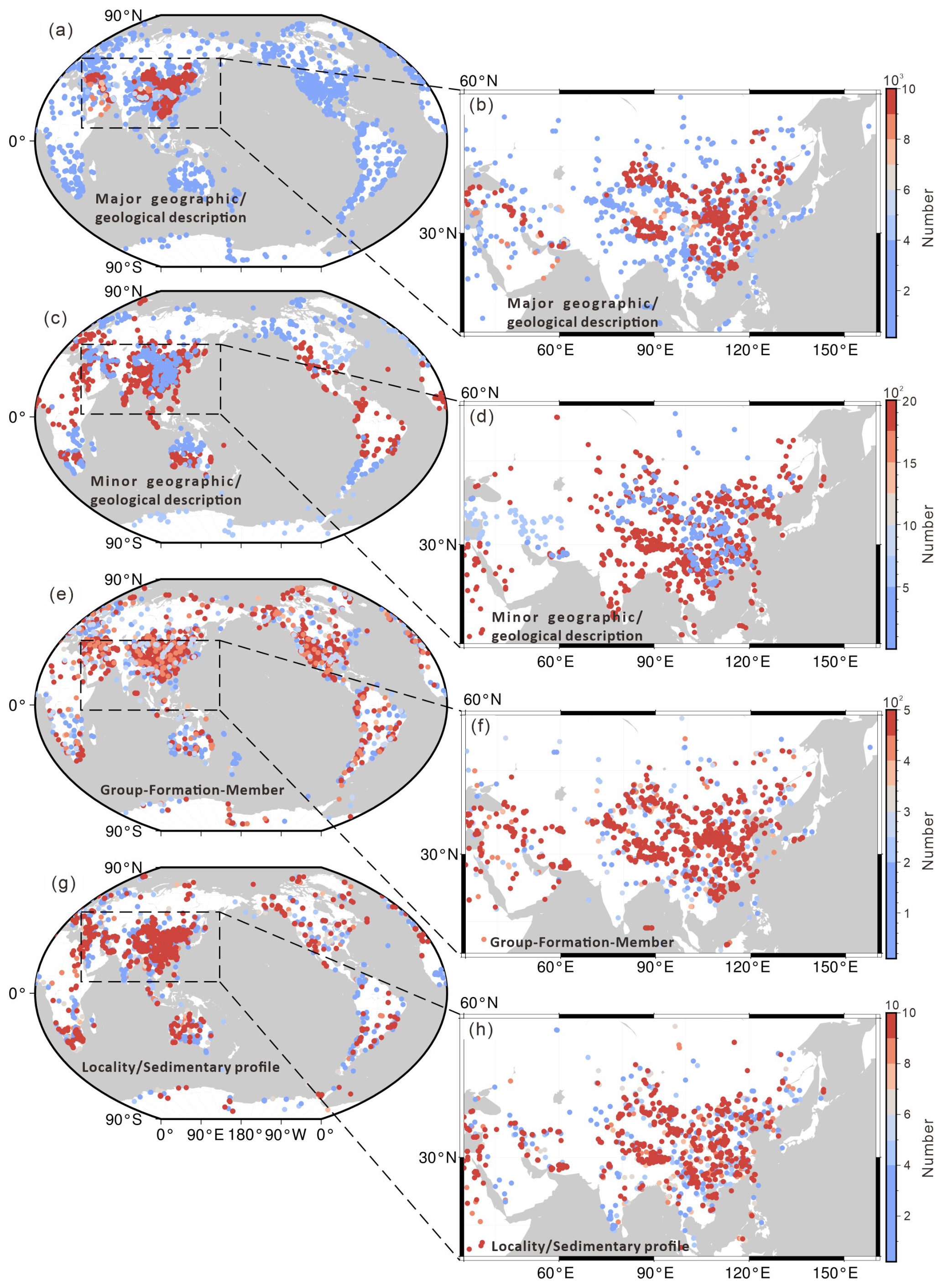
Figure 4Visualizations of the spatial, temporal and strata information in Lu-Hf dataset. (a–b) Major geographic/geological description; (c–d) Minor geographic/geological description; (e–f) Group-Formation-Member records; (g–h) Locality/Sedimentary profile.
Despite this concentration, all indicators suggest a substantial global representation within our datasets. The visualization tools employed highlight the areas of high research activity while also underscoring the need for further research in underrepresented regions to achieve a more balanced global perspective.
Table 5Data specifications of the U-Pb isotopic system (the proportion was calculated by number of valid items divided the number of total items).
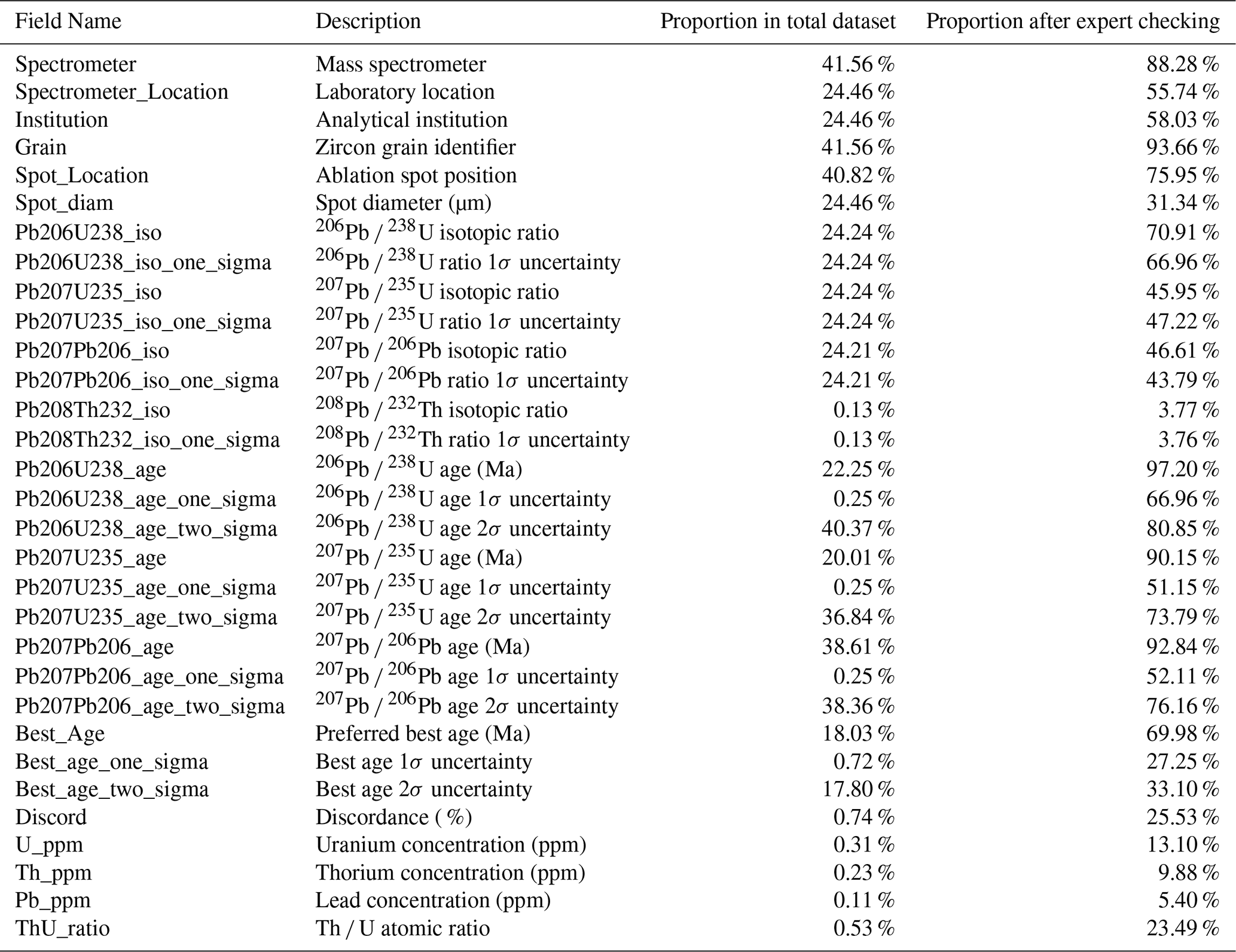
Table 6Data specifications of the Lu-Hf isotopic system (the proportion was calculated by number of valid items divided the number of total items).
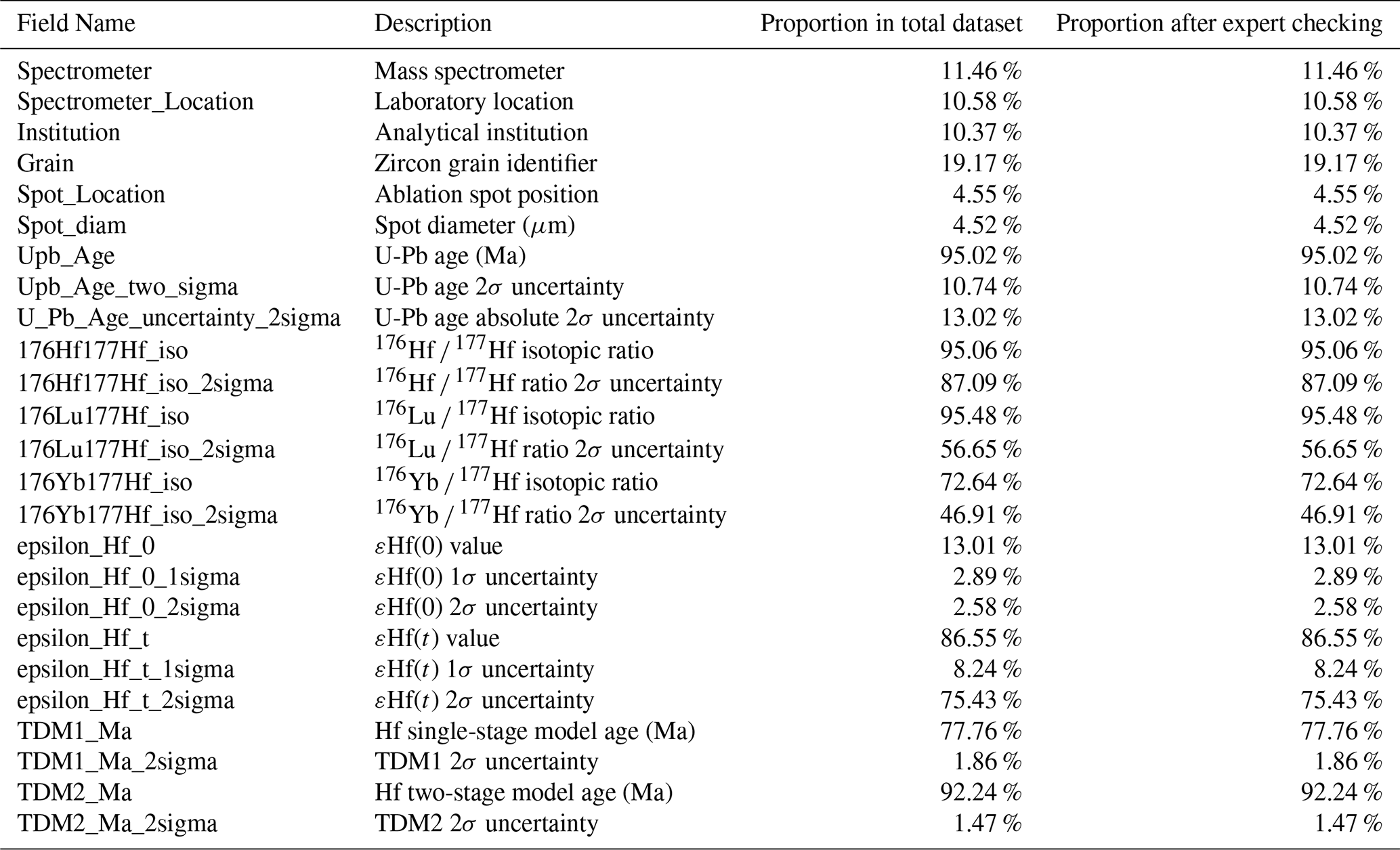
3.3 U-Pb isotopes database
The geochronological records include full analytical-method metadata: the technique used (e.g., LA-ICP-MS, SHRIMP or ID-TIMS), the analytical institution's spot location (rim vs core), and the spot diameter. For the chronological data, the isotopic ratios 206Pb 238U, 207Pb 235U, 207Pb 206Pb, and 208Pb 232Th were recorded with corresponding 1σ uncertainties. A limited number of papers have reported uncertainties at the 2σ level. Where a preferred age was not explicitly reported by the original authors (≤ 0.5 % of records), OneDZ estimated the most reliable date using 1 uncertainty and the 1200 Ma 1600 Ma thresholds of Gehrels et al. (2008). These rare “estimated ages” are flagged as EstAge = 1 so that users can readily distinguish them from author-specified values.
