the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 30 Mar 2022
| 30 Mar 2022
TimeSpec4LULC: a global multispectral time series database for training LULC mapping models with machine learning
Rohaifa Khaldi
Domingo Alcaraz-Segura
Emilio Guirado
Yassir Benhammou
Abdellatif El Afia
Francisco Herrera
Siham Tabik
Land use and land cover (LULC) mapping are of paramount importance to monitor and understand the structure and dynamics of the Earth system. One of the most promising ways to create accurate global LULC maps is by building good quality state-of-the-art machine learning models. Building such models requires large and global datasets of annotated time series of satellite images, which are not available yet. This paper presents TimeSpec4LULC (https://doi.org/10.5281/zenodo.5913554; Khaldi et al., 2022), a smart open-source global dataset of multispectral time series for 29 LULC classes ready to train machine learning models. TimeSpec4LULC was built based on the seven spectral bands of the MODIS sensors at 500 m resolution, from 2000 to 2021, and was annotated using spatial–temporal agreement across the 15 global LULC products available in Google Earth Engine (GEE). The 22-year monthly time series of the seven bands were created globally by (1) applying different spatial–temporal quality assessment filters on MODIS Terra and Aqua satellites; (2) aggregating their original 8 d temporal granularity into monthly composites; (3) merging Terra + Aqua data into a combined time series; and (4) extracting, at the pixel level, 6 076 531 time series of size 262 for the seven bands along with a set of metadata: geographic coordinates, country and departmental divisions, spatial–temporal consistency across LULC products, temporal data availability, and the global human modification index. A balanced subset of the original dataset was also provided by selecting 1000 evenly distributed samples from each class such that they are representative of the entire globe. To assess the annotation quality of the dataset, a sample of pixels, evenly distributed around the world from each LULC class, was selected and validated by experts using very high resolution images from both Google Earth and Bing Maps imagery. This smartly, pre-processed, and annotated dataset is targeted towards scientific users interested in developing various machine learning models, including deep learning networks, to perform global LULC mapping.
- Article
(4884 KB) - Full-text XML
- BibTeX
- EndNote





Broadly, land cover (LC) refers to the different vegetation types (usually following biotype, plant functional type, or physiognomy schemes, such as forests, shrublands, or grasslands) or other biophysical classes (such as water bodies, snow, or bare soil) that cover the Earth's surface (Moser, 1996). Land cover is an essential variable that provides powerful insights for the assessment and modeling of terrestrial ecosystem processes, biogeochemical cycles, biodiversity, climate, and water resources, among others (Luoto et al., 2007; Menke et al., 2009; Polykretis et al., 2020), whereas land use (LU) incorporates many types of modifications that an increasing human population, more than 9 billion expected by 2050, causes to the LC (such as urban areas and croplands). Accurate LULC information, including distribution, dynamics, and changes, is of paramount importance for understanding and modeling the natural and human-modified behavior of the Earth's system (Tuanmu and Jetz, 2014; Verburg et al., 2009).
LULCs are subjected to anomalies, trends, and changes both from anthropogenic and natural origins (Polykretis et al., 2020). LULC change is usually interpreted as the conversion from one LULC category to another and/or the modification of land management within LULC (Meyer and Turner, 1994). LULC is an essential climate and biodiversity variable (Bojinski et al., 2014; Pettorelli et al., 2016) to model and assess the status and trends of social–ecological systems from the local to the global scale in the pursuit of a safe operating space for humanity (Steffen et al., 2015). For example, characterizing such LULC changes is critical for the climate through two mechanisms: biophysical (BPH) and biogeochemical (BGC) feedbacks (Duveiller et al., 2020). For instance, the conversion from forests to croplands (i.e., deforestation) generates a fast increase in land surface temperature (i.e., biogeophysical effect) and also releases part of the carbon stored in the forest into the atmosphere (i.e., biogeochemical component). Both mechanisms contribute to local and global warming, respectively (Oki et al., 2013). Other examples of LULC conversion are urban sprawl, agriculture expansion, or abandonment, which also affect the biodiversity, soil and water quality, food security, and human health among many others (Lambin and Geist, 2008; Feddema et al., 2005). For these reasons, continuous and accurate LULC and LULC change mapping is essential in policy and research to monitor ecological and environmental change at different temporal and spatial scales (Polykretis et al., 2020; García-Mora et al., 2012) and as a decision support system to ensure an effective and sustainable planning and management of natural resources (Kong et al., 2016; Congalton et al., 2014; Grekousis et al., 2015).
Satellite remote sensing in combination with geographic information systems (GISs) has provided convenient, inexpensive, and continuous spatial–temporal information for mapping LULCs and detecting changes on the Earth’s surface from regional to global scales (Kong et al., 2016; Kerr and Ostrovsky, 2003; Pfeifer et al., 2012) thanks to their strong ability to cover, timely and repeatedly, wide and inaccessible areas, as well as to get high spatial and temporal resolution data (Alexakis et al., 2014; Yirsaw et al., 2017; Patel et al., 2019).
Deep learning (DL), a sub-field of machine learning essentially based on deep artificial neural networks (Zhang et al., 2018c), has shown impressive performance in computer vision and promising ones in remote sensing during the last decades. Currently, two specific types of DL models, i.e., CNNs (convolutional neural networks) and RNNs (recurrent neural networks), constitute the state of the art in respectively extracting spatial and temporal/sequential patterns from data records. Indeed, DL models are showing great performance in LULC tasks such as scene classification (Zhang et al., 2018a), object detection (Zhao et al., 2015; Guirado et al., 2021), and segmentation (Zhao and Du, 2016; Guirado et al., 2017; Safonova et al., 2021) in RGB and multispectral satellite and aerial images. However, such good performance is only possible when DL models are trained on smart data. The concept of smart data involves all pre-processing methods that improve value and veracity of data and of associated expert annotations (Luengo et al., 2020), resulting in high-quality and accurately annotated datasets. In general, remote sensing datasets contain noise, missing values, and high variability and complexity across space, time, and spectral bands. Applying pre-processing methods, such as gap filling and noise reduction to data, and consensus across multiple sources to annotations contribute to creating smart remote sensing datasets.
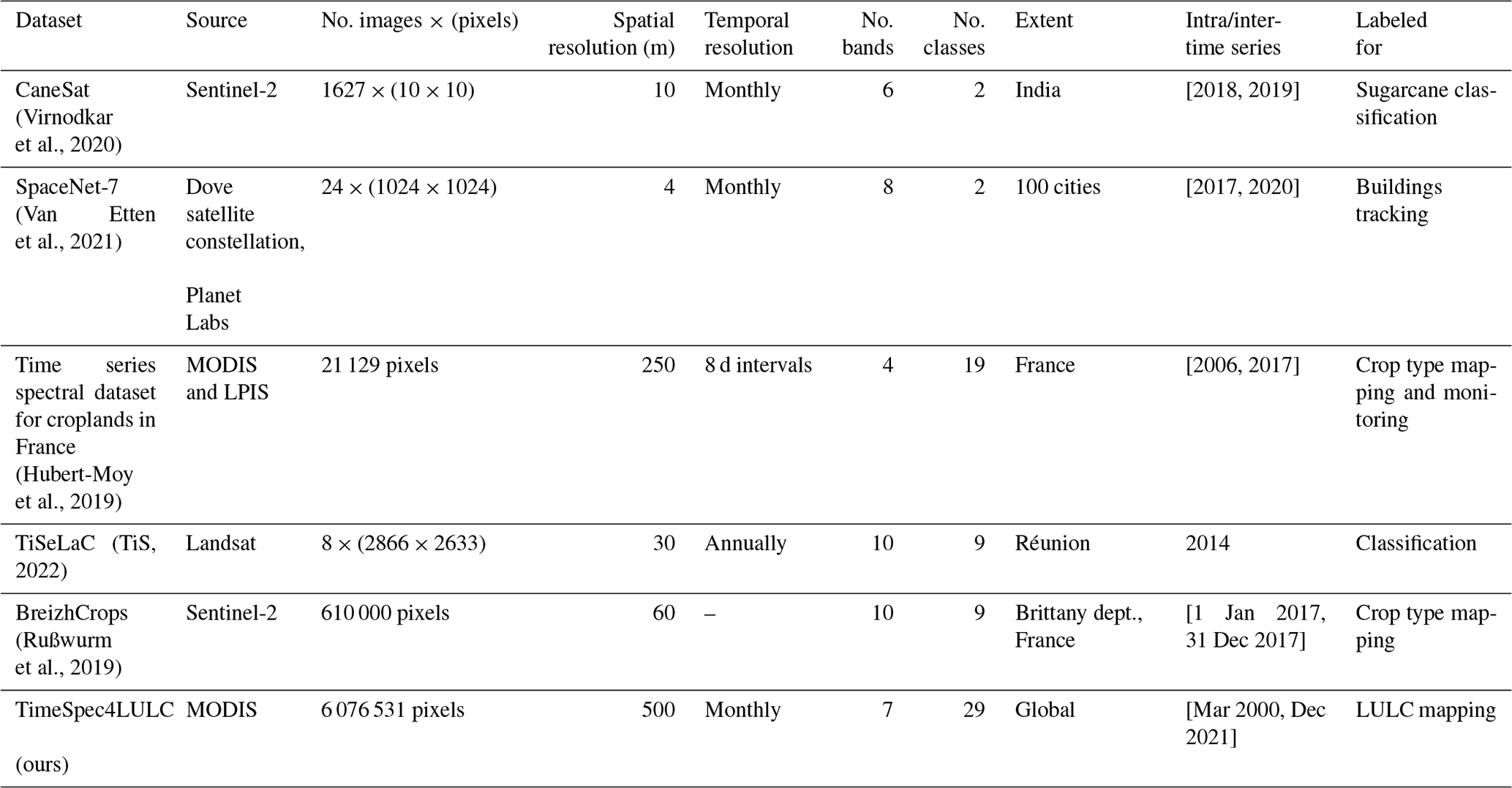
Currently, there only exist few multispectral datasets annotated for training DL models to map LULC and monitor their change (Table 1). However, most of these datasets provide very short time series of data, provide very few LULC classes, and do not have a global coverage. As far as we know, there is no dataset designed for DL models that allows global-scale analysis of many LULC classes using long-time-series data.
This paper presents TimeSpec4LULC, a new open-source, smart, and global dataset of multispectral time series targeted towards the development and evaluation of DL models to globally map LULCs. TimeSpec4LULC was built using GEE (Gorelick et al., 2017) by combining the seven 500 m spectral bands of MODIS Aqua and MODIS Terra satellite sensors at a monthly time step from 2000 to 2021. It contains millions of pixels that were annotated based on a spatial–temporal consensus across up to 15 global LULC products (Table 2) for 29 broad and globally harmonized LULC classes. In addition, it provides metadata at pixel level: geographic coordinates, country and departmental divisions, spatial–temporal consistency across LULC products, statistics on temporal data availability, and the global human modification index. The annotation quality was further assessed by experts using Google Earth and Bing Maps very high resolution images using 100 samples per class evenly distributed around the world.
(Virnodkar et al., 2020)(Van Etten et al., 2021)(Hubert-Moy et al., 2019)(TiS, 2022)(Rußwurm et al., 2019)Table 1A list of existing datasets of times series of satellite images, including the proposed TimeSpec4LULC dataset, for training machine learning models.
To build TimeSpec4LULC, we first determined the spatial–temporal agreement across 15 heterogeneous global LULC products (listed in Table 2) for 29 broad and globally harmonized LULC classes. Then, for each class, we extracted a 22-year monthly time series for the seven 500 m spectral bands of MODIS Terra and Aqua combined. We carried out this process in GEE since it provides access to freely available satellite imagery under a unified programming, processing, and visualization environment.
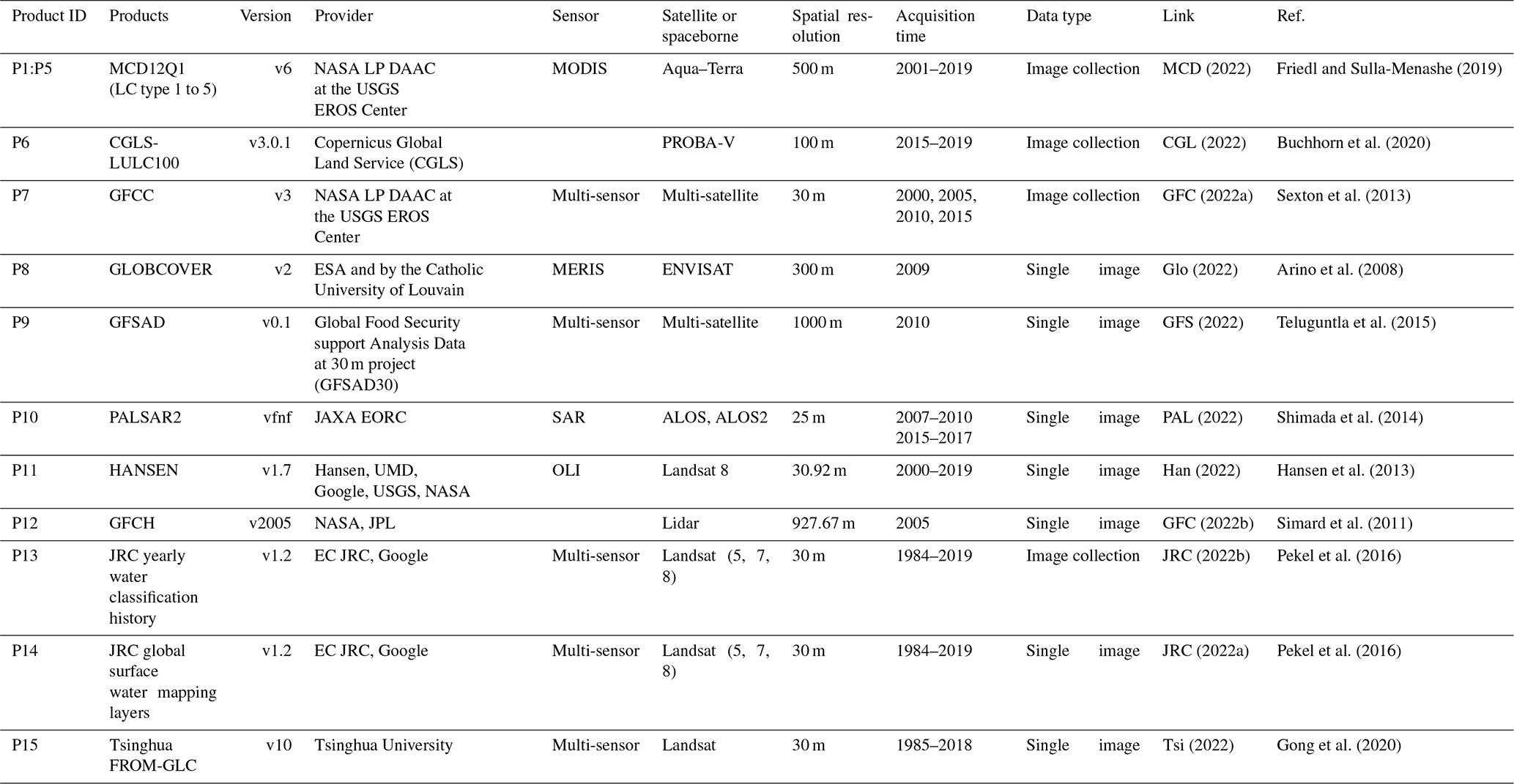
MCD (2022)Friedl and Sulla-Menashe (2019)CGL (2022)Buchhorn et al. (2020)GFC (2022a)Sexton et al. (2013)Glo (2022)Arino et al. (2008)GFS (2022)Teluguntla et al. (2015)PAL (2022)Shimada et al. (2014)Han (2022)Hansen et al. (2013)GFC (2022b)Simard et al. (2011)JRC (2022b)Pekel et al. (2016)JRC (2022a)Pekel et al. (2016)Tsi (2022)Gong et al. (2020)Table 2Description of the GEE global LULC products used in this study.
