the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 15 Jun 2021
| 15 Jun 2021
GLC_FCS30: global land-cover product with fine classification system at 30 m using time-series Landsat imagery
Xiao Zhang
Xidong Chen
Yuan Gao
Shuai Xie
Jun Mi
Over past decades, a lot of global land-cover products have been released; however, these still lack a global land-cover map with a fine classification system and spatial resolution simultaneously. In this study, a novel global 30 m land-cover classification with a fine classification system for the year 2015 (GLC_FCS30-2015) was produced by combining time series of Landsat imagery and high-quality training data from the GSPECLib (Global Spatial Temporal Spectra Library) on the Google Earth Engine computing platform. First, the global training data from the GSPECLib were developed by applying a series of rigorous filters to the CCI_LC (Climate Change Initiative Global Land Cover) land-cover and MCD43A4 NBAR products (MODIS Nadir Bidirectional Reflectance Distribution Function-Adjusted Reflectance). Secondly, a local adaptive random forest model was built for each geographical tile by using the multi-temporal Landsat spectral and texture features and the corresponding training data, and the GLC_FCS30-2015 land-cover product containing 30 land-cover types was generated for each tile. Lastly, the GLC_FCS30-2015 was validated using three different validation systems (containing different land-cover details) using 44 043 validation samples. The validation results indicated that the GLC_FCS30-2015 achieved an overall accuracy of 82.5 % and a kappa coefficient of 0.784 for the level-0 validation system (9 basic land-cover types), an overall accuracy of 71.4 % and kappa coefficient of 0.686 for the UN-LCCS (United Nations Land Cover Classification System) level-1 system (16 LCCS land-cover types), and an overall accuracy of 68.7 % and kappa coefficient of 0.662 for the UN-LCCS level-2 system (24 fine land-cover types). The comparisons against other land-cover products (CCI_LC, MCD12Q1, FROM_GLC, and GlobeLand30) indicated that GLC_FCS30-2015 provides more spatial details than CCI_LC-2015 and MCD12Q1-2015 and a greater diversity of land-cover types than FROM_GLC-2015 and GlobeLand30-2010. They also showed that GLC_FCS30-2015 achieved the best overall accuracy of 82.5 % against FROM_GLC-2015 of 59.1 % and GlobeLand30-2010 of 75.9 %. Therefore, it is concluded that the GLC_FCS30-2015 product is the first global land-cover dataset that provides a fine classification system (containing 16 global LCCS land-cover types as well as 14 detailed and regional land-cover types) with high classification accuracy at 30 m. The GLC_FCS30-2015 global land-cover products produced in this paper are free access at https://doi.org/10.5281/zenodo.3986872 (Liu et al., 2020).
- Article
(11039 KB) - Full-text XML
- BibTeX
- EndNote





Global land-cover information, as used by the scientific community, governments, and international organizations, is critical to the understanding of environmental changes, food security, conservation, and the coordination of actions needed to mitigate and adapt to global change (Ban et al., 2015; Chen et al., 2015; Tsendbazar et al., 2015). These data also play an important role in improving the performance of models of the ecosystem, hydrology, and atmosphere (Gong et al., 2013). Accurate and reliable information on global land cover is, therefore, urgently needed (Ban et al., 2015; Zhang et al., 2019).
Due to the frequent and large area coverage that it provides, more and more attention has been attached to using the remote sensing technology for global land-cover mapping. In past decades, several global land-cover products have been produced at various spatial resolutions ranging from 1 km to 300 m (Bontemps et al., 2010; Defourny et al., 2018; Friedl et al., 2010; Loveland et al., 2000; Tateishi et al., 2014). However, owing to differences in classification accuracy, thematic detail, classification schemes, and spatial resolution, the harmonization of these land-cover products is usually difficult (Ban et al., 2015; Gómez et al., 2016; Giri et al., 2013; Grekousis et al., 2015), and their quality is also far from satisfactory for many fine applications (Giri et al., 2005; Grekousis et al., 2015; Y. Yang et al., 2017). Recently, thanks to free access to fine-resolution remote sensing imagery (Landsat and Sentinel-2), combined with rapidly increasing data storage and computation capabilities, global land-cover products at fine spatial resolutions (10 and 30 m) have been successfully developed (Chen et al., 2015; Gong et al., 2013, 2019). Specifically, Chen et al. (2015) used multi-temporal Landsat and similar image data along with the integration of pixel- and object-based methods to produce the GlobeLand30 land-cover product that has an overall classification accuracy of over 80 %. Similarly, Gong et al. (2013, 2019) produced the global 30 and 10 m land-cover products (FROM_GLC30 and FROM_GLC10) using single-date Landsat imagery and multi-temporal Sentinel-2 imagery, respectively. Unlike FROM_GLC10 and GlobeLand30, which have only 10 land-cover types, FROM_GLC30 was classified using 28 detailed land-cover types. However, as the overall accuracy for the detailed land-cover types was only 52.76 % and the patch effects were noticeable due to the temporal differences among the Landsat scenes, FROM_GLC30 focused on the mapping results for just 10 major land-cover types (Gong et al., 2013). Although these products permit the detection of land information at the scale of most human activity and offer increased flexibility for the environmental model parameterization needed for global land-cover studies (Ban et al., 2015), the simple classification system and large amount of manual work required (manual collection of training samples and knowledge-based interactive verification) limit their greater use in many specific and fine applications at regional or global scales.
As Giri et al. (2013) and Ban et al. (2015) stated, there are a number of challenges to overcome in producing a fine-resolution characterization of global land cover. These include the unavailability of timely, accurate, and sufficient training data; the high cost of collecting satellite data with consistent global coverage; difficulties in preparing image mosaics; and the need for high-performance computing facilities.
Firstly, Foody and Arora (2010) stated that the training data had more impact on the classification results than the selection of the classifier: the collection of timely, accurate, and sufficient training data is especially important for global or regional land-cover mapping. Generally, the collection of training data can be divided into two types of method: interpretation-based methods and the derivation of training samples from existing land-cover products. Specifically, the interpretation-based methods are widely used in regional land-cover classification because high confidence in the training data can be guaranteed (Xie et al., 2018; Zhu et al., 2016). However, for large-area land-cover mapping, the interpretation of sufficient and accurate training data usually involves a huge amount of manual work. For example, Gong et al. (2013) collected 91 433 training samples using 27 image analysts who were experienced in remote-sensing image interpretation. Similarly, Tateishi et al. (2014) selected 312 753 training points from 2080 prior training polygons (Tateishi et al., 2011) and used a large amount of reference data, including Google Earth images from around 2008, existing regional land-cover maps, and MODIS NDVI phenological curves from 2008. Despite the total number of training samples apparently being large in the works of Gong et al. (2013) and Tateishi et al. (2014), in fact, in terms of global land-cover mapping, these training samples still provided only sparse coverage: Zhu et al. (2016) suggested that the optimal number of training pixels needed to classify an area about the size of a Landsat scene was about 20 000. Furthermore, the land-cover diversity (the number of land-cover types in the final results) of training data is also constrained by the available expert knowledge: for example, Chen et al. (2015) produced a global land-cover product (GlobeLand30) containing only 10 land-cover types; Gong et al. (2019) developed the first global 10 m land-cover product (FROM_GLC10), which also contained 10 major land-cover types.
Compared with the interpretation-based methods, the second type of data collection method – deriving training samples from existing land-cover products – has been demonstrated to have many significant advantages, including fully automated collection and refinement of training data, the production of a large and geographically distributed training dataset, and the possibility of using the same land-cover classes as existing land-cover products (Inglada et al., 2017; Jokar Arsanjani et al., 2016b; Liu et al., 2017; Radoux et al., 2014; Wessels et al., 2016; Xian et al., 2009; Zhang and Roy, 2017; Zhang et al., 2018, 2019). For these reasons, this type of data collection has recently attracted more attention in large-area land-cover mapping. For example, Radoux et al. (2014) used the coarse-resolution land-cover products Global Land Cover (GLC) 2000 and Corine Land Cover (CLC) 2006 to develop 300 m land-cover results for South America and Eurasia, respectively; Zhang and Roy (2017) used the MODIS land-cover product (MCD12Q1) to classify time series of Landsat imagery and then produce a 30 m land-cover classification of North America, achieving an overall agreement of 95.44 % and a kappa coefficient of 0.9443. Recently, Zhang et al. (2019) proposed simultaneously using the MODIS Nadir Bidirectional Reflectance Distribution Function-Adjusted Reflectance (MCD43A4 NBAR) and the CCI_LC (European Space Agency Climate Change Initiative Global Land Cover) land-cover product from 2015 to generate a 30 m Landsat land-cover dataset for China. However, as well as these advantages, there is the problem that the derived training data might be affected by classification errors in the existing land-cover products and by spatial resolution and temporal differences between the land-cover products and the satellite data that are to be classified. In recent years, many researchers have proposed various measures to ensure that only reliably defined training data are extracted: for example, Radoux et al. (2014) proposed the use of spatial and spectral filters to remove outliers, and Zhang and Roy (2017) proposed that only MCD12Q1 pixels that had been stable for 3 consecutive years should be used and that these pixels should be refined using the “metric centroid” method developed by Roy and Kumar (2016). In summary, if effective measures can be taken to control the confidence and reliability of the training data, the derivation of training samples from existing land-cover products has great potential for global land-cover mapping.
Secondly, the high cost of collecting satellite data with consistent global coverage, the lack of high-performance-computing requirements, and the difficulties in preparing image mosaics also cause problems. However, because the Google Earth Engine (GEE) cloud-based platform consists of a multi-petabyte analysis-ready data catalog co-located with a high-performance, intrinsically parallel computation service and because the library's image-based functions in the GEE are per-pixel algebraic operations (Gorelick et al., 2017), these difficulties can be easily solved by using the GEE cloud-computation platform. In recent years, many large-area land-cover classifications have been produced based on the GEE cloud computation platform: for example, Teluguntla et al. (2018) successfully derived 30 m cropland extent products for Australia and China, which had overall accuracies of 97.6 % and 94 %, on the GEE platform. Gong et al. (2019) produced the first global 10 m land-cover product using time series of Sentinel-2 imagery also on the GEE platform.
Overall, due to the difficulties in collecting sufficient accurate training data with a fine classification system and the computing requirements involved, producing a global 30 m land-cover classification with a fine classification system is a challenging and labor-intensive task. This paper presents an automatic classification strategy for producing a global land-cover product with a fine classification system at a spatial resolution of 30 m for 2015 (GLC_FCS30-2015) using the Google Earth Engine cloud computation platform. To achieve this goal, we first derived the global training data from the updated Global Spatial Temporal Spectra Library (GSPECLib), which was developed by combining the MCD43A4 NBAR surface reflectance product and the CCI_LC land-cover product for 2015. Secondly, time series of Landsat imagery on the GEE platform were collected and then temporally composited into several temporal spectral and texture metrics using the metrics-composite method. Finally, by combining a multi-temporal random forest model, global training data, and Landsat temporal features, a global annual land-cover map with 30 land-cover types was produced. The validation results indicated that the GLC_FCS30-2015 is a promising land-cover product and could provide important support for numerous regional or global applications.
2.1 Satellite datasets
2.1.1 Landsat surface reflectance data
Taking account of the frequent contamination of cloud in the remote sensing imagery, particularly in the tropics, all Landsat-8 surface reflectance (SR) imagery from 2014–2016 archived on the GEE platform was collected for the nominal year 2015. Each Landsat-8 SR image on the GEE was atmospherically corrected by the Landsat Surface Reflectance Code (LaSRC) atmospheric correction method (Roy et al., 2014; Vermote et al., 2016), and bad pixels – including cloud, cloud shadow, and saturated pixels – were identified by the CFMask algorithm (Zhu et al., 2015; Zhu and Woodcock, 2012). In this study, only six optical bands – blue, green, red, near infrared (NIR), SWIR1, and SWIR2 – were used for land-cover classification because the coastal band is easily affected by the atmosphere conditions (Wang et al., 2016).
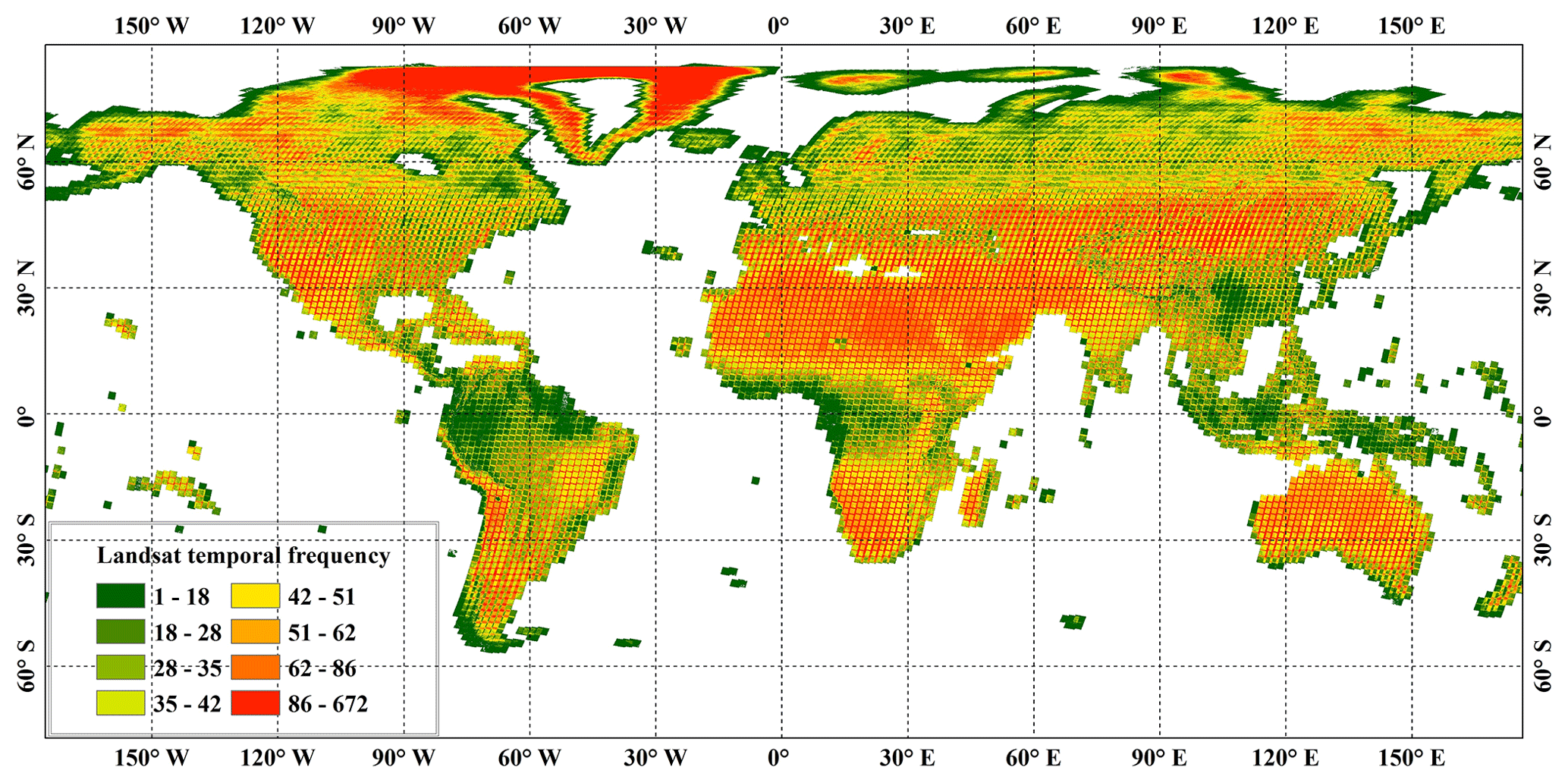
Figure 1The availability of clear-sky Landsat SR imagery for the years 2014–2016 on the GEE platform.