Furthermore, the database also archives the discordance ratio, concentrations of U, Th, and Pb, as well as the Th U ratios, providing a comprehensive set of parameters for geochronological analysis.
3.4 Lu-Hf isotopes database
The Lu-Hf isotopic data within OneDZ are fundamentally anchored in U-Pb chronological results. Alongside the age determinations, we have meticulously documented the basic analytical results, including the 176Yb 177Hf, 176Lu 177Hf, and 176Hf 177Hf isotopic ratios, each accompanied by their corresponding 2σ uncertainties, which reflect the precision of the measurements.
In addition to the raw isotopic data, OneDZ encompassed several calculated parameters derived from these ratios. These include the calculated ratios of the hafnium isotope composition εHf(t) with their respective 2σ uncertainties, and the model ages TDM1 (Ma) and TDM2 (Ma). These calculated results provide further insights into the isotopic evolution and the crustal residence history of the samples analyzed.
4.1 Rock types statistics
Clastic sediments are vital geological archives to offer deep insights into the sedimentary provenance and evolutionary history of the continental crust (Taylor and McLennan, 1985). In preparation for studies on sedimentary provenance and related geological inquiries, the OneDZ database collected petrological contexts from original articles. OneDZ categorized rock types into the widely accepted hierarchical granularity system, with Class-1 encompassing clastic, meta-clastic, and pyroclastic rocks. These categories reflect the diverse origins of sediments. Specifically, Class-2 and Class-3 types provide a more nuanced classification based on grain size, which is crucial for understanding sedimentary processes and environments. Class-2 further subdivided the rocks, serving as a supplement to the macroscopic rock classification of Class-1. Class-3 adopts the particle size classification scheme for detrital sedimentary rocks proposed by Udden (1914), Wentworth (1922), and Krumbein (1938), and provides the most detailed classification of rock types. In the U-Pb datasets, Class-1 rock types are predominantly clastic (50 %, Fig. 5a). Meta-clastics are the second lithological source (36.3 %, Fig. 5a). Pyroclastic takes up a little ratio (13.8 %, Fig. 5a). For Class-2 rock types, the major component is sandstone (53.6 %, Fig. 5b). The breccia, shale, mudstone equally allocated the remaining proportion (13 %, 15.7 %, 17.8 %, Fig. 5b). For Class-3 rock types, the distribution of particle sizes is quite uniform, with the proportions ranging from 1.8 % to 16.0 %. Specifically, fine sand and very coarse sand are the predominant types, accounting for 16.0 % and 12.5 % of the total, respectively (Fig. 5c).
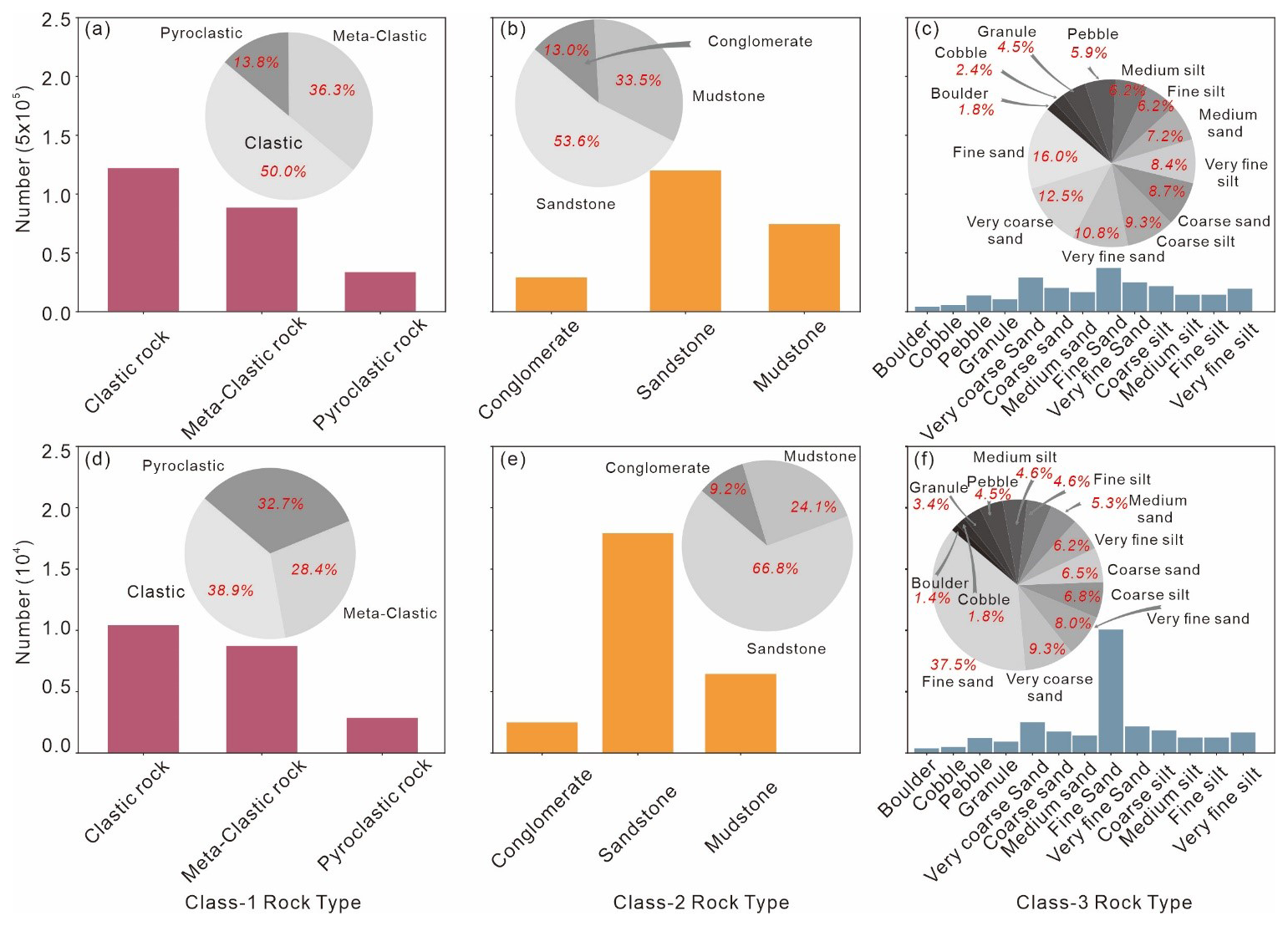
Figure 5Statistics of the rock types. (a) Class-1 type in U-Pb database; (b) Class-2 type in U-Pb database; (c) Class-3 type in U-Pb database; (d) Class-1 type in Lu-Hf database; (e) Class-2 type in Lu-Hf database; (f) Class-3 type in Lu-Hf database.
In the Lu-Hf datasets, relatively little rock records were provided in the original article. Clastic rock types contributed the most data to the dataset, comprising 38.9 % of the total (Fig. 5d). Meta-clastic offered 28.4 % of the data and pyroclastic provided 32.7 % of the data (Fig. 5d). For Class-2 rock types, the major component is sandstone (66.8 %, Fig. 5e). The breccia, shale, mudstone equally allocated the remaining proportion (9.2 %, 11.3 %, 12.8 %, Fig. 5e). In the Class-3 rock types, the distribution of grain sizes is dominated by fine sand, which accounts for 37.5 % of the total, making it the most prevalent grain size (Fig. 5f). Very coarse sand is also a significant component, comprising 9.3 % of the dataset. Other grain sizes contribute with percentages ranging from 1.4 % to 8.0 %, indicating a relatively balanced but varied composition across the different grain sizes.
4.2 Data uncertainty
The data uncertainty in the OneDZ database is stemmed from methodological errors, dating uncertainties, and potential biases associated with analytical instruments. Methodological errors are primarily attributed to variations in decay constants and half-lives among different isotopic systems. Dating uncertainties and potential biases have more to do with data processing. Figure 6 illustrates the relationships between isotopic ratios, calculated ages, and their corresponding 2σ uncertainties. The 206Pb 238U isotopic system adheres to a first-order linear regression model (Fig. 6a), demonstrating a relatively consistent uncertainty across a wide range of ages. However, for samples with depositional ages exceed approximately 2000 Ma, the 2σ uncertainty of ages increases to around 300 Ma. This trend suggests that approximately 67 % of samples may be associated with a temporal uncertainty of approximately 600 Ma. In contrast, the 207Pb 235U and 207Pb 206Pb isotopic systems are characterized by second-order polynomial regressions (Fig. 6b–c). The complex regression models suggest a 2σ uncertainty of 500 Ma emerging at around 3000 Ma in 207Pb 235U and 207Pb 206Pb isotopic systems. The age uncertainty becomes significantly pronounced when analyzing samples over 3000 Ma. Because the uncertainties in 207Pb 235U and 207Pb 206Pb isotopic systems accumulate with time and become significant only in very old samples, these systems are best suited for dating ancient rocks. (between 1000 and 3000 Ma). The relatively low uncertainties suggest 207Pb 235U and 207Pb 206Pb isotopic systems are particularly valuable for studying the early history of the earth's crust.
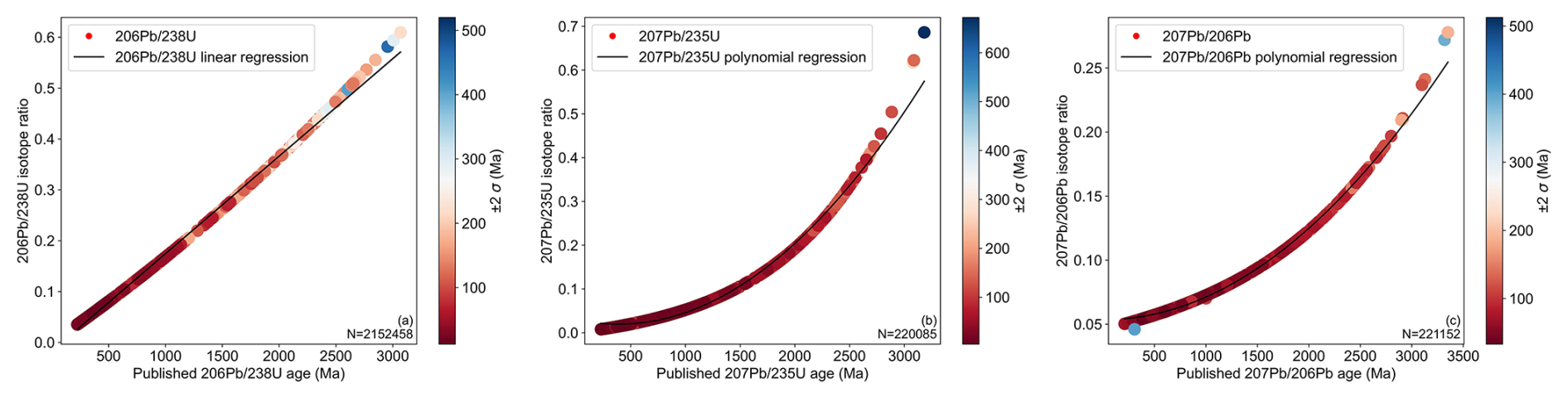
Figure 6Ages errors of different isotopic systems. (a) 206Pb 238U; (b) 207Pb 235U; (c) 207Pb 206Pb.