2.1 Finding spatial–temporal agreement across 15 global LULC products
Since the 1980s, multiple global LULC products (Table 2) have been derived from remotely sensed data, providing alternative characterizations of the Earth surface at varying extents of spatial and temporal resolutions (Townshend et al., 1991; Loveland et al., 2000; Bartholome and Belward, 2005). One of the most important limitations of global LULC products is the within-product variability of accuracy (across different years, regions, and LULC types) and the low agreement among products in many regions of the world (Tsendbazar et al., 2015b, 2016; Gao et al., 2020; Gong et al., 2013; Zimmer-Gembeck and Helfand, 2008). The accuracy of the global products at the local level is low compared to their accuracy at the global level and to the accuracy of local products at the local level. Such lack of consensus can translate into huge implications for subsequent global assessments of biodiversity status, carbon balance, or climate change (Estes et al., 2018; de la Cruz et al., 2017). In addition, accuracy at the local level can be too low, which impedes the use of global or regional LULC products in local studies (Hoskins et al., 2016; Tsendbazar et al., 2016), since it can lead to different conclusions due to the compelling amount of inconsistencies, uncertainties, and inaccuracies (Tsendbazar et al., 2015a; Estes et al., 2018). Multiple reasons lie behind these discrepancies among LULC products (Congalton et al., 2014; Grekousis et al., 2015; Gómez et al., 2016).
-
Satellite sensors. The spatial, temporal, and spectral resolutions of the source satellite images strongly determine the precision and accuracy of derived LULCs. Native pixel size can vary from dozens of meters to kilometers, which determines the precision. Revisiting frequency can vary from daily images to several weeks, which determines the possibility of removing cloud and atmospheric noise effects. In addition, the greater the number of spectral bands in a sensor, the greater the amount of complementary information that can help to differentiate among LULC classes.
-
Processing techniques. The different algorithms for atmospheric correction, cloud filtering, image composition, viewing geometry corrections, etc., can also influence LULC accuracy.
-
Acquisition year(s). Some LULC products just refer to a particular year, while others are regularly updated.
-
Classification schemes. LULC legends can greatly differ in the number of classes and typology definitions. In general, LULC products tend to agree more in broader general categories than in finer specific ones.
-
Classification algorithms. The approaches and rules used to identify each LULC have evolved from decision trees to multivariate clustering and machine learning, including now deep learning.
-
Validation techniques of the final product. The amount and global distribution of ground truth samples differ across products and influence their reported accuracy.
Many efforts have been made to assess, compare, and harmonize the increasing plethora of global, regional, and local LULC products, including their integration into synthetic products, which has shed light onto their strengths and weaknesses (Feng and Bai, 2019; Zhang et al., 2019; Gao et al., 2020; Liu et al., 2021). Still, the myriad of existing products with different specifications and accuracies have made their selection by the users problematic and discouraging because it is frequently unknown whether a product meets the user's needs for a particular area or LULC class (Tsendbazar et al., 2015b; Xu et al., 2020). In addition, many of these efforts are either limited to regional or national scale (e.g., Pérez-Hoyos et al., 2012; Gengler and Bogaert, 2018), coarse spatial resolution (e.g., Tuanmu and Jetz, 2014; Jung et al., 2006), or just one LULC type (e.g., Fritz et al., 2011). The use of synergistic products takes advantage from the strengths of individual products while attenuating their respective weaknesses. However, they still face the challenge of taking into consideration the spatial–temporal consistency within pixels. In general, given a target maximum error of 5 %–15 % either per class or for the overall accuracy, most of the current global land cover maps still do not meet the accuracy demands of many applications (Liu et al., 2021).
To overcome all the aforementioned limitations, a spatial–temporal agreement across 15 global LULC products available in GEE was performed. To find the spatial–temporal consensus across global LULC products for different LULC classes, we followed five steps: (1) selection of global LULC products, (2) standardization and harmonization of LULC legends, (3) combination of products across space and time, and (4) reprojection and selection of spatial agreement thresholds to get a final consistent mask across the 15 products for each one of the 29 LULC classes.
2.1.1 Selection of global LULC products
We used the 15 most updated global LULC products available in GEE (Table 2). These products widely differ in their source satellite data, spatial resolution, temporal coverage, class legend, and accuracy. Given such heterogeneity, we used the consensus across all of them in space and time as a source of reliability to support our annotation. That is, a given LULC class is assigned to a 500 m pixel only if it was consistent over time and space across all the 15 LULC products.
2.1.2 Standardization and harmonization of LULC legends
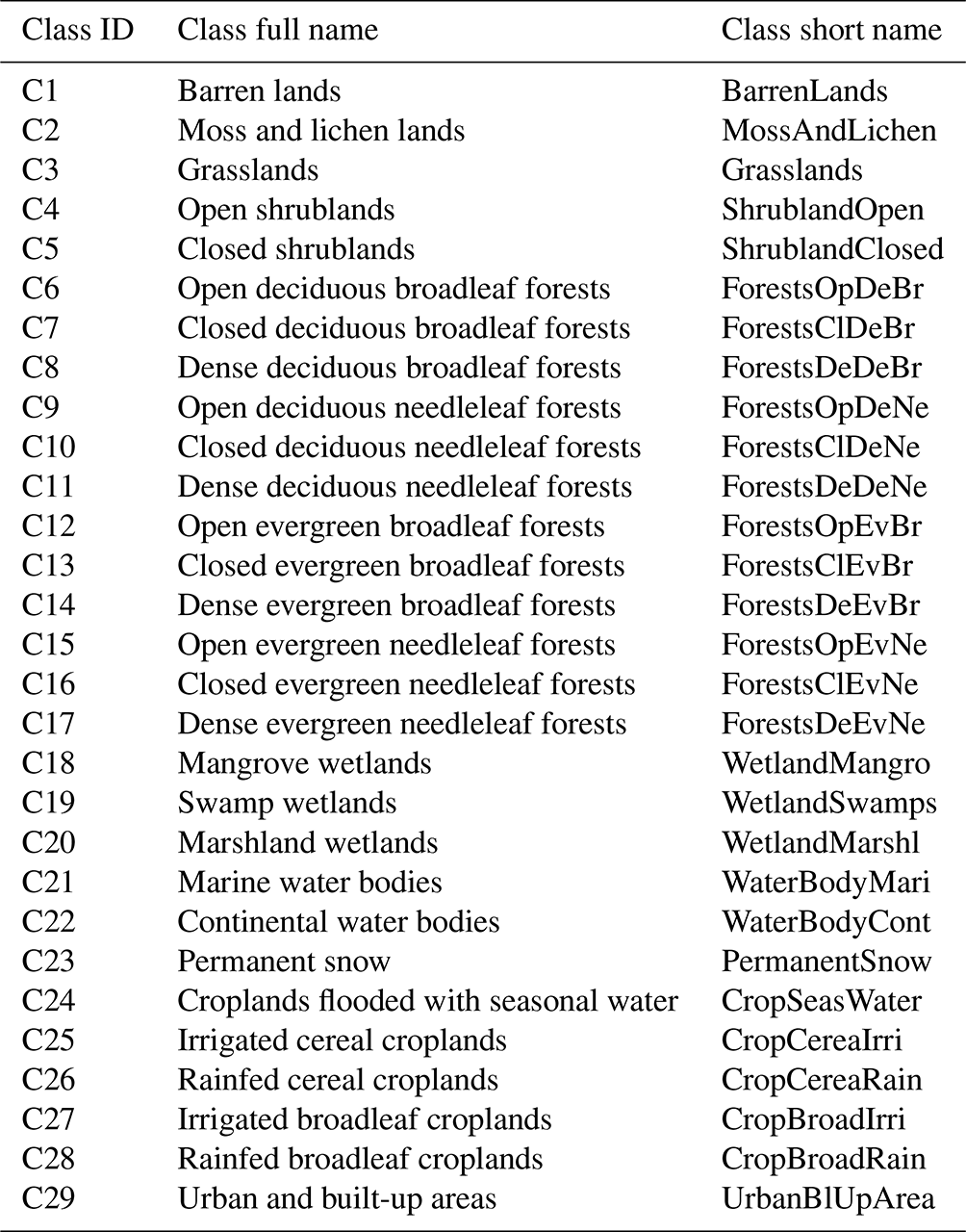
To standardize and harmonize the LULC legends across the 15 LULC products, we used expert knowledge (Vancutsem et al., 2013) to find a common nomenclature based on spatial, temporal, and thematic consensus between equivalent classes from different products. We always matched our resulting consensus class into the hierarchy of FAO's Land Cover Classification System (LCCS) (Di Gregorio, 2005); see correspondence across LULC products in Table 4, as well as the correspondence with FAO's LCCS in Table A1 of the Appendix. Our final legend contained 29 classes at the finest detail (6 LU classes and 23 LC classes) that were interoperable across all products (see the hierarchical structure of our legend in Fig. 1) and FAO's LCCS (Table A1). Table 3 provides the IDs, full names, and short names of the 29 LULC classes. Table A2, in Appendix, provides the detailed definitions of each one of the 29 classes from the definitions given in the original products.
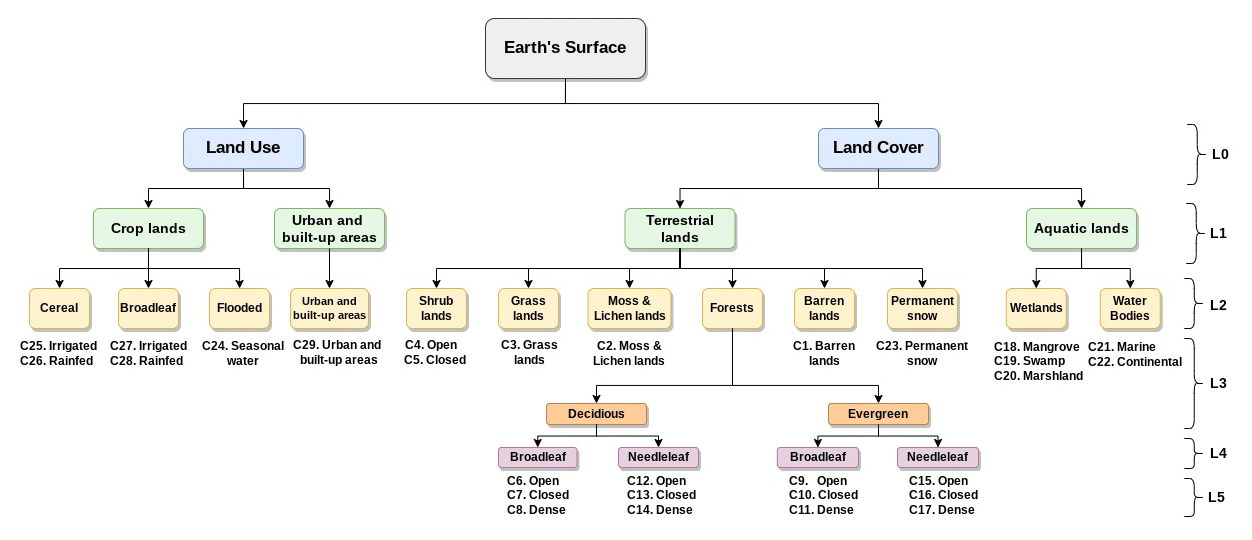
Figure 1Hierarchical structure of the LULC classes contained in the TimeSpec4LULC dataset. C1 to C29: the 29 LULC classes. L0 to L5: the 5 LULC levels. L0 includes the 2 blue boxes. L1 includes the 4 green boxes. L2 includes the 12 yellow boxes. L3 includes all the classes of the 12 yellow boxes (from C1 to C5 and from C18 to C29) except the forests class where it includes only the 2 orange boxes (deciduous and evergreen). L4 includes the same classes but expands the forests class into the 4 purple boxes: deciduous (broadleaf and needleleaf) and evergreen (broadleaf and needleleaf). L5 includes all the 29 LULC classes (from C1 to C29).
Table 3Description of the full name and short name of each LULC class in the TimeSpec4LULC dataset.
The LULC legend was structured into six hierarchical levels (L0 to L5). The six anthropogenic LU classes contained urban and built-up areas and five types of croplands. The 23 natural or semi-natural LC classes covered 5 aquatic systems (marine water bodies, continental water bodies, and 3 types of wetlands) and 18 terrestrial systems (permanent snow, barren lands, moss and lichen lands, grasslands, closed shrublands, open shrublands, and 12 types of forests that differed in their canopy type, phenology, and tree cover).
Some of the products provide discrete categorization of LULC classes in each pixel (P1–P5, P8–P10, P13, and P14), while other products provide continuous categorization represented by a class proportion in each pixel (P11, P12, and P15), or even both continuous and discrete categorizations of LULC (P6 and P7) (Table 4). To define the class of each pixel within these two different categorization mechanisms, we either specify a unique value (e.g., select the value 16 to access barren lands in P1) or use a range of values (e.g., tree canopy cover less than 10 (TCC<10) to access barren lands in P6).
2.1.3 Combining products across time and space
For each LULC class, we built a consensus image describing its global distribution by agreement over time and space across the LULC products. Based on their data type, the LULC products can be classified into two main categories: (1) products with single image referring to a particular year or period (P1 to P7) and (2) products with a collection of images over years (P8 to P12). Thus, the temporal agreement can only be applied for the second category of products. In (1) the single-image-based products, we obtained a binary mask where value 1 corresponds to the targeted LULC class, whereas in (2) the image-collection-based products, we first obtained a binary mask for each year, and then we produced their combination over years to obtain one mask. Afterwards, we performed a spatial agreement over the 12 masks of the first 12 products (P1 to P12), and then we used the masks of the two water bodies products (P13 and P14) and the mask of the impervious surface product (P15) to further refine the consensus.
Based on the temporal consistency, the LULC classes can be classified into (1) classes with high temporal stability, namely urban and built-up areas, water bodies, permanent snow, open shrublands, barren lands, and grasslands; and (2) classes with low temporal stability characterized with plausible inter-annual changes, namely moss and lichen lands, forests, closed shrublands, wetlands, and croplands. This instability is due to several reasons, for example wetlands affected by droughts, or large areas of no-forest cover in one year preceded and followed by forest in the previous and following years, respectively. Our main objective is to collect from each class a representative number of pixels that satisfy the temporal stability constraint of a specific class type. Thus, the temporal agreement, over the masks of each image-collection-based product, was performed based on two different types of operators governed by Algorithm 1. (1) The AND operator, which represents a hard temporal stability constraint, ensures getting pixels with stable class type over time but more likely a small number of pixels. (2) The MEAN operator, which represents a soft temporal stability constraint, provides a large number of pixels but with fewer stability patterns over time. A list of these operators mapping each LULC class is provided in Table 5.
Subsequently, the spatial combination of the 15 masks was performed following six rules according to the global abundance of each class. The main rule (Rule 1) is to apply the MEAN operator across products P1 to P12 and multiply the result by the two water masks of P13 and P14 to eliminate water pixels from land classes and land pixels from water classes, as well as by the impervious surface mask of P15 to eliminate impervious pixels from all classes but urban. However, when the number of pixels for some LULC classes is small (less than 1000), Rule 1 was relaxed differently, generating five other different rules (Rule 2 to Rule 6). These five rules were applied to five LULC classes that had too few pixels with Rule 1: the moss and lichen lands (Rule 2), mangrove wetlands (Rule 3), swamp wetlands (Rule 4), marshland wetlands (Rule 5), and croplands flooded with seasonal water (Rule 6). The usage of the spatial combination rules is described in Algorithm 2.
Finally, the spatial–temporal combination of the 15 LULC products resulted in a mask for each LULC class produced at the resolution of the finest product (i.e., 30 m), where each pixel had a consensus level value p in [0,1]. Hence, for each LULC mask, the pixel value p indicates the spatial–temporal agreement degree over the 15 LULC products on the belonging of this pixel to the class represented by this mask.