Figure 1 illustrates the clear-sky Landsat-8 SR temporal frequency after the cloud, cloud shadow, and saturated pixels have been masked out. The statistical results indicated that (1) most land areas, except for tropical areas, had a high availability of clear-sky Landsat imagery, and (2) areas with a low frequency of clear-sky Landsat SR were mainly located in rainforest areas including the Amazon rainforest, African rainforests, and Indian–Malay rainforests, which are areas mainly covered by evergreen broadleaved forests.
2.1.2 Digital elevation model data
Over the past few years, many studies have demonstrated that a digital elevation model (DEM) and variables derived from it (slope and aspect) are necessary and important auxiliary variables for land-cover mapping (Gomariz-Castillo et al., 2017; Zhang et al., 2019). In this study, the Shuttle Radar Topography Mission (SRTM) DEM, which has a spatial resolution of 30 m and covers the area between 60∘ N and 56∘ S (Farr et al., 2007), and the slope and aspect variables, were used as the classification features. It should be noted that this dataset archived on the GEE platform has been optimized by a void-filling process that uses other open-source DEM data. Furthermore, to complement the missing SRTM data at high latitudes, the GDEM2 DEM dataset (Tachikawa et al., 2011) was collected.
2.2 Global 30 m impervious surface products
Due to the spectral heterogeneity and complicated make-up of impervious surfaces, large-area impervious mapping is usually challenging and difficult (Chen et al., 2015; Gong et al., 2013; Zhang and Roy, 2017). For example, in our previous work Zhang et al. (2019), impervious surfaces had a low producer's accuracy of 50.7 % because fragmented impervious surfaces such as rural cottages, roads, etc., were easily missed. Therefore, Chen et al. (2015) split the impervious surface class into three independent sub-classes including “vegetated”, “low reflectance”, and “high reflectance” and then used the classification method of integrating pixel- and object-based techniques and manual editing to produce accurate global impervious surface products.
In this study, the global land-cover classification neglected the impervious surface land-cover type when building the classification model; instead, existing global 30 m impervious surface products for 2015 (MSMT_IS30-2015) were directly superimposed over the global land-cover classifications (Zhang et al., 2020). The MSMT_IS30-2015 dataset was produced in our previous work and developed by combining 420 000 Landsat-8 SR and 83 500 Sentinel-1 SAR images from around the globe on the GEE platform. The validation results indicated that the MSMT_IS30-2015 product achieved an overall accuracy of 95.1 % and a kappa coefficient of 0.898 using 11 942 validation samples from 15 representative regions. The MSMT_IS30-2015 dataset is available at https://doi.org/10.5281/zenodo.3505079 (Zhang and Liu, 2019).
2.3 Global validation datasets
To guarantee the confidence of the validation points, several existing prior datasets (see Table 1), high-resolution Google Earth imagery, and time series of NDVI values for each vegetated point were integrated to derive the global validation datasets. Many studies have demonstrated that an inappropriately sized validation sample could lead to limited and sometimes erroneous assessments of accuracy (Foody, 2009 and Olofsson et al., 2014); therefore, a stratified random sampling based on the proportion of the land-cover areas was adapted to determine the sample size of each land-cover type:
where Wi was the area proportion for class i over the globe, Si is the standard deviation of class i, is the standard error of the estimated overall accuracy, pi is the expected accuracy of class i, and ni represents the sample size of the class i.
Table 1Multi-source auxiliary datasets used for collecting the global validation samples.
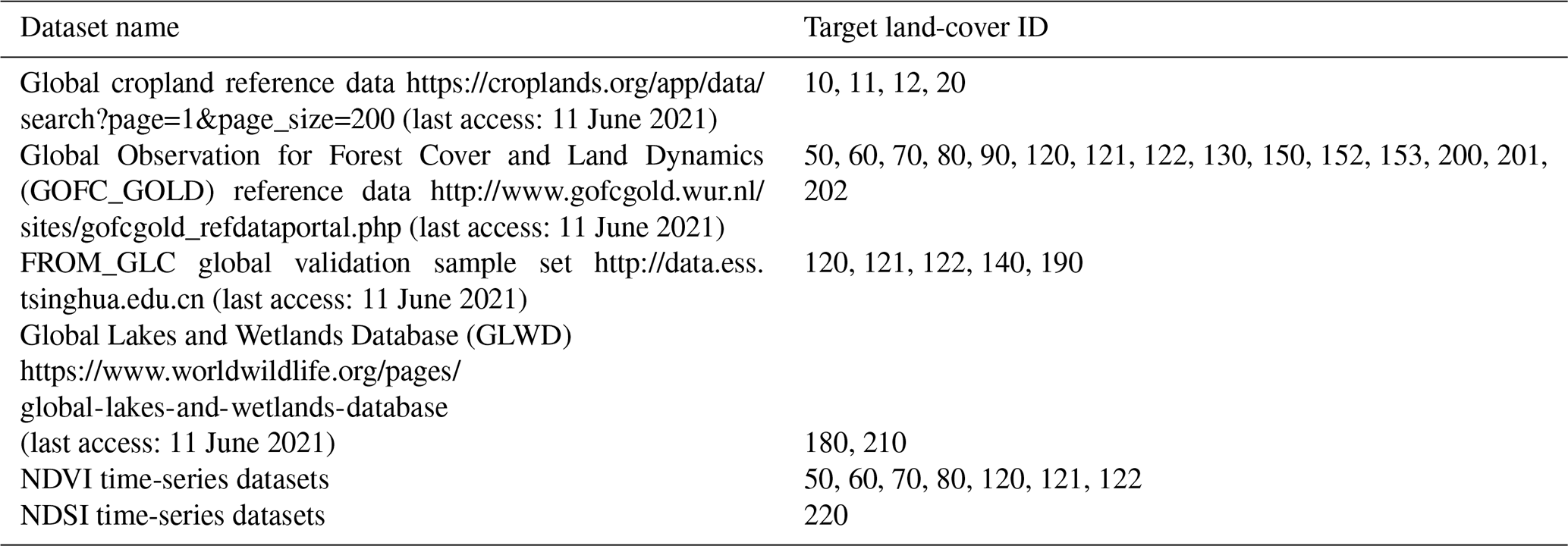
Note: for details of the land-cover IDs, refer to Table 2.
First, the cropland-related validation samples were directly inherited from the global cropland reference data, which were first collected by worldwide crowdsourcing using the ground data collection mobile app and then reviewed using high-resolution imagery in the online image interpretation tool to ensure that the samples were centered on agricultural fields. There are 22 823 cropland validation samples in the reference dataset (Xiong et al., 2017). In addition, due to the possible temporal interval between the acquisition of the reference data and the GLC_FCS30 products (2015), the reference samples were checked by three interpreters using the high-resolution imagery for 2015 in the Google Earth software and were discarded if the judgements of three experts were in disagreement. After discarding wrong cropland points and resampling using Eq. (1), a total of 6917 cropland samples in 2015 were retained.
Secondly, the GOFC_GOLD datasets contained several reference datasets which included the Global Land Cover National Mapping Organizations (GLCNMO) 2008 (Tateishi et al., 2014) training dataset, the Visible Infrared Imaging Radiometer Suite (VIIRS) dataset, the MODIS Land Cover (MCD12Q1) product System for Terrestrial Ecosystem Parameterization (STEP) dataset, the GlobCover2005 validation database, and the GLC2000 database (Herold et al., 2010). In this study, the GlobCover2005 and GLC2000 datasets were removed because they were too sparse and also because the temporal difference between them and our GLC_FCS30-2015 products was too big. The GLCNMO, VIIRS, and STEP datasets all contained numerous validation polygons, so we first rechecked each validation polygon against the high-resolution imagery for 2015 and then randomly selected several validation points within each refined polygon.
Table 2The fine classification system and its relationships with other classification systems (LCCS and GlobeLand30 Level 0).

Specifically, as the GLCNMO used the UN LCCS (United Nations Land Cover Classification System), similar to our study (Table 2), and the VIIRS and STEP datasets followed the IGBP (International Geosphere Biosphere Programme) classification system, and as the land-cover types had consistent definitions in both the UN LCCS and IGBP classification systems (including land-cover IDs 50, 60, 70, 80, 90, 130 and 200: see Table 2), the corresponding validation points were randomly collected from each polygon for all three datasets. For other land-cover types, where there were slight differences according to the two classification systems (120 and 150), the validation points were selected from within the GLCNMO polygons only.
Thirdly, the FROM_GLC validation dataset was only used to complement our validation datasets because of the discrepancy between the classification systems (C. Li et al., 2017). The lichen and moss land-cover type (140) was missing in the GOFC_GOLD datasets, the shrubland polygons (120) in the GLCNMO dataset were too sparse, and the impervious surface polygons (190) in GOFC_GOLD were not suitable for validation of the impervious surfaces at a resolution of 30 m because the impervious surfaces within the polygons were usually broken and heterogeneous. Therefore, the shrubland, tundra and impervious samples in the FROM_GLC validation dataset were collected and then refined using the high-resolution imagery for 2015.
Afterwards, the GLWD dataset, which had a spatial resolution of 30 arcsec and contained 12 lake and wetland classes (Lehner and Döll, 2004; Tootchi et al., 2019), was used to derive the validation samples for the water body (210) and wetland (180) classes. To further ensure confidence in these validation samples, they were rechecked by the interpreters using high-resolution Google Earth imagery for the year 2015.
The time series of NDVI (normalized difference vegetation index) values for each validation point, derived from the Landsat SR imagery time series, were used to help distinguish between the vegetation-related land-cover types; for example, evergreen shrubland (121) and deciduous shrubland (122), evergreen broadleaved/needleleaved forests (50, 70), and deciduous broadleaved/needleleaved forests (60, 80).
Lastly, as the ice and snow cover generally varied with time, the time series of NDSI (normalized difference snow index) values and high-resolution imagery were combined to collect high-confidence permanent ice and snow (220) samples. Overall, after the combination of the auxiliary datasets from multiple sources and careful rechecking by several interpreters, a total of 44 043 validation samples for 24 fine land-cover types were finally collected – see Fig. 2. The global validation dataset is publicly available at https://doi.org/10.5281/zenodo.3551994 (Liu et al., 2019).

Figure 2The spatial distribution of the global validation datasets.
3.1 Deriving training samples from the CCI_LC land-cover product
As explained in our previous studies (Zhang et al., 2018, 2019), the Global Spatial Temporal Spectral Library (GSPECLib) was developed to store the reflectance spectra of different land cover types within each 158.85 km×158.85 km geographic grid cell at a temporal resolution of 8 d using time series of the MCD43A4 NBAR and ESA CCI_LC land-cover products. The reasons for selecting the CCI_LC and MCD43A4 NBAR products were that (1) MODIS has similar spectral bands to the Landsat OLI sensor, and MCD43A4 NBAR has better correction for view-angle effects than other SR products such as MOD09A1, meaning that there is more consistency between MCD43A4 NBAR and Landsat 8 SR (at small view angles, i.e., ) (Feng et al., 2012), and (2) the CCI_LC land-cover product has a detailed classification scheme containing 36 land-cover types, achieves the required classification accuracy over homogeneous areas (75.38 % overall), and has a relatively high spatial resolution of 300 m as well as a stable transition between the different annual land-cover products (Defourny et al., 2018; Y. Yang et al., 2017). In contrast to the previous GSPECLib that was used to store the reflectance spectra, in this study GSPECLib was developed to derive the location of training samples. The training samples' spectra were derived from Landsat data, while their land-cover labels were derived from CCI_LC.
The fine classification system used in this study (Table 2) inherited that of the CCI_LC products after the removal of four mosaic land-cover types (including mosaic natural vegetation and cropland and mosaic forest and grass or shrubland) because, in the 30 m Landsat imagery, it is possible to clearly identify the mosaic land-cover types in the coarse-resolution imagery (Fisher et al., 2018; Mishra et al., 2015). The three wetland land-cover types (tree–shrub–herbaceous cover, flooded, and fresh/saline or brackish water) were further combined into one wetland land-cover type as their high spatial and spectral heterogeneity as well as temporal dynamics made it difficult to identify the wetlands using remote sensing imagery (Gong et al., 2013; Ludwig et al., 2019). It should be noted that the CCI_LC products provide detailed land-cover results only for certain regions and not for the whole world because these detailed land-cover types made use of more accurate and regional information – where available – to define more LCCS classifiers and so to reach a higher level of detail in the legend (Defourny et al., 2018); therefore, the fine classification system in this study simultaneously contained 16 LCCS land-cover types (“multiple-of-10” values such as 10, 20, 50, 60, etc.) and 14 detailed regional land-cover types (other “non-10” values such as 11, 12, 61, etc.).
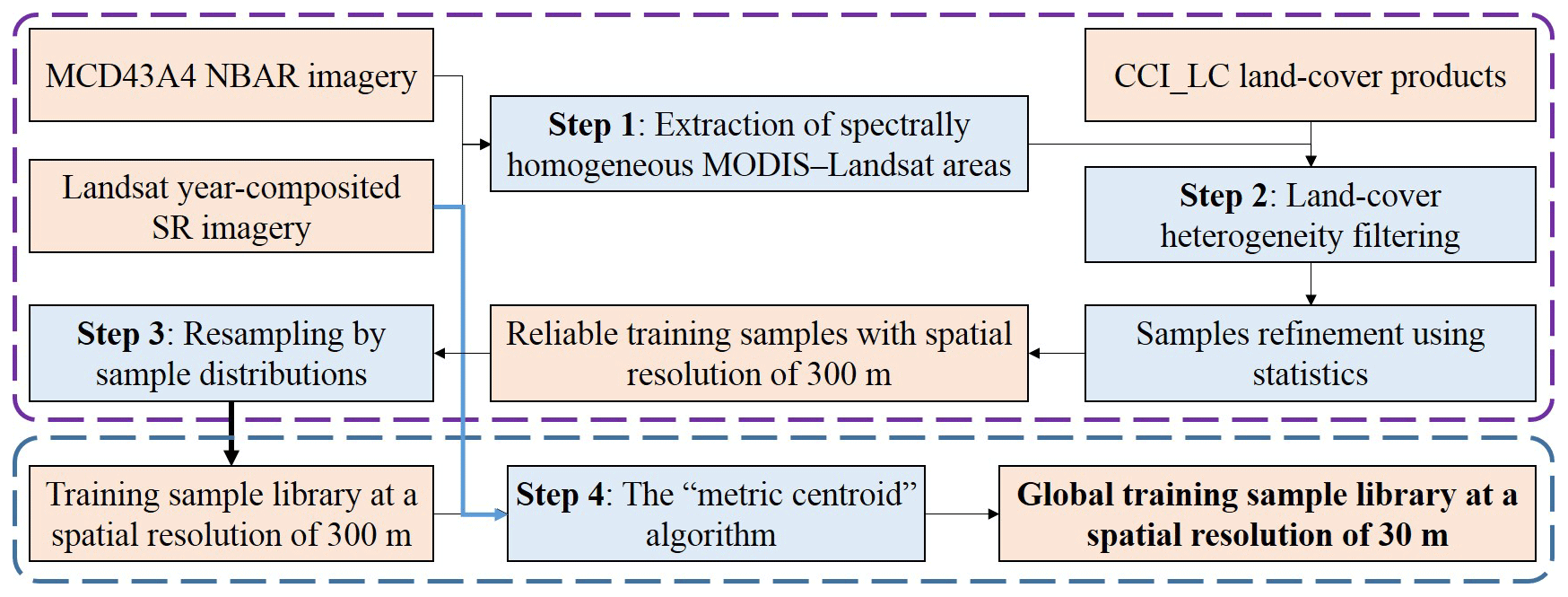
Similar to our previous works (Zhang et al., 2018, 2019), four key steps were adopted to guarantee the confidence of each training point, as illustrated in Fig. 3. As in Zhang et al. (2019), the spectrally homogeneous MODIS–Landsat areas were firstly identified based on the variance of a 3×3 local window using spectral thresholds of [0.03, 0.03, 0.03, 0.06, 0.03, and 0.03] for the six spectral bands (blue, green, red, NIR, SWIR1, and SWIR2) in both the MCD43A4 NBAR products and Landsat SR imagery (Feng et al., 2012). It should be noted that the year-composited Landsat SR data were downloaded from the GEE platform with the sinusoidal projection. As the MCD43A4 NBAR is corrected for view-angle effects and Landsat has a small view angle of , the view-angle difference between MCD43A4 and Landsat SR could be considered negligible.