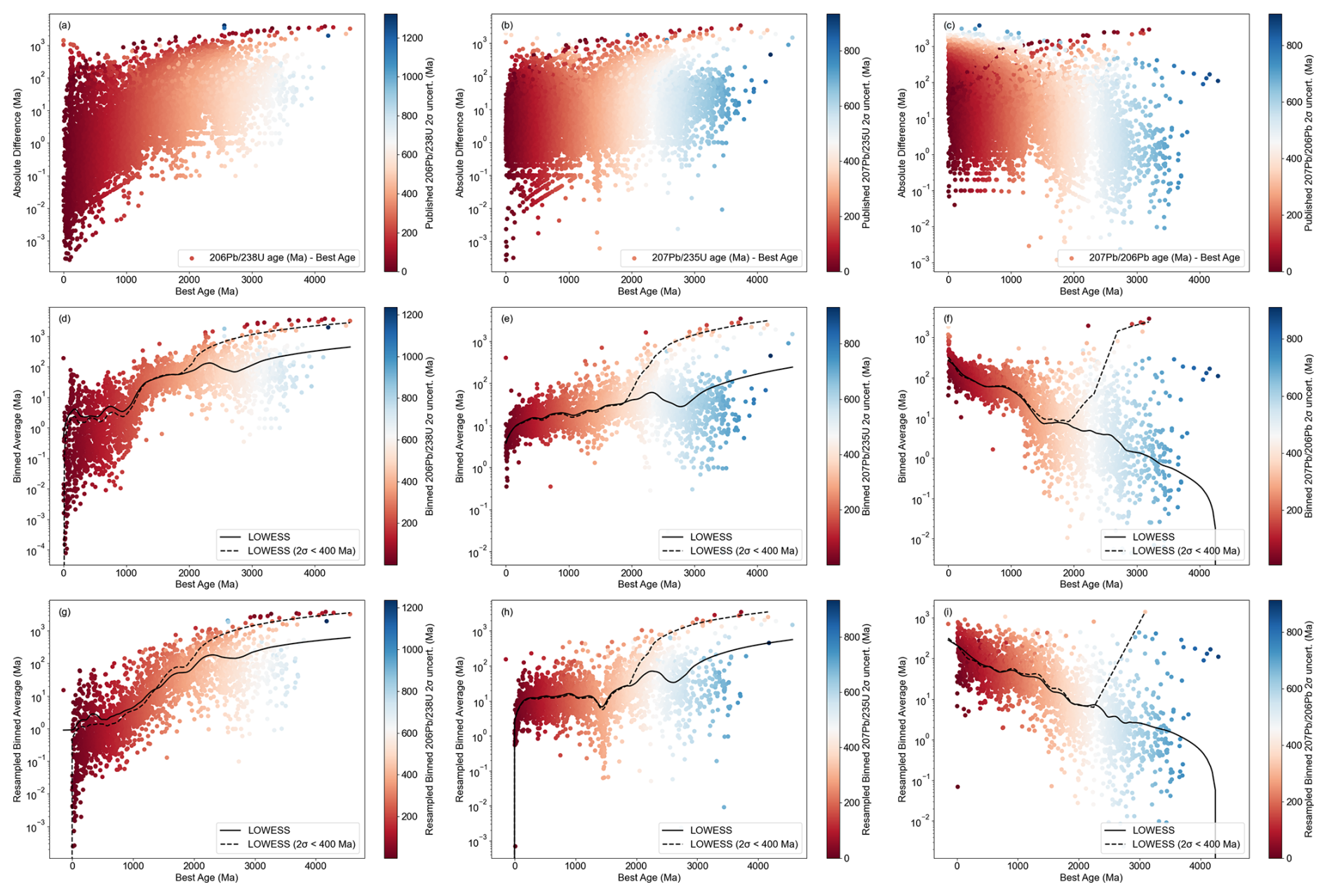
Figure 7Time-series of dating error via different isotopes. (a–c) Original data distribution; (d–f) Resampled by Monte-Carlo method; (g–i) Resampled by bootstrap method.
In addition to the intrinsic variability of isotopic systems, dating uncertainty in OneDZ database is significantly influenced by the selection of the best age. Figure 7 provides a visual representation of the discrepancies between calculated isotope ages and the best ages selected from the raw data extracted directly from published papers. Dating uncertainties grow with increasing best ages across all isotopic systems (Fig. 7a–c). To address this, we employed advanced statistical techniques, including Monte-Carlo resampling (Fig. 7d–f) and Bootstrap resampling (Fig. 7g–i), coupled with locally weighted scatter plot smoothing (LOWESS) to estimate and visualize the dating uncertainties. The LOWESS trend lines indicate that potential thresholds of uncertainty may lie around 1000 and 3000 Ma. Samples younger than 1000 Ma exhibit minimal bias, suggesting that the choice of isotopic system and the application of resampling methods have a limited impact on data uncertainty. However, isotopic uncertainties compound with time and reach ∼ 500 Ma by ages of 3000 Ma, limiting reliable dating to still older samples. While commonly employed strategies such as filtering samples based on acceptable 2σ uncertainty or utilizing resampling techniques aim to mitigate the adverse effects of selecting the best age, the analysis presented in Fig. 7 suggests that filtering alone does not significantly reduce uncertainties associated with the best age. Notably, in all isotopic systems, filtered results often reveal substantial gaps in the best age, indicating that the filtering process may not be sufficient to address the underlying uncertainties. The resampling methods, however, demonstrate a capacity to alleviate these gaps, particularly in the 207Pb 206Pb isotopic system, where they prove effective in reducing the best age discrepancies (Fig. 7i).
For analytical techniques, the LA-ICP-MS has become the preferred method for sedimentary research due to its efficiency in yielding geochronological data. Figure 8 illustrates the variation in discordance ratios over time for different analytical instruments. The SHRIMP method, known for its precision, demonstrates a consistently low discordance ratio (Fig. 8a). Remarkably, even samples with elevated age uncertainties maintain discordance ratios below 0.5 %, indicating SHRIMP's reliability in dating. LA-ICP-MS displays an increase in age uncertainty for samples exceeding 1000 Ma but maintains a discordance ratio below 0.5 % for these samples (Fig. 8b). However, LA-ICP-MS exhibits a notable disadvantage for samples with low age uncertainties dating from approximately 800 to 1200 Ma, where the discordance ratio can be relatively high, occasionally exceeding 1 %. This underscores the need for particularly careful data interpretation in these specific age ranges. The ID-TIMS method, while less commonly utilized in sediment dating, exhibits low discordance ratios (Fig. 8c). This suggests that ID-TIMS, despite its limitations, offers robust results for the most precision of dating requirements. Samples analyzed by SIMS appear to exhibit a potential linear relationship between age uncertainty and discordance ratio (Fig. 8d).
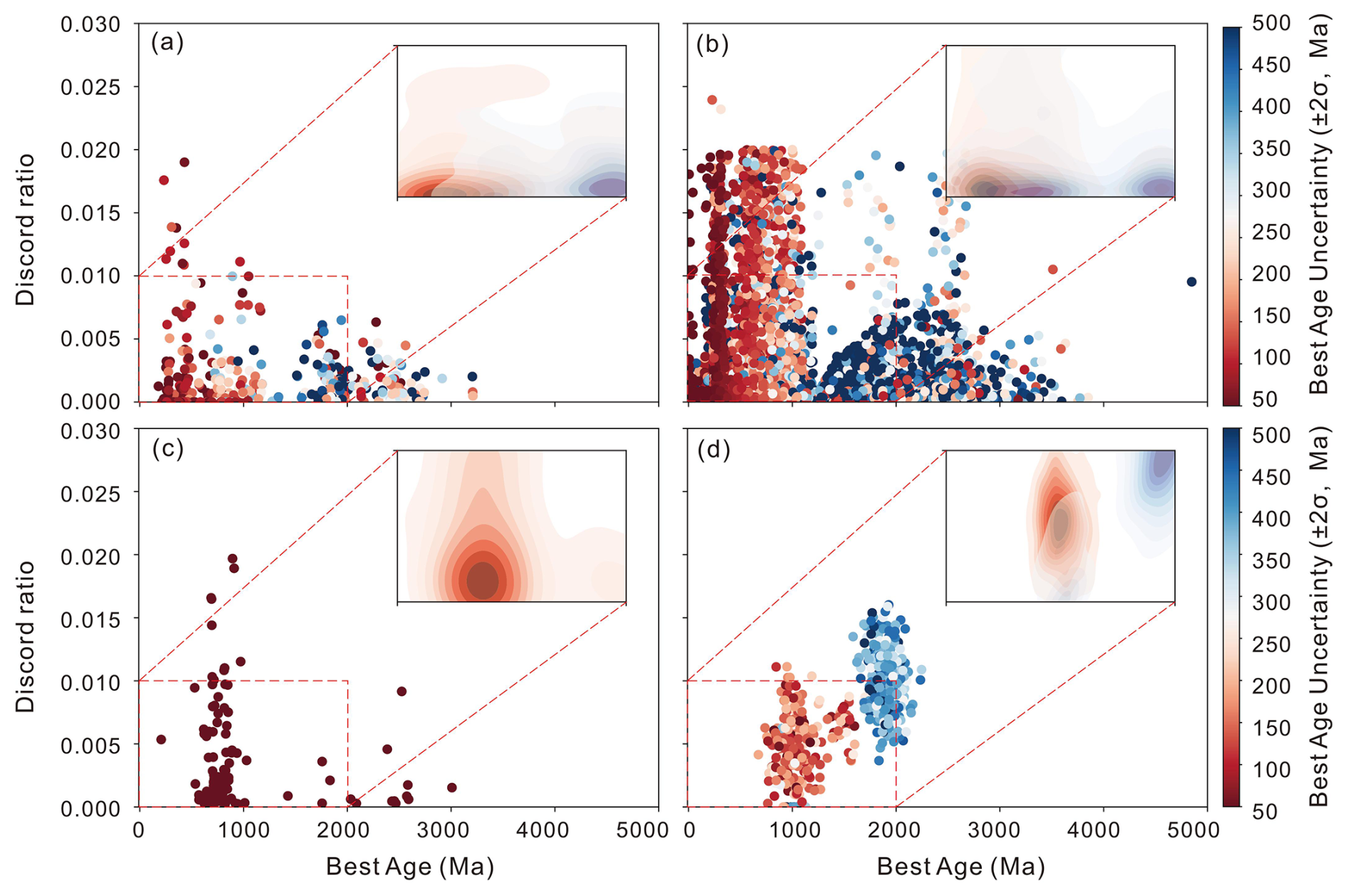
Figure 8Discordance ratio varying with time by different instruments. (a) SHRIMP; (b) LA-ICP-MS; (c) ID-TIMS; (d) SIMS.
The original uncertainty associated with the Lu-Hf dataset predominantly pertains to the analytical outcomes obtained from isotopic measurements. Across all geological periods, the 2σ errors for the isotopic ratios 176Hf 177Hf, 176Lu 177Hf, and 176Yb 177Hf typically fluctuate around 2 × 10−5, as depicted in Fig. S7. The measurement ranges for these three isotopes are approximately 2 × 10−2, indicating a high level of precision in the analytical process (Fig. S7). The uncertainties for the Lu-Hf isotopic system are notably an order of magnitude lower than the analytical results, suggesting that the system is inherently more precise than the measurements themselves. This stability in Lu-Hf uncertainties is maintained even at high resolutions, highlighting the robustness of the dataset in providing reliable isotopic age estimates. Other uncertainty in Lu-Hf datasets are the εHf(0) and εHf(t) errors (Fig. S8). The high-quality isotopic results obtained from the Lu-Hf dataset contribute to the stable and low 2σ errors observed in both εHf(0) and εHf(t), as depicted in Fig. S8. These parameters reflect the hafnium isotope composition at the time of zircon crystallization (εHf(0)) and at a specific time in the past (εHf(t)), exhibiting a consistency in error magnitude that underscores the reliability of the dataset. Similar to the isotopic uncertainty observed in the Lu-Hf system, the uncertainties associated with εHf(0) and εHf(t) are considerably larger than their corresponding 2σ errors. This discrepancy highlights the precision of the isotopic measurements relative to the calculated uncertainties of the hafnium isotope ratios. The stability of the error over the timescale is particularly noteworthy, suggesting that εHf(0) and εHf(t) values are independent and robust indicators of the isotopic evolution of the samples. This temporal stability further reinforces the reliability of these parameters in geochronological and geochemical analyses.