Table 4The rule set used to build the legend and define each LULC class in the TimeSpec4LULC dataset. P1 to P15: product 1 to 15. C1 to C29: class 1 to 29. The numbers from 0 to 220 correspond to class IDs in the original LULC products in Google Earth Engine. NU: not used; NA: not available; TC: tree cover; G: gain; L: loss; D: data mask; TH: tree height; TCC: tree canopy cover; TCF: tree-cover fraction; SCF: shrub-cover fraction.

2.1.4 Re-sampling and selection of agreement threshold
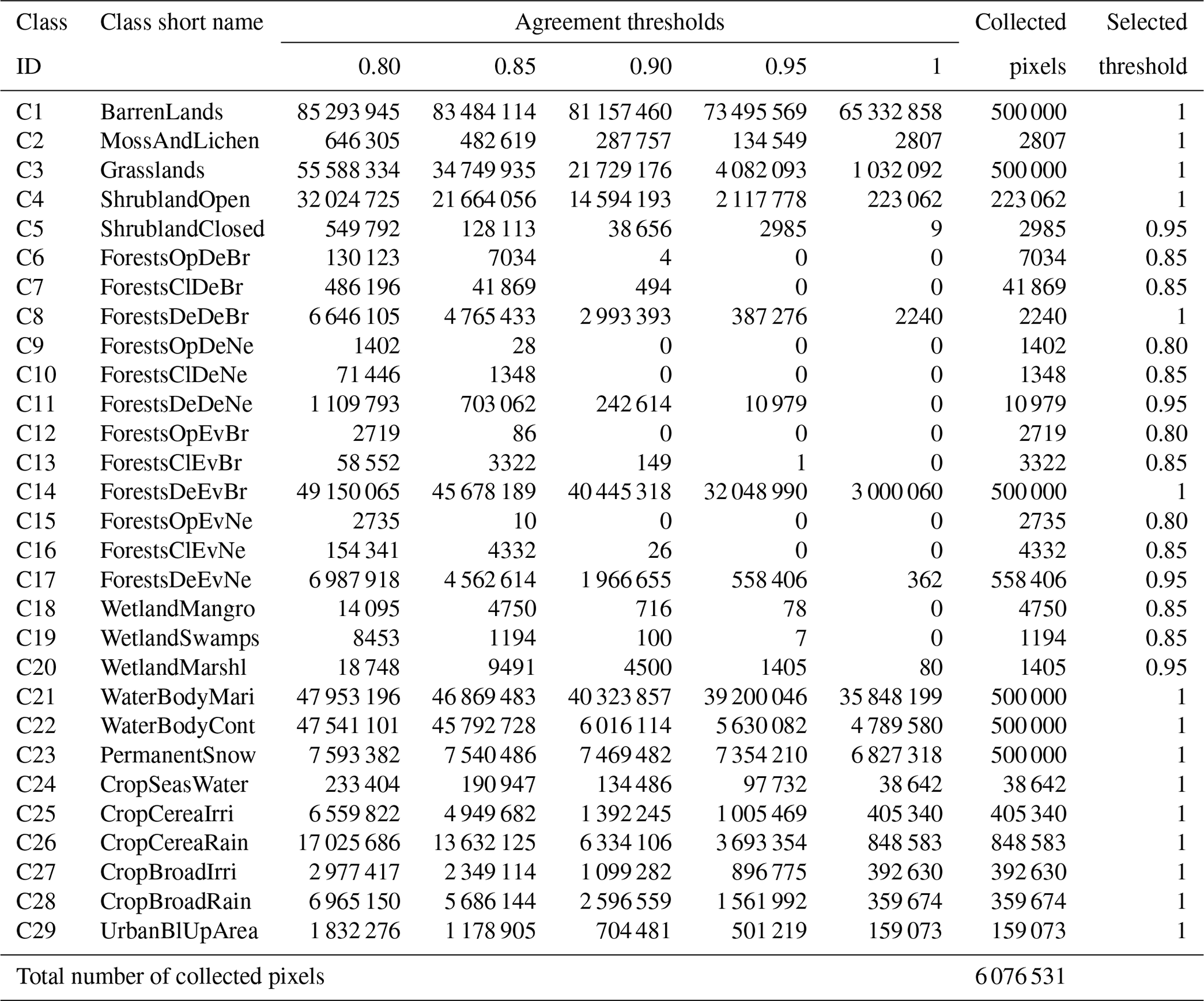
The final mask of each LULC class maintained the spatial resolution of the last aggregated LULC product P15 at 30 m resolution. The 30 m resolution LULC consensus was re-sampled with MODIS resolution (approximately equal to 500 m) using the spatial MEAN reducer. This 500 m average consensus was used to explore different agreement thresholds θ for each LULC class. We used θ=1 when the number of retrieved 500 m pixels is greater than 1000, which means that the 15 LULC products totally agree on the class type of these pixels. Otherwise, we decreased the threshold θ by 0.05 until we reached at least 1000 pixels (Algorithm 3). Table 7 provides the number of pixels obtained with each agreement threshold. In any case, our dataset provides as metadata the agreement percentage at pixel level, so that the user can control the desired agreement threshold and subsequent sample size. To ensure collecting at least 1000 pixels from each class, the lowest pixel-agreement threshold used is θ=0.80 (Table 7).
After performing, for each LULC class, the spatial–temporal agreement, the re-projection, and the selection of the agreement threshold, we combined the final class masks of all the 29 LULC classes to generate one global LULC map describing their distribution (Fig. 2). This figure shows in which place of the world the 29 LULC classes are more stable in time and the 15 LULC products are more compliant, since the number of the collected pixels in each class is affected by the temporal consistency of the 29 LULC classes and the spatial consistency over the 15 LULC products. To illustrate all the steps of the spatial–temporal agreement process across the 15 global LULC products, we provide an example explaining the generation of the final mask for the class “dense evergreen broadleaf forests” (Fig. 3).
Table 5Description of the temporal–spatial combination of the 15 global LULC products (P1 : P15) masks to build a consensus image for each LULC class.
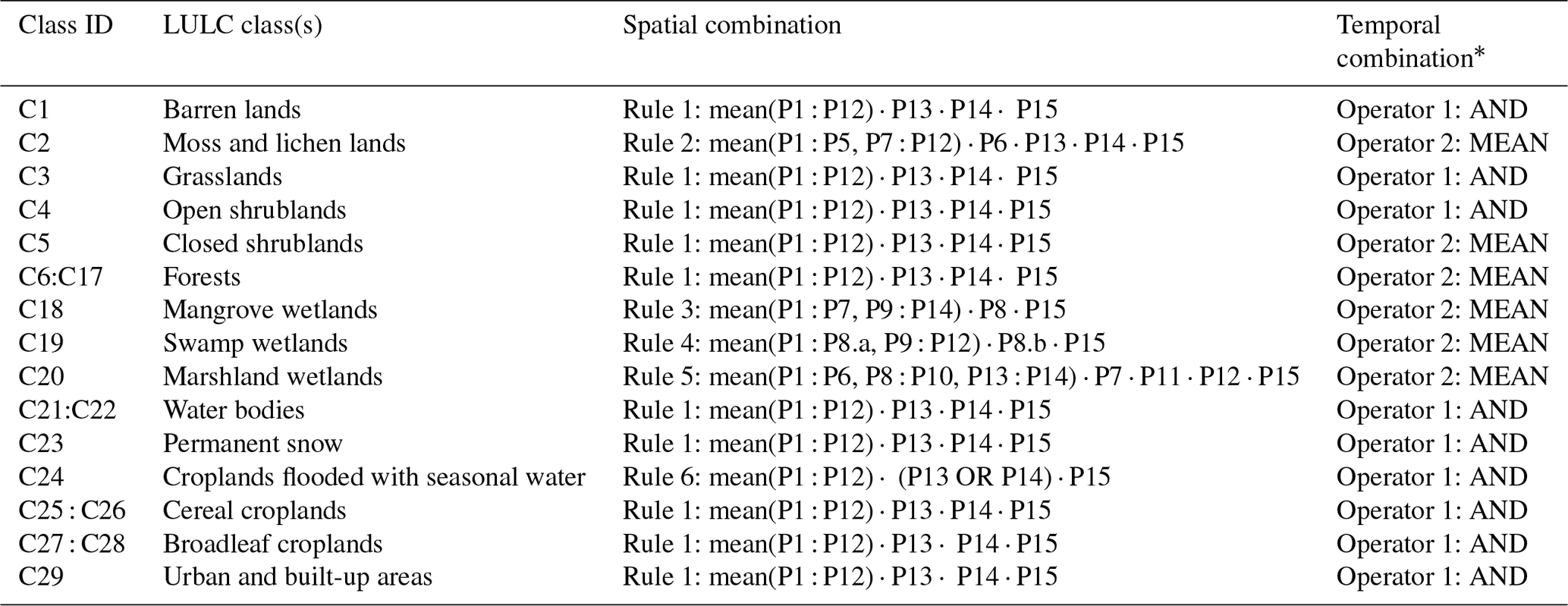
∗ Inter-annual combination used in all products except in P13, where we first calculated the inter-annual mean and then transformed it into a water–no-water binary mask.

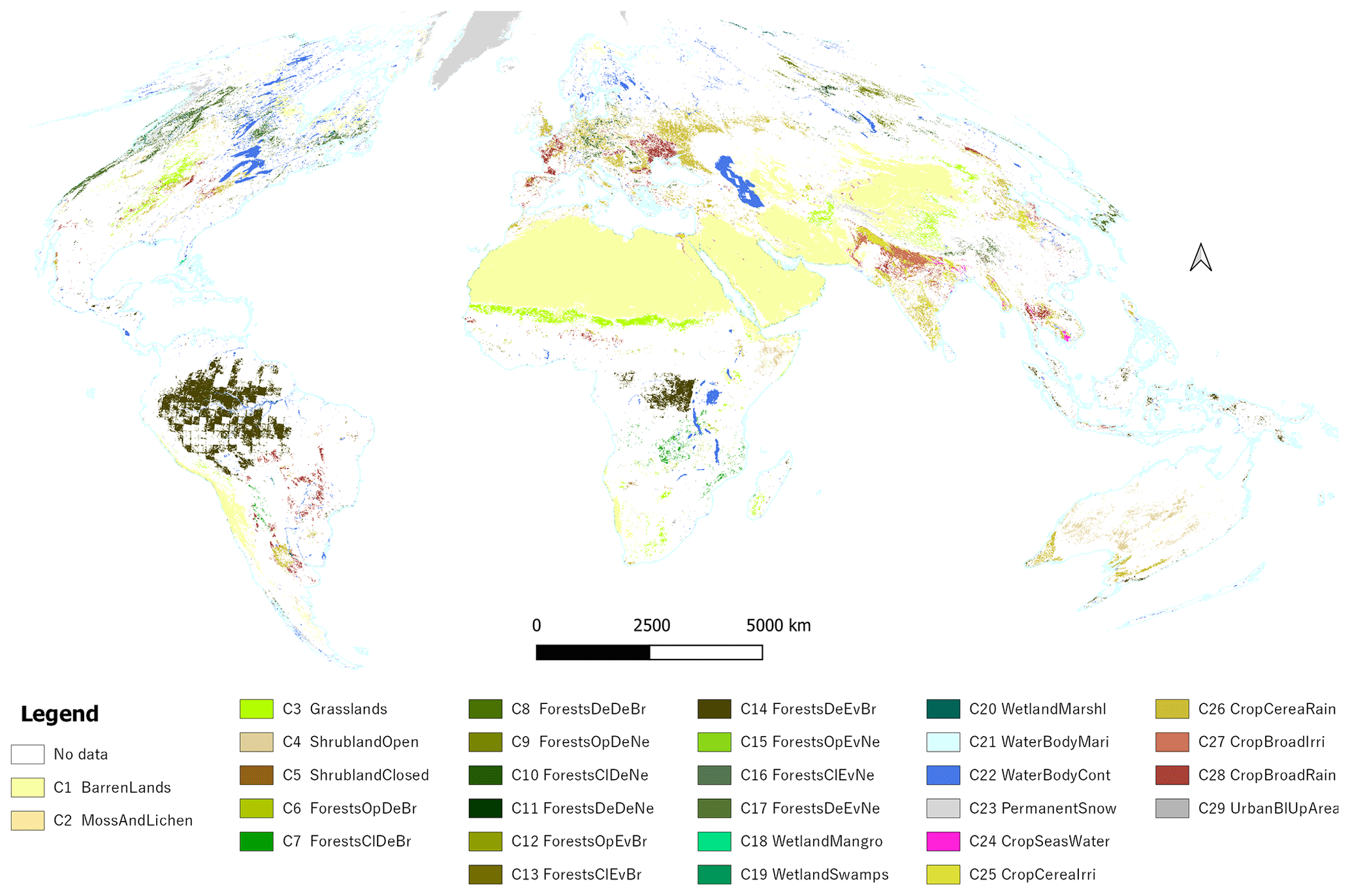
Figure 2Distribution of the number of covered countries (Food and Agricultural Organization's Global Administrative Unit Layers 2015 GAUL-ADM0) over the 29 LULC classes. This map combines all the final LULC class masks that were generated from the process of spatial–temporal agreement across the 15 global LULC products available in GEE. In the map's legend we are presenting the short names of the LULC classes (their corresponding full names are presented in Table 3).
2.2 Extracting times series of spectral data for 29 LULC classes globally
To extract the 22-year monthly time series of the seven 500 m MODIS spectral bands for each of the 29 LULC classes throughout the entire world, we followed four steps (Fig. 4): (1) spatial–temporal filtering of Terra and Aqua data based on quality assessment flags, (2) aggregation of the original 8 d Terra and Aqua data into monthly composites, (3) merging of the two monthly time series into a Terra + Aqua combined time series, and (4) data extraction and archiving (Fig. 6).
2.2.1 Spatial–temporal filtering of Terra and Aqua data based on quality assessment flags
MODIS sensor has high temporal coverage, ensured by Terra and Aqua satellite revisit frequencies, and also spectral and spatial features that are highly suitable for LULC mapping and change detection (García-Mora et al., 2012; Xiong et al., 2017). Thus, we used two MODIS products, MOD09A1 (Ter, 2022) and MYD09A1 (Aqu, 2022), that estimate the 8 d surface spectral reflectance for the seven 500 m bands from Terra and Aqua, respectively.
The quality of any time series of satellite imagery is affected by the internal malfunction of satellite sensor atmospheric (i.e., clouds, shadows, cirrus, etc.) or land (i.e., floods, snow, fires, etc.) conditions. In addition to the spectral bands, MODIS products provide quality assessment (QA) flags as metadata bands to allow the user to filter out spectral values affected by disruptive conditions. Therefore, all QA flags were used to remove noise, spurious values, and outliers in the image collection. MODLAND QA flags (bits 0–1) were used to only select pixel values produced at ideal quality.