Before the process of refinement and labeling, the CCI_LC land-cover products, which had geographical projections, were reprojected to the sinusoidal projection of MCD43A4. The spatial resolution of MCD43A4 was 1.67 times that of the CCI_LC land-cover product, and the spectrally homogeneous MODIS–Landsat areas had been identified in the 3×3 local windows. Also, Defourny et al. (2018) and Y. Yang et al. (2017) found that the CCI_LC performed better over homogeneous areas; therefore, a larger local 5×5 window was applied to the CCI_LC land-cover product to refine and label each spectrally homogeneous MODIS–Landsat pixel. Specifically, the land-cover heterogeneity in the local 5×5 window was calculated as being the percentage of land-cover types occurring within the window (Jokar Arsanjani et al., 2016a). Aware of the possibility of reprojection and classification errors in the CCI_LC products, the land-cover heterogeneity threshold was empirically selected as approximately 0.95; in other words, if the maximum frequency of dominant land-cover types was less than 22 in the 5×5 window, the point was excluded from GSPECLib. After a spatial–spectral filter had been applied to MCD43A4 and a heterogeneity filter to the CCI_LC product, the points that had homogeneous spectra and land-cover types were retained. In addition, to further remove the abnormal points contaminated by classification error in the CCI_LC, the homogeneous points were refined based on their spectral statistics distribution, in which the normal samples would form the peak of the distribution whereas the influenced samples were on the long tail (Zhang et al., 2018). It should be noted that the geographical coordinates of each homogeneous point were selected as being the center of the local window in the CCI_LC product because this had a higher spatial resolution than that of MCD43A4.
Then, Zhu et al. (2016) and Jin et al. (2014) found that the distribution (proportional to area and equal allocation) and balance of training data had a significant impact on classification results and quantitatively demonstrated that the proportional approach usually achieves higher overall accuracy than the equal-allocation distribution. In addition, Zhu et al. (2016) also suggested extracting a minimum of 600 training pixels and a maximum of 8000 training pixels per class for alleviating the problem of unbalancing training data. In this study, the proportional distribution and sample balancing parameters were used to resample these homogeneous points in each GSPECLib 158.85 km×158.85 km geographic grid cell.
Lastly, different from the previous spectrally based classification using MCD43A4 reflectance spectra (Zhang et al., 2019), in this study, we proposed using the Landsat reflectance spectra, derived by combining the global training samples and time-series Landsat imagery, to produce the global 30 m land-cover mapping. However, as the spatial resolution difference between Landsat SR (30 m) and homogeneous training samples would cause resolution effects when acquiring the training spectra (300 m), the “metric centroid” algorithm proposed by Zhang and Roy (2017) was used to find the optimal and corresponding training points at a resolution of 30 m. Specifically, as each homogeneous point corresponded to an area equivalent to 10×10 Landsat pixels, the normalized distances (Eq. 2) between each Landsat pixel and the mean of all 10×10 pixel areas were calculated. The optimal and corresponding training points at 30 m were selected as the ones having the minimum normalized distance,
where ρi is a vector representing the annually composited Landsat SR for 2015 and n is the number of Landsat pixels within a 10×10 local window (defined as 100). If several 30 m pixels had the same minimum Di value, then one pixel was selected at random.
3.2 Land-cover classification on the GEE platform
Despite the long-term plans for periodic systematic acquisitions and the improved accessibility of Landsat data through global archive consolidation efforts, the availability of Landsat data for persistently cloud-contaminated areas (the rainforest areas in Fig. 1) is less than ideal. To overcome the limitations of scene-level data quality, pixel-based compositing of Landsat data has increased in popularity since the opening of the USGS Landsat archive in 2008 (Griffiths et al., 2013; Woodcock et al., 2008). In particular, the seasonal composite and metrics composite are two widely used methods in large-area land-cover classification (Hansen et al., 2014; Massey et al., 2018; Teluguntla et al., 2018; Zhang and Roy, 2017). Recently, Azzari and Lobell (2017) quantitatively demonstrated that season- and metric-based approaches had nearly the same overall accuracies for land-cover classification containing multiple land-cover types or for single cropland mapping. Also, the metrics-composite method proposed by the Hansen et al. (2014) can capture the phenology and land-cover changes without the need for any explicit assumptions or prior knowledge regarding the timing of the season; therefore, its main advantage is that it is applicable globally without the need for location-specific modifications.
In this study, the time series of Landsat SR imagery and corresponding spectral indexes, including NDVI (normalized difference vegetation index) (Tucker, 1979), NDWI (normalized difference water index) (Xu, 2006), EVI (enhanced vegetation index) (Huete et al., 1999), and NBR (normalized burnt ratio) (Miller and Thode, 2007), were composited into the 25th, 50th, and 75th percentiles for each spectral band using the metrics-composite method. It should be noted that the 25th and 75th percentiles were used instead of the minimum and maximum values to minimize the effects of residual haze, cloud, and shadows caused by the errors in the CFMask method. In addition, many researchers have found that the texture variables can significantly improve the classification accuracy for land-cover mapping (M. Li et al., 2017; Rodriguez-Galiano et al., 2012; Wang et al., 2015; Zhu et al., 2012), for example, Zhu et al. (2012) found that the import of Landsat-derived texture features improved the land-cover accuracy from 86.86 % to 92.69 %. Therefore, the NIR band texture variables of variance, homogeneity, contrast, dissimilarity, entropy, and correlation were also added using a method based on GLCM (gray level co-occurrence matrix). Due to the great similarity between the six Landsat optical bands (Rodriguez-Galiano et al., 2012), only the texture variables of the NIR bands were considered. In total, there were 16 spectral–texture metrics (MS–T) for each percentile and a total of 48 metrics for each Landsat pixel. Except for these Landsat-based metrics, the three topographical variables of elevation, slope, and aspect, derived from the DEM datasets, were also added.
Afterwards, the random forest (RF) classifier, comprised of a decision-tree classification using the bagging strategy (Breiman, 2001) and an internal algorithm on the GEE platform, was used to combine the training data and aforementioned composited metrics for land-cover mapping. Many studies have demonstrated that the RF performs better with high-dimensional data, gives a higher classification accuracy, and is less sensitive to noise and feature selection than other widely used classifiers such as the support vector machine, artificial neural network, and classification and regression tree (Belgiu and Drăguţ, 2016; Du et al., 2015; Pelletier et al., 2016). Moreover, the RF classifier has only two adjustable parameters: the number of selected prediction variables (Mtry) and the number of decision trees (Ntree). Belgiu and Drăguţ (2016) also explained that the classification accuracy was less sensitive to Ntree than to the Mtry parameter, and Mtry was usually set to the square root of the number of input variables. Due to these advantages, the RF classifier is widely used in land-cover mapping (Gong et al., 2013, 2019; Zhang and Roy, 2017; Zhang et al., 2019). In this study, the values of Ntree and Mtry were set to 100 and the default value (the square root of the total number of input features), respectively.
There were usually two options for large-area or global land-cover classification including global classification modeling (Gong et al., 2013; Teluguntla et al., 2018) and local adaptive classification modeling (Gong et al., 2020; Phalke et al., 2020; Zhang et al., 2020). First, the global classification strategy meant using all training samples to train a single classifier which was suitable for land-cover mapping in any areas. For example, Buchhorn et al. (2020) used 141 000 unique 100×100 m training locations to train a single random forest classifier to generate the Copernicus Global Land Cover layers. Then, the local adaptive classification modeling first divided the globe into a lot of regions and then trained the corresponding local classifiers using the regional training samples, and the global land-cover map was spatially mosaicked by a lot of regional land-cover classification results. For example, Zhang and Roy (2017) split the United States into 561 159×159 km tiles and then trained 561 corresponding local adaptive random forest models to generate the regional land-cover results, and they found the land-cover maps derived from the local adaptive models achieved higher accuracy performance than that of the single global model. Similarly, Radoux et al. (2014) also found that the local adaptive modeling allowed regional tuning of classification parameters to consider regional characteristics and increased the sensitivity of the training samples. Therefore, as illustrated in the previous works, the training samples in a small spatial grid (Landsat scene) might not be enough, especially for sparse land-cover types, and the training samples from neighboring 3-by-3 tiles were also imported (Zhang and Roy, 2017; Zhang et al., 2019). The GEE platform also had some limitations for computation capacity and memory. Therefore, after balancing the accuracy performance, computation efficiency, and training sample volume, the local adaptive random forest models, which split the globe into approximately 948 geographical tiles (approximately 3×3 Landsat scenes) similar to our previous work (Zhang et al., 2020), were applied to generate a lot of regional land-cover maps. In addition, to guarantee the spatially continuous transition over adjacent regional land-cover maps, the training samples from neighboring 3×3 tiles were used to train the random forest model and classify the central tile.
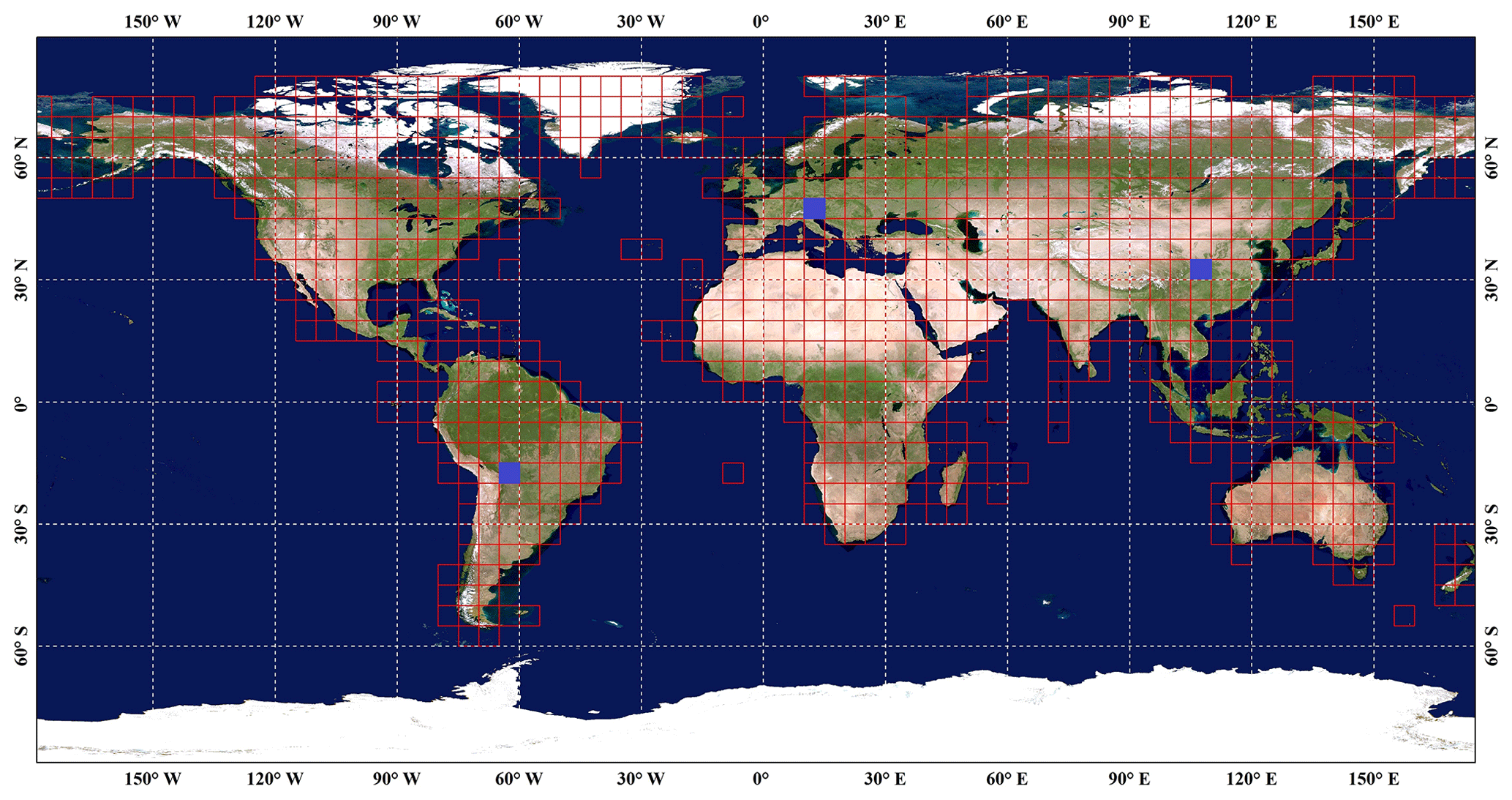
Figure 4Overview of the geographical tiles used for local adaptive modeling. Three blue rectangular tiles were used for comparing GLC_FCS30 with other land-cover products. The background imagery came from the National Aeronautics and Space Administration (https://visibleearth.nasa.gov, last access: 11 June 2021).
3.3 Accuracy assessment
Assessing the accuracy of land-cover products is an essential step in describing the quality of the products before they are used in related applications (Olofsson et al., 2013). In the past, although there has been no standard method of assessing the accuracy of land-cover maps, the error or confusion matrix has been widely considered to be the best measure (Foody and Mathur, 2004; Gómez et al., 2016; Olofsson et al., 2014). This is because it not only describes the confusion between various land-cover types but also provides quantitative metrics, including the user's accuracy (U.A.) (measuring the commission error), producer's accuracy (P.A.) (measuring the omission error), overall accuracy (O.A.), and kappa coefficient, to measure the performance of the products.
In this study, since the GLC_FCS30 products contained 30 fine land-cover types, including 16 LCCS level-1 types and 14 detailed level-2 types (Table 2), for a more comprehensive validation of the GLC_FCS30 products, the confusion matrices were divided into three parts: (1) a level-0 confusion matrix containing 9 major land-cover types, similar to the GlobaLand30 and FROM_GLC classification systems; (2) a LCCS level-1 validation matrix containing 16 level-1 land-cover types; and (3) a LCCS level-2 validation matrix containing 24 fine land-cover types after the removal of 6 coverage-related level-2 types (closed or open deciduous or evergreen or broadleaved/needleleaved forests) from the classification system. These six coverage-related types were removed because it was difficult to guarantee the confidence for these detailed land-cover types in the validation datasets. It should be noted that the relationship between the level-0 validation system and the classification system used in this study was related to the work of Defourny et al. (2018) and Y. Yang et al. (2017).
