the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 09 Apr 2020
| 09 Apr 2020
Asset exposure data for global physical risk assessment
Dario Stocker
Thomas Röösli
David N. Bresch
One of the challenges in globally consistent assessments of physical climate risks is the fact that asset exposure data are either unavailable or restricted to single countries or regions. We introduce a global high-resolution asset exposure dataset responding to this challenge. The data are produced using “lit population” (LitPop), a globally consistent methodology to disaggregate asset value data proportional to a combination of nightlight intensity and geographical population data. By combining nightlight and population data, unwanted artefacts such as blooming, saturation, and lack of detail are mitigated. Thus, the combination of both data types improves the spatial distribution of macroeconomic indicators. Due to the lack of reported subnational asset data, the disaggregation methodology cannot be validated for asset values. Therefore, we compare disaggregated gross domestic product (GDP) per subnational administrative region to reported gross regional product (GRP) values for evaluation. The comparison for 14 industrialized and newly industrialized countries shows that the disaggregation skill for GDP using nightlights or population data alone is not as high as using a combination of both data types. The advantages of LitPop are global consistency, scalability, openness, replicability, and low entry threshold. The open-source LitPop methodology and the publicly available asset exposure data offer value for manifold use cases, including globally consistent economic disaster risk assessments and climate change adaptation studies, especially for larger regions, yet at considerably high resolution. The code is published on GitHub as part of the open-source software CLIMADA (CLIMate ADAptation) and archived in the ETH Data Archive with the link https://doi.org/10.5905/ethz-1007-226 (Bresch et al., 2019b). The resulting asset exposure dataset for 224 countries is archived in the ETH Research Repository with the link https://doi.org/10.3929/ethz-b-000331316 (Eberenz et al., 2019).
Please read the corrigendum first before continuing.
-
Notice on corrigendum
The requested paper has a corresponding corrigendum published. Please read the corrigendum first before downloading the article.
-
Article
(5191 KB)
- Corrigendum
-
Supplement
(61 KB)
-
The requested paper has a corresponding corrigendum published. Please read the corrigendum first before downloading the article.
- Article
(5191 KB) - Full-text XML
- Corrigendum
-
Supplement
(61 KB) - BibTeX
- EndNote





The modeling of climate risks on a global scale requires globally consistent data representing hazard, vulnerability, and exposure, as defined by the Intergovernmental Panel on Climate Change (IPCC, 2012, 2014) among others. While natural hazard data can be derived from general circulation models, there is a lack of consistent exposure data on a global scale. Exposure is frequently defined as an inventory of elements at risk from natural hazards (Cardona et al., 2012; UNISDR, 2009). For the modeling of physical risk as the direct economic impacts of disasters, exposure should specifically represent the spatial distribution of physical asset stock, i.e., buildings and machinery. While aggregate estimates of asset values are available at country level, open data on the spatial distribution of asset values are scarce. Proprietary asset exposure data (e.g., owned by insurance companies) are usually not publicly available.
Due to the lack of comprehensive asset stock inventories, large-scale asset exposure maps are often estimated top-down, using downscaling techniques (De Bono and Mora, 2014; Gunasekera et al., 2015; Murakami and Yamagata, 2019). On a country aggregate level, estimates of total asset values can be derived from socioeconomic flow measures, such as gross domestic product (GDP), since the two indicators exhibit strong correlations (Kuhn and Ríos-Rull, 2016). Annual values of socioeconomic flow variables, particularly GDP, are often more readily available than asset values. Assuming that human presence and activity are proxies of economic output, downscaling of GDP has been based on geographical population data (Kummu et al., 2018) and on population combined with land use, road networks, and locations of airports (Murakami and Yamagata, 2019). High-resolution yearly GDP maps based on these approaches are publicly available (Geiger et al., 2017; Kummu et al., 2018). Global asset exposure data were produced for the Global Assessment Report 2013 of the United Nations Office for Disaster Risk Reduction (UNISDR), following a downscaling approach (De Bono and Mora, 2014). However, the data's use beyond the scope of the Global Assessment Report is limited, because the data represent urban areas only and the methodology is not easily reproducible and thus not adaptable. For future quantitative risk assessments, more recent exposure data would be desirable. An alternative methodology to model global asset exposure based on the combination of diverse datasets was presented by Gunasekera et al. (2015). The authors combined data on built-up areas, building typologies, and construction cost with sector-specific asset data and GDP disaggregated proportional to population density. Unfortunately, the source code and resulting exposure data have not been made publicly available. Reproducing these previously mentioned exposure modeling efforts is beyond the scope of most economic disaster risk assessments and climate change adaptation studies.