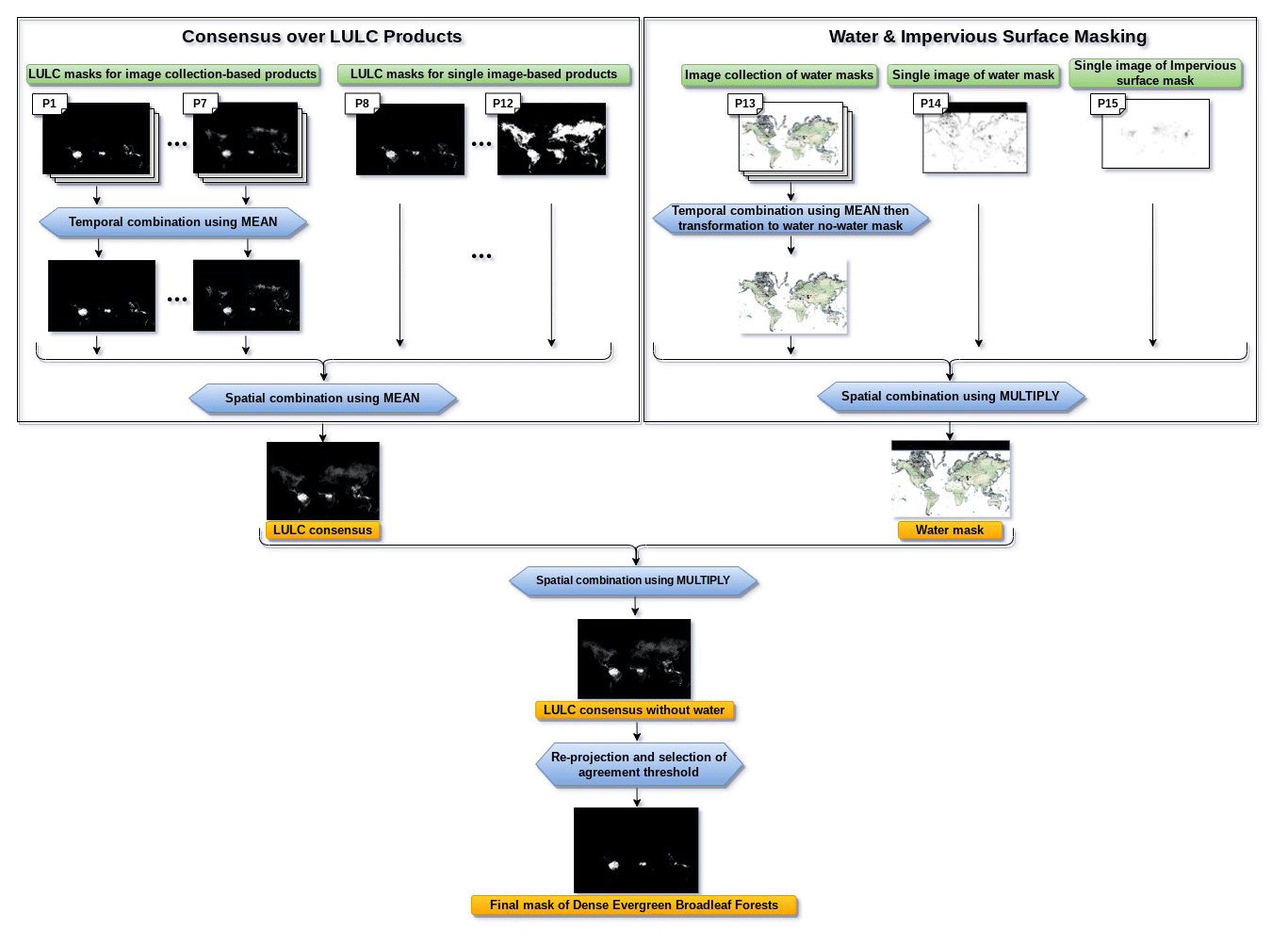
Figure 3Example of the final mask creation process for the dense evergreen broadleaf forests LULC class produced through the spatial–temporal agreement over the 15 global LULC products available in GEE.

Figure 4Description of the spatial–temporal filtering of Terra and Aqua, their aggregation into monthly composites, and their merging into Terra + Aqua combined time series. This process aims to filter out spectral values affected by disruptive conditions and to reduce the number of gaps in the multispectral time series for the 29 LULC classes.
Then, State QA flags were used to mask out clouds (bits 0–1), internal clouds (bit 10), pixels adjacent to clouds (bit 13), cirrus (bits 8–9), cloud shadows (bit 2), high aerosol quantities (bits 6–7), and internal fires (bit 11). The water flag (bits 3–5) was used to mask out water pixels in all terrestrial systems, but not in the terrestrial systems of permanent snow, and in croplands flooded with seasonal water to avoid unrealistic data loss.
2.2.2 Aggregating the original 8 d Terra and Aqua data into monthly composites
Filtering the MODIS Terra and Aqua data records produced many missing values in their 8 d time series. To overcome this issue and further reduce the presence of noise in our dataset, the original 8 d time series were aggregated into monthly composites by computing the mean over the observations of each month. Indeed, despite the fact that reducing the temporal resolution from 8 d to monthly composites shortened the time series size, it generated two datasets with fewer missing values and clear monthly patterns, which are more intuitive to track LULC dynamics than the 8 d patterns.
2.2.3 Merging the two monthly time series into a Terra + Aqua combined time series
Terra satellite daily orbits above the Earth's surface from north to south in the morning at around 10:30 local time, while Aqua orbits in the opposite direction in the afternoon at around 13:30. Having two opportunities per day at each location increases the chances of capturing an image under good atmospheric conditions. To further reduce the number of missing values in our dataset, we merged the monthly time series provided by these two satellites into a Terra + Aqua combined time series. That is, for each pixel, band, and month, when both Terra and Aqua had values, we used the mean between them; when one satellite had a missing value, we used the available one; and when both of them had missing values, the combined value remains missing. Since Aqua was launched 3 years later (in 2002) after Terra had been launched, the acquisition time of our dataset is (1) from 5 March 2000 to 4 July 2002 using Terra time series and (2) from 4 July 2002 to 19 December 2021 using Terra + Aqua time series.
2.2.4 Extracting and archiving the dataset
One of the main advantages of our dataset is its global-scale characteristic since all the LULC data were extracted globally from all the regions over the world. The data exportation process was performed in two steps (Fig. 6). (1) We exported the metadata of all the pixels generated by the consensus. Then, (2) we exported their corresponding time series data. Detailed descriptions and discussions about each step are provided as follows.
-
From each LULC class mask, we first exported the metadata of all the available pixels in one file. However, for the class masks having more than 1 million pixels (barren lands, water bodies, permanent snow, grasslands, open shrublands, and dense evergreen broadleaf forests) we only exported the metadata of 500 000 pixels randomly selected over the globe because of the memory limitations in GEE (Table 7). The exported metadata includes the coordinates of the pixel center and the percentage of agreement over the 15 LULC products. To take into account all the differences across the globe and thinking of regional interests that some users may have, we used the Food and Agricultural Organization's Global Administrative Unit Layers 2015 (FAO GAUL) product, available in GEE, to provide for each pixel the ADM0-CODE obtained from the country boundaries (GAU, 2022a) of FAO GAUL (i.e., countries) and the ADM1-CODE obtained from the first-level administrative units (GAU, 2022b) of FAO GAUL (e.g., departments, states, provinces). Further, to provide the user with extra metadata that could be used to filter time series according to different levels of human intervention on each pixel, the average GHM index was included. The GHM index was derived from the Global Human Modification dataset (CSP gHM) (https://developers.google.com/earth-engine/datasets/catalog/CSP_HM_GlobalHumanModification?hl=en, last access: 22 March 2022; Kennedy et al., 2019) available in GEE, which provides a cumulative measure of human modification of terrestrial lands. Then, it was projected to MODIS resolution using the spatial mean reducer to generate the average GHM index.
-
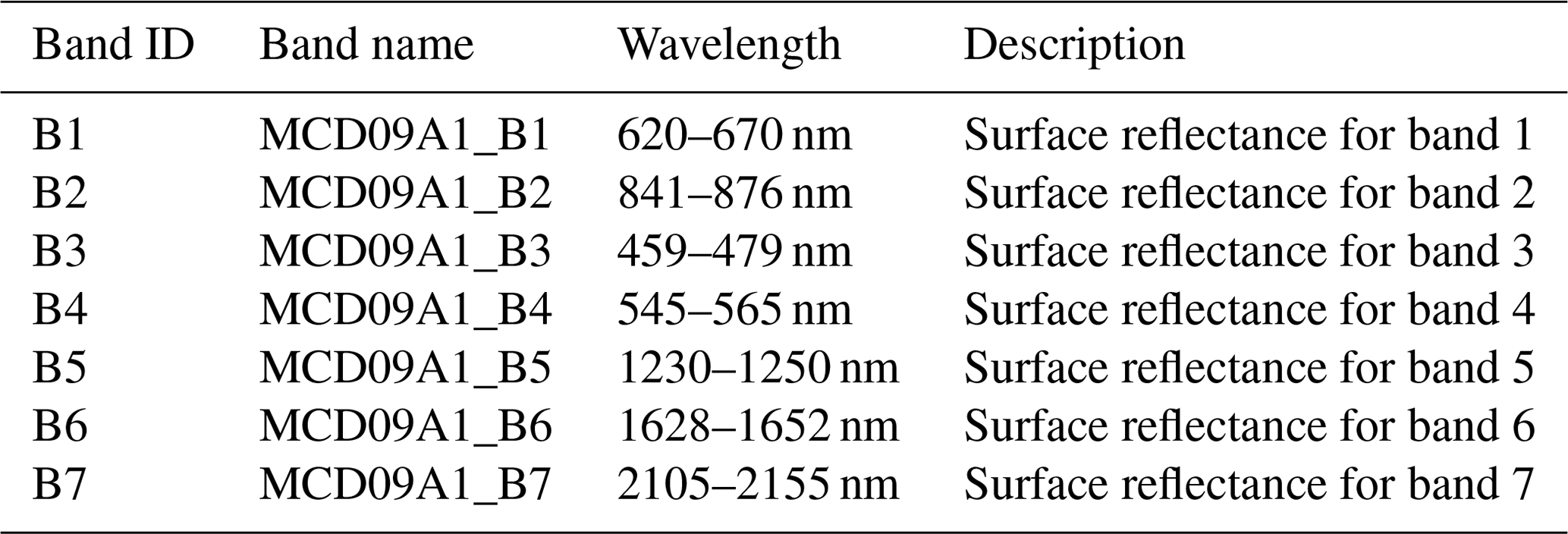
After exporting the metadata, we accessed the coordinates of each LULC class to download their time series data for the seven spectral bands (Table 6). Each time series dataset contains 262 observations covering almost 22 years (i.e., from 2000 to the end of 2021). In order to optimize the exportation process, for each LULC class, the 262 observations corresponding to the 262 months were exported separately in 262 parallel requests. In each request, we exported seven values corresponding to the seven spectral bands for all the LULC-class-related pixels.
The exported data generated highly imbalanced LULC classes obviously due to the differences in their spatial distributions. Thus, to facilitate the exploration of the dataset, we also provided a balanced dataset ready to train machine learning models. The balanced subset of TimeSpec4LULC provides the time series data for 1000 pixels from each class since the smallest LULC class contains 1194 pixels (Table 7). The selection of these 1000 samples from each class was performed using Algorithm 4 such that they are evenly distributed in the globe and representative for the world. In Fig. 5, we provide the distribution of the 1000 pixels selected from the class “marine water bodies”.
Table 6Description of the seven spectral bands of MODIS sensor.
The provided metadata can also be used in case the user wants to export future time series observations for the coming months. In this context, the user needs to make use of the ADM0-CODE and the ADM1-CODE to access the coordinates of any region in the world included in the consensus. Then, the user can upload these coordinates to GEE to export the time series data of the desired range of time.

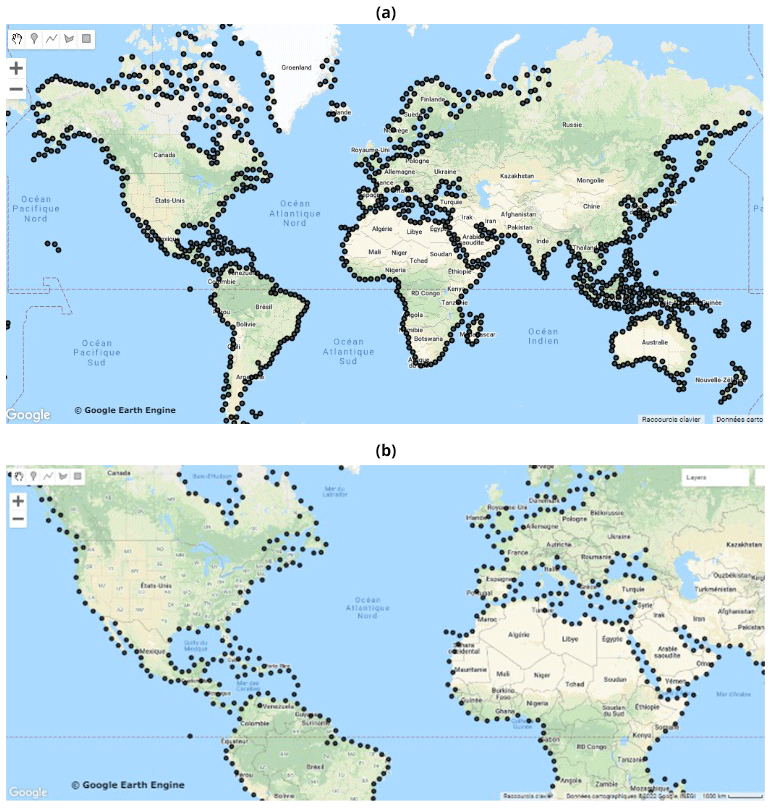
Figure 5Distribution of the 1000 points selected by Algorithm 4 for the class “marine water bodies”: (a) global view and (b) zoomed-in view.
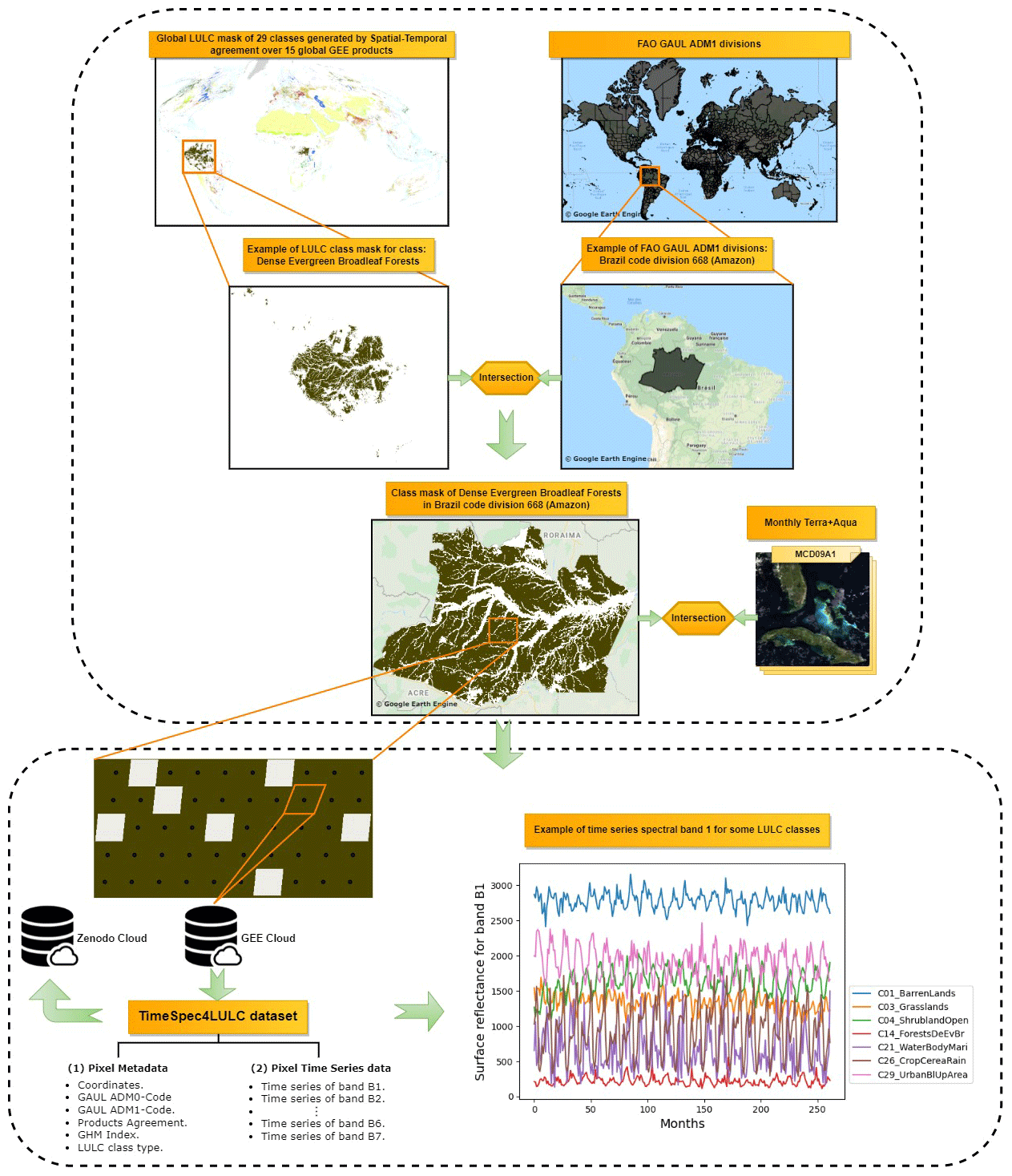
Figure 6Description of the data extraction process for the LULC class dense evergreen broadleaf forests from all the world's partitions (GAUL-ADM0, https://developers.google.com/earth-engine/datasets/catalog/FAO_GAUL_2015_level0, last access: 22 March 2022; and GAUL-ADM1, https://developers.google.com/earth-engine/datasets/catalog/FAO_GAUL_2015_level1, last access: 22 March 2022) where this class is available, in addition to a visualization of the first spectral band time series for some LULC classes.