4.3 Spatial and temporal distributions of samples
Spatial distribution biases are evident within the OneDZ database (Figs. 3–4). To delve into the effects of biased distributions, the U-Pb age data was segmented according to geological time sequences and visualized (Fig. 9). Temporal slices reveal that the Qinghai-Tibet Plateau, Alps, Cordillera and Andes mountains are the main sampling areas in the Cenozoic (Fig. 9a–c). In the Mesozoic, the main sampling regions are similar to areas from the Cenozoic (Fig. 9d–f). In the Paleozoic, East Asia is obviously over-sampled relative to other regions (Fig. 9g–l). In the pre-Cambrian period, East Asia, Europe and Australia contributed the majority of samples (Fig. 9m–n)
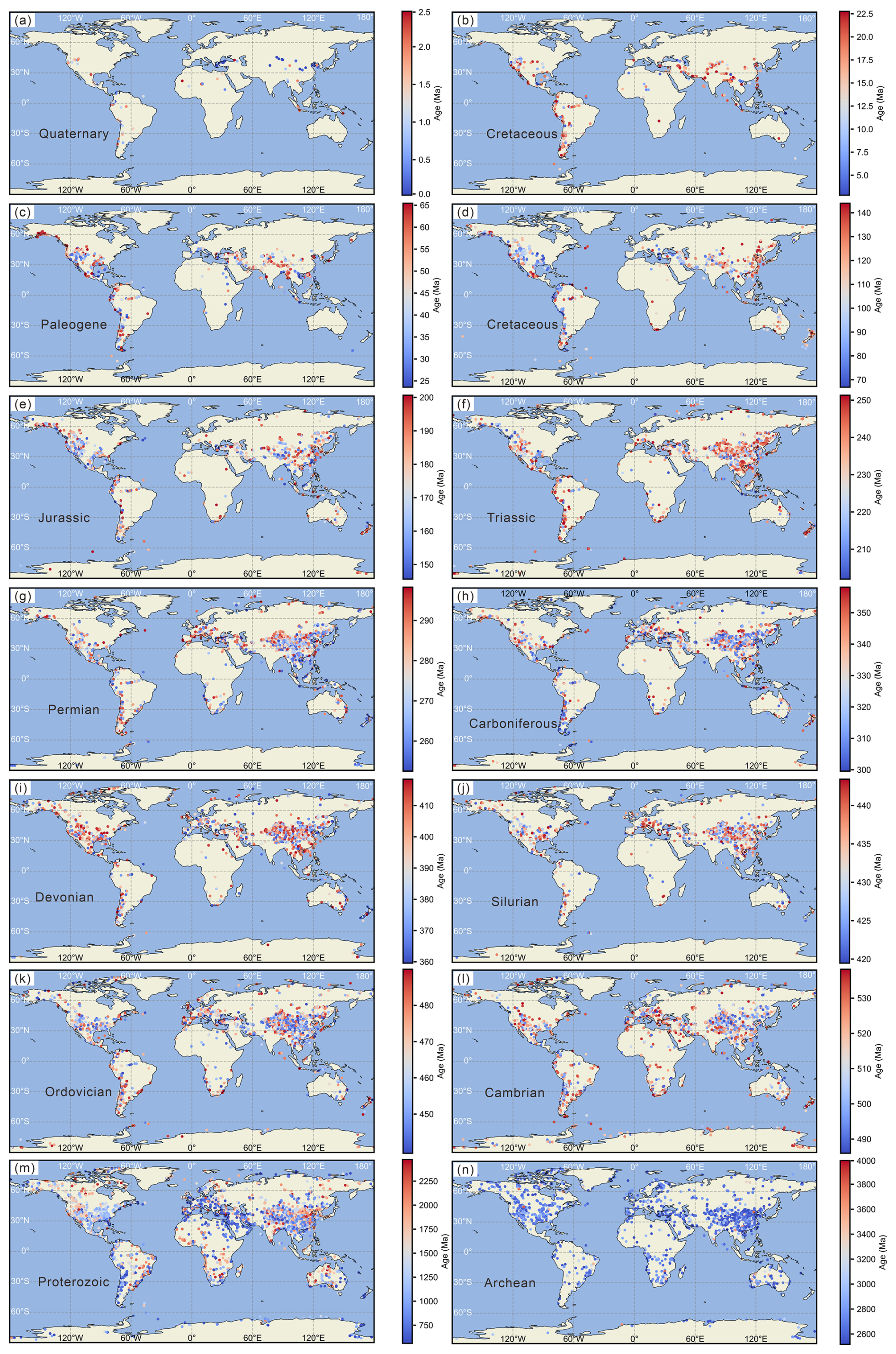
Figure 9Spatial-temporal distribution of the single U-Pb age record.
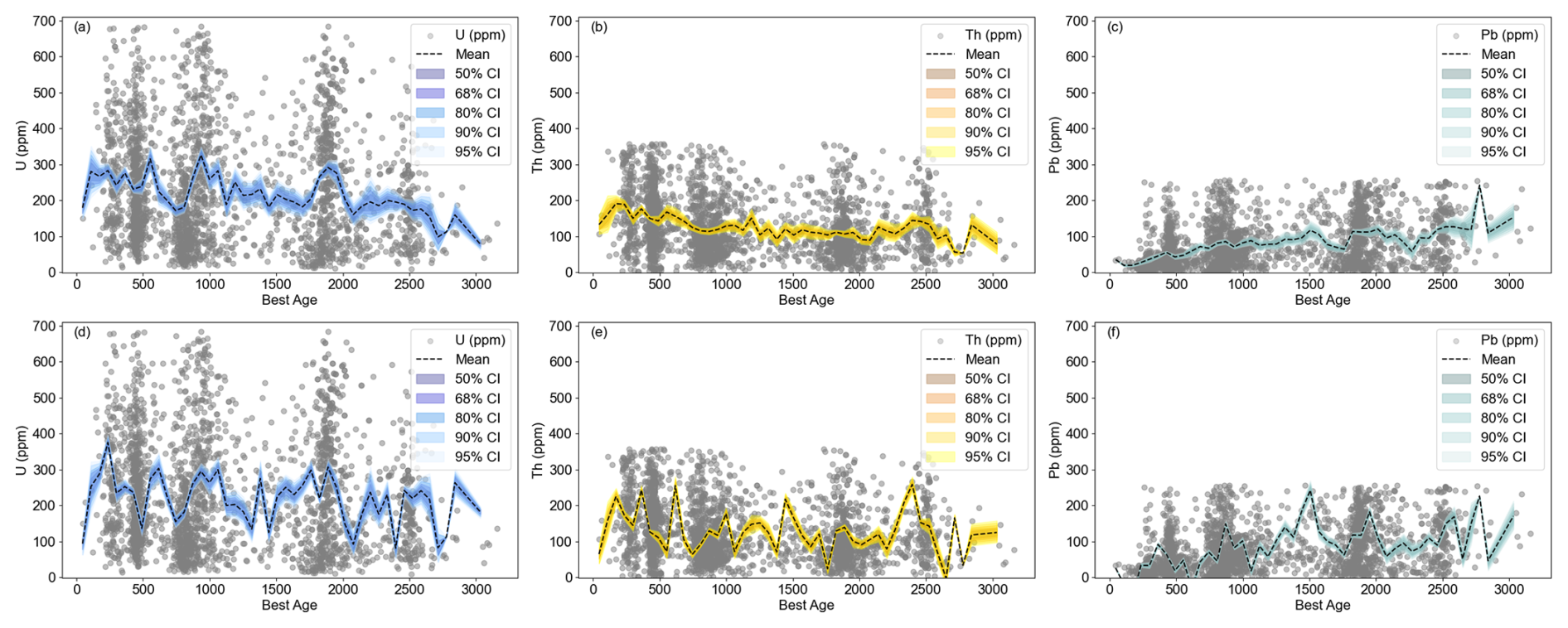
Figure 10Temporal variations of U, Th, Pb concentrations in U-Pb dataset. (a) U concentrations with bootstrap resampling; (b) Th concentrations with bootstrap resampling; (c) Pb concentrations with Monte-Carlo resampling; (d) U concentrations with Monte-Carlo resampling; (e) Th concentrations with Monte-Carlo resampling; (f) Pb concentrations with Monte-Carlo resampling.
In this study, we also present the visualization of the temporal distributions of uranium, thorium, and lead concentrations in detrital zircons (Fig. 10). The concentrations of these elements exhibit temporal stability, with uranium ranging from approximately 100 to 300 ppm, thorium from 100 to 200 ppm, and lead from 0 to 200 ppm. Notably, there are differences in the estimation of temporal distributions of element concentrations when using Bootstrap and Monte Carlo methods (Fig. 10). Furthermore, beyond elemental concentrations, the Th U ratio in zircon is a crucial indicator for determining the provenance of zircon. It is widely accepted that a Th U ratio below 0.1 suggests zircon may have experienced metamorphism and recrystallization, while a ratio above 0.4 is indicative of magmatic zircon. The resampling methods displays from all time spans, that the Th U is larger than 0.4, indicates magmatic zircon dominants the detrital zircon (Fig. S9).
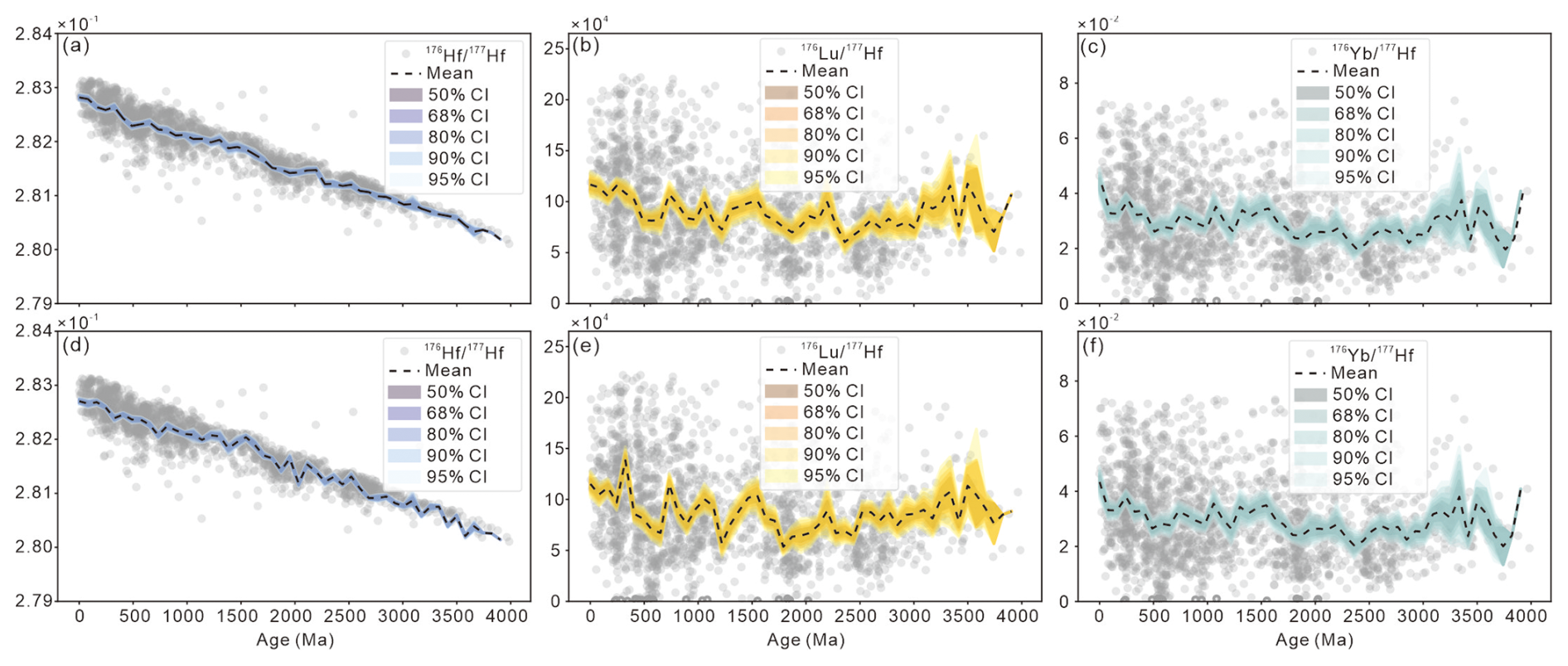
Figure 11Temporal variations of isotopic uncertainties in Lu-Hf dataset. (a) 176Hf 177Hf with bootstrap resampling; (b) 176Lu 177Hf with bootstrap resampling; (c) 176Yb 177Hf with Monte-Carlo resampling; (d) 176Hf 177Hf with Monte-Carlo resampling; (e) 176Lu 177Hf with Monte-Carlo resampling; (f) 176Yb 177Hf with Monte-Carlo resampling.
For Lu-Hf isotopes, the 176Hf 177Hf isotope decreases with the 176Lu 177Hf and 176Yb 177Hf isotopes showing periodic fluctuations (Fig. 11). The εHf(0) displays a continuous decline, while the εHf(t) peridocially fluctuates (Fig. 12).
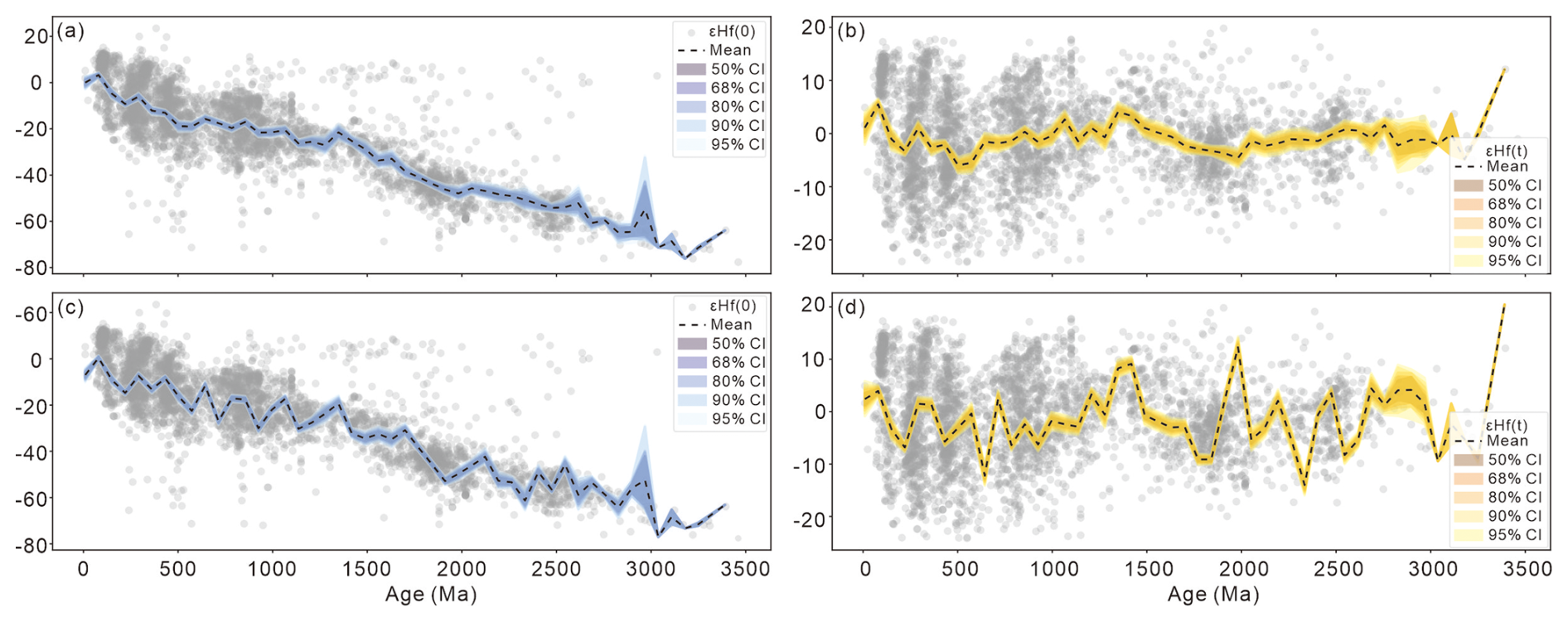
Figure 12Temporal variations of εHf uncertainties in Lu-Hf dataset. (a) εHf(0) with bootstrap resampling; (b) εHf(t) with bootstrap resampling; (c) εHf(0) with Monte-Carlo resampling; (d) εHf(t) with Monte-Carlo resampling.