4.1 The GLC_FCS30-2015 land-cover map
Figure 5 illustrates the global 30 m land-cover map for the nominal year of 2015 (GLC_FCS30-2015) containing 30 fine land-cover types and produced using the time series of Landsat SR imagery and the local random forest classification models. Intuitively, the GLC_FCS30-2015 land-cover map accurately delineates the spatial distributions of various land-cover types and is consistent with the actual spatial patterns of global land cover: for example, areas of evergreen broadleaved forest are mainly distributed in tropical areas, including the Amazon rainforest, African rainforests, and India–Malay rainforests, whereas bare areas are found in the African Sahara, Arabian Desert, Australian deserts, and China–Mongolia desert areas. In addition, owing to importing the multi-temporal Landsat features for land-cover classification and using the training samples from neighboring 3×3 tiles to train the random forest model and classify the central tile, the stamping problem that occurs in single-date land-cover classification (Gong et al., 2013; Zhang et al., 2018) has been largely solved in the case of this global map, and the spatial transitions between adjacent geographical tiles are continuous and natural. Similarly, Zhang and Roy (2017) used the time-series Landsat imagery and imported the neighboring training samples to generate the spatially consistent land-cover classification over the United States.
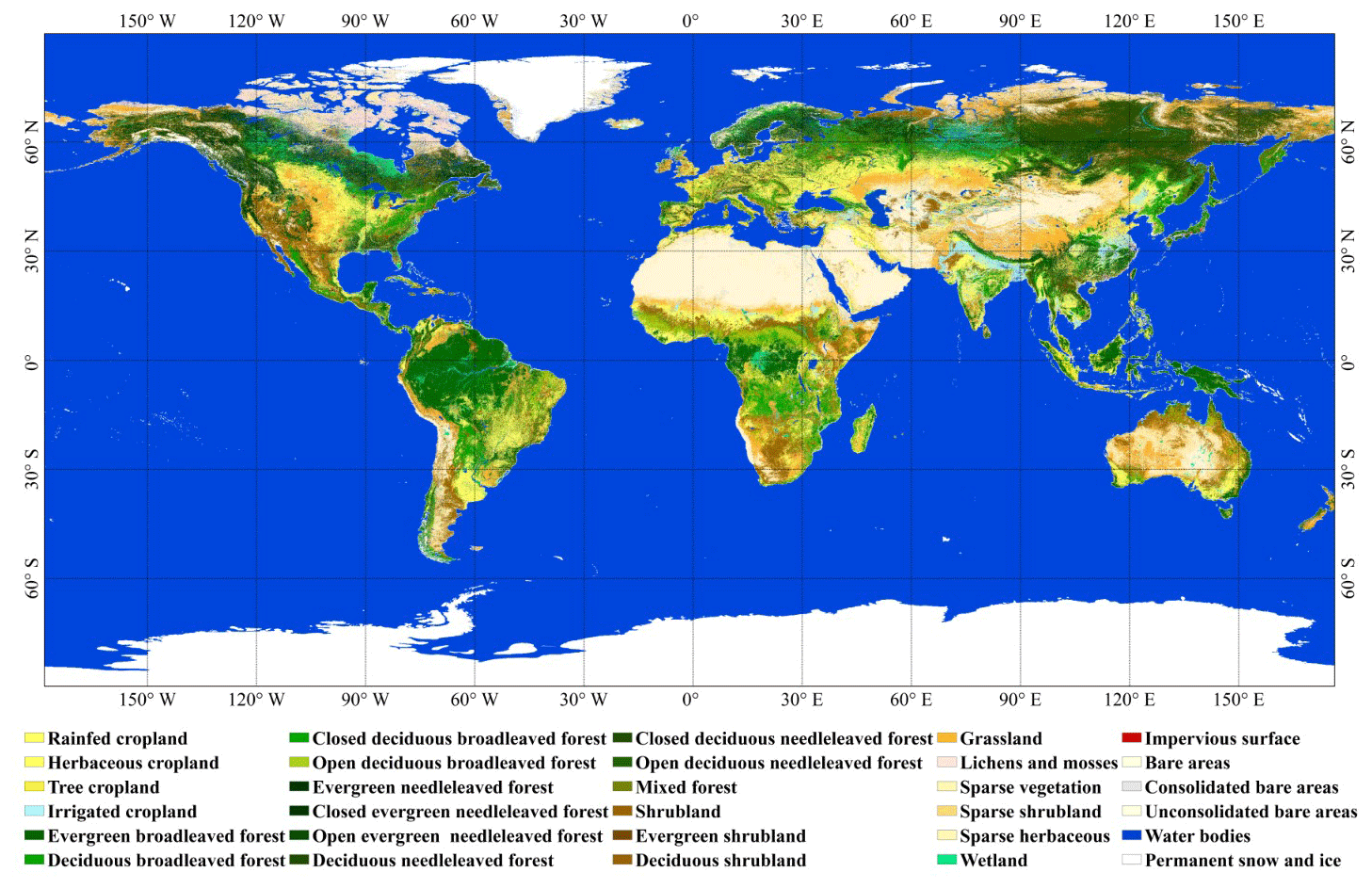
Figure 5GLC_FCS30-2015 land-cover map containing 30 fine land-cover types for the nominal year 2015 and the legend color map inherited from the CCI_LC land-cover product. The legend color map inherited from the ESA CCI_LC land-cover products (Defourny et al., 2018).
Table 3The accuracy matrix for the GLC_FCS30-2015 land-cover product according to the level-0 validation scheme and containing nine major land-cover types.
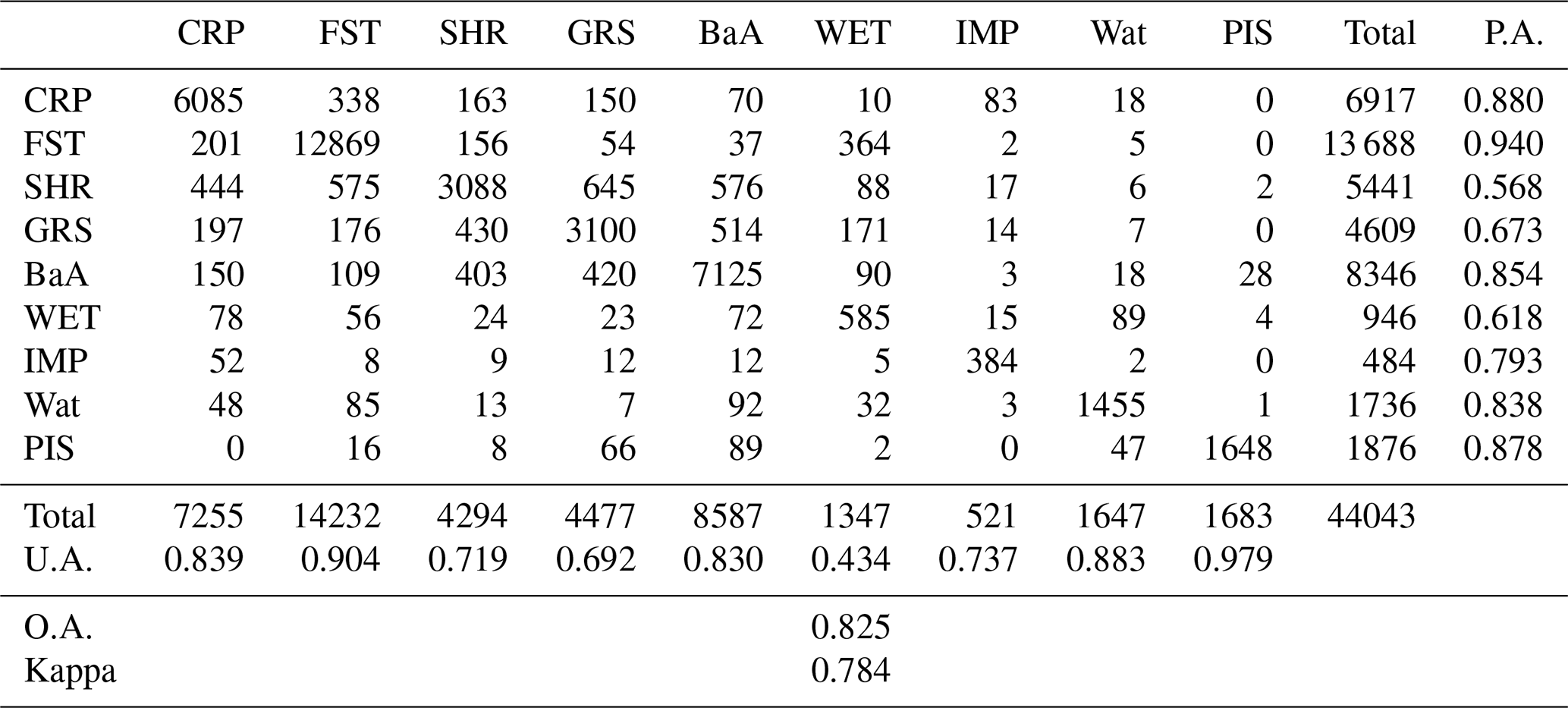
Note: CRP: cropland; FST: forest; SHR: shrubland; GRS: grassland; WET: wetlands; IMP: impervious surfaces; BaA: bare areas; Wat: water body; PIS: permanent ice and snow.
Using the validation datasets described earlier, three confusion matrices (Tables 3–5) corresponding to different validation systems were generated. Table 3 summarizes the accuracy metrics for nine major land-cover types: overall, the GLC_FCS30-2015 map achieved an overall accuracy of 82.5 % and a kappa coefficient of 0.784. From the perspective of the producer's accuracy, the forest type had the highest accuracy, followed by cropland, permanent ice and snow, bare areas, and water body; wetland, shrubland, and grassland had low accuracies. These results indicate that land-cover types that had relatively pure spectral properties or occupied a large proportion of the Earth's surface usually had a relatively high accuracy. In contrast, the complex land-cover types were often confused with other types: for example, the spectra of the wetlands were especially complicated and easily confused with water body and vegetation (Ludwig et al., 2019). As a result, 16.7 % and 9.5 % of wetland validation points were wrongly identified as vegetation (including cropland, forest, and shrubland) and water body, respectively, in Table 3. As for the user's accuracy metric, the accuracy rankings were similar to those for the producer's accuracy; however, in this case, the permanent ice and snow class achieved the highest accuracy.
Table 4The accuracy matrix for the GLC_FCS30-2015 land-cover product according to the LCCS level-1 validation scheme.
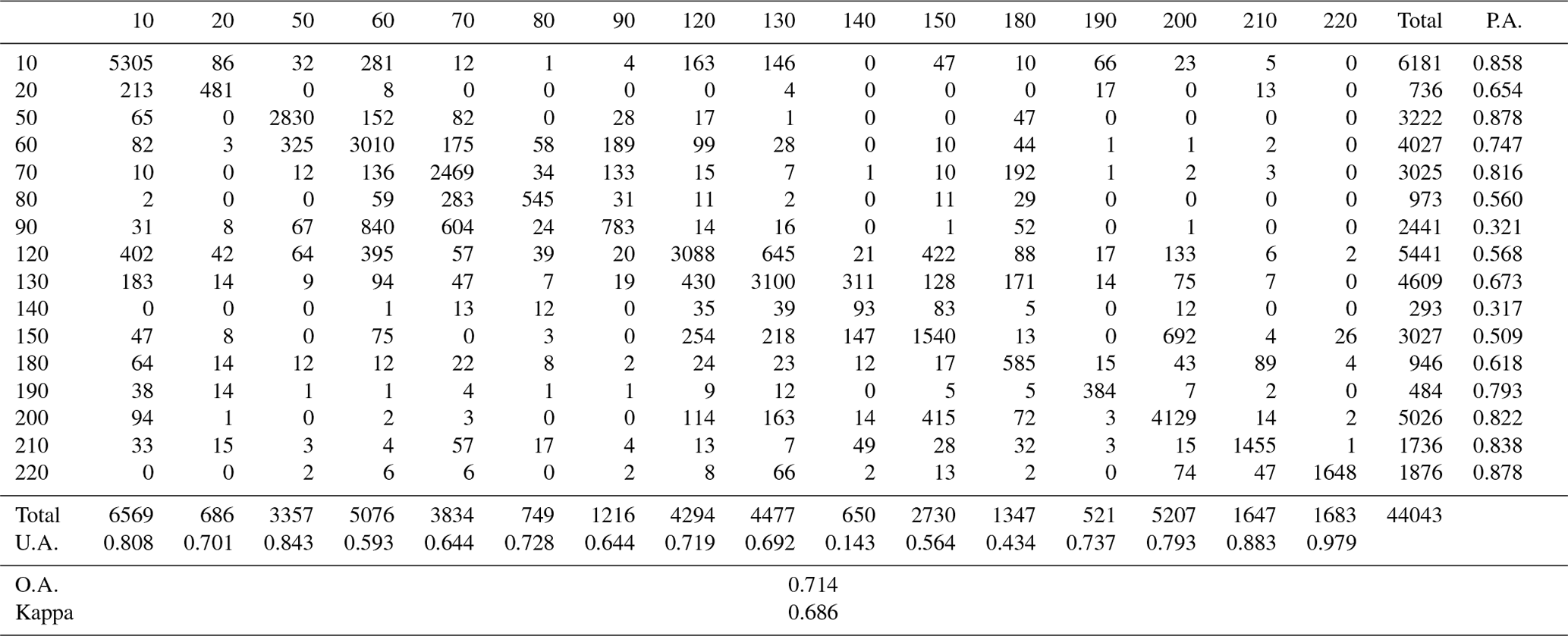
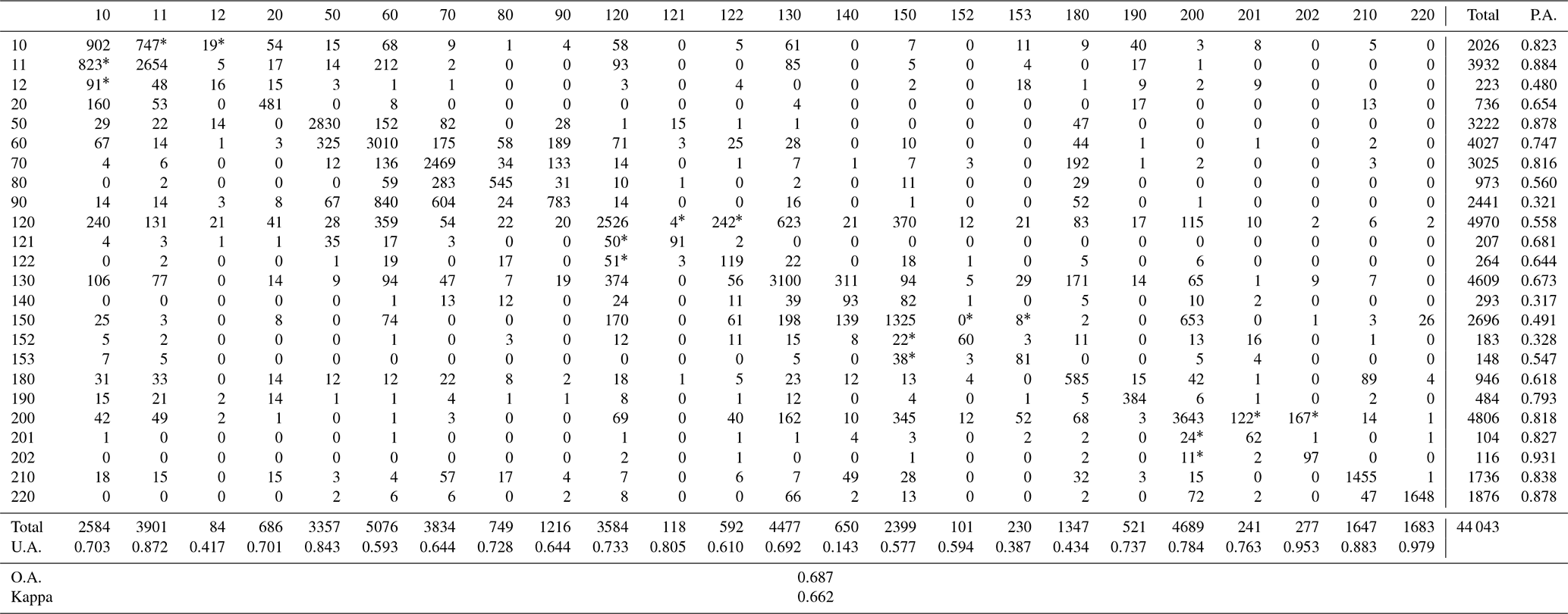
Table 5The accuracy matrix for the GLC_FCS30-2015 land-cover product according to the LCCS level-2 validation scheme. Note the values with an asterisk also represent correct classification.