Table 7Sensitivity analysis of the number of pixels with respect to different values of agreement thresholds along with the final number of collected pixels at the selected threshold. When the number of pixels at threshold 1 exceeds 1 million, we collect 500 000 random pixels. Otherwise, we decrease the threshold by 0.05 until we obtain at least 1000 pixels (Algorithm 3).
To organize and assess the quality of the extracted global data for all the 29 LULC classes, we first present the description of the dataset structure, and then we evaluate the quality of its annotation process.
3.1 Description of the data structure
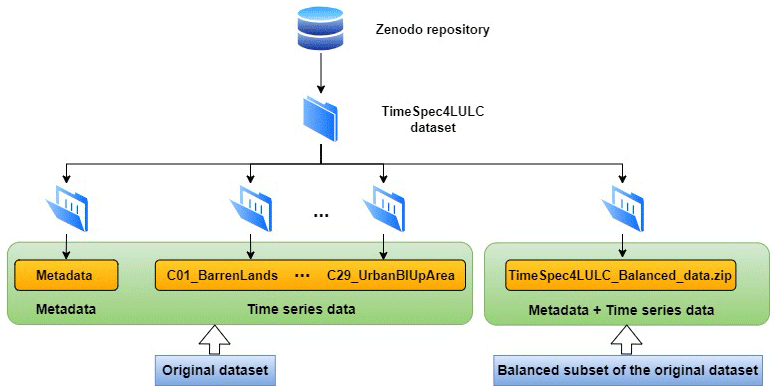
The TimeSpec4LULC dataset is hosted by https://doi.org/10.5281/zenodo.5020024 (Khaldi et al., 2022). It contains two datasets: the original dataset “TimeSpec4LULC_Original_data.zip” and the balanced subset of the original dataset “TimeSpec4LULC_Balanced_data.zip”. The structure of TimeSpec4LULC is organized as follows (Fig. 7).
-
The original dataset contains 30 folders, namely “Metadata”, and 29 folder corresponding to the 29 LULC classes. The folder “Metadata” holds 29 different CSV files named on behalf of the 29 LULC classes. The naming of each file follows the structure “ClassId_metadata.csv”. For instance, the metadata CSV file for the barren lands class is named “C01_metadata.csv”. Each CSV file holds the metadata of all the pixels generated by the consensus limited to 500 000 for classes that exceed 1 million at agreement threshold 1.
The remaining 29 folders contain the time series data for the 29 LULC classes. Each folder has the form “ClassId_ClassShortName” and holds 262 CSV files corresponding to the 262 months. For example, the CSV file for the barren lands class for the last month is named “C01_261.csv”. Inside each CSV file, we provide the seven values of the spectral bands as well as the coordinates for all the LULC-class-related pixels.
A clear description of the metadata folder along with an example of the time series data for barren lands is presented in Fig. 8.
-
The balanced subset of the original dataset holds the metadata and the time series data for 1000 pixels per class representative of the globe selected by Algorithm 4. It contains 29 different JSON files following the names of the 29 LULC classes. The naming of each file follows the structure “ClassId_ClassShortName.json”. For instance, the JSON file for the barren lands class is named “C01_BarrenLands.json”.
Each JSON file “Class_File” is a dictionary containing the short name of the LULC class “Class_Name”, the ID of the class “Class_Id”, and a list of all the relative pixels “Pixels” (for more information about the LULC classes short names, see Table 3). Each element of the list “Pixels” is a dictionary holding the ID of the pixel “Pixel_Id”, the class of the pixel “Pixel_Label”, the metadata of the pixel “Pixel_Metadata”, and the seven time series of the pixel “Pixel_TS”.
The variable “Pixel_Metadata” contains the geometry and coordinates (longitude and latitude) of the pixel center following the GEE format “.geo”, the GAUL country code “ADM0_Code”, the GAUL first-level administrative unit code “ADM1_Code”, the average of the global human modification index “GHM_Index”, the agreement percentage over the 15 LULC products “Products_Agreement_Percentage”, and a dictionary carrying the temporal availability percentage for each band “Temporal_Availability_Percentage” (i.e., percentage of non-missing data per band from B1 to B7).
The variable “Pixel_TS” is a dictionary that holds the names and the time series values of the seven spectral bands (from MCD09A1_B1 to MCD09A1_B7) of size 262. A clear description of the JSON class file is presented in Fig. 9.

Figure 8Data structure of the metadata folder (a) and the time series data folder (b) for the class “barren lands” in the original dataset.
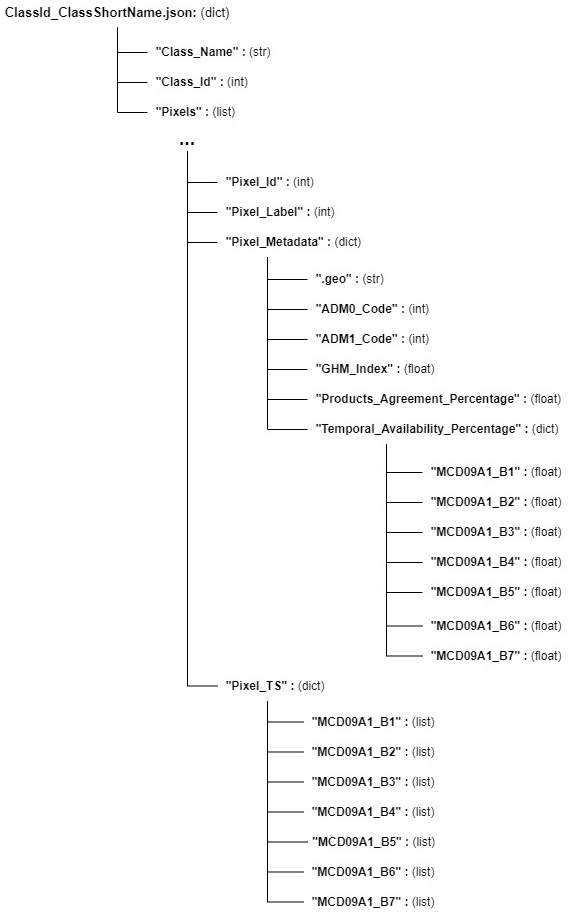
Figure 9Data structure of an LULC class JSON file for the balanced subset of the original dataset.
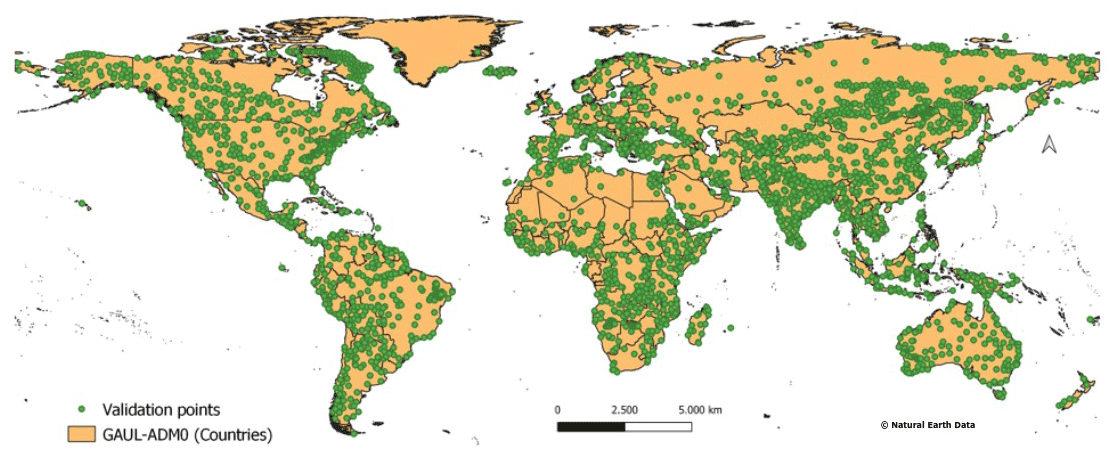
Figure 10Global distribution of the selected 2900 pixels to perform the quality control over all the 29 LULC classes.
3.2 Data quality control
The quality of the dataset annotation was assessed and validated visually by two co-author experts using two very high resolution imagery (<1 m/pixel) sources, namely Google Earth (https://earth.google.com/web/, last access: 22 March 2022) and Bing Maps imagery (https://www.bing.com/maps/, last access: 22 March 2022). The assessment process includes three stages.
-
First, a set of 100 samples is carefully selected from each class following the maximum distance criteria described in Algorithm 4. That is, depending on the overall size of each LULC class, 100 evenly distributed pixels over the globe were selected. Figure 10 shows the distribution of the 2900 selected pixels.
-
Second, the class of each pixel of the 29 × 100 samples is identified visually by the expert eye following the next rule. We consider as ground truth the dominant LULC class; such LULC class occupies at least 70 % of the pixel. The presence of up to 30 % of features of other different LULC classes within the dominate class is ignored.
-
Once the validated LULC classification matrix was obtained (Table 8), the F1 score was calculated for all the LULC levels (from L0 to L5). We used F1 score because it evaluates the balance between precision and recall, where (1) precision indicates how accurate the annotation process is in predicting true positives and (2) the recall, also called sensitivity, indicates how many actual positives were predicted as true positives (Eq. 3).
As it can be observed from Table 8, as we go up from level L0 to level L5 the obtained F1 score decreases from 96 % to 87 % mainly due to the classification of forests, grasslands, open shrublands, water bodies, and croplands flooded with seasonal water. Typically, the obtained F1 score of each class is independent of the selected agreement threshold. In some classes, even if the agreement threshold is equal to 1, the F1 score is low compared to other classes with small agreement threshold. For instance, the agreement threshold of grasslands and open deciduous needleleaf forests is equal to 1 and 0.80, respectively. However, the F1 score of grasslands is lower (0.68) than the F1 score of open deciduous needleleaf forests (0.90).
The total number of collected time series (pixels) in all the 29 LULC classes is 6 076 531, which is large enough to build high-quality DL models (Table 7). This number covers the 29 LULC classes in unbalanced way due to two reasons: (1) the global abundance of each class and (2) the choice of the agreement threshold. We provide, in Table 7, the variation of the number of pixels with respect to different values of agreement thresholds. It can be noticed that as we decrease the agreement threshold, the number of pixels increases. Table 7 highlights also the classes that reduced the consensus F1 score (with selected threshold less than 1) which are the three wetlands classes, closed shrublands, and all forests classes except dense deciduous broadleaf and dense evergreen broadleaf.
In 15 LULC classes, the number of collected time series, at agreement threshold 1, is at least 2240 per class. This means that the 15 LULC products are 100 % compliant with regard to the nature of these classes. Thus, these classes have enough pure spectral information, describing their behavior over time, to train DL models with very high accuracy. However, in the remaining 14 LULC classes, the number of time series, collected at agreement threshold 100 %, is either small (with closed shrublands, dense evergreen needleleaf forests, and marshland wetlands) or null in the remaining wetlands classes and forests classes (except dense broadleaf classes). This implies that, within 500 m pixels, the LULC products are less consistent within these classes, and there may be remaining noise in one class from other classes. Since our dataset provides, as metadata, the agreement percentage at the pixel level, the user can always select the desired agreement threshold.
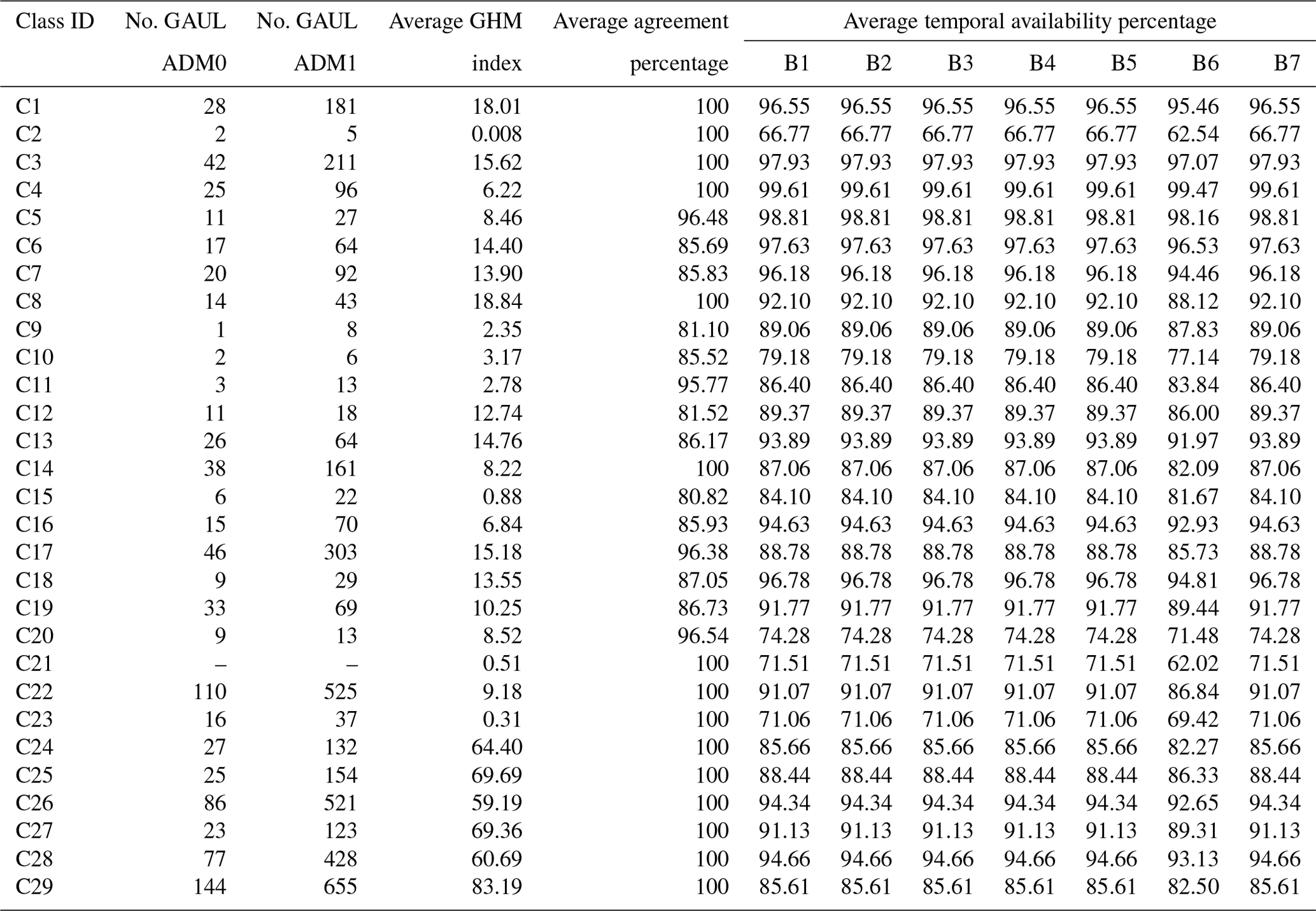
The collected time series data in each LULC class still contains some missing data that could be handled neither with the monthly aggregation process nor with the Terra–Aqua merging process (Table 10). For some classes, the average temporal availability percentage is very high (e.g., grasslands, shrublands, and open deciduous broadleaf forests). However, it is low for other classes (e.g., moss and lichen lands, marshland wetlands, marine water bodies, and permanent snow), which implies that their multispectral time series information is hugely affected by atmospheric and/or land conditions. For all LULC classes, it is noticeable that the average temporal availability percentage in band 6 is low compared to the other bands which make band 6 the most contaminated by gaps. The reason behind this is the “dead lines” in Aqua band 6 caused by the already reported malfunctioning or noise in some of its detectors (Zhang et al., 2018b).