5.1 Evaluate the paleo-spatial reconstruction
Despite the OneDZ database compiles comprehensive information about detrital zircon data, obvious oversampling bias exists in regions such East Asia due to disparities in research intensity and focus. This oversampling creates an imbalance and potentially leads to overrepresentations of regional samples.
For instance, the spatial analysis of the global zircon oxygen isotope record has shown that the temporal anomalies in zircon oxygen isotopes were predominantly attributed to regional samples' imbalance (Sundell et al., 2024). To address the issue of regional disparities in global zircon data analysis, Puetz et al. (2024b) introduced a method to assess global representativeness. This method involves overlaying a grid across the Earth's surface, dividing each item into discrete cells. The degree of global representativeness is then calculated by determining the ratio of the number of cells containing zircon data to the total number of cells in the grid. This approach allows for a quantitative measure of how well the zircon data cover different geographical regions. However, this evaluation approach is predicated on the present-day distribution of land and sea. In geological time scales, current geographical pattern does not accurately reflect the samples' spatial positions during the depositing period. To enhance the analysis of the spatiotemporal representativeness, we undertook a reconstruction based on the spatial distribution of detrital zircon U-Pb data. Utilizing tools such as pyGplate (Müller et al., 2018; Mather et al., 2024) and in situ block reconstruction methods (Jian et al., 2022), samples were reconstructed following the geohistorical spatial distribution (details can be seen in Sect. S4). As shown in Fig. 13, the scatter plot of reconstructed data shows that OneDZ covers almost all major continents in various periods of Earth's evolution. However, the spatial kernel density map in Fig. 13 re-evaluated the global representativeness of the data. In fact, as we delve into more ancient geological periods, the sampling locations tend to cluster around one or two ancient tectonic plates. This pattern is due to the fact that older zircon grains, which have undergone multiple episodes of sedimentary recycling (where the age difference between the zircon and the time of deposition exceeds 150 Ma), have been subject to significant transport and thus may not accurately represent the original paleogeographic context. Consequently, after approximately accounting for the effects of sedimentary recycling, the data from these ancient times are predominantly sourced from a limited number of locations, lacking global representativeness. Therefore, the evaluation of results based on OneDZ, indicate that the global scope of zircon big data research needs further assessment.
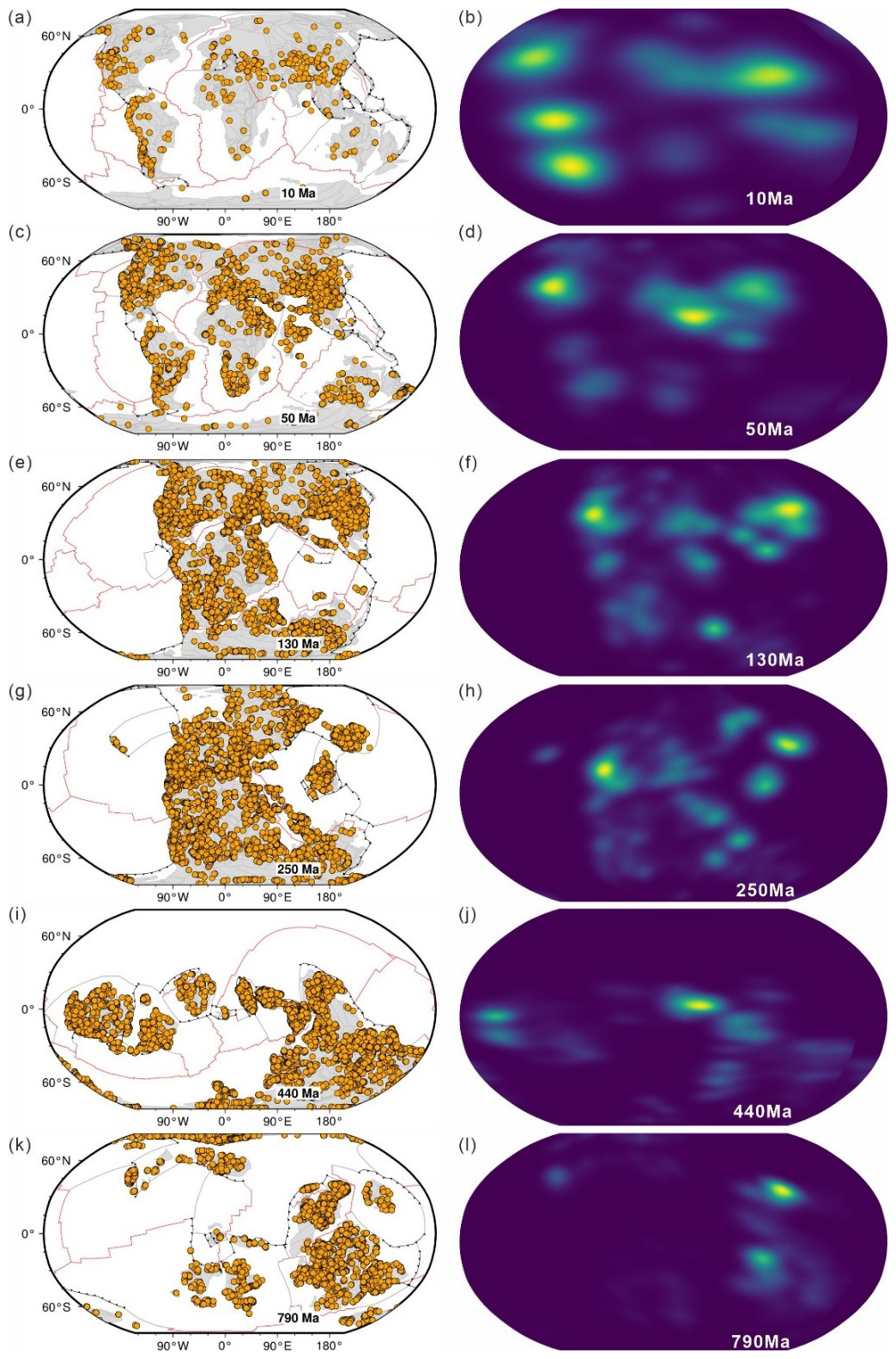
Figure 13Paleo-distributions and spatial kernel density estimate of U-Pb records (the tectonic model was from Merdith et al., 2021 and the temporal resolution is 1° × 1°). (a–b) Paleo-distribution and density of 10 Ma; (c–d) Paleo-distribution and density of 50 Ma; (e–f) Paleo-distribution and density of 130 Ma; (g–h) Paleo-distribution and density of 250 Ma; (i–j) Paleo-distribution and density of 440 Ma; (k–l) Paleo-distribution and density of 790 Ma.
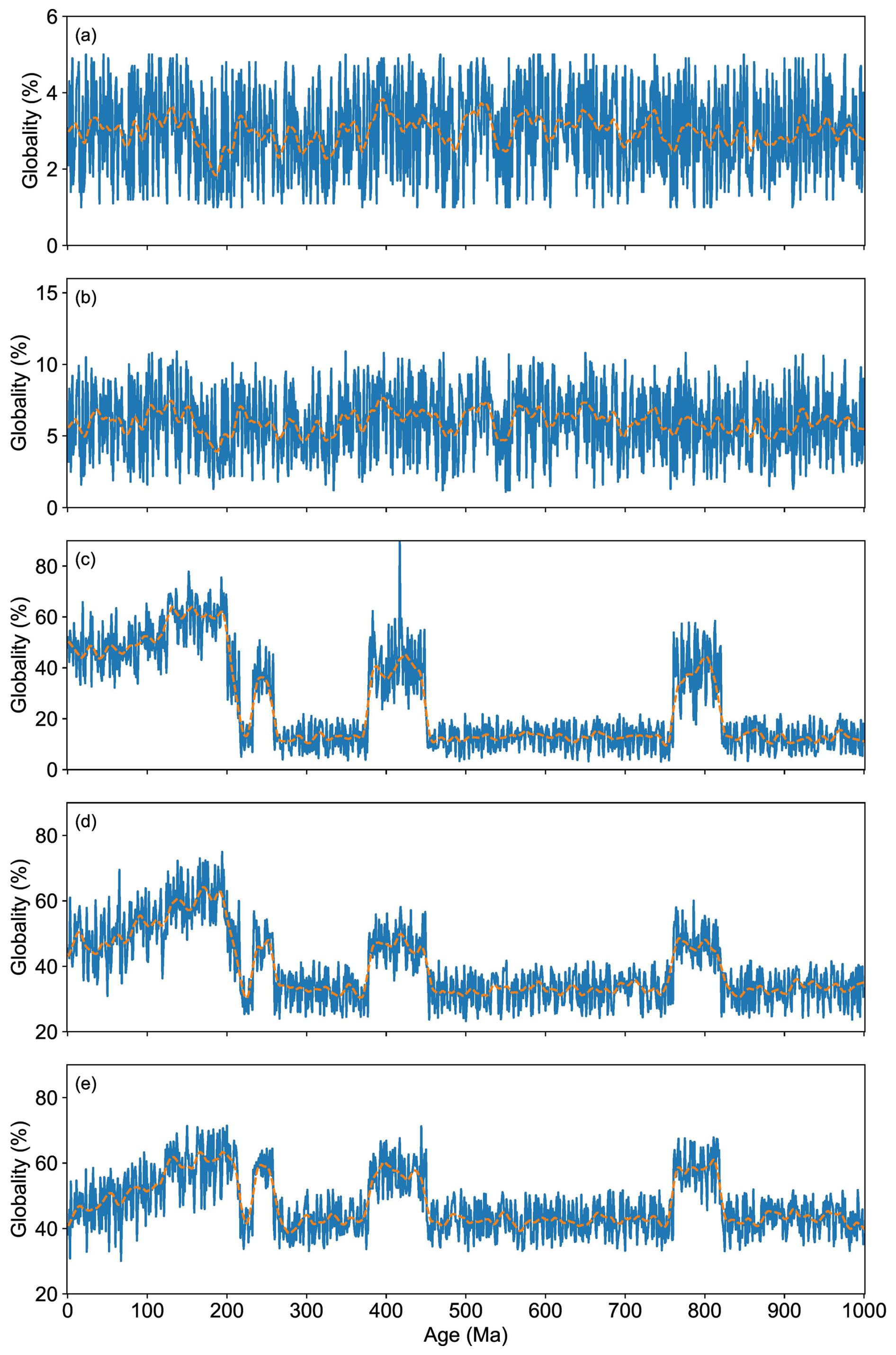
Figure 14Global evaluation of U-Pb data with different grid sizes. (a) 2°; (b) 4°; (c) 6°; (d) 8°; (e) 10°.
Following the new paleo-spatial reconstruction evaluating methods, the temporal globality of OneDZ detrital zircon U-Pb data was visualized in Fig. 14. Instead of no significant variation with 2 and 4° grids (Fig. 14a–b), the visualizations in Fig. 14c–e demonstrate that the U-Pb data has achieved spatial coverage across paleo-continents. A notable rise (14 %) in paleo-spatial reconstruction and valuable stability were observed when the grid size was enlarged from 6 to 10°. As the grid size increases, the spatial resolution of globality gradually decreases, resulting in a continuous increase in the calculated global representative values. The global representative value loses a significant amount of spatial detail when calculated at an excessively large scale. Similarly, small-scale grid calculation results in computational bias towards local detail information, leading to underestimation of the globality. After considering both local and global information, 6° is deemed suitable for evaluating the global representativeness of U-Pb data in the OneDZ database.