Tables 4 and 5 describe the performance of the GLC_FCS30-2015 land-cover map under the LCCS level-1 and level-2 validation schemes, respectively. Compared with the values of the accuracy metrics in Table 3, the values in these tables are clearly lower because similar fine land-cover types were easily confused under these conditions. According to Table 4, the GLC_FCS30-2015 achieved an overall accuracy of 71.4 % and a kappa coefficient of 0.686. From the perspectives of the user's accuracy and producer's accuracy, there was significant confusion between the forest-related and cropland-related cover types. In order to intuitively display the degree of confusion for the 16 LCCS level-1 land-cover types, the confusion proportions for each of the land-cover types in Table 4 were calculated; these are shown in Fig. 6. First, it can be seen that the complicated land-cover types were more easily misclassified: for example, mixed forest (90) and lichens and mosses (140) had the highest confusion proportions, with more than 60 % of the validation samples being misclassified as other types. Secondly, there was a great deal of misclassification between similar land-cover types: for example, more than 20 % of irrigated cropland samples (20) were misclassified as rainfed cropland (10), approximately 30 % of deciduous needleleaved forest samples (80) were misclassified as evergreen needleleaved forest (70), and the confusion between sparse vegetation (150) and bare areas (200) was also considerable.

Figure 6The confusion proportions for each of the land-cover types in the LCCS level-1 validation scheme.
In Table 5, it can be seen that GLC_FCS30-2015 achieved an overall accuracy of 68.7 % and kappa coefficient of 0.662. It should be noted that the values with superscript (*) in Table 5 also represented correct classification because GLC_FCS30-2015 simultaneously consisted of 16 LCCS land-cover types (the “tens” values such as 10, 20, 50, etc.) and 14 detailed regional land-cover types (the “non-10” values such as 11, 12, 61 etc.), which were only present in some regions (Defourny et al., 2018). Also, the 14 detailed land-cover types simultaneously belonged to the corresponding LCCS land-cover types according to Table 2; similar operators for these detailed land-cover types can also be found in the works of Defourny et al. (2018) and Bontemps et al. (2010). Under the LCCS level-2 fine validation system, the accuracy metrics were basically consistent with those found for the LCCS level-1 validation scheme. Figure 7 illustrates the confusion proportions between each of the fine land-cover types. In contrast to the results discussed above, the degrees of confusion for these fine land-cover types are more significant: for example, most tree-covered cropland (12) samples are misclassified as herbaceous-covered cropland (11), and the confusion between the LCCS land-cover types (the “tens” values) and the corresponding detailed land-cover types (the “non-10” values) is more obvious.
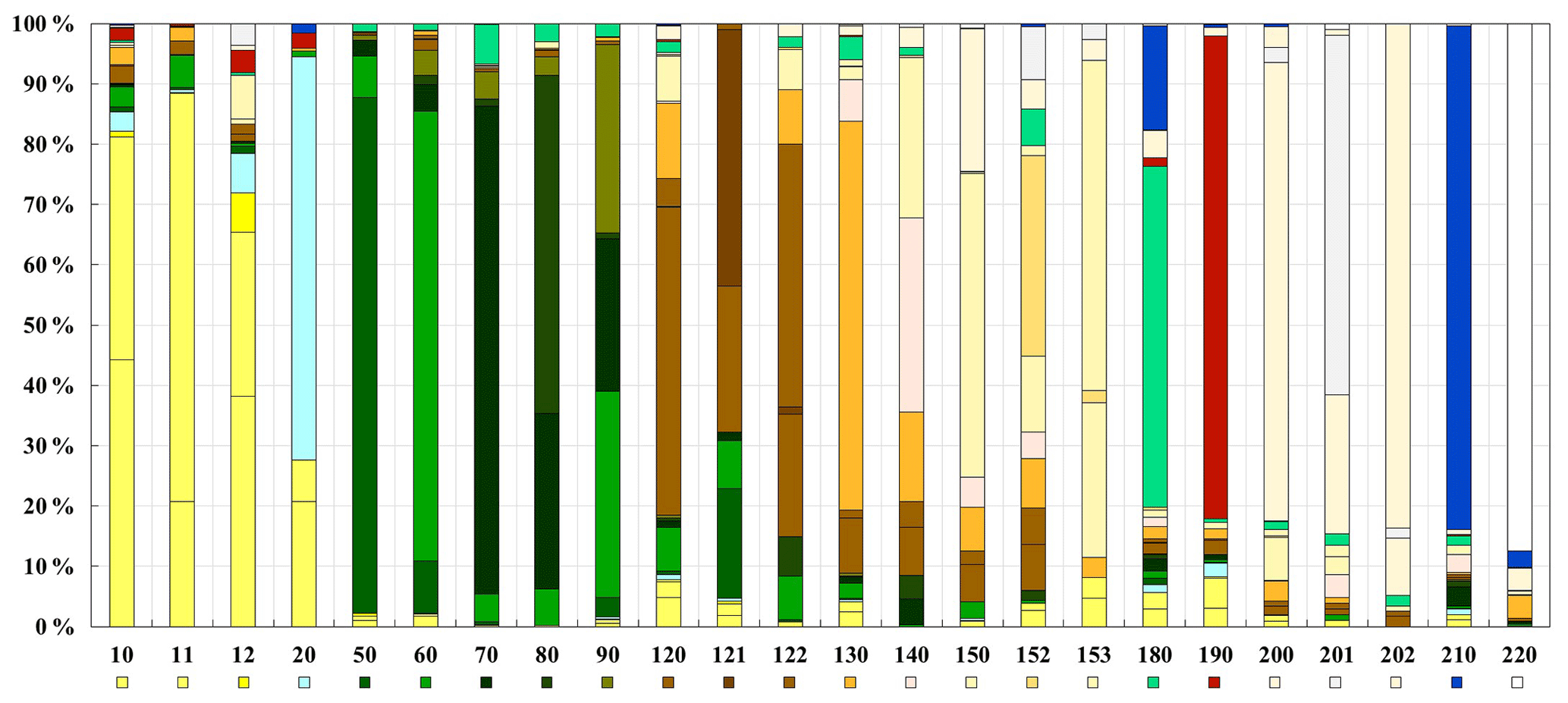
Figure 7The confusion proportions for each of the land-cover types in LCCS level-2 validation scheme.
4.2 Comparison between GLC_FCS30-2015 and other land-cover products
4.2.1 Comparison between three global 30 m land-cover products
Based on the global validation datasets and the Level-0 validation scheme, the classification accuracy of GLC_FCS30-2015 was compared to two other global 30 m land-cover products (FROM_GLC-2015 and GlobeLand30-2010), as listed in Table 6. Overall, the GLC_FCS30-2015 achieved the best accuracy performance of 82.5 % against the FROM_GLC-2015 of 59.1 % and the GlobeLand30-2010 of 75.9 %. Specifically, the GLC_FCS30-2015 gave better performance than GlobeLand30-2010 in shrublands, grasslands, and impervious surfaces and achieved similar accuracies with the GlobeLand30 in most land-cover types (cropland, forest, bare land, water body, and permanent ice and snow). Compared to the FROM_GLC-2015 products, the GLC_FCS30-2015 and GlobeLand30-2010 had higher accuracy for most land-cover types, especially for the cropland and forest.
Table 6The accuracy metrics of three global 30 m land-cover products using the validation datasets.

Note: CRP: cropland, FST: forest, SHR: shrubland, GRS: grassland, WET: wetlands, IMP: impervious surfaces, BaA: bare areas, Wat: water body, PIS: permanent ice and snow
Similarly, Kang et al. (2020) also analyzed the performance of three global land-cover products in the complicated tropical rainforest region (Indonesia) using over 2000 verification points, and validation results indicated that the GLC_FCS-2015 achieved the highest accuracy of 65.59 %, followed by the GlobeLand30-2010 of 61.65 % and FROM_GLC-2015 of 57.71 %. Specifically, all three land-cover products had greater performance for forests and impervious surfaces, and the cropland and wetland mapping accuracy of GLC_FCS30-2015 was higher than that of the other two products (Kang et al., 2020).
Except for the quantitative assessment, three typical regions (the blue rectangles in Fig. 4) and their local enlargements, covering various climate and landscape environments, were selected to directly illustrate the performance of each land-cover product in Fig. 8. Overall, there was higher spatial consistency between the GLC_FCS30-2015 and GlobeLand30-2010 products; both of them accurately depicted the spatial distributions of different land-cover types. As for the FROM_GLC-2015 products, it was different from other two products in spatial distribution; for example, the areas (in Fig. 8II), identified by FROM_GLC-2015 as grassland and shrubland, were labeled as cropland and forest in the GLC_FCS30-2015 and GlobeLand30-2010. In addition, from the perspective of land-cover diversity, it was obvious that the GLC_FCS30-2015 products had significant advantages over other two products, which made the regional land-cover maps of GLC_FCS30-2015 contain diverse color legends. In more detail, as for the cropland-prevalent areas (Fig. 8Ia and IIIc), the spatial distribution of GLC_FCS30-2015 was similar to the GlobeLand30-2010 products; however, the FROM_GLC-2015 had omission error for impervious surfaces (Fig. 8Ia) and misidentified some cropland pixels as grassland (Fig. 8Ia) and forest (Fig. 8IIIc). Secondly, for the undulating agricultural and forestry areas (Fig. 8Ib, 8Ic, 8IIb, 8IIIa), three land-cover products captured the spatial patterns of various land-cover types; for example, the cropland was usually located in the flat areas, and the mountain areas mainly contained the forest and grassland. Lastly, in the woodland areas where some forests are reclaimed as farmland (Fig. 8IIa), both the GLC_FCS30-2015 and GlobeLand30-2010 accurately delineated the tracks of human interference, and the GLC_FCS30-2015 had larger cropland areas than that of GlobeLand30-2010, which also demonstrated the increase in reclamation over the 5-year interval. Different from the other two products, the FROM_GLC-2015 identified these reclaimed areas as grassland pixels, and some forest pixels were also labeled as grassland, which meant the FROM_GLC-2015 had the largest grassland area in Fig. 8IIa.

Figure 8Comparison between GLC_FCS30-2015 and other land-cover products (CCI_LC-2015 products developed by Defourny et al., 2018; the MCD12Q1-2015 developed by Friedl et al., 2010; the FROM_GLC-2015 developed by Gong et al., 2013; and the GlobeLand30 developed by Chen et al., 2015) in three regions. In each case, two to three local enlargements (a–c) with the size of 40 km×60 km were used to reveal further details of each land-cover product.
4.2.2 The comparisons of GLC_FCS30-2015 with CCI_LC and MCD12Q1 land-cover products
Except for comparing with global 30 m land-cover products, two widely used global products (CCI_LC-2015 and MCD12Q1), which both contained diverse land-cover types, were also selected to comprehensively analyze performance of the GLC_FCS30-2015. It should be noted that the global validation dataset (Sect. 2.3) was collected to validate the 30 m land-cover products, so the quantitative assessment was skipped for the coarse-resolution land-cover products of CCI_LC-2015 and MCD12Q1-2015. Figure 8 intuitively compared the performances of GLC_FCS30-2015, CCI_LC-2015, and MCD12Q1-2015 products over three typical regions and corresponding local enlargements. Overall, the spatial consistency of GLC_FCS30-2015 and CCI_LC-2015 was higher than that of MCD12Q1-2015 because the GLC_FCS30-2015 and CCI_LC-2015 shared the same classification system. For example, the savanna pixels (tree cover 10 %–30 %) (Friedl et al., 2010) in the MCD12Q1-2015 were labeled as broadleaved forest in the other two products (Fig. 8II).
Lastly, it can be found that the GLC_FCS30-2015 had a great advantage in spatial details compared to the CCI_LC-2015 and MCD12Q1-2015 products over these local enlargements in Fig. 8. For example, the river boundary in Fig. 8Ia; the fragmented impervious surfaces in Fig. 8Ia, 8Ib, and 8IIb; and the terrain changes in Fig. 8Ic, IIb, and IIIa were more accurately captured in the GLC_FCS30-2015, while two coarse land-cover products (CCI_LC-2015 and MCD12Q1-2015) usually lost these details. Therefore, compared with CCI_LC-2015 and MCD12Q1-2015 land-cover products, the GLC_FCS30-2015 not only had obvious advantages in spatial details, but also achieved a higher accuracy and corrected a lot of misclassification in the CCI_LC-2015 land-cover products.
5.1 Advantages of GLC_FCS30 using huge training samples
Global land-cover classification is a challenging and labor-intensive task because of the large volume of data pre-processing involved, the high-performance computing requirements, and the difficulty of collecting training data that allow the classification models to be both locally reliable and globally consistent (Friedl et al., 2010; Giri et al., 2013; Zhang and Roy, 2017). Thanks to the parallel computing ability and efficient and free access to multi-petabyte, analysis-ready remote-sensing data that are available on the GEE platform (Gorelick et al., 2017), the main challenge lies in collecting sufficient reliable training data. In this study, we propose extending our previous work on SPECLib-based classifications (Zhang et al., 2018, 2019) and deriving global high-quality training data from the updated GSPECLib for global land-cover mapping (Sect. 3.1). Figure 9 illustrates the number of global training samples in each geographical grid cell. The statistics are generally consistent with the land-cover patterns shown in Fig. 5. In addition, in contrast to other studies that used manual interpretation of samples for global land-cover mapping (Friedl et al., 2010; Gong et al., 2013; Tateishi et al., 2014), the total number of training samples in this study reached 27 858 258 points and so was tens to hundreds of times higher than that used in these global land-cover classifications.