The unbalanced dataset (Table 9) and the balanced dataset corresponding to the 1000 pixels per class (Table 10) are distributed all over the world's GAUL partitions: ADM0 (i.e., countries) and ADM1 (e.g., departments, states, provinces). Each LULC class, in the two datasets, covers more than 6 countries and more than 13 departments, except moss and lichen lands as well as deciduous needleleaf forests that cover fewer countries and departments because of their naturally scarce distribution over the world, whereas some of the LULC classes, namely continental water bodies, rainfed croplands (cereal and broadleaf), and urban and built-up areas, have a broad world coverage, i.e., more than 70 countries and more than 400 departments. In addition, the GHM index of the five cropland classes and the urban and built-up areas class is widely higher (more than 59 % of human change) compared to the other land cover classes, which proves their accurate annotation as human land uses. In a cultivated landscape, some plots may be in rotational fallow while other plots are being cultivated, even though the main signal from this class would come from the cultivated land because it is the main land use of the pixel.
Table 8Description of the data quality control results of the 2900 pixels for each LULC level (L0 to L5) using the F1 score. The correspondence between long and short names of the LULC classes is provided in Table 3.
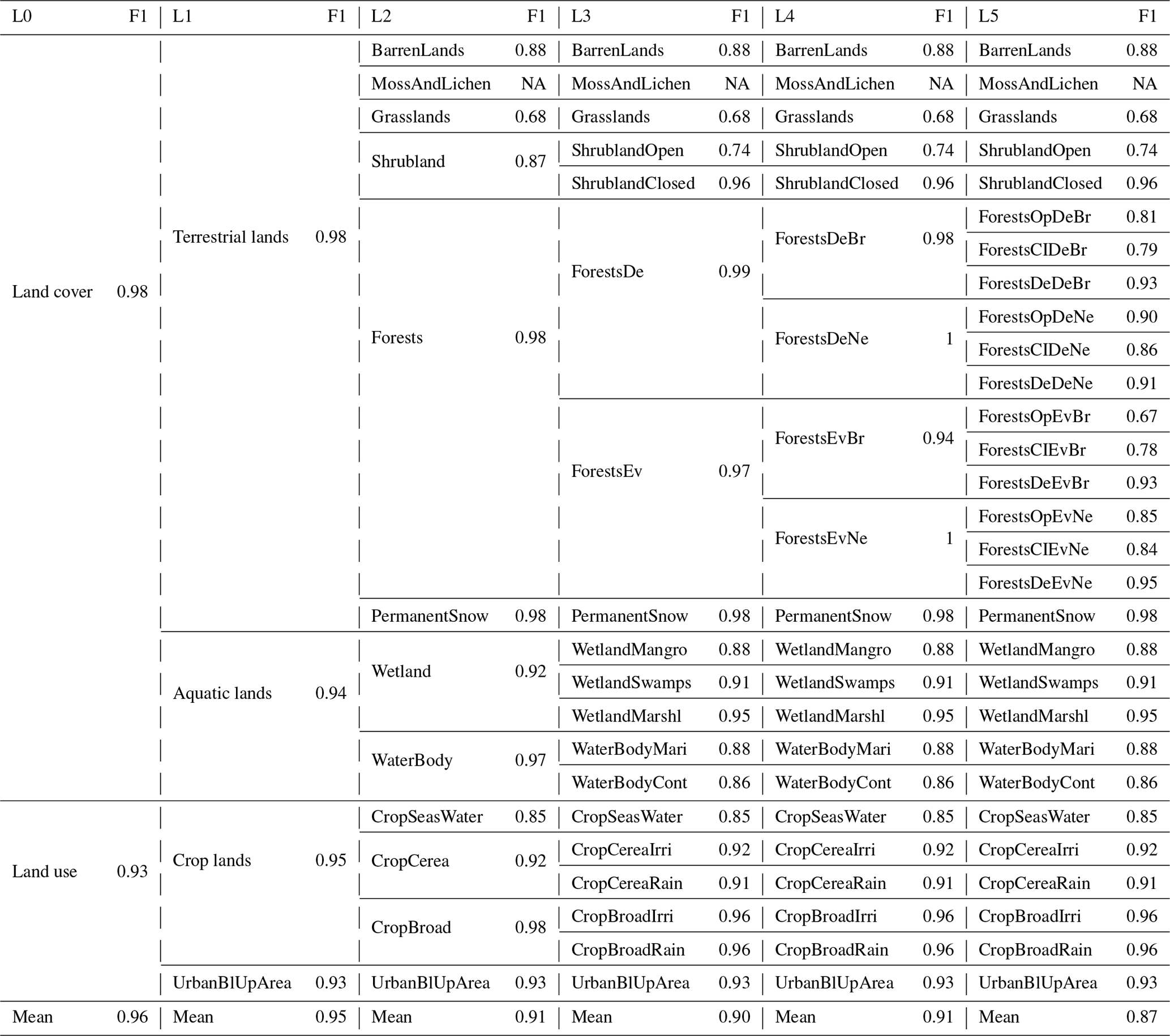
Table 9Description of the number of Food and Agricultural Organization's Global Administrative Unit Layers 2015 (GAUL) partitions ADM0 and ADM1, the average GHM index, and the average agreement percentage for the imbalanced version of the data. The number of ADM0 and ADM1 partitions for the class “marine water bodies” (C21) is not provided because the GAUL partitions do not cover the seas and oceans.
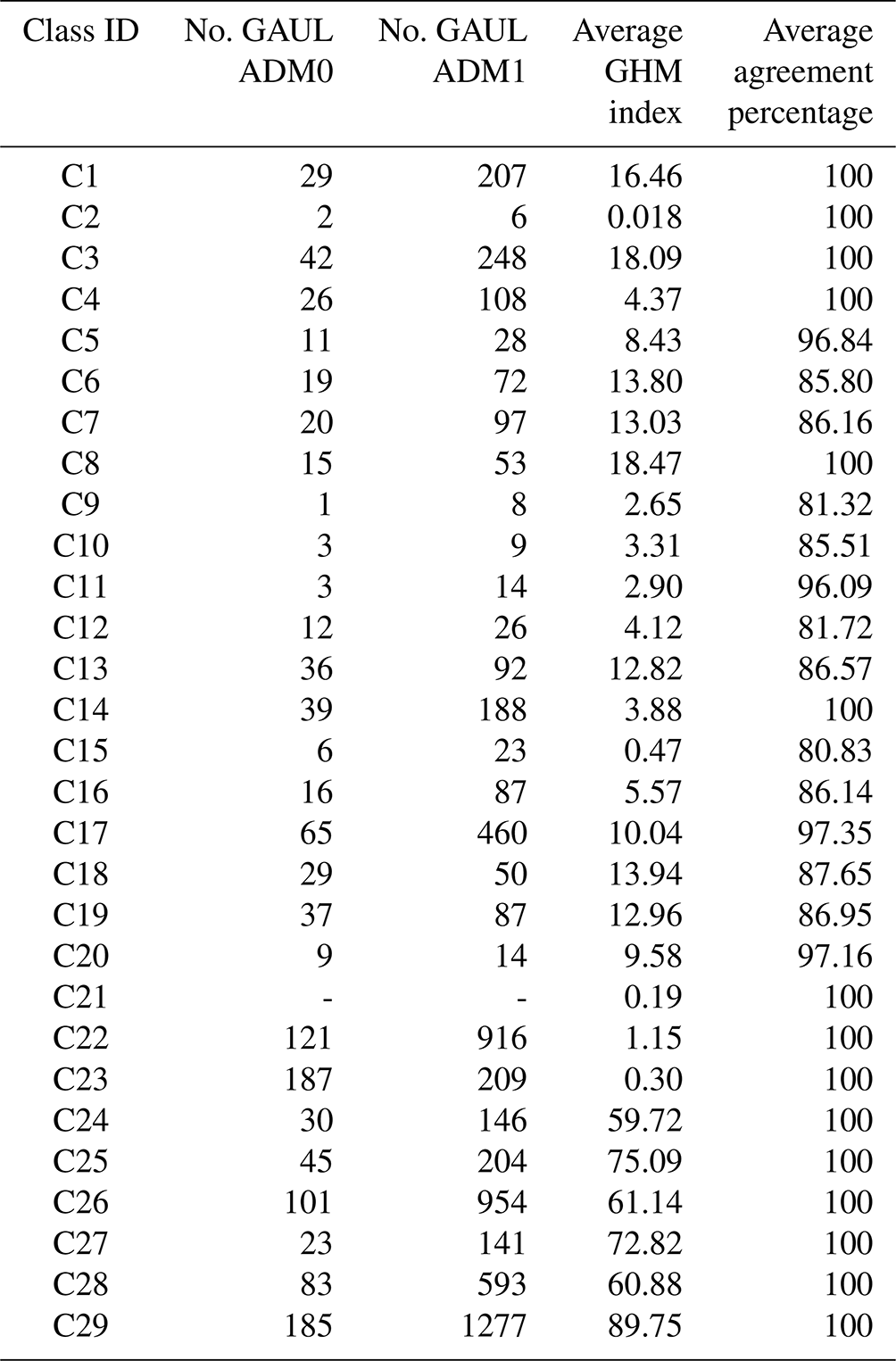
Table 10Description of the number of GAUL partitions ADM0 and ADM1, the average GHM index, the average agreement percentage, and the average temporal availability percentage of each spectral band (B1 to B7) for the balanced version of the data. The number of ADM0 and ADM1 partitions for the class “marine water bodies” (C21) is not provided because the GAUL partitions do not cover the seas and oceans.
The produced dataset is of high quality both in terms of the annotation and the generation of spectral reflectance. On the one hand, our dataset was annotated using the process of spatial–temporal combination of 15 global LULC products available in GEE. On the other hand, the time series of spectral reflectance were generated with less noise thanks to (1) the application of the quality assessment filters (MODLAND QA and State QA) in both MODIS products (MOD09A1 and MYD09A1), (2) the temporal aggregation from 8 d to monthly data, and (3) the Terra + Aqua merging process.
In addition, the annotation accuracy was assessed in two ways. First, thanks to the spatial–temporal agreement across the global GEE products, the level of consensus offered a cross-validation across independent products. Second, the annotation accuracy was assessed using a geographically representative sample of 2900 pixels (100 pixels per class selected by Algorithm 4) manually inspected by experts (visually photo-interpreted) using very high resolution imagery from both Google Earth and Bing Maps. Then, it was jointly agreed on which class each pixel corresponded to (agreement across interpreters according to Muchoney et al., 1999). Thus the high quality of this dataset will certainly ensure the building of highly accurate machine learning models because building good quality machine learning models is possible only when trained on good quality data (García-Gil et al., 2019).
This smartly, pre-processed, and annotated dataset is targeted towards scientific users interested in developing and evaluating various DL models to detect LULC classes. For example, TimeSpec4LULC can be used (i) to study the intra-class behaviors of LULCs, i.e., assess the behavior of one specific LULC in different areas of the world and see whether it maintains the same pattern or it reveals different patterns, and (ii) to study the inter-class differences and similarities of LULCs, i.e., recognize and compare the patterns and dynamics of all LULCs (e.g., time series classification).
It appears that the dataset is only oriented towards LULC mapping since we provide for each time series a unique label. Nevertheless, this data can also be used (i) to characterize the seasonal and inter-annual dynamics and changes of vegetation types and LULC classes and (ii) to perform environmental monitoring, management, and planning. This can be done by creating an artificial dataset characterized by LULC change where each time series can have a sequence of annotations relative to each LULC type. Then, time series-based DL segmentation models can be trained on this artificial data and deployed on real time series to detect and monitor the LULC change. On the other hand, the coordinates of each class provided in the dataset can also be used to detect anomalies in a specific class type, such as forest.
The dataset also has some limitations that we discuss below and to which we tried to provide some alternative solutions.
-
Due to memory limitations in GEE, for some classes (barren lands, grasslands, dense evergreen broadleaf forests, water bodies, and permanent snow), we could not export all the available pixels where the 15 LULC products agree. But we are still providing the representative data number (500 000 time series) distributed over the different GAUL partitions ADM0 and ADM1 where the class types exist.
-
Even though we aggregated the original 8 d Terra and Aqua data into monthly composites and merged both satellite monthly data into Terra + Aqua combined time series, we still have time series contaminated by missing values (Table 10). To overcome this issue and impute the time series, the user can apply different models, namely recurrent neural network (RNN)-based time series imputation models, such as the Bidirectional Recurrent Imputation for Time Series (BRITS) (Cao et al., 2018), or the generative adversarial network (GAN)-based time series imputation models, for example the end-to-end generative adversarial network (E2GAN) (Luo et al., 2019).
-
For some classes, the agreement percentage is less than 100 % (wetlands classes, closed shrublands, and almost all forests classes) because the 15 LULC products do not totally agree. In any case, we tried to slightly decrease the agreement threshold and retain at least a sample of 1000 with the highest agreement percentage. In addition, we are providing at the pixel level the value of the agreement percentage so that the user can control the desired threshold and take it into consideration to evaluate the F1 score of the models.
-
For some pixels, the ADM0-CODE and the ADM1-CODE are null because they are not provided by the GAUL product, especially for almost all the pixels of the class “marine water bodies” (Tables 9 and 10). This is obvious since the GAUL partitions do not cover the seas and oceans.
-
The number of 100 validated pixels is relatively small with regard to some classes containing a high number of pixels. The choice of this number was due to the challenging technical feasibility of the validation process and the lack of control resources. However, the pixels of each class were randomly selected following the maximum distance criteria described in Algorithm 4 which make them spatially representative of each class (Fig. 10).
-
The original dataset is highly imbalanced since there is a high variation of the number of time series between the different 29 classes. This imbalance is due to three reasons: (1) the spatial distribution of the different classes over the world – e.g., barren lands class is more world dominant than moss and lichen lands; (2) the agreement between the 15 LULC products – e.g., with an agreement threshold equal 1, the 15 products are compliant on 223 062 pixels in open shrublands and only on 9 pixels in closed shrublands; and (3) the temporal stability of the 29 classes – e.g., the two water bodies classes are more consistent in time than the three wetlands classes. To train machine learning models it is recommended to balance the dataset by selecting pixels evenly distributed over the world, with high agreement percentage and with high temporal availability percentage. Thus, we also provided a balanced subset of the original dataset containing 1000 pixels in each class, such that they are evenly distributed and representative of the globe (Algorithm 4).
This dataset (Version 1.2) (Khaldi et al., 2022) is available to the public through an unrestricted data repository hosted by Zenodo at https://doi.org/10.5281/zenodo.5913554.