Figure 14c–e also show periodic peaks in globality coincides with specific geological eras. This phenomenon might be correlated with the heightened research interest in these periods. Samples from these periods are more likely to stimulate scientific inquiry due to the dynamic geological processes occurring at those times. Despite the large volume of data in OneDZ, the calculated paleo-spatial reconstruction does not fully represent global features for most geological times, as the reconstruction does not account for 100 % of the spatial details. For example, the sample distribution reconstructed for 250 Ma (as shown in Fig. 13g–h) appears to have global coverage. However, the calculated paleo-spatial reconstruction for this period only accounts for approximately 30 % to 60 % of the actual spatial distribution. Consequently, we recommend that regional data be handled with greater caution when interpreting global geological events. It is particularly important to employ spatial kernel density evaluation methods to ensure a more accurate representation of the data.
5.2 Compare the resampling methods
The temporal evolution of zircon U-Pb data is often analysed through big data methods and plays a crucial role in understanding the development of orogenic belts and crustal thickness. Big data methods with zircon U-Pb offer insights into Earth system evolution based on anomalies in time series data. Usually, the fluctuations in the curve are explained as the evolution of the Earth system. Not only is there a risk of data not being globally representative, but the zircon U-Pb curves obtained from big data analysis may also be statistically biased due to inconsistent data volumes. Some resampling statistical tools like Bootstrap and Monte-Carlo methods are applied in zircon big data analysis (Keller and Schoene, 2012; Yang et al., 2024, 2025). These methods have usually been assumed to be effective in previous studies. However, these resampling methods have not been systematically tested. The zircon U-Pb data in OneDZ, as the world's largest multidimensional imbalanced spatiotemporal dataset, provides a data foundation for comparing the effects when applying different resampling methods.
Firstly, we selected the best age data from zircon U-Pb data for time resampling experiments. In addition to comparing Bootstrap and Monte-Carlo resampling methods, we assessed the impact of data sparsity using the 2σ error to identify potential outliers and quantify the uncertainty. The experiment focuses on the sparsity of samples generated within the time range of zircon U-Pb ages exceeding 2500 Ma, with a threshold of 400 Ma. After time resampling using Monte-Carlo (Fig. 7d–f) and Bootstrap methods (Fig. 7g–i), the overall trend of zircon best age data is consistent. Even on time series after 2500 Ma, there was no significant difference in the characterization of evolutionary trends between the two resampling methods. However, there is a significant difference between the two methods in characterizing the details of a time series. In the 206Pb 238U isotope system, four periodic fluctuations were observed in the Monte-Carlo resampling results over the time period of 0–1000 Ma (Fig. 7d). The Bootstrap method only shows a slight increase around 500 Ma on the same time scale (Fig. 7g). The rest of the time scales show a slow increase. In the 207Pb 235U isotope system, the Monte-Carlo resampling results showed four small amplitude periodic fluctuations in the 0–2000 Ma time period under a generally slow rising background (Fig. 7e). The Bootstrap method showed a significant decrease around 1500 Ma on the same time scale (Fig. 7h). In the 207Pb 206U isotope system, the Monte-Carlo resampling results showed a significant decrease around 1500 Ma (Fig. 7f). In contrast, the Bootstrap method shows a periodic decrease (Fig. 7i), which differs from the more substantial decrease observed with other methods. Although Fig. 7 overall depicts the magnitude of age error over time in different systems and does not have practical geological significance, the significant differences in the time curves after resampling using Monte-Carlo and Bootstrap methods indicate the need for caution in interpreting data after applying resampling methods. Furthermore, we compared the results of time resampling methods for zircon U-Pb and Lu-Hf system time series data in OneDZ. In the analysis of zircon U-Pb data, the Bootstrap method demonstrates greater consistency over time (Fig. 10a–c), meaning that the results obtained using this method exhibit less variation across different time periods compared to other methods. The Monte-Carlo method is more sensitive to local data fluctuations than the Bootstrap method (Figs. S7–S9). The Monte Carlo method also shows significant oscillations on relatively sparse εHf(0) and εHf(t) and corresponding errors data (Fig. S7). The difference between Bootstrap and Monte Carlo methods will also disappear as the amount of data increases. In the 176Yb 177Hf 2σ error time series, due to the significant increase in data volume, the significant difference in the results of resampling methods is relatively little (Fig. S8). The above experimental time series data density statistics show that different resampling methods are actually controlled by data density and the areas where significant oscillations occur in the Monte-Carlo method coincide with areas with high data density (Figs. 10–11, S7–S9). Since standard Monte-Carlo time-resampling assumes that the underlying process is stationary (often approximated by normality or local uniformity, by Rubinstein and Kroese, 2016), it can yield biased estimates when the data density evolves sharply within the chosen window, which is a situation common in high-frequency zircon datasets. Consequently, more flexible, density-aware resampling strategies are preferred for zircon big-data analysis.
Spatial over-sampling introduces another potential bias that has gained attention in the field (Keller et al., 2018). Addressing this issue often involves spatial resampling methods, which were employed in this research using the OneDZ database. Initially, Monte Carlo spatial resampling was used to assess the frequency at which samples are selected (Keller et al., 2018). Ideally, a balanced spatial sampling should achieve equal total sampling frequencies across regions, increasing the likelihood of sampling from underrepresented areas. Our findings suggest that direct application of the Monte-Carlo method does not mitigate sampling bias. Samples from East Asia, particularly China, remain overrepresented due to the large volume of available data from this region, skewing the overall data distribution and leaving other regions sparsely represented, similar to the observed sample sparsity in the temporal domain (Fig. 15a). To counteract the hypothesis, we explored data augmentation methods to generate new data points in under-sampled regions. This study introduces the Synthetic Minority Over-sampling Technique (SMOTE, Chawla et al., 2002) to create synthetic data points from regions other than China while preserving the same data features. Applying SMOTE led to a significant increase in resampling frequency in these regions (Fig. 15b). Inspired by grid-based methods, we also pre-processed the data by averaging the U-Pb age signals before applying SMOTE. This novel approach enhanced resampling frequency in previously under-sampled regions, resulting in the sampling differences in different regions to significantly reduce (Fig. 15c). Direct spatial resampling methods may not adequately resolve spatial imbalances. However, combining these methods with data enhancement techniques and grid-based approaches can significantly mitigate spatial biases.
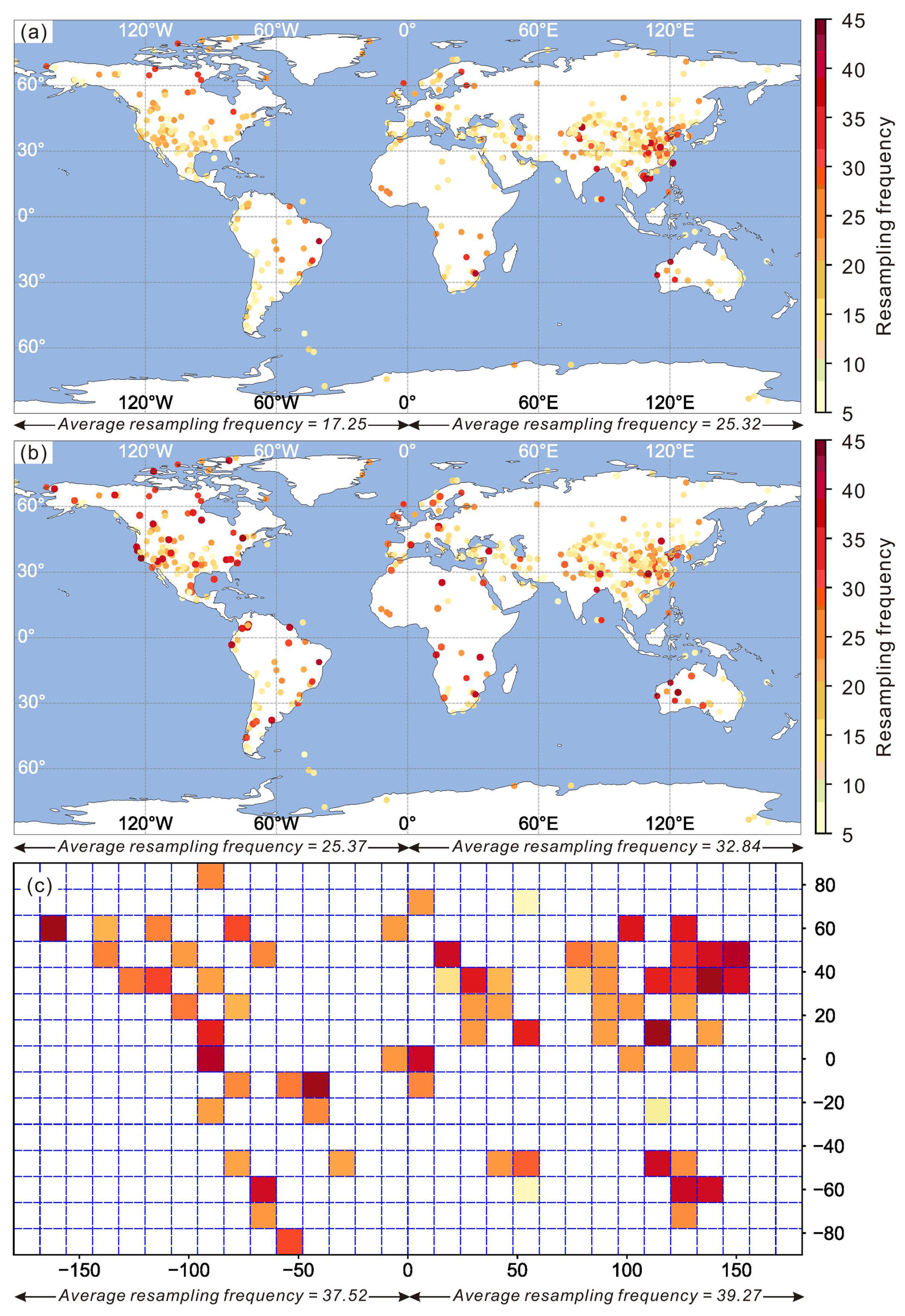
Figure 15The resampling frequency of different methods. (a) Monte-Carlo method; (b) SMOTE-Monte-Carlo method; (c) 12° × 12° grid-SMOTE-Monte-Carlo method.
5.3 Implications for database construction and future developments
The compilation of the OneDZ dataset, which employs a crowdfunding approach, has the potential to significantly broaden data coverage (comparison with other databases can be seen in Fig. S10). However, crowdfunding introduces challenges, such as inconsistencies in data formatting and the risk of human errors. To address these issues, a series of Python scripts for automated data cleaning and inspection were developed. These scripts have successfully replaced labor-intensive manual inspections, reducing both labor costs and the potential for data errors. From the OneDZ compilation process, crowdfunding combined with automatic data cleaning by Python code snippets is feasible and greatly improved the efficiency of dataset assembly.
Moreover, AI tools have played a pivotal role in the data collection and extraction process. Unlike traditional web crawlers, which can pose privacy risks, AI models can predict whether an article may contain the required database features based on publicly available text information, such as titles and abstracts. The integration of AI models into the database construction process eliminates the need for manual screening of potential articles, significantly improving efficiency. Additionally, computer vision tools like DeepShovel are crucial, as a considerable amount of article data is stored in PDF image files in the form of tables. Manual reading and data storage are not sustainable approaches for handling such large volumes of data. Computer vision-based AI models show great promise in reducing labor costs and increasing efficiency.
As of the current submission, the number of U-Pb entries in this dataset has increased from approximately 1.8 million in the initial preprint to 2.5 million, suggesting that eliminating manual data organization and template-based input substantially encourages community contributions. However, this rapid expansion introduces notable challenges in data quality and source relevance. Although agents demonstrate high efficiency in extracting data from heterogeneous source files, including manuscript PDFs and supplementary materials in Word, Excel, or PDF formats (Fig. S11), the automated workflow occasionally yields extraction errors, making manual verification indispensable (Sect. S5). Nevertheless, given the time-intensive nature of meticulous checking, verified records remain at 1.5 million, considerably fewer than the total collected entries, which necessitates clearly distinguishing checked and unchecked records upon publication and explicitly cautioning users regarding unchecked data. Moreover, without template constraints, users may upload arbitrary PDF files unrelated to detrital zircon studies, prompting the deployment of an independent classification agent to assess file relevance, whereby over five thousand irrelevant publications, such as those concerning magmatic or granitic zircons and general geochemical articles, were identified and filtered during our experiments (Fig. S12). Therefore, integrating large language models into database construction does not inherently reduce manual labor but rather demands additional human oversight to ensure data quality and reliability.
Future work will focus on refining the automated extraction pipelines and expanding community-contributed data coverage, rather than on developing custom web portals.