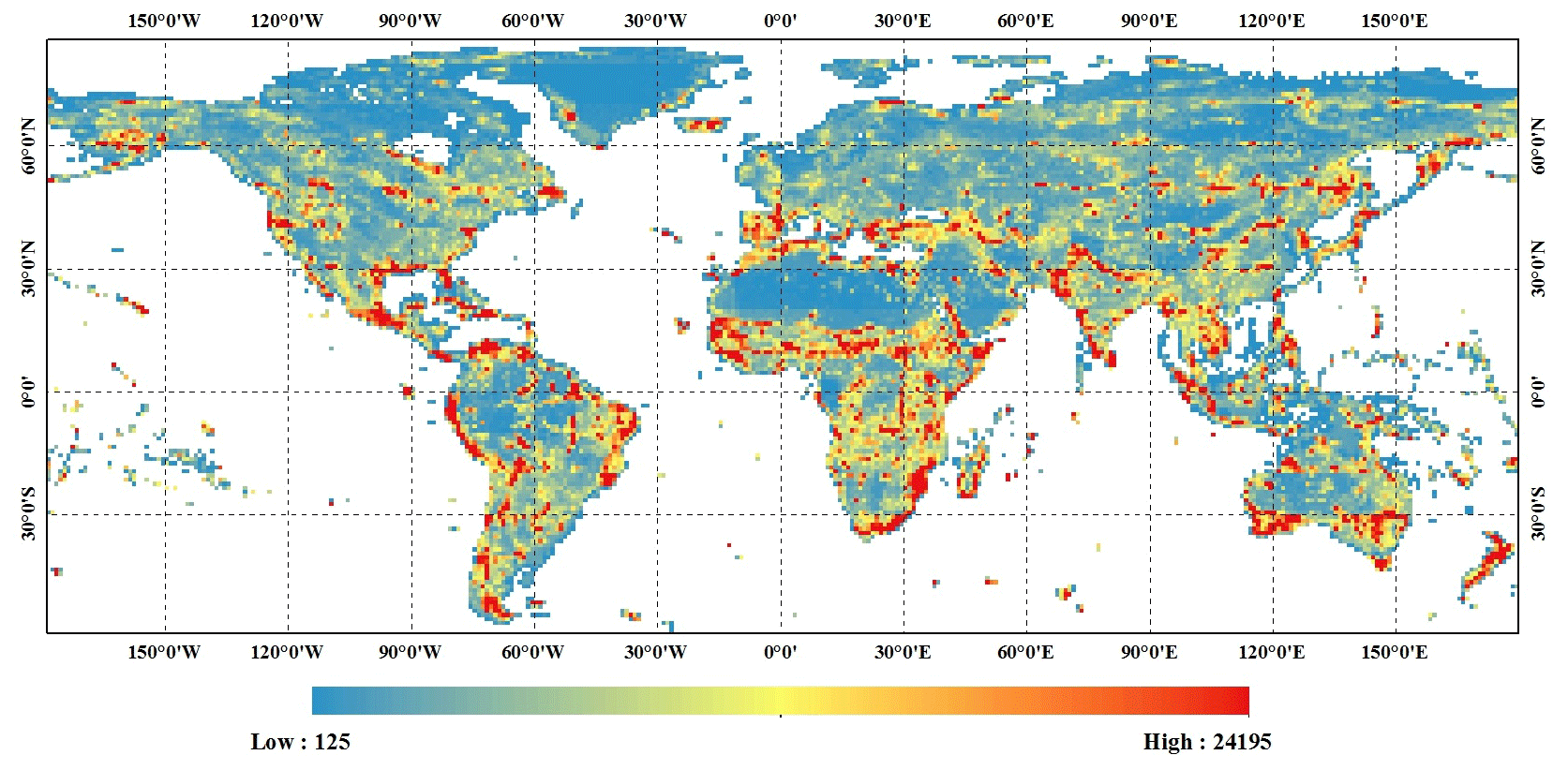
Figure 9The number of global training samples in each geographical grid cell.
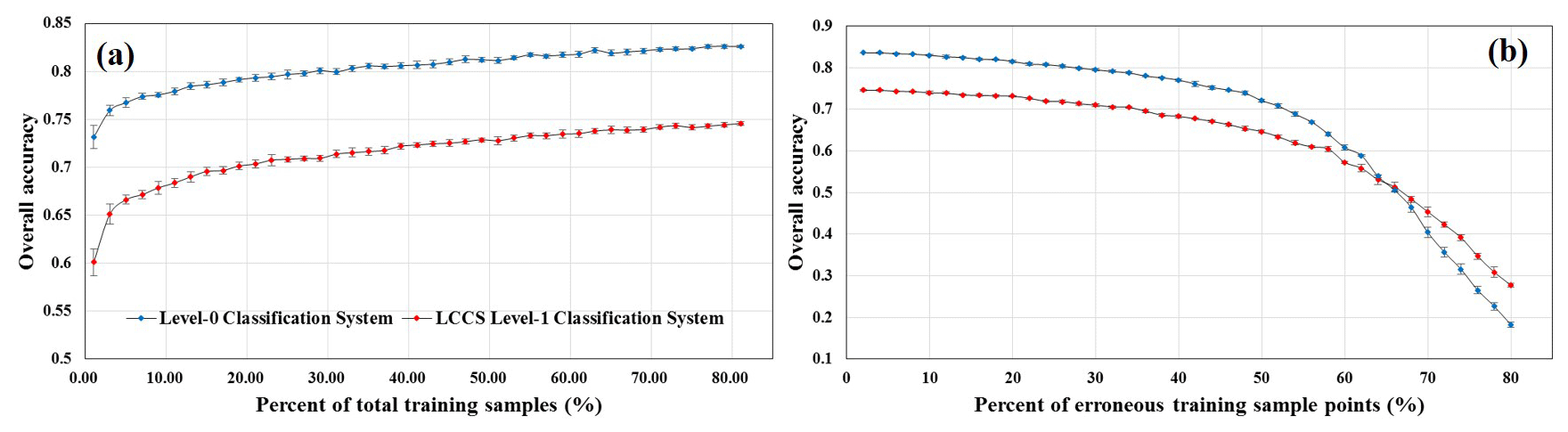
Figure 10Sensitivity analysis showing the relations between the overall classification accuracy and the percentage of total samples and erroneous sample points.
To demonstrate the importance of sample sizes, 200 000 points, approximately 1 % of the total training samples, were randomly selected to quantitatively analyze the relationship between overall accuracy and the corresponding sample size. Specifically, we used the 10-fold cross-validation method to split these points into training and validation samples, and then we gradually increased the size of training samples with the step of 2 % and repeated the process 100 times. Figure 10a illustrates the overall accuracy (level-0 and LCCS level-1 classification systems) increased for the increased percentage of training samples. It was found that the overall accuracy rapidly increased when the percentage of training samples increased from 1 % to 30 %, while it remained relatively stable when the percentage of training samples was higher than 30 %. Therefore, the appropriate sample size should be larger than 60 000 (30 % of the total input points); fortunately, the local training samples in this study almost all exceeded the 60 000 because the training samples from neighboring 3×3 tiles were used to train the random forest model and classify the central tile. Similarly, Foody (2009) also found that the sample size had a positive relationship with the classification accuracy up to the point where the sample size was saturated, and Zhu et al. (2016) suggested that the optimal size was a total of 20 000 training pixels to classify an area about the size of a Landsat scene.
Secondly, many studies have demonstrated that the sample outliers had influence on the land-cover classification accuracy (Mellor et al., 2015, Pelletier et al., 2017). In this study, using the previous 200 000 training points, we further analyzed the relationship between overall classification accuracy and erroneous training samples by randomly changing the category of a certain percentage of these samples and using the “noisy” samples to train the random forest classifier. Similar to the previous quantitative analysis of sample size, we gradually increased the percentage of erroneous training samples with the step of 2 % and then repeated the process 100 times. Figure 10b showed that the overall accuracy of two classification systems (level-0 and LCCS level-1) generally decreased with the increase in percentage of erroneous sample points. It remained relatively stable when the percentage of erroneous training samples were controlled within 30 % and decreased obviously after exceeding the threshold of 30 %. Meanwhile, the overall accuracy of a simple classification system was more susceptible to the erroneous samples than that of the LCCS classification system in Fig. 10b. Similarly, many scientists have also demonstrated that a small number of erroneous training data have little effect on the classification results (Gong et al., 2019; Mellor et al., 2015; Pelletier et al., 2016; Zhu et al., 2016): for example, Mellor et al. (2015) found the error rate of the RF classifier was insensitive to mislabeled training data, and the overall accuracy decreased from 78.3 % to 70.1 % when the proportion of mislabeled training data increased from 0 % to 25 %. Similarly, Pelletier et al. (2016) found the RF classifier was little affected by low random noise levels up to 25 %–30 % but that the performance dropped at higher noise levels.
Defourny et al. (2018) demonstrated that CCI_LC achieved an overall accuracy of 75.38 % for homogeneous areas. In this study, some measures have been taken to guarantee the confidence of training samples. Some complicated land-cover types were then further optimized to improve the accuracy of the training data; for example, impervious surfaces were imported as an independent product and directly superimposed over the final global land-cover classifications, the three wetland types were merged into an overall wetland land-cover type, and four mosaicked land-cover types were removed (Table 2). After optimizing these complicated land-cover types, the overall accuracy of CCI_LC reached 77.36 % for homogeneous areas based on the confusion matrix of Defourny et al. (2018). In addition, other measures, including the spectral filters applied to the MCD43A4 NBAR data, the land-cover homogeneity constraint for CCI_LC land-cover products, and the “metric centroid” algorithm for removing the resolution differences, were used to further improve confidence in the training data. Therefore, some training samples (exceeding 18 000 points) in the previous analysis were randomly selected to quantitatively evaluate the confidence of the global training dataset. After pixel-by-pixel interpretation and inspection, the validation results indicated that these samples had satisfactory performance with the overall accuracy of 91.7 % for the level-0 classification system and 82.6 % for level-1 LCCS classification system. Therefore, it can be assumed that the training data, derived by combining the MCD43A4 NBAR and CCI_LC land-cover products, were accurate and suitable for large-area land-cover mapping at 30 m.
Lastly, the sample balance is also an important factor in land-cover classification, especially for rare land-cover types, because unbalanced training data would cause the under-fitting of the classification model for rare land-cover types and further degrade the classification accuracy. In this study, we used the sample balancing parameters (a minimum of 600 training pixels and a maximum of 8000 training pixels per class), based on the work of Zhu et al. (2016), to alleviate the problem of unbalancing training data when deriving training samples from the GSPECLib in the Sect. 3.1; therefore, Fig. 8II and III illustrated that the water body, which was the rare land-cover type in all the regions, has been accurately captured in the corresponding enlargement figures.
5.2 Uncertainty and limitations of the GLC_FCS30-2015 land-cover map
Except for the training sample uncertainties (including sample size, outliers) in Sect. 5.1, the land-cover heterogeneity also had a significant effect on the classification accuracy (Calderón-Loor et al., 2021; Wang and Liu, 2014). To clarify the relationship between land-cover heterogeneity and overall accuracy of the GLC_FCS30-2015 land-cover map, we firstly used the Shannon entropy to calculate the spatial heterogeneity using the GLC_FCS30_2015 at spatial resolution of (Eq. 4). Figure 11a illustrated the land-cover heterogeneity of the GLC_FCS30 land-cover map. Intuitively, the highly heterogeneous regions mainly corresponded to the climatic transition zone, especially for the sparse-vegetation areas. Then, we combined the land-cover heterogeneity and global validation datasets (in the Sect. 2.3) to calculate the mean accuracy at different heterogeneities illustrated in Fig. 11b. It could be found that the classification accuracy had a negative relationship with land-cover heterogeneity with the slope of −0.3347; namely the GLC_FCS30 had better performance in the homogeneous areas than of the heterogeneous areas. Similarly, Defourny et al. (2018) also demonstrated that the CCI_LC land-cover products achieved the higher accuracy of 77.36 % in the homogeneous areas than 75.38 % in all the areas.
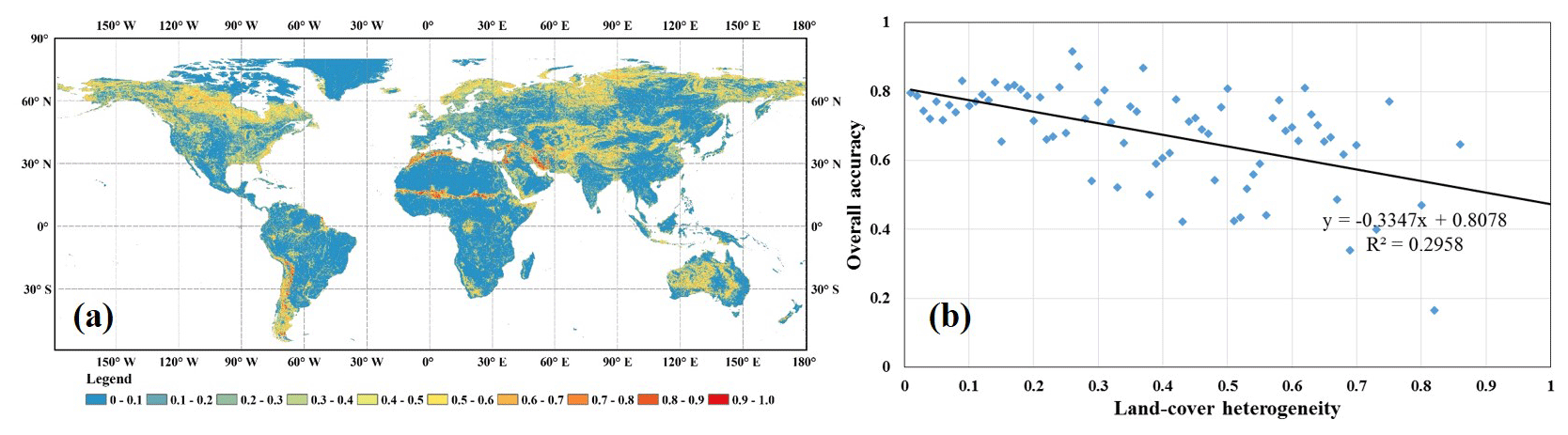
Figure 11The land-cover heterogeneity of the GLC_FCS30 land-cover map at a spatial resolution of 0.05∘, and the relationship between land-cover heterogeneity and overall accuracy using the global validation datasets.
Figure 12The spatial distributions of 14 detailed regional land-cover types in the GLC_FCS30-2015 products.
The CCI_LC map used a fine classification system in some regions but used a coarse classification system in other regions (Defourny et al., 2018). Because the training samples were derived from the CCI_LC land-cover product, our GLC_FCS30 product inherited these characteristics. Therefore, although the GLC_FCS30-2015 provided a global 30 m land-cover product with 30 land-cover types (Table 2), the 14 LCCS level-2 detailed land-cover types were applied only for certain regions rather than the globe, illustrated in Fig. 12. In future work, quantitative retrieval models and multi-source datasets should be combined to improve the diversity of global land-cover types in GLC_FCS30-2015 and further avoid the existence of a global LCCS classification system and detailed regional land-cover classification system. This could be done, for example, by using the fractional vegetation cover (FVC) estimation models (L. Yang et al., 2017) to retrieve the annual maximum FVC and then distinguish between open and closed broadleaved or needleleaved forests, combining the time-series NDVI to split the evergreen and deciduous shrublands, as well as integrating the GLCNMO training dataset to further distinguish consolidated from unconsolidated bare areas (Tateishi et al., 2011, 2014). In addition, although the patch problem that occurred in single-date land-cover classification had been solved in the GLC_FCS30 global maps (Fig. 5), there was still a very slight boundary effect between neighbor tiles over transitional areas (for example, the bare land transited to the sparse vegetation and grassland), which was also tricky for local training and classification because the similar land-over types were classified by different local classification models. Therefore, further work should take some measures to improve the spatial consistency of GLC_FCS30 products over transition areas.