Accurate LULC mapping is highly relevant for many applications, including Earth system modeling, environmental monitoring, management and planning, or natural hazard assessment, among many others. However, there still exists a high level of disagreement across current global LULC products, particularly for some LULC classes. To address the challenge of improving LULC products, we have created a smart open-source global dataset of multispectral time series for 29 LULC classes containing almost 6 million pixels annotated by using the spatial–temporal agreement across 15 global LULC products available in GEE. The 29 LULC classes were hierarchically grouped into a legend with five levels. The monthly seven-band time series dataset was made by merging the two MODIS sensor data records, Terra and Aqua, at 500 m resolution and expands 22 years from 2000 to the end of 2021. Each pixel is provided with a set of metadata about geographic coordinates, country and departmental divisions, spatial–temporal consistency across LULC products, temporal data availability, and the global human modification index. Finally, to assess the annotation quality of the dataset, a sample of 100 pixels per class, evenly distributed around the world, was selected by maximizing the distance among sampled pixels and validated with photo-interpretation by experts using very high resolution images from both Google Earth and Bing Maps. The overall F1 score of the annotation varied from 96 % at the coarser classification level to 87 % at the finest level. This smartly pre-processed and annotated dataset is targeted towards scientific users interested in developing and evaluating various machine learning models, including deep learning networks, to perform global LULC mapping.
Table A1Translation of TimeSpec4LULC legend to FAO's Land Cover Classification System (LCCS).
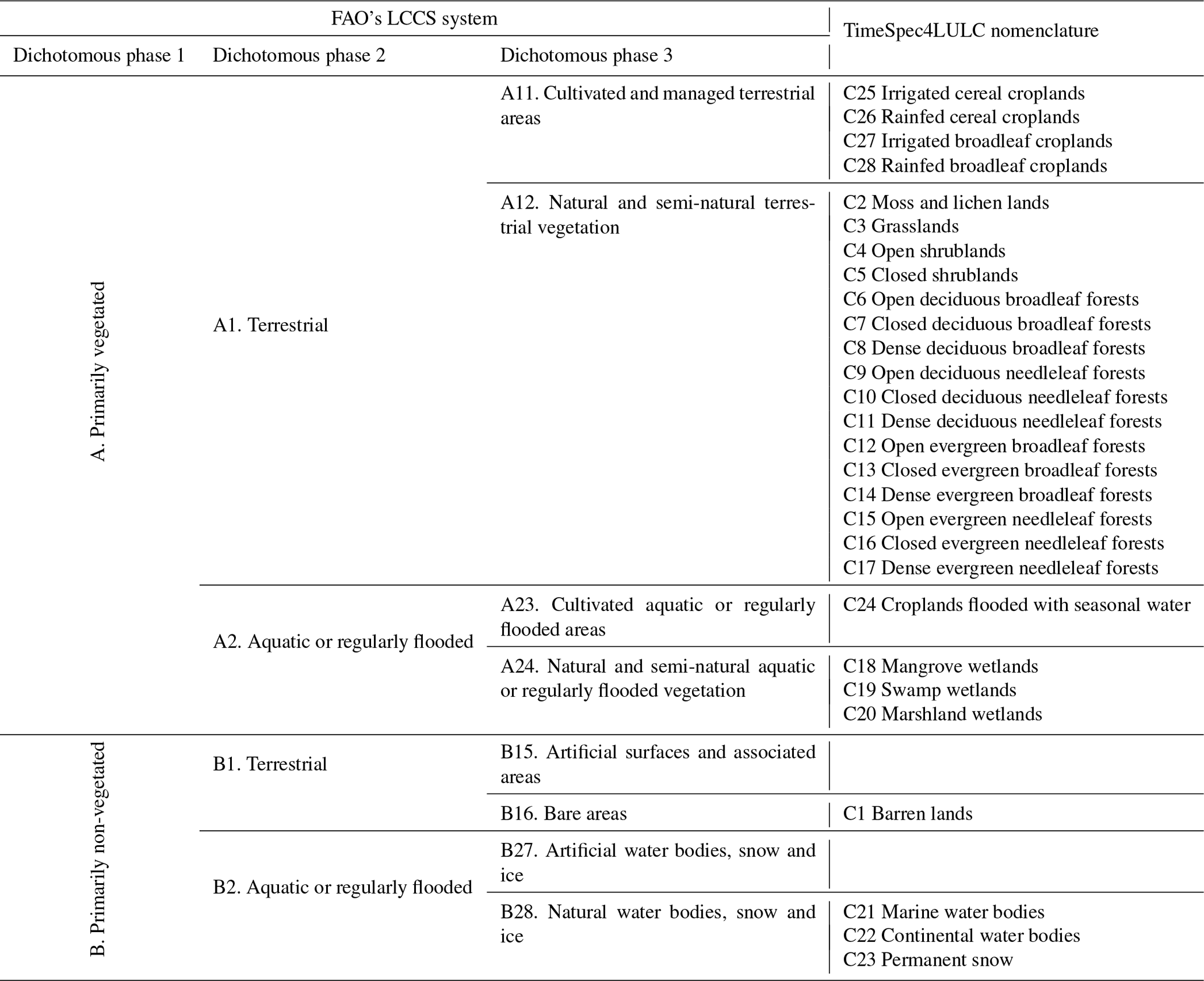
Table A2Detailed description of each LULC class used to build the legend for TimeSpec4LULC dataset. NU: not used. NA: not available.

RK contributed to the conception of the dataset, developed the data scripts, performed the data extraction, and wrote the paper. DAS contributed to the conception and design of the dataset, assessed its quality, provided guidance, wrote the paper, and supervised the whole process. EG assessed the quality of the dataset. YB contributed to the conception of the dataset. AEA and FH provided edits and suggestions. ST contributed to the conception of the dataset, provided guidance, and wrote the paper.
The contact author has declared that neither they nor their co-authors have any competing interests.
This article is part of the special issue “Benchmark datasets and machine learning algorithms for Earth system science data (ESSD/GMD inter-journal SI)”. It is not associated with a conference.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
We thank Howard E. Epstein and Amanda Armstrong from the Essential Biodiversity Variables – ScaleUp (EBV-ScaleUp) project, and we very much appreciate the technical support from Juan Torres-Batlló, a data scientist from EO Data Science, for helping with GEE issues. We would like to thank GEE for providing free access to their platform for performing large-scale satellite data visualization and processing, as well as all the authors and organizations of the LULC products used in our study. We would also like to thank the editorial team, specifically the editor Francesco N. Tubiello, Kirsten Elger, and two anonymous reviewers for their constructive reviews, which greatly improved the structure and quality of the paper. This work aims to contribute to GEO BON's working group on ecosystem structure essential biodiversity variables.
This work was partially supported by DETECTOR (grant no. A-RNM-256-UGR18, Universidad de Granada/FEDER), LifeWatch SmartEcoMountains (grant no. LifeWatch-2019-10-UGR-01, Ministerio de Ciencia e Innovación/Universidad de Granada/FEDER), BBVA DeepSCOP (Ayudas Fundación BBVA a Equipos de Investigación Científica 2018), DeepL-ISCO (grant no. A-TIC-458-UGR18, Ministerio de Ciencia e Innovación/FEDER), SMART-DASCI (grant no. TIN2017-89517-P, Ministerio de Ciencia e Innovación/Universidad de Granada/FEDER), BigDDL-CET (grant no. P18-FR-4961, Ministerio de Ciencia e Innovación/Universidad de Granada/FEDER), RESISTE (grant no. P18-RT-1927, Consejería de Economía, Conocimiento y Universidad from the Junta de Andalucía/FEDER), Ecopotential (grant no. 641762, European Commission), PID2020-119478GB-I00, the Consellería de Educación, Cultura y Deporte de la Generalitat Valenciana, the European Social Fund (grant no. APOSTD/2021/188), the European Research Council (ERC grant no. 647038/BIODESERT), and the Group on Earth Observations and Google Earth Engine (Essential Biodiversity Variables – ScaleUp project).
This paper was edited by Francesco N. Tubiello and reviewed by two anonymous referees.
Alexakis, D. D., Grillakis, M. G., Koutroulis, A. G., Agapiou, A., Themistocleous, K., Tsanis, I. K., Michaelides, S., Pashiardis, S., Demetriou, C., Aristeidou, K., Retalis, A., Tymvios, F., and Hadjimitsis, D. G.: GIS and remote sensing techniques for the assessment of land use change impact on flood hydrology: the case study of Yialias basin in Cyprus, Nat. Hazards Earth Syst. Sci., 14, 413–426, https://doi.org/10.5194/nhess-14-413-2014, 2014. a
Aqu: MYD09A1, https://developers.google.com/earth-engine/datasets/catalog/MODIS_006_MYD09A1?hl=en, last access: 10 January 2022. a
Arino, O., Bicheron, P., Achard, F., Latham, J., Witt, R., and Weber, J.-L.: The most detailed portrait of Earth, Eur. Space Agency, 136, 25–31, 2008. a
Bartholome, E. and Belward, A. S.: GLC2000: a new approach to global land cover mapping from Earth observation data, Int. J. Remote Sens., 26, 1959–1977, 2005. a
Bojinski, S., Verstraete, M., Peterson, T. C., Richter, C., Simmons, A., and Zemp, M.: The concept of essential climate variables in support of climate research, applications, and policy, B. Am. Meteorol. Soc., 95, 1431–1443, 2014. a
Buchhorn, M., Lesiv, M., Tsendbazar, N.-E., Herold, M., Bertels, L., and Smets, B.: Copernicus global land cover layers – collection 2, Remote Sens., 12, 1044, https://doi.org/10.3390/rs12061044, 2020. a
Cao, W., Wang, D., Li, J., Zhou, H., Li, L., and Li, Y.: Brits: Bidirectional recurrent imputation for time series, arXiv preprint arXiv:1805.10572, 2018. a
CGL: CGLS-LC100, https://developers.google.com/earth-engine/datasets/catalog/COPERNICUS_Landcover_100m_Proba-V-C3_Global?hl=en##description, last access: 10 January 2022. a
Congalton, R. G., Gu, J., Yadav, K., Thenkabail, P., and Ozdogan, M.: Global land cover mapping: A review and uncertainty analysis, Remote Sens., 6, 12070–12093, 2014. a, b
de la Cruz, M., Quintana-Ascencio, P. F., Cayuela, L., Espinosa, C. I., and Escudero, A.: Comment on “The extent of forest in dryland biomes”, Science, 358, 2017. a
Di Gregorio, A.: Land cover classification system: classification concepts and user manual: LCCS, vol. 2, Food & Agriculture Org., ISBN 92-5-105327-8, 2005. a
Duveiller, G., Caporaso, L., Abad-Viñas, R., Perugini, L., Grassi, G., Arneth, A., and Cescatti, A.: Local biophysical effects of land use and land cover change: towards an assessment tool for policy makers, Land Use Policy, 91, 104382, https://doi.org/10.1016/j.landusepol.2019.104382, 2020. a
Estes, L., Chen, P., Debats, S., Evans, T., Ferreira, S., Kuemmerle, T., Ragazzo, G., Sheffield, J., Wolf, A., Wood, E., et al.: A large-area, spatially continuous assessment of land cover map error and its impact on downstream analyses, Global Change Biol., 24, 322–337, 2018. a, b
Feddema, J. J., Oleson, K. W., Bonan, G. B., Mearns, L. O., Buja, L. E., Meehl, G. A., and Washington, W. M.: The importance of land-cover change in simulating future climates, Science, 310, 1674–1678, 2005. a
Feng, M. and Bai, Y.: A global land cover map produced through integrating multi-source datasets, Big Earth Data, 3, 191–219, 2019. a
Friedl, M. and Sulla-Menashe, D.: MCD12Q1 MODIS/Terra+Aqua Land Cover Type Yearly L3 Global 500 m SIN Grid V006, NASA EOSDIS Land Processes DAAC [data set], doi10.5067/MODIS/MCD12Q1.006, 2019. a
Fritz, S., You, L., Bun, A., See, L., McCallum, I., Schill, C., Perger, C., Liu, J., Hansen, M., and Obersteiner, M.: Cropland for sub-Saharan Africa: A synergistic approach using five land cover data sets, Geophys. Res. Lett., 38, 1–6, https://doi.org/10.1029/2010GL046213, 2011. a
Gao, Y., Liu, L., Zhang, X., Chen, X., Mi, J., and Xie, S.: Consistency Analysis and Accuracy Assessment of Three Global 30-m Land-Cover Products over the European Union using the LUCAS Dataset, Remote Sens., 12, 3479, https://doi.org/10.3390/rs12213479, 2020. a, b
García-Gil, D., Luengo, J., García, S., and Herrera, F.: Enabling smart data: noise filtering in big data classification, Information Sciences, 479, 135–152, 2019. a
García-Mora, T. J., Mas, J.-F., and Hinkley, E. A.: Land cover mapping applications with MODIS: a literature review, Int. J. Dig. Earth, 5, 63–87, 2012. a, b
GAU: FAO-GAUL Level0, https://developers.google.com/earth-engine/datasets/catalog/FAO_GAUL_2015_level0, last access: 10 January 2022a. a
GAU: FAO-GAUL Level1, https://developers.google.com/earth-engine/datasets/catalog/FAO_GAUL_2015_level1, last access: 10 January 2022b. a
Gengler, S. and Bogaert, P.: Combining land cover products using a minimum divergence and a Bayesian data fusion approach, Int. J. Geogr. Inf. Sci., 32, 806–826, 2018. a
GFC: GFCC, https://developers.google.com/earth-engine/datasets/catalog/NASA_MEASURES_GFCC_TC_v3?hl=en, last access: 10 January 2022a. a
GFC: GFCH, https://developers.google.com/earth-engine/datasets/catalog/NASA_JPL_global_forest_canopy_height_2005, last access: 10 January 2022b. a
GFS: GFSAD 1000, https://developers.google.com/earth-engine/datasets/catalog/USGS_GFSAD1000_V1?hl=en, last access: 10 January 2022. a
Glo: GlobCover, https://developers.google.com/earth-engine/datasets/catalog/ESA_GLOBCOVER_L4_200901_200912_V2_3?hl=en, last access: 10 January 2022. a
Gómez, C., White, J. C., and Wulder, M. A.: Optical remotely sensed time series data for land cover classification: A review, ISPRS J. Photogramm., 116, 55–72, 2016. a
Gong, P., Wang, J., Yu, L., Zhao, Y., Zhao, Y., Liang, L., Niu, Z., Huang, X., Fu, H., Liu, S., et al.: Finer resolution observation and monitoring of global land cover: First mapping results with Landsat TM and ETM+ data, Int. J. Remote Sens., 34, 2607–2654, 2013. a
Gong, P., Li, X., Wang, J., Bai, Y., Chen, B., Hu, T., Liu, X., Xu, B., Yang, J., Zhang, W., et al.: Annual maps of global artificial impervious area (GAIA) between 1985 and 2018, Remote Sens. Environ., 236, 111510, https://doi.org/10.1016/j.rse.2019.111510, 2020. a
Gorelick, N., Hancher, M., Dixon, M., Ilyushchenko, S., Thau, D., and Moore, R.: Google Earth Engine: Planetary-scale geospatial analysis for everyone, Remote Sens. Environ., 202, 18–27, https://doi.org/10.1016/j.rse.2017.06.031, 2017. a
Grekousis, G., Mountrakis, G., and Kavouras, M.: An overview of 21 global and 43 regional land-cover mapping products, Int. J. Remote Sens., 36, 5309–5335, 2015. a, b
Guirado, E., Tabik, S., Alcaraz-Segura, D., Cabello, J., and Herrera, F.: Deep-learning versus OBIA for scattered shrub detection with Google earth imagery: Ziziphus Lotus as case study, Remote Sensing, 9, 1220, https://doi.org/10.3390/rs9121220, 2017. a
Guirado, E., Blanco-Sacristán, J., Rodríguez-Caballero, E., Tabik, S., Alcaraz-Segura, D., Martínez-Valderrama, J., and Cabello, J.: Mask R-CNN and OBIA Fusion Improves the Segmentation of Scattered Vegetation in Very High-Resolution Optical Sensors, Sensors, 21, 320, https://doi.org/10.3390/s21010320, 2021. a
Han: Hansen, https://developers.google.com/earth-engine/datasets/catalog/UMD_hansen_global_forest_change_2019_v1_7, last access: 10 January 2022. a
Hansen, M. C., Potapov, P. V., Moore, R., Hancher, M., Turubanova, S. A., Tyukavina, A., Thau, D., Stehman, S. V., Goetz, S. J., Loveland, T. R., Kommareddy, A., Egorov, A., Chini, L., Justice, C. O., and Townshend, J. R. G.: High-Resolution Global Maps of 21st-Century Forest Cover Change, Science, 342, 850–853, https://doi.org/10.1126/science.1244693, 2013. a
Hoskins, A. J., Bush, A., Gilmore, J., Harwood, T., Hudson, L. N., Ware, C., Williams, K. J., and Ferrier, S.: Downscaling land-use data to provide global estimates of five land-use classes, Ecol. Evol., 6, 3040–3055, 2016. a
Hubert-Moy, L., Thibault, J., Fabre, E., Rozo, C., Arvor, D., Corpetti, T., and Rapinel, S.: Time-series spectral dataset for croplands in France (2006–2017), Data in Brief, 27, 104810, https://doi.org/10.1016/j.dib.2019.104810, 2019. a