The complete OneDZ dataset (Li et al., 2026) is freely available as flat CSV files via Zenodo at https://doi.org/10.5281/zenodo.19690702. The release includes 22 sequential CSV parts for the full U-Pb compilation (2 550 738 records, 64 standardised columns), 3 parts for the Lu-Hf compilation (297 527 records, 33 standardised columns), and 14 parts for the expert-verified U-Pb subset (1 414 062 records). All files use UTF-8 encoding with comma delimiters and a single header row, enabling direct ingestion without database infrastructure. For users who prefer to import the data into relational database environments, an archived SQL dump of the same dataset is separately available at https://doi.org/10.5281/zenodo.17407937 (Li et al., 2025) (this is not required to access or use the data). Python code snippets for data cleaning and harmonisation used in this research are accessible via https://github.com/KeranLi/Global-Detrital-Zircon (last access: 11 May 2026). For researchers who wish to replicate the LLM-driven extraction workflow, the original data sources and agent outputs are accessible at https://doi.org/10.5281/zenodo.19691004 (Li, 2026), and the corresponding code snippets are available at https://github.com/KeranLi/onedz_llm_coding (last access: 11 May 2026).
In this study, we introduce a ground-breaking global detrital zircon U-Th-Pb geochronology and Lu-Hf isotope database, which serves as a critical resource for advancing Earth science research. This database includes 2 550 738 U-Pb and 297 527 Lu-Hf records, offering a broad sampling range from global detrital rocks. The database offers an extensive and diverse collection of data, including various types of stratigraphic information, a broad range of sedimentary ages, comprehensive isotope geochemical datasets, and data from multiple analytical techniques such as LA-ICP-MS, SHRIMP, SIMS, and TIMS.
Based on this database, we have characterized the uncertainties associated with zircon dating, compared the efficacy of different analytical techniques, proposed an evaluation method that assesses the deep-time global coverage of the data and discussed the challenges and potential solutions related to spatiotemporal sampling methods. Although the data is globally sourced, variations in spatial and temporal distribution can affect its global representativeness. Therefore, when conducting big data analyses on spatial or temporal distributions, reconstructing data's paleo-points is necessary. In imbalanced spatiotemporal data resampling methods, Bootstrap methods and SMOTE data augmentation methods may be more suitable.
The development of OneDZ demonstrates that leveraging crowdfunding, large language models, and automated code cleaning processes is essential for the rapid assembly of a comprehensive geoscience dataset. By distributing the final product as standardised, flat CSV files via Zenodo, we ensure that the data are immediately accessible to any researcher without requiring proprietary database software or custom web interfaces. Furthermore, integrating AI tools and scripting workflows enhances both the efficiency of data extraction and the reliability of harmonised outputs, making large-scale compilations more reproducible and transparent.
The supplement related to this article is available online at https://doi.org/10.5194/essd-18-3671-2026-supplement.
KL, XH, RC, JH, WX, YP, AM, HH, QG, WY, LH, LQ, GC, GS, SZ, TD, KL, JS and BG compiled the data. KL, RC and WX merged the data, formatted the data, performed the analyses, standardized the reference materials, organized the database, managed the publication of the database in the Zenodo repository, and drafted and revised the manuscript. KL designed the code snippets. TL and CF developed the web platform. HX initiated and supported the data compilation.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. The authors bear the ultimate responsibility for providing appropriate place names. Views expressed in the text are those of the authors and do not necessarily reflect the views of the publisher.
The authors would thank S. J. Puetz and Y. Wu and their colleagues for establishing 1.2 million detrital zircon database and Chinese zircon database. We thank the sedimentary group members in IUGS Deep-time Digital Earth (DDE) Big Science Program for their assistance in collecting and cleaning detrital zircon data in China. The related sub database research has been published in the special issue of the Geoscience Data Journal in 2024. This work was financially supported by the National Natural Science Foundation of China (42142004). This paper contributes to the IUGS “Deep-time Digital Earth” Big Science Program. This paper got support from high performance computing center, Nanjing University in reconstructing the paleo-locations of records.
This research has been supported by the National Natural Science Foundation of China, Key Programme (grant no. 42142004).
This paper was edited by Kirsten Elger and reviewed by Bryant Ware and one anonymous referee.
Barham, M., Kirkland, C. L., and Hollis, J.: Spot the difference: Zircon disparity tracks crustal evolution, Geology, 47, 435–439, https://doi.org/10.1130/G45840.1, 2019.
Barham, M., Kirkland, C. L., and Hollis, J.: Understanding ancient tectonic settings through detrital zircon analysis, Earth Pl. Sc. Lett., 590, 117580, https://doi.org/10.1016/j.epsl.2022.117580, 2022.
Cao, W., Lee, C.-T. A., and Lackey, J. S.: Episodic nature of continental arc activity since 750 Ma: A global compilation, Earth Pl. Sc. Lett., 474, 160–165, https://doi.org/10.1016/j.epsl.2017.06.040, 2017.
Cawood, P. A.: Earth matters: a tempo to our planet's evolution, Geology, 48, 525–526, https://doi.org/10.1130/focus052020.1, 2020.
Cawood, P. A., Hawkesworth, C. J., and Dhuime, B.: Detrital zircon record and tectonic setting, Geology, 40, 875–878, https://doi.org/10.1130/G32945.1, 2012.
Chai, R., Yang, J., Deng, T., and Hu, X.: A detrital zircon dataset for the eastern Central China Orogenic Belt (East Qinling, Dabie and Sulu orogens), Geosci. Data J., 11, 562–572, https://doi.org/10.12297/dpr.dde.202212.3, 2023.
Chawla, N. V., Bowyer, K. W., Hall, L. O., and Kegelmeyer, W. P.: SMOTE: synthetic minority over-sampling technique, J. Artif. Intell. Res., 16, 321–357, https://doi.org/10.1613/jair.953, 2002.
Chen, G., Li, C., Shi, Y., and Zha, K.: A synthesis of available detrital zircon data from Turkey, Cyprus and Greek peninsula, Geosci. Data J., 11, 137–147, https://doi.org/10.1002/gdj3.216, 2023a.
Chen, X., Wang, P., Xie, H., Zhu, L., Liao, X., and Kong, X.: Detrital zircon U-Pb ages and Hf isotope analyses of modern and Quaternary sediments in China: A new dataset with preliminary analysis, Geosci. Data J., 11, 374–384, https://doi.org/10.1002/gdj3.193, 2023b.
Cheng, Q.: Singularity analysis of global zircon U-Pb age series and implication of continental crust evolution, Gondwana Res., 51, 51–63, https://doi.org/10.1016/j.gr.2017.07.011, 2017.
Chu, X., Ilyas, I. F., Krishnan, S., and Wang, J.: Data cleaning: Overview and emerging challenges, in: Proceedings of the 2016 international conference on management of data, 2201–2206, https://doi.org/10.1145/2882903.2912574, 2016.
Compston, W., Williams, I. S., and Meyer, C. E.: U-Pb geochronology of zircons from lunar breccia 73217 using a sensitive high mass-resolution ion microprobe, J. Geophys. Res., 89, B525–B534, https://doi.org/10.1029/JB089iS02p0B525, 1984.
Deng, C., Jia, Y., Xu, H., Zhang, C., Tang, J., Fu, L., Zhang, W., Zhang, H., Wang, X., and Zhou, C.: GAKG: A multimodal geoscience academic knowledge graph, in: Proceedings of the 30th ACM International Conference on Information and Knowledge Management, 535, 4445–4454, https://doi.org/10.1145/3459637.3482003, 2021.
Dong, Y., Zuo, P., Xiao, Z., Zhao, Y., Zheng, D., Sun, F., and Li, Y.: A database of detrital zircon U-Pb ages in the North China Craton from the Paleoproterozoic to the early Palaeozoic, Geosci. Data J., 11, 365–373, https://doi.org/10.1002/gdj3.192, 2023.
Fedo, C. M., Sircombe, K. N., and Rainbird, R. H.: Detrital zircon analysis of the sedimentary record, Rev. Mineral. Geochem., 53, 277–303, https://doi.org/10.2113/0530277, 2003.
Gehrels, G.: Detrital zircon U-Pb geochronology applied to tectonics, Annu. Rev. Earth Pl. Sc., 42, 127–149, https://doi.org/10.1146/annurev-earth-050212-124012, 2014.
Gehrels, G. E., Valencia, V. A., and Ruiz, J.: Enhanced precision, accuracy, efficiency, and spatial resolution of U-Pb ages by laser-ablation–multicollector–inductively coupled plasma–mass spectrometry, Geochem. Geophy. Geosy., 9, Q03017, https://doi.org/10.1029/2007GC001805, 2008.
Guo, Z., Wang, C., Zhou, J., Zheng, G., Wang, X., and Zhou, C.: GeoKnowledgeFusion: A Platform for multimodal data compilation from geoscience literature, Remote Sens., 16, 1484, https://doi.org/10.3390/rs16091484, 2024.
He, W., Sun, J., Dong, Y., Qian, T., Wang, T., He, L., and Qi, Y.: A synthesis of available detrital zircon data from the Qilian-Qaidam-Kunlun collage, northern Tibet, Geosci. Data J., 11, 465–478, https://doi.org/10.1002/gdj3.225, 2023.
Hellerstein, J. M.: Quantitative data cleaning for large databases, United Nations Econ. Comm. Eur. (UNECE), 25, 1–42, https://dsf.berkeley.edu/jmh/papers/cleaning-unece.pdf (last access: 21 May 2026), 2008.
Hellerstein, J. M.: Quantitative data cleaning for large databases, http://db.cs.berkeley.edu/jmh (last access: 21 May 2026), 2013.
Horstwood, M. S. A., Košler, J., Gehrels, G., Jackson, S. E., McLean, N. M., Paton, C., Pearson, N. J., Sircombe, K., Sylvester, P., Vermeesch, P., Bowring, J. F., Condon, D. J., and Schoene, B.: Community-derived standards for LA-ICP-MS U-(Th-)Pb geochronology—Uncertainty propagation, age interpretation and data reporting, Geostand. Geoanal. Res., 40, 311–332, https://doi.org/10.1111/j.1751-908X.2016.00379.x, 2016.
Hu, X. M., Xu, Y. W., Ma, X. G., Zhu, Y. Q., Ma, C., Li, C., Lü, H. R., Wang, X. B, Zhou, C. H., and Wang, C. S.: Knowledge System, Ontology, and Knowledge Graph of the Deep-Time Digital Earth (DDE): Progress and Perspective, J. Earth Sci., 34, 1323–1327, https://doi.org/10.1007/s12583-023-1930-1, 2023.
Huang, Y. and Hu, L.: A database of detrital zircon U–Pb ages and Lu–Hf isotope of sediments in the South China Sea, Geosci. Data J., 11, 433–442, https://doi.org/10.1002/gdj3.218, 2023.
Jackson, S. E., Pearson, N. J., Griffin, W. L., and Belousova, E. A.: The application of laser ablation-inductively coupled plasma-mass spectrometry to in situ U-Pb zircon geochronology, Chem. Geol., 211, 47–69, https://doi.org/10.1016/j.chemgeo.2004.06.017, 2004.
Jaffey, A., Flynn, K., Glendenin, L., Bentley, W. T., and Essling, A.: Precision measurement of half-lives and specific activities of 235U and 238U, Phys. Rev. C, 4, 1889–1906, https://doi.org/10.1103/PhysRevC.4.1889, 1971.
Jarvis, K. E.: Inductively coupled plasma mass spectrometry: a new technique for the rapid or ultra-trace level determination of the rare-earth elements in geological materials, Chem. Geol., 68, 31–39, 1988.
Jian, D., Williams, S. E., Yu, S., and Zhao, G.: Quantifying the link between the detrital zircon record and tectonic settings, J. Geophys. Res.-Sol. Ea., 127, e2022JB024606, https://doi.org/10.1029/2022JB024606, 2022.
Keller, C. B. and Schoene, B.: Statistical geochemistry reveals disruption in secular lithospheric evolution about 2.5 Gyr ago, Nature, 485, 490–493, https://doi.org/10.1038/nature11024, 2012.
Keller, C. B., Schoene, B., and Samperton, K. M.: A stochastic sampling approach to zircon eruption age interpretation, Geochem. Perspect. Lett., 8, 31–35, https://doi.org/10.7185/geochemlet.1826, 2018
Kinny, P. D. and Mass, R.: Lu–Hf and Sm–Nd isotope systems in zircon, Rev. Miner. Geochem., 53, 327–341, https://doi.org/10.2113/0530327, 2003.
Krogh, T.: A low-contamination method for hydrothermal decomposition of zircon and extraction of U and Pb for isotopic age determinations, Geochim. Cosmochim. Ac., 37, 485–494, https://doi.org/10.1016/0016-7037(73)90213-5, 1973.
Krumbein, W. C.: Size frequency distributions of sediments and the normal phi curve, J. Sediment. Petrol., 8, 84–90, https://doi.org/10.1306/D4268EDB-2B26-11D7-8648000102C1865D, 1938.