Due to the differences in classification system, spatial resolution, and mapping year, the comparisons between GLC_FCS30-2015 and other land-cover products described in Sect. 4.2 focused on a qualitative analysis over three regions only. The comparisons illustrated that GLC_FCS30-2015 had great advantages compared to CCI_LC-2015 and MCD12Q1-2015 in terms of spatial detail and had a greater diversity of land-cover types than FROM_GLC-2015 and GlobeLand30-2010; however, quantitative metrics for measuring the advantages and disadvantages of GLC_FCS30-2015 compared to other land-cover types were missing. Therefore, our future work will aim to further optimize the global validation datasets and combine more prior validation datasets so that the performance of these land-cover products can be assessed using common validation data. For example, Y. Yang et al. (2017) used common validation data to quantitatively assess the accuracy of seven global land-cover datasets over China, and Tsendbazar et al. (2015) analyzed metadata information from 12 existing GLC reference datasets and assessed their characteristics and potential uses in the context of four GLC user groups.
The GLC_FCS30-2015 product generated in this paper is available at https://doi.org/10.5281/zenodo.3986872 (Liu et al., 2020). The global land-cover products are grouped by 948 regional tiles in the GeoTIFF format, which are named “GLCFCS30_E/W**N/S**.tif”, where “E/W**N/S**” explains the longitude and latitude information of the upper left corner of each regional land-cover map. Further, each image contains a land-cover label band ranging from 0–255, and the projection relationship between label values and corresponding land-cover types has been explained in Table 2 (Sect. 3.1), and the invalid fill value is labeled as 0 and 250.
The corresponding validation dataset, produced by integrating existing prior datasets, high-resolution Google Earth imagery, time series of NDVI values for each vegetated point, and visual checking by several interpreters, is available at https://doi.org/10.5281/zenodo.3551994 (Liu et al., 2019).
In this study, a global land-cover product for 2015 that had a fine classification system (containing 16 global LCCS land-cover types as well as 14 detailed and regional land-cover types) and 30 m spatial resolution (GLC_FCS30-2015) was developed by combining time series of Landsat imagery and global training data derived from multi-source datasets. Specifically, by combining MCD43A4 NBAR, CCI_LC land-cover products, and Landsat imagery, the difficulties of collecting sufficient reliable training data were easily solved, and the fine classification system was also made use of. Local adaptive random forest models, which allow regional tuning of classification parameters to consider regional characteristics, were applied to combine the time series of Landsat SR imagery and corresponding training data to produce numerous accurate regional land-cover maps.
The GLC_FCS30-2015 product was validated using 44 043 validation samples which were generated by combining many prior validation datasets and visual interpretation of high-resolution imagery. The validation results indicated that GLC_FCS30-2015 achieved an overall accuracy of 82.5 % and a kappa coefficient of 0.774 for the Level-0 validation system (similar to that of GlobeLand30, which contains nine major land-cover types), as well as overall accuracies of 71.4 % and 68.7 % and kappa coefficients of 0.686 and 0.662 for the LCCS level-1 (containing 16 land-cover types) and LCCS level-2 (containing 24 land-cover types) validation systems, respectively. The qualitative comparisons between GLC_FCS30-2015 and other land-cover products (CCI_LC, MCD12Q1, FROM_GLC, and GlobeLand30) indicated that GLC_FCS30-2015 had great advantages over CCI_LC-2015 and MCD12Q1-2015 in terms of spatial detail and had a greater diversity of land-cover types than FROM_GLC-2015 and GlobeLand30-2010. The quantitative comparisons against the other two 30 m land-cover products (FROM_GLC and GlobeLand30) indicated that GLC_FCS30-2015 achieved the best overall accuracy of 82.5 % against FROM_GLC-2015 of 59.1 % and GlobeLand30-2010 of 75.9 %. Therefore, it was concluded that GLC_FCS30-2015 is a promising accurate land-cover product with a fine classification system and can provide important support for numerous regional or global applications.
LL and XZ designed the method. XZ and XC programmed the software while LL provided the technical support. XZ, YG, SX, and JM collected the validation dataset. XZ wrote the original draft, and LL reviewed the draft.
The authors declare that they have no conflict of interest.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
We gratefully acknowledge the free access of CCI_LC land-cover products provided by the European Space Agency, the MCD12Q1 land-cover products provided by the National Aeronautics and Space Administration, the FROM_GLC products provided by Tsinghua University, and the GlobeLand30 land-cover products provided by the National Geomatics Center of China.
This research has been supported by the Strategic Priority Research Program of the Chinese Academy of Sciences (grant no. XDA19090125), the Key Research Program of the Chinese Academy of Sciences (grant no. ZDRW-ZS-2019-1), and the National Natural Science Foundation of China (grant no. 41825002).
This paper was edited by Yuyu Zhou and reviewed by two anonymous referees.
Azzari, G. and Lobell, D. B.: Landsat-based classification in the cloud: An opportunity for a paradigm shift in land cover monitoring, Remote Sens. Environ., 202, 64–74, https://doi.org/10.1016/j.rse.2017.05.025, 2017.
Ban, Y., Gong, P., and Giri, C.: Global land cover mapping using Earth observation satellite data: Recent progresses and challenges, ISPRS J. Photogramm., 103, 1–6, https://doi.org/10.1016/j.isprsjprs.2015.01.001, 2015.
Belgiu, M. and Drăguţ, L.: Random forest in remote sensing: A review of applications and future directions, ISPRS J. Photogramm., 114, 24–31, https://doi.org/10.1016/j.isprsjprs.2016.01.011, 2016.
Bontemps, S., Defourny, P., Bogaert, E. V., Arino, O., Kalogirou, V., and Perez, J. R.: GLOBCOVER 2009 Products Description and Validation Report, available at: http://due.esrin.esa.int/files/GLOBCOVER2009_Validation_Report_2.2.pdf (last access: 15 August 2020), 2010.
Breiman, L.: Random Forests, Mach. Learn., 45, 5–32, https://doi.org/10.1023/a:1010933404324, 2001.
Buchhorn, M., Lesiv, M., Tsendbazar, N.-E., Herold, M., Bertels, L., and Smets, B.: Copernicus Global Land Cover Layers – Collection 2, Remote Sens., 12, 1044, https://doi.org/10.3390/rs12061044, 2020.
Calderón-Loor, M., Hadjikakou, M., and Bryan, B. A.: High-resolution wall-to-wall land-cover mapping and land change assessment for Australia from 1985 to 2015, Remote Sens. Environ., 252, 112148, https://doi.org/10.1016/j.rse.2020.112148, 2021.
Chen, J., Chen, J., Liao, A., Cao, X., Chen, L., Chen, X., He, C., Han, G., Peng, S., Lu, M., Zhang, W., Tong, X., and Mills, J.: Global land cover mapping at 30 m resolution: A POK-based operational approach, ISPRS J. Photogramm., 103, 7–27, https://doi.org/10.1016/j.isprsjprs.2014.09.002, 2015.
Defourny, P., Kirches, G., Brockmann, C., Boettcher, M., Peters, M., Bontemps, S., Lamarche, C., Schlerf, M., and Santoro, M.: Land Cover CCI: Product User Guide Version 2, available at: https://www.esa-landcover-cci.org/?q=webfm_send/84 (last access: 15 August 2020), 2018.
Du, P., Samat, A., Waske, B., Liu, S., and Li, Z.: Random Forest and Rotation Forest for fully polarized SAR image classification using polarimetric and spatial features, ISPRS J. Photogramm., 105, 38–53, https://doi.org/10.1016/j.isprsjprs.2015.03.002, 2015.
Farr, T. G., Rosen, P. A., Caro, E., Crippen, R., Duren, R., Hensley, S., Kobrick, M., Paller, M., Rodriguez, E., Roth, L., Seal, D., Shaffer, S., Shimada, J., Umland, J., Werner, M., Oskin, M., Burbank, D., and Alsdorf, D.: The Shuttle Radar Topography Mission, Rev. Geophys., 45, RG2004, https://doi.org/10.1029/2005rg000183, 2007.
Feng, M., Huang, C., Channan, S., Vermote, E. F., Masek, J. G., and Townshend, J. R.: Quality assessment of Landsat surface reflectance products using MODIS data, Comput. Geosci., 38, 9–22, https://doi.org/10.1016/j.cageo.2011.04.011, 2012.
Fisher, J. R. B., Acosta, E. A., Dennedy-Frank, P. J., Kroeger, T., and Boucher, T. M.: Impact of satellite imagery spatial resolution on land use classification accuracy and modeled water quality, Remote Sensing in Ecology & Conservation, 4, 137–149, https://doi.org/10.1002/rse2.61, 2018.
Foody, G. M.: Sample size determination for image classification accuracy assessment and comparison, Int. J. Remote Sens., 30, 5273–5291, https://doi.org/10.1080/01431160903130937, 2009.
Foody, G. M. and Arora, M. K.: An evaluation of some factors affecting the accuracy of classification by an artificial neural network, Int. J. Remote Sens., 18, 799–810, https://doi.org/10.1080/014311697218764, 2010.
Foody, G. M. and Mathur, A.: Toward intelligent training of supervised image classifications: directing training data acquisition for SVM classification, Remote Sens. Environ., 93, 107–117, https://doi.org/10.1016/j.rse.2004.06.017, 2004.
Friedl, M. A., Sulla-Menashe, D., Tan, B., Schneider, A., Ramankutty, N., Sibley, A., and Huang, X.: MODIS Collection 5 global land cover: Algorithm refinements and characterization of new datasets, Remote Sens. Environ., 114, 168–182, https://doi.org/10.1016/j.rse.2009.08.016, 2010.
Gómez, C., White, J. C., and Wulder, M. A.: Optical remotely sensed time series data for land cover classification: A review, ISPRS J. Photogramm., 116, 55–72, https://doi.org/10.1016/j.isprsjprs.2016.03.008, 2016.
Giri, C., Zhu, Z. L., and Reed, B.: A comparative analysis of the Global Land Cover 2000 and MODIS land cover data sets, Remote Sens. Environ., 94, 123–132, https://doi.org/10.1016/j.rse.2004.09.005, 2005.
Giri, C., Pengra, B., Long, J., and Loveland, T. R.: Next generation of global land cover characterization, mapping, and monitoring, Int. J. Appl. Earth Obs., 25, 30–37, https://doi.org/10.1016/j.jag.2013.03.005, 2013.
Gomariz-Castillo, F., Alonso-Sarría, F., and Cánovas-García, F.: Improving Classification Accuracy of Multi-Temporal Landsat Images by Assessing the Use of Different Algorithms, Textural and Ancillary Information for a Mediterranean Semiarid Area from 2000 to 2015, Remote Sens., 9, 1058, https://doi.org/10.3390/rs9101058, 2017.
Gong, P., Wang, J., Yu, L., Zhao, Y., Zhao, Y., Liang, L., Niu, Z., Huang, X., Fu, H., Liu, S., Li, C., Li, X., Fu, W., Liu, C., Xu, Y., Wang, X., Cheng, Q., Hu, L., Yao, W., Zhang, H., Zhu, P., Zhao, Z., Zhang, H., Zheng, Y., Ji, L., Zhang, Y., Chen, H., Yan, A., Guo, J., Yu, L., Wang, L., Liu, X., Shi, T., Zhu, M., Chen, Y., Yang, G., Tang, P., Xu, B., Giri, C., Clinton, N., Zhu, Z., Chen, J., and Chen, J.: Finer resolution observation and monitoring of global land cover: first mapping results with Landsat TM and ETM+ data, Int. J. Remote Sens., 34, 2607–2654, https://doi.org/10.1080/01431161.2012.748992, 2013.
Gong, P., Liu, H., Zhang, M., Li, C., Wang, J., Huang, H., Clinton, N., Ji, L., Li, W., Bai, Y., Chen, B., Xu, B., Zhu, Z., Yuan, C., Ping Suen, H., Guo, J., Xu, N., Li, W., Zhao, Y., Yang, J., Yu, C., Wang, X., Fu, H., Yu, L., Dronova, I., Hui, F., Cheng, X., Shi, X., Xiao, F., Liu, Q., and Song, L.: Stable classification with limited sample: transferring a 30 m resolution sample set collected in 2015 to mapping 10 m resolution global land cover in 2017, Sci. Bull., 64, 370–373, https://doi.org/10.1016/j.scib.2019.03.002, 2019.
Gong, P., Li, X., Wang, J., Bai, Y., Chen, B., Hu, T., Liu, X., Xu, B., Yang, J., Zhang, W., and Zhou, Y.: Annual maps of global artificial impervious area (GAIA) between 1985 and 2018, Remote Sens. Environ., 236, 111510, https://doi.org/10.1016/j.rse.2019.111510, 2020.
Gorelick, N., Hancher, M., Dixon, M., Ilyushchenko, S., Thau, D., and Moore, R.: Google Earth Engine: Planetary-scale geospatial analysis for everyone, Remote Sens. Environ., 202, 18–27, https://doi.org/10.1016/j.rse.2017.06.031, 2017.
Grekousis, G., Mountrakis, G., and Kavouras, M.: An overview of 21 global and 43 regional land-cover mapping products, Int. J. Remote Sens., 36, 5309–5335, https://doi.org/10.1080/01431161.2015.1093195, 2015.
Griffiths, P., Linden, S. V. D., Kuemmerle, T., and Hostert, P.: A Pixel-Based Landsat Compositing Algorithm for Large Area Land Cover Mapping, IEEE J. Sel. Top. Appl., 6, 2088–2101, https://doi.org/10.1109/JSTARS.2012.2228167, 2013.
Hansen, M. C., Egorov, A., Potapov, P. V., Stehman, S. V., Tyukavina, A., Turubanova, S. A., Roy, D. P., Goetz, S. J., Loveland, T. R., Ju, J., Kommareddy, A., Kovalskyy, V., Forsyth, C., and Bents, T.: Monitoring conterminous United States (CONUS) land cover change with Web-Enabled Landsat Data (WELD), Remote Sens. Environ., 140, 466–484, https://doi.org/10.1016/j.rse.2013.08.014, 2014.
Herold, M., Woodcock, C., Stehman, S., Nightingale, J., Friedl, M., and Schmullius, C.: The GOFC-GOLD/CEOS land cover harmonization and validation initiative: technical design and implementation, available at: http://articles.adsabs.harvard.edu/pdf/2010ESASP.686E.268H (last access: 15 August 2020), 2010.
Huete, A., Justice, C., and Van Leeuwen, W.: MODIS vegetation index (MOD13), Algorithm theoretical basis document, 3, 213, 1999.
Inglada, J., Vincent, A., Arias, M., Tardy, B., Morin, D., and Rodes, I.: Operational High Resolution Land Cover Map Production at the Country Scale Using Satellite Image Time Series, Remote Sens., 9, 95, https://doi.org/10.3390/rs9010095, 2017.
Jin, H., Stehman, S. V., and Mountrakis, G.: Assessing the impact of training sample selection on accuracy of an urban classification: a case study in Denver, Colorado, Int. J. Remote Sens., 35, 2067–2081, https://doi.org/10.1080/01431161.2014.885152, 2014.
Jokar Arsanjani, J., See, L., and Tayyebi, A.: Assessing the suitability of GlobeLand30 for mapping land cover in Germany, Int. J. Digit. Earth, 9, 873–891, https://doi.org/10.1080/17538947.2016.1151956, 2016a.