JRC: JRC Global Surface Water, https://developers.google.com/earth-engine/datasets/catalog/JRC_GSW1_2_GlobalSurfaceWater, last access: 10 January 2022a. a
JRC: JRC Yearly Water, https://developers.google.com/earth-engine/datasets/catalog/JRC_GSW1_2_YearlyHistory, last access: 10 January 2022b. a
Jung, M., Henkel, K., Herold, M., and Churkina, G.: Exploiting synergies of global land cover products for carbon cycle modeling, Remote Sens. Environ., 101, 534–553, 2006. a
Kennedy, C. M., Oakleaf, J. R., Theobald, D. M., Baruch-Mordo, S., and Kiesecker, J.: Managing the middle: A shift in conservation priorities based on the global human modification gradient, Global Change Biol., 25, 811–826, 2019. a
Kerr, J. T. and Ostrovsky, M.: From space to species: ecological applications for remote sensing, Trends Ecol. Evol., 18, 299–305, 2003. a
Khaldi, R., Alcaraz-Segura, D., Guirado, E., Benhammou, Y., and Tabik, S.: TimeSpec4LULC: A Smart-Global Dataset of Multi- Spectral Time Series of MODIS Terra-Aqua from 2000 to 2021 for Training Machine Learning models to perform LULC Mapping, https://doi.org/10.5281/zenodo.5913554, 2022. a, b, c
Kong, F., Li, X., Wang, H., Xie, D., Li, X., and Bai, Y.: Land cover classification based on fused data from GF-1 and MODIS NDVI time series, Remote Sensing, 8, 741, https://doi.org/10.3390/rs8090741, 2016. a, b
Lambin, E. F. and Geist, H. J. (Eds.): Land-use and land-cover change: local processes and global impacts, Springer Science & Business Media, ISBN-10 3-540-32201-9, 2008. a
Liu, L., Zhang, X., Gao, Y., Chen, X., Shuai, X., and Mi, J.: Finer-Resolution Mapping of Global Land Cover: Recent Developments, Consistency Analysis, and Prospects, J. Remote Sens., 2021, 1–38, 2021. a, b
Loveland, T. R., Reed, B. C., Brown, J. F., Ohlen, D. O., Zhu, Z., Yang, L., and Merchant, J. W.: Development of a global land cover characteristics database and IGBP DISCover from 1 km AVHRR data, Int. J. Remote Sens., 21, 1303–1330, 2000. a
Luengo, J., García-Gil, D., Ramírez-Gallego, S., García, S., and Herrera, F.: Big data preprocessing – Enabling Smart Data, Springer, Cham, ISBN 978-3-030-39105-8, 2020. a
Luo, Y., Zhang, Y., Cai, X., and Yuan, X.: E2gan: End-to-end generative adversarial network for multivariate time series imputation, in: AAAI Press, 3094–3100, ISBN 9780999241141, 2019. a
Luoto, M., Virkkala, R., and Heikkinen, R. K.: The role of land cover in bioclimatic models depends on spatial resolution, Global Ecol. Biogeogr., 16, 34–42, 2007. a
MCD: MCD12Q1.006, https://developers.google.com/earth-engine/datasets/catalog/MODIS_006_MCD12Q1?hl=en, last access: 10 January 2022. a
Menke, S., Holway, D., Fisher, R., and Jetz, W.: Characterizing and predicting species distributions across environments and scales: Argentine ant occurrences in the eye of the beholder, Global Ecol. Biogeogr., 18, 50–63, 2009. a
Meyer, W. B. and Turner II, B. L.: Changes in land use and land cover: a global perspective, vol. 4, Cambridge University Press, ISBN 0-521-47085-4, 1994. a
Moser, S. C.: A partial instructional module on global and regional land use/cover change: assessing the data and searching for general relationships, GeoJournal, 39, 241–283, 1996. a
Muchoney, D., Strahler, A., Hodges, J., and LoGastro, J.: Terrestrial Ecosystem Parameteilzation: Tools for Validating Global Land-Gover Data, Photogramm. Eng., 65, 1061–1067, 1999. a
Oki, T., Blyth, E. M., Berbery, E. H., and Alcaraz-Segura, D.: Land use and land cover changes and their impacts on hydroclimate, ecosystems and society, in: Climate science for serving society, edited by: Asrar, G. R. and Hurrell, J. W., Springer, 185–203, ISBN 978-94-007-6692-1, 2013. a
PAL: PALSAR, https://developers.google.com/earth-engine/datasets/catalog/JAXA_ALOS_PALSAR_YEARLY_FNF?hl=en, last access: 10 January 2022. a
Patel, S. K., Verma, P., and Singh, G. S.: Agricultural growth and land use land cover change in peri-urban India, Environ. Monit. Assess., 191, 1–17, 2019. a
Pekel, J.-F., Cottam, A., Gorelick, N., and Belward, A. S.: High-resolution mapping of global surface water and its long-term changes, Nature, 540, 418–422, 2016. a, b
Pérez-Hoyos, A., García-Haro, F. J., and San-Miguel-Ayanz, J.: A methodology to generate a synergetic land-cover map by fusion of different land-cover products, Int. J. Appl. Earth Obs., 19, 72–87, 2012. a
Pettorelli, N., Wegmann, M., Skidmore, A., Mücher, S., Dawson, T. P., Fernandez, M., Lucas, R., Schaepman, M. E., Wang, T., O'Connor, B., Jongman, R. H. G., Kempeneers, P., Sonnenschein, R., Leidner, A. K., Böhm, M., He, K. S., Nagendra, H., Dubois, G., Fatoyinbo, T., Hansen, M. C., Paganini, M., de Klerk, H. M., Asner, G. P., Kerr, J. T., Estes, A. B., Schmeller, D. S., Heiden, U., Rocchini, D., Pereira, H. M., Turak, E., Fernandez, N., Lausch, A., Cho, M. A., Alcaraz-Segura, D., McGeoch, M. A., Turner, W., Mueller, A., St-Louis, V., Penner, J., Vihervaara, P., Belward, A., Reyers, B., and Geller, G. N.: Framing the concept of satellite remote sensing essential biodiversity variables: challenges and future directions, Remote Sens. Ecol. Conserv., 2, 122–131, 2016. a
Pfeifer, M., Disney, M., Quaife, T., and Marchant, R.: Terrestrial ecosystems from space: a review of earth observation products for macroecology applications, Global Ecol. Biogeogr., 21, 603–624, 2012. a
Polykretis, C., Grillakis, M. G., and Alexakis, D. D.: Exploring the impact of various spectral indices on land cover change detection using change vector analysis: A case study of Crete Island, Greece, Remote Sensing, 12, 319, https://doi.org/10.3390/rs12020319, 2020. a, b, c
Rußwurm, M., Pelletier, C., Zollner, M., Lefèvre, S., and Körner, M.: BreizhCrops: A Time Series Dataset for Crop Type Mapping, arXiv preprint arXiv:1905.11893, 2019. a
Safonova, A., Guirado, E., Maglinets, Y., Alcaraz-Segura, D., and Tabik, S.: Olive Tree Biovolume from UAV Multi-Resolution Image Segmentation with Mask R-CNN, Sensors, 21, 1617, https://doi.org/10.3390/s21051617, 2021. a
Sexton, J. O., Song, X.-P., Feng, M., Noojipady, P., Anand, A., Huang, C., Kim, D.-H., Collins, K. M., Channan, S., DiMiceli, C., Townshend, J. R.: Global, 30-m resolution continuous fields of tree cover: Landsat-based rescaling of MODIS vegetation continuous fields with lidar-based estimates of error, Int. J. Dig. Earth, 6, 427–448, 2013. a
Shimada, M., Itoh, T., Motooka, T., Watanabe, M., Shiraishi, T., Thapa, R., and Lucas, R.: New global forest/non-forest maps from ALOS PALSAR data (2007–2010), Remote Sens. Environ., 155, 13–31, 2014. a
Simard, M., Pinto, N., Fisher, J. B., and Baccini, A.: Mapping forest canopy height globally with spaceborne lidar, J. Geophys. Res.-Biogeo., 116, 1–12, 2011. a
Steffen, W., Richardson, K., Rockström, J., Cornell, S. E., Fetzer, I., Bennett, E. M., Biggs, R., Carpenter, S. R., De Vries, W., De Wit, C. A., Folke, C., Gerten, D., Heinke, J., Mace, G. M., Persson, L. M., Ramanathan, V., Reyers, B., and Sörlin, S.: Planetary boundaries: Guiding human development on a changing planet, Science, 347, 1–11, 2015. a
Teluguntla, P., Thenkabail, P. S., Xiong, J., Gumma, M. K., Giri, C., Milesi, C., Ozdogan, M., Congalton, R., Tilton, J., Sankey, T. T., Massey, R., Phalke, A., and Yadav, K.: Global Cropland Area Database (GCAD) derived from Remote Sensing in Support of Food Security in the Twenty-first Century: Current Achievements and Future Possibilities, in: Land Resources Monitoring, Modeling, and Mapping with Remote Sensing (Remote Sensing Handbook). Taylor & Francis, Boca Raton, Florida, 01–45, 2015. a
Ter: MOD09A1, https://developers.google.com/earth-engine/datasets/catalog/MODIS_006_MOD09A1?hl=en, last access: 10 January 2022. a
TiS: TiSeLaC, https://sites.google.com/site/dinoienco/tiselac-time-series-land-cover-classification-challenge?authuser=0, last access: 10 January 2022. a
Townshend, J., Justice, C., Li, W., Gurney, C., and McManus, J.: Global land cover classification by remote sensing: present capabilities and future possibilities, Remote Sens. Environ., 35, 243–255, 1991. a
Tsendbazar, N., De Bruin, S., and Herold, M.: Assessing global land cover reference datasets for different user communities, ISPRS J. Photogramm., 103, 93–114, 2015a. a
Tsendbazar, N.-E., De Bruin, S., Fritz, S., and Herold, M.: Spatial accuracy assessment and integration of global land cover datasets, Remote Sensing, 7, 15804–15821, 2015b. a, b
Tsendbazar, N.-E., de Bruin, S., Mora, B., Schouten, L., and Herold, M.: Comparative assessment of thematic accuracy of GLC maps for specific applications using existing reference data, Int. J. Appl. Earth Obs., 44, 124–135, 2016. a, b
Tsi: Tsinghua FROM-GLC, https://developers.google.com/earth-engine/datasets/catalog/Tsinghua_FROM-GLC_GAIA_v10?hl=en, last access: 10 January 2022. a
Tuanmu, M.-N. and Jetz, W.: A global 1-km consensus land-cover product for biodiversity and ecosystem modelling, Global Ecol. Biogeogr., 23, 1031–1045, 2014. a, b
Van Etten, A., Hogan, D., Martinez-Manso, J., Shermeyer, J., Weir, N., and Lewis, R.: The Multi-Temporal Urban Development SpaceNet Dataset, arXiv preprint arXiv:2102.04420, 2021. a
Vancutsem, C., Marinho, E., Kayitakire, F., See, L., and Fritz, S.: Harmonizing and combining existing land cover/land use datasets for cropland area monitoring at the African continental scale, Remote Sens., 5, 19–41, 2013. a
Verburg, P. H., Van De Steeg, J., Veldkamp, A., and Willemen, L.: From land cover change to land function dynamics: a major challenge to improve land characterization, J. Environ. Manage., 90, 1327–1335, 2009. a
Virnodkar, S. S., Pachghare, V. K., Patil, V., and Jha, S. K.: CaneSat dataset to leverage convolutional neural networks for sugarcane classification from Sentinel-2, Journal of King Saud University-Computer and Information Sciences, 2020. a
Xiong, J., Thenkabail, P. S., Gumma, M. K., Teluguntla, P., Poehnelt, J., Congalton, R. G., Yadav, K., and Thau, D.: Automated cropland mapping of continental Africa using Google Earth Engine cloud computing, ISPRS J. Photogramm., 126, 225–244, 2017. a
Xu, P., Herold, M., Tsendbazar, N.-E., and Clevers, J. G.: Towards a comprehensive and consistent global aquatic land cover characterization framework addressing multiple user needs, Remote Sens. Environ., 250, 112034, https://doi.org/10.1016/j.rse.2020.112034, 2020. a
Yirsaw, E., Wu, W., Shi, X., Temesgen, H., and Bekele, B.: Land use/land cover change modeling and the prediction of subsequent changes in ecosystem service values in a coastal area of China, the Su-Xi-Chang Region, Sustainability, 9, 1204, https://doi.org/10.3390/su9071204, 2017. a
Zhang, C., Pan, X., Li, H., Gardiner, A., Sargent, I., Hare, J., and Atkinson, P. M.: A hybrid MLP-CNN classifier for very fine resolution remotely sensed image classification, ISPRS J. Photogramm., 140, 133–144, 2018a. a
Zhang, C., Ye, Y., Fang, X., Li, H., and Wei, X.: Synergistic Modern Global 1 Km Cropland Dataset Derived from Multi-Sets of Land Cover Products, Remote Sens., 11, 2250, https://doi.org/10.3390/rs11192250, 2019. a
Zhang, Q., Yuan, Q., Zeng, C., Li, X., and Wei, Y.: Missing data reconstruction in remote sensing image with a unified spatial–temporal–spectral deep convolutional neural network, IEEE T. Geosci. Remote, 56, 4274–4288, 2018b. a
Zhang, W., Yang, G., Lin, Y., Ji, C., and Gupta, M. M.: On definition of deep learning, in: 2018 World automation congress (WAC), IEEE, 1–5, https://doi.org/10.23919/WAC.2018.8430387, 2018c. a
Zhao, W. and Du, S.: Learning multiscale and deep representations for classifying remotely sensed imagery, ISPRS J. Photogramm., 113, 155–165, 2016. a
Zhao, W., Guo, Z., Yue, J., Zhang, X., and Luo, L.: On combining multiscale deep learning features for the classification of hyperspectral remote sensing imagery, Int. J. Remote Sens., 36, 3368–3379, 2015. a
Zimmer-Gembeck, M. J. and Helfand, M.: Ten years of longitudinal research on US adolescent sexual behavior: Developmental correlates of sexual intercourse, and the importance of age, gender and ethnic background, Dev. Rev. 28, 153–224, 2008. a
- Abstract
- Introduction
- Methods
- Data
- Results and discussions
- Advantages, limitations, and potential applications of the dataset
- Code and data availability
- Conclusions
- Appendix A
- Author contributions
- Competing interests
- Special issue statement
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Methods
- Data
- Results and discussions
- Advantages, limitations, and potential applications of the dataset
- Code and data availability
- Conclusions
- Appendix A
- Author contributions
- Competing interests
- Special issue statement
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References