Li, K.: Data source for LLM-driven agents part for “OneDZ: A Global Detrital Zircon Database and Implications for Constructing Giant Geoscience Database”, Zenodo [data set], https://doi.org/10.5281/zenodo.19691004, 2026.
Li, K., Hu, X., Chai, R., Yang, J., Xue, W., Pan, Y., Li, T., Fang, C., Ma, A., Huang, H., Guo, Q., Yang, W., Hu, L., Qi, L., Chen, G., Sun, G., Zhang, S., Deng, T., Li, K., and Gao, B.: OneDZ: A Global Detrital Zircon Database and Implications for Constructing Giant Geoscience Database, Zenodo [data set], https://doi.org/10.5281/zenodo.17407937, 2025.
Li, K., Hu X., Chai R., Yang J., Xue W., Pan Y., Li T., Fang, C., Ma, A., Huang, H., Guo, Q., Yang, W., Hu, L., Qi, L., Chen, G., Sun, G., Zhang, S., Deng, T., Li, K., Sun, J., and Gao, B.: OneDZ: A Global Detrital Zircon Database and Implications for Constructing Giant Geoscience Database, Zenodo [data set], https://doi.org/10.5281/zenodo.19690702, 2026.
Lu, B., Wu, L., Yang, L., Sun, C., Liu, W., Gan, X., Liang, S., Fu, L., Wang, X., and Zhou, C.: DataExpo: A One-Stop Dataset Service for Open Science Research, in: Companion Proceedings of the ACM Web Conference 2023, 32–36, https://doi.org/10.1145/3543873.3587305, 2023.
Ludwig, K. R.: User's Manual for Isoplot 3.00: A Geochronological Toolkit for Microsoft Excel, Berkeley Geochronology Center Special Publication No. 4, 2003.
Luo, C., Qi, L., and Xia, T.: A database of detrital zircon U–Pb ages and Hf isotope of Precambrian strata in South China, Geosci. Data J., 11, 385–393, https://doi.org/10.1002/gdj3.194, 2023.
Martin, E. L., Barrote, V. R., and Cawood, P. A.: A resource for automated search and collation of geochemical datasets from journal supplements, Sci. Data, 9, 724, https://doi.org/10.1038/s41597-022-01730-7, 2022.
Mather, B. R., Müller, R. D., Zahirovic, S., Cannon, J., Chin, M., Ilano, L., Wright, N. M., Alfonso, C., Williams, S., Tetley, M., and Merdith, A.: Deep time spatio-temporal data analysis using pyGPlates with PlateTectonicTools and GPlately, Geosci. Data J., 11, 3–10, https://doi.org/10.1002/gdj3.185, 2024.
McKenzie, N. R., Horton, B. K., Loomis, S. E., Stocklli, D. F., Planavsky, N. J., and Lee, C. A.: Continental arc volcanism as the principal driver of icehouse-greenhouse variability, Science 352, 444–447, https://doi.org/10.1126/science.aad5787, 2016.
Merdith, A. S., Williams, S. E., Collins, A. S., Tetley, M. G., Mulder, J. A., Blades, M. L., Young, A., Armistead, S. E., Cannon, J., Zahirovic, S., and Müller, R. D.: Extending full-plate tectonic models into deep time: Linking the Neoproterozoic and the Phanerozoic, Earth-Sci. Rev., 214, 103477, https://doi.org/10.1016/j.earscirev.2020.103477, 2021.
Müller, R. D., Cannon, J., Qin, X., Watson, R. J., Gurnis, M., Williams, S., Pfaffelmoser, T., Seton, M., Russell, S. H., and Zahirovic, S.: GPlates: Building a virtual Earth through deep time, Geochem. Geophy. Geosy., 19, 2243–2261, https://doi.org/10.1029/2018GC007584, 2018.
Odlum, M. L., Capaldi, T. N., Thomson, K. D., and Stockli, D. F.: Tracking cycles of Phanerozoic opening and closing of ocean basins using detrital rutile and zircon geochronology and geochemistry, Geology, 52, 357–361, https://doi.org/10.1130/G51826.1, 2024.
Pan, Y. and Hu, X.: A database of detrital zircon U–Pb geochronology and Hf isotopes from the Songpan–Ganzi and Western Qinling terranes, Geosci. Data J., 11, 394–404, https://doi.org/10.1002/gdj3.195, 2023.
Patchett, P. J.: Importance of the Lu-Hf isotopic system in studies of planetary chronology and chemical evolution, Geochim. Cosmochim. Ac., 47, 81–91, https://doi.org/10.1016/0016-7037(83)90092-3, 1983.
Patchett, P. J. and Tatsumoto, M.: A routine high–precision method for Lu–Hf isotope geochemistry and chronology, Contrib. Miner. Petrol., 75, 263–267, https://doi.org/10.1007/BF01166766, 1981.
Puetz, S. J. and Condie, K. C.: Time series analysis of mantle cycles Part I: Periodicities and correlations among seven global isotopic databases, Geosci. Front., 10, 1305–1326, https://doi.org/10.1016/j.gsf.2019.04.002, 2019.
Puetz, S. J., Spencer, C. J., and Ganade, C. E.: Analyses from a validated global U-Pb detrital zircon database: Enhanced methods for filtering discordant U-Pb zircon analyses and optimizing crystallization age estimates, Earth-Sci. Rev., 220, 103745, https://doi.org/10.1016/j.earscirev.2021.103745, 2021.
Puetz, S. J., Condie, K. C., Sundell, K., Roberts, N. M., Spencer, C. J., Boulila, S., and Cheng, Q.: The replication crisis and its relevance to Earth Science studies: Case studies and recommendations, Geosci. Front., 15, 101821, https://doi.org/10.1016/j.gsf.2024.101821, 2024a.
Puetz, S. J., Spencer, C. J., Condie, K. C., and Roberts, N. M.: Enhanced U-Pb detrital zircon, Lu-Hf zircon, δ18O zircon, and Sm-Nd whole rock global databases, Sci. Data, 11, 56, https://doi.org/10.1038/s41597-023-02902-9, 2024b.
Rubinstein, R. Y. and Kroese, D. P.: Simulation and the Monte Carlo method, John Wiley and Sons, https://doi.org/10.1002/9781118631980, 2016.
Saylor, J. E. and Sundell, K. E.: Quantifying comparison of large detrital geochronology data sets, Geosphere, 12, 203–220, https://doi.org/10.1130/GES01237.1, 2016.
Schaltegger, U., Schmitt, A. K., and Horstwood, M. S. A.: U-Th-Pb zircon geochronology by ID-TIMS, SIMS, and laser ablation ICP-MS: Recipes, interpretations, and opportunities, Chem. Geol., 402, 89–110, https://doi.org/10.1016/j.chemgeo.2015.02.028, 2015.
Scherer, E., Münker, C., and Mezger, K.: Calibration of the lutetium-hafnium clock, Science, 293, 683–687, 2001.
Sharman, G. R., Sharman, J. P., and Sylvester, Z.: detritalPy: A Python-based toolset for visualizing and analysing detrital geo-thermochronologic data, Depos. Rec., 4, 202–215, https://doi.org/10.1002/dep2.45, 2018.
Söderlund, U., Patchett, P. J., Vervoort, J. D., Isachsen, C. E.: The 176Lu decay constant determined by Lu–Hf and U–Pb isotope systematics of Precambrian mafic intrusions, Earth Planet. Sc. Lett., 219, 311–324, https://doi.org/10.1016/S0012-821X(04)00012-3, 2004.
Sun, G. and Chen, J.: A database of detrital zircon U–Pb ages and Hf isotopes for the Middle East (Iranian and Arabian plates), Geosci. Data J., 11, 107–117, https://doi.org/10.1002/gdj3.187, 2023.
Sundell, K. E., Macdonald, F. A., and Puetz, S. J.: Does zircon geochemistry record global sediment subduction?, Geology, 52, 282–286, https://doi.org/10.1130/G51817.1, 2024.
Taylor, S. R. and McLennan, S. M.: The continental crust: its composition and evolution, Black well Scientific Publications, Oxford, 1–328, https://commons.library.stonybrook.edu/geo-articles/12/ (last access: 21 May 2026), 1985.
Udden, J. A.: Mechanical composition of clastic sediments, Bull. Geol. Soc. Am., 25, 655–744, https://doi.org/10.1130/GSAB-25-655, 1914.
Vermeesch, P.: IsoplotR: A free and open toolbox for geochronology, Geosci. Front., 9, 1479–1493, https://doi.org/10.1016/j.gsf.2018.04.001, 2018.
Voice, P. J., Kowalewski, M., and Eriksson, K. A.: Quantifying the timing and rate of crustal evolution: Global compilation of radiometrically dated detrital zircon grains, J. Geol., 119, 109–126, https://doi.org/10.1086/658295, 2011.
Wang, L., Huo, N., Jiang, G., Han, C., Sun, J., and Huang, H.: Detrital zircon U–Pb and Hf isotopic dataset for the Central Asian Orogenic Belt, northern China, Geosci. Data J., 11, 426–432, https://doi.org/10.1002/gdj3.214, 2023.
Wang, W., Pei, Y., Cheng, Q., and Wang, W.: Local singularity spectrum: An innovative graphical approach for analyzing detrital zircon geochronology data in provenance analysis, Fractal Fract., 8, 64, https://doi.org/10.3390/fractalfract8010064, 2024.
Wentworth, C. K.: A scale of grade and class terms for clastic sediments, J. Geol., 30, 377–392, https://doi.org/10.1086/622910, 1922.
Wu, Y., Fang, X., and Ji, J.: A global zircon U–Th–Pb geochronological database, Earth Syst. Sci. Data, 15, 5171–5181, https://doi.org/10.5194/essd-15-5171-2023, 2023.
Xia, T., Li, K., Hu, L., Zhao, Z., Huang, Y., Ma, Q., and Qi, L.: A database of detrital zircon geochronology ages of Cambrian to Paleogene deposits in South China, Geosci. Data J., 11, 405–413, https://doi.org/10.1002/gdj3.196, 2023.
Xue, W. W., Hu, X. M., Garzanti, E., Ma, A. L., Lai, W., and Li, C.: Discriminating Qiangtang, Lhasa, and Himalayan sediment sources in the Tibetan Plateau by detrital-zircon U-Pb age and Hf isotope facies, Earth-Sci. Rev., 236, 104271, https://doi.org/10.1016/j.earscirev.2022.104271, 2023.
Yang, W., Li, Q., Yang, J., Fang, T., and Ma, R.: Dataset of detrital zircon U–Pb ages and Hf isotopic compositions for the late Paleozoic–Mesozoic strata in the North China block, Geosci. Data J., 11, 414–425, https://doi.org/10.1002/gdj3.211, 2023.
Yang, X., Zhang, Z., Zhou, Y., and Yang, J.: Spatio-temporal analysis of Permian-Cretaceous magmatic activities in the Tengchong block: Implications for tectono-magmatic evolution, Geosci. Front., 15, 101920, https://doi.org/10.1016/j.gsf.2024.101920, 2024.
Yang, X., Zhang, Z., Zhou, Y., Yang, J., and Wang, Y.: Decoding the geological evolution of Tengchong Block: A big data analysis of zircon from the Late Permian to Early Cretaceous, Tectonics, 44, e2025TC008882, https://doi.org/10.1029/2025TC008882, 2025.
Zhang, S., Jia, Y., Xu, H., Wang, D., Li, T. J.-J., Wen, Y., Wang, X., and Zhou, C.: KnowledgeShovel: An AI-in-the-Loop Document Annotation System for Scientific Knowledge Base Construction, arXiv [preprint], https://doi.org/10.48550/arXiv.2210.02830, 2022a.
Zhang, S., Jia, Y., Xu, H., Wen, Y., Wang, D., and Wang, X.: Deepshovel: An online collaborative platform for data extraction in geoscience literature with ai assistance, arXiv [preprint], https://doi.org/10.48550/arXiv.2202.10163, 2022b.
Zhang, S., Hu, X., Zhang, J., Li, Q., Xu, Y., Yu, Y., and Han, L.: A database of detrital zircon U–Pb ages and Hf isotopic compositions from the Tarim, West Kunlun, Pamir, Tajik and Tianshuihai terranes, Geosci. Data J., 11, 118–127, https://doi.org/10.1002/gdj3.213, 2023a.
Zhang, S., Xu, H., Jia, Y., Wen, Y., Wang, D., Fu, L., Wang, X., and Zhou, C.: GeoDeepShovel: A platform for building scientific database from geoscience literature with AI assistance, Geosci. Data J., 10, 519–537, https://doi.org/10.1002/gdj3.186, 2023b.
Zhang, Z.: Spatio-temporal analysis of big data sets of detrital zircon U-Pb geochronology and Hf isotope data: Tests of tectonic models for the Precambrian evolution of the North China Craton, Earth-Sci. Rev., 239, 104372, https://doi.org/10.1016/j.earscirev.2023.104372, 2023.