Jokar Arsanjani, J., Tayyebi, A., and Vaz, E.: GlobeLand30 as an alternative fine-scale global land cover map: Challenges, possibilities, and implications for developing countries, Habitat Int., 55, 25–31, https://doi.org/10.1016/j.habitatint.2016.02.003, 2016b.
Kang, J., Wang, Z., Sui, L., Yang, X., Ma, Y., and Wang, J.: Consistency Analysis of Remote Sensing Land Cover Products in the Tropical Rainforest Climate Region: A Case Study of Indonesia, Remote Sens., 12, 1410, https://doi.org/10.3390/rs12091410, 2020.
Lehner, B. and Döll, P.: Global Lakes and Wetlands Database GLWD, GLWD Docu mentation, available at: https://www.worldwildlife.org/pages/global-lakes-and-wetlands-database (last access: 15 August 2020), 2004.
Li, C., Peng, G., Wang, J., Zhu, Z., Biging, G. S., Yuan, C., Hu, T., Zhang, H., Wang, Q., and Li, X.: The first all-season sample set for mapping global land cover with Landsat-8 data, Sci. Bull., 62, 508–515, https://doi.org/10.1016/j.scib.2017.03.011, 2017.
Li, M., Zang, S., Zhang, B., Li, S., and Wu, C.: A Review of Remote Sensing Image Classification Techniques: the Role of Spatio-contextual Information, European Journal of Remote Sensing, 47, 389-411, https://doi.org/10.5721/EuJRS20144723, 2017.
Liu, L., Zhang, X., Hu, Y., and Wang, Y.: Automatic land cover mapping for Landsat data based on the time-series spectral image database, Geoscience and Remote Sensing Symposium (IGARSS), 23–28 July 2017, Fort Worth, 17379785, 4282–4285, https://doi.org/10.5281/zenodo.3551995, 2017.
Liu, L., Gao, Y., Zhang, X., Chen, X., and Xie, S.: A Dataset of Global Land Cover Validation Samples, Zenodo [data], https://doi.org/10.5281/zenodo.3551995, 2019.
Liu, L., Zhang, X., Chen, X., Gao, Y., and Mi, J.: GLC_FCS30: Global land-cover product with fine classification system at 30 m using time-series Landsat imagery, Zenodo [data], https://doi.org/10.5281/zenodo.3986872, 2020.
Loveland, T. R., Reed, B. C., Brown, J. F., Ohlen, D. O., Zhu, Z., Yang, L., and Merchant, J. W.: Development of a global land cover characteristics database and IGBP DISCover from 1 km AVHRR data, Int. J. Remote Sens., 21, 1303–1330, https://doi.org/10.1080/014311600210191, 2000.
Ludwig, C., Walli, A., Schleicher, C., Weichselbaum, J., and Riffler, M.: A highly automated algorithm for wetland detection using multi-temporal optical satellite data, Remote Sens. Environ., 224, 333–351, https://doi.org/10.1016/j.rse.2019.01.017, 2019.
Massey, R., Sankey, T. T., Yadav, K., Congalton, R. G., and Tilton, J. C.: Integrating cloud-based workflows in continental-scale cropland extent classification, Remote Sens. Environ., 219, 162–179, https://doi.org/10.1016/j.rse.2018.10.013, 2018.
Mellor, A., Boukir, S., Haywood, A., and Jones, S.: Exploring issues of training data imbalance and mislabelling on random forest performance for large area land cover classification using the ensemble margin, ISPRS J. Photogramm., 105, 155–168, https://doi.org/10.1016/j.isprsjprs.2015.03.014, 2015.
Miller, J. D. and Thode, A. E.: Quantifying burn severity in a heterogeneous landscape with a relative version of the delta Normalized Burn Ratio (dNBR), Remote Sens. Environ., 109, 66–80, https://doi.org/10.1016/j.rse.2006.12.006, 2007.
Mishra, V. N., Prasad, R., Kumar, P., Gupta, D. K., and Ohri, A.: Evaluating the effects of spatial resolution on land use and land cover classification accuracy, International Conference on Microwave, Optical and Communication Engineering (ICMOCE), 18–20 December 2015, Bhubaneswar, 16072605, 208–211, https://doi.org/10.1109/ICMOCE.2015.7489727, 2015.
Olofsson, P., Foody, G. M., Stehman, S. V., and Woodcock, C. E.: Making better use of accuracy data in land change studies: Estimating accuracy and area and quantifying uncertainty using stratified estimation, Remote Sens. Environ., 129, 122–131, https://doi.org/10.1016/j.rse.2012.10.031, 2013.
Olofsson, P., Foody, G. M., Herold, M., Stehman, S. V., Woodcock, C. E., and Wulder, M. A.: Good practices for estimating area and assessing accuracy of land change, Remote Sens. Environ., 148, 42–57, https://doi.org/10.1016/j.rse.2014.02.015, 2014.
Pelletier, C., Valero, S., Inglada, J., Champion, N., and Dedieu, G.: Assessing the robustness of Random Forests to map land cover with high resolution satellite image time series over large areas, Remote Sens. Environ., 187, 156–168, https://doi.org/10.1016/j.rse.2016.10.010, 2016.
Pelletier, C., Valero, S., Inglada, J., Champion, N., Marais Sicre, C., and Dedieu, G.: Effect of Training Class Label Noise on Classification Performances for Land Cover Mapping with Satellite Image Time Series, Remote Sensing, 9, 173, https://doi.org/10.3390/rs9020173, 2017.
Phalke, A. R., Özdoğan, M., Thenkabail, P. S., Erickson, T., Gorelick, N., Yadav, K., and Congalton, R. G.: Mapping croplands of Europe, Middle East, Russia, and Central Asia using Landsat, Random Forest, and Google Earth Engine, ISPRS J. Photogramm., 167, 104–122, https://doi.org/10.1016/j.isprsjprs.2020.06.022, 2020.
Radoux, J., Lamarche, C., Van Bogaert, E., Bontemps, S., Brockmann, C., and Defourny, P.: Automated Training Sample Extraction for Global Land Cover Mapping, Remote Sens., 6, 3965–3987, https://doi.org/10.3390/rs6053965, 2014.
Rodriguez-Galiano, V. F., Chica-Olmo, M., Abarca-Hernandez, F., Atkinson, P. M., and Jeganathan, C.: Random Forest classification of Mediterranean land cover using multi-seasonal imagery and multi-seasonal texture, Remote Sens. Environ., 121, 93–107, https://doi.org/10.1016/j.rse.2011.12.003, 2012.
Roy, D. P. and Kumar, S. S.: Multi-year MODIS active fire type classification over the Brazilian Tropical Moist Forest Biome, Int. J. Digit. Earth, 10, 54–84, https://doi.org/10.1080/17538947.2016.1208686, 2016.
Roy, D. P., Qin, Y., Kovalskyy, V., Vermote, E. F., Ju, J., Egorov, A., Hansen, M. C., Kommareddy, I., and Yan, L.: Conterminous United States demonstration and characterization of MODIS-based Landsat ETM+ atmospheric correction, Remote Sens. Environ., 140, 433–449, https://doi.org/10.1016/j.rse.2013.09.012, 2014.
Tachikawa, T., Hato, M., Kaku, M., and Iwasaki, A.: Characteristics of ASTER GDEM Version 2, Geoscience and Remote Sensing Symposium (IGARSS), 24–29 July 2011, Vancouver, 12477285, 3657–3660, https://doi.org/10.1109/IGARSS.2011.6050017, 2011.
Tateishi, R., Uriyangqai, B., Al-Bilbisi, H., Ghar, M. A., Tsend-Ayush, J., Kobayashi, T., Kasimu, A., Hoan, N. T., Shalaby, A., Alsaaideh, B., Enkhzaya, T., Gegentana, and Sato, H. P.: Production of global land cover data – GLCNMO, Int. J. Digit. Earth, 4, 22–49, https://doi.org/10.1080/17538941003777521, 2011.
Tateishi, R., Hoan, N. T., Kobayashi, T., Alsaaideh, B., Tana, G., and Phong, D. X.: Production of Global Land Cover Data – GLCNMO2008, Journal of Geography and Geology, 6, 99, https://doi.org/10.5539/jgg.v6n3p99, 2014.
Teluguntla, P., Thenkabail, P. S., Oliphant, A., Xiong, J., Gumma, M. K., Congalton, R. G., Yadav, K., and Huete, A.: A 30 m landsat-derived cropland extent product of Australia and China using random forest machine learning algorithm on Google Earth Engine cloud computing platform, ISPRS J. Photogramm., 144, 325–340, https://doi.org/10.1016/j.isprsjprs.2018.07.017, 2018.
Tootchi, A., Jost, A., and Ducharne, A.: Multi-source global wetland maps combining surface water imagery and groundwater constraints, Earth Syst. Sci. Data, 11, 189–220, https://doi.org/10.5194/essd-11-189-2019, 2019.
Tsendbazar, N. E., de Bruin, S., and Herold, M.: Assessing global land cover reference datasets for different user communities, ISPRS J. Photogramm., 103, 93–114, https://doi.org/10.1016/j.isprsjprs.2014.02.008, 2015.
Tucker, C. J.: Red and photographic infrared linear combinations for monitoring vegetation, Remote Sens. Environ., 8, 127–150, https://doi.org/10.1016/0034-4257(79)90013-0, 1979.
Vermote, E., Justice, C., Claverie, M., and Franch, B.: Preliminary analysis of the performance of the Landsat 8/OLI land surface reflectance product, Remote Sens. Environ., 185, 46–56, https://doi.org/10.1016/j.rse.2016.04.008, 2016.
Wang, J., Zhao, Y., Li, C., Yu, L., Liu, D., and Gong, P.: Mapping global land cover in 2001 and 2010 with spatial-temporal consistency at 250 m resolution, ISPRS J. Photogramm., 103, 38–47, https://doi.org/10.1016/j.isprsjprs.2014.03.007, 2015.
Wang, Y., Liu, L., Hu, Y., Li, D., and Li, Z.: Development and validation of the Landsat-8 surface reflectance products using a MODIS-based per-pixel atmospheric correction method, Int. J. Remote Sens., 37, 1291–1314, https://doi.org/10.1080/01431161.2015.1104742, 2016.
Wang, Z. and Liu, L.: Assessment of Coarse-Resolution Land Cover Products Using CASI Hyperspectral Data in an Arid Zone in Northwestern China, Remote Sens., 6, 2864–2883, https://doi.org/10.3390/rs6042864, 2014.
Wessels, K., van den Bergh, F., Roy, D., Salmon, B., Steenkamp, K., MacAlister, B., Swanepoel, D., and Jewitt, D.: Rapid Land Cover Map Updates Using Change Detection and Robust Random Forest Classifiers, Remote Sens., 8, 888, https://doi.org/10.3390/rs8110888, 2016.
Woodcock, C. E., Allen, R. G., and Anderson, M. C.: Free access to Landsat imagery, Science, 320, 1011, https://doi.org/10.1126/science.320.5879.1011a, 2008.
Xian, G., Homer, C., and Fry, J.: Updating the 2001 National Land Cover Database land cover classification to 2006 by using Landsat imagery change detection methods, Remote Sens. Environ., 113, 1133–1147, https://doi.org/10.1016/j.rse.2009.02.004, 2009.
Xie, S., Liu, L., Zhang, X., and Chen, X.: Annual land-cover mapping based on multi-temporal cloud-contaminated landsat images, Int. J. Remote Sens., 40, 1–23, https://doi.org/10.1080/01431161.2018.1553320, 2018.
Xiong, J., Thenkabail, P. S., Gumma, M. K., Teluguntla, P., Poehnelt, J., Congalton, R. G., Yadav, K., and Thau, D.: Automated cropland mapping of continental Africa using Google Earth Engine cloud computing, ISPRS J. Photogramm., 126, 225–244, https://doi.org/10.1016/j.isprsjprs.2017.01.019, 2017.
Xu, H.: Modification of normalised difference water index (NDWI) to enhance open water features in remotely sensed imagery, Int. J. Remote Sens., 27, 3025–3033, https://doi.org/10.1080/01431160600589179, 2006.
Yang, L., Jia, K., Liang, S., Wei, X., Yao, Y., and Zhang, X.: A Robust Algorithm for Estimating Surface Fractional Vegetation Cover from Landsat Data, Remote Sens., 9, 857, https://doi.org/10.3390/rs9080857, 2017.
Yang, Y., Xiao, P., Feng, X., and Li, H.: Accuracy assessment of seven global land cover datasets over China, ISPRS J. Photogramm., 125, 156–173, https://doi.org/10.1016/j.isprsjprs.2017.01.016, 2017.
Zhang, H. K. and Roy, D. P.: Using the 500 m MODIS land cover product to derive a consistent continental scale 30 m Landsat land cover classification, Remote Sens. Environ., 197, 15–34, https://doi.org/10.1016/j.rse.2017.05.024, 2017.
Zhang, X. and Liu, L.: Development of a global 30 m impervious surface map using multi-source and multi-temporal remote sensing datasets with the Google Earth Engine platform, Zenodo [data], https://doi.org/10.5281/zenodo.3505079, 2019.
Zhang, X., Liu, L., Wang, Y., Hu, Y., and Zhang, B.: A SPECLib-based operational classification approach: A preliminary test on China land cover mapping at 30 m, Int. J. Appl. Earth Obs., 71, 83–94, https://doi.org/10.1016/j.jag.2018.05.006, 2018.
Zhang, X., Liu, L., Chen, X., Xie, S., and Gao, Y.: Fine Land-Cover Mapping in China Using Landsat Datacube and an Operational SPECLib-Based Approach, Remote Sens., 11, 1056, https://doi.org/10.3390/rs11091056, 2019.
Zhang, X., Liu, L., Wu, C., Chen, X., Gao, Y., Xie, S., and Zhang, B.: Development of a global 30 m impervious surface map using multisource and multitemporal remote sensing datasets with the Google Earth Engine platform, Earth Syst. Sci. Data, 12, 1625–1648, https://doi.org/10.5194/essd-12-1625-2020, 2020.
Zhu, Z. and Woodcock, C. E.: Object-based cloud and cloud shadow detection in Landsat imagery, Remote Sens. Environ., 118, 83–94, https://doi.org/10.1016/j.rse.2011.10.028, 2012.
Zhu, Z., Woodcock, C. E., Rogan, J., and Kellndorfer, J.: Assessment of spectral, polarimetric, temporal, and spatial dimensions for urban and peri-urban land cover classification using Landsat and SAR data, Remote Sens. Environ., 117, 72–82, https://doi.org/10.1016/j.rse.2011.07.020, 2012.
Zhu, Z., Wang, S. X., and Woodcock, C. E.: Improvement and expansion of the Fmask algorithm: cloud, cloud shadow, and snow detection for Landsats 4–7, 8, and Sentinel 2 images, Remote Sens. Environ., 159, 269–277, https://doi.org/10.1016/j.rse.2014.12.014, 2015.
Zhu, Z., Gallant, A. L., Woodcock, C. E., Pengra, B., Olofsson, P., Loveland, T. R., Jin, S., Dahal, D., Yang, L., and Auch, R. F.: Optimizing selection of training and auxiliary data for operational land cover classification for the LCMAP initiative, ISPRS J. Photogramm., 122, 206–221, https://doi.org/10.1016/j.isprsjprs.2016.11.004, 2016.