In recent years, the use of nightlight intensity from satellite imagery has seen a marked increase in science in general and especially for the disaggregation of socioeconomic indicators (Elvidge et al., 2012; Gettelman et al., 2017; Ghosh et al., 2013; Mellander et al., 2015; Pinkovskiy, 2014; Sutton et al., 2007; Sutton and Costanza, 2002). Being publicly available and updated regularly, global nightlight images have been proven to be a useful source of information and are commonly used in scientific contexts for the estimation of unavailable GDP or growth data (Henderson et al., 2012). However, there are some technical limits to the usage of nightlight satellite imagery (Han et al., 2018), especially saturation and blooming. As luminosity can only be distinguished up to a certain brightness, saturation may lead to very bright spots being underrepresented. In state-of-the-art nightlight products from the Suomi National Polar-orbiting Partnership's Visible Infrared Imaging Radiometer Suite (VIIRS), there are 256 shades of brightness, from the minimum zero (no light emission) to the maximum 255 (NASA Earth Observatory, 2017; Román et al., 2018). Any pixel brighter than what would entail a value of 255 will also appear at this value (Elvidge et al., 2007). Brightness can exude from bright pixels to neighboring pixels, causing the brightness in the latter to be overestimated, leading to blooming. This issue occurs in particular in large urban areas and on specific surfaces, such as sand and water (Elvidge et al., 2004; Small et al., 2005). As a consequence of saturation, socioeconomic indicators scale rather exponentially than linearly with nightlight intensity (Sutton and Costanza, 2002; Zhao et al., 2015, 2017). To counteract the saturation effect, Gettelman et al. (2017) and Aznar-Siguan and Bresch (2019) used exponentially scaled nightlight intensity as a basis for GDP disaggregation for tropical cyclone risk assessments. Saturation and blooming can also be mitigated by combining nightlights with other data types: Sutton et al. (2007) combined the areal extent of lit area with population data to estimate GDP at a subnational level. Zhao et al. (2017) enhanced nightlight intensity values with population data to get a more accurate estimation of spatial economic activity in China. This is based on the observation that there is also an exponential relationship between nightlight intensity and population density. The authors showed that the product of nightlight intensity and gridded population count (called “lit population” by the authors) is a better proxy for economic activity in China than nightlight intensity alone.
Here, we are using and expanding the lit population approach presented by Zhao et al. (2017) to define and implement a globally consistent methodology for asset exposure disaggregation, named LitPop hereafter. This paper presents global gridded asset exposure data and documents and evaluates the underlying LitPop methodology. The resulting asset exposure dataset for 224 countries is made available online at the ETH Research Repository (Eberenz et al., 2019). It is suitable to provide the globally consistent asset exposure base for modeling physical risks. The methodology is published on GitHub as part of the open-source event-based probabilistic impact model CLIMADA (CLIMate ADAptation) (Aznar-Siguan and Bresch, 2019; Bresch et al., 2019a) and archived in the ETH Data Archive (Bresch et al., 2019b).
Information on input data, methodology, and the evaluation approach is provided in Sect. 2. Subsequently, the resulting global asset exposure data are presented, and evaluation results are shown in Sect. 3. The advantages and limitations of the methodology are discussed in Sect. 4. Please refer to Sect. 5 for data and code availability.
2.1 Overview
The core functionality of the LitPop methodology is the spatial disaggregation of national total asset values to obtain a gridded asset exposure product. Gridded nightlight intensity (Sect. 2.2) and gridded population data (Sect. 2.3) are combined to compute a digital number at grid cell level. Physical asset stock values (i.e., produced capital, Sect. 2.4.1) are then disaggregated proportionally to the digital number per grid cell (Sect. 2.5). This results in the gridded asset exposure dataset presented here. Instead of the physical asset stock, GDP (Sect. 2.4.2) or gross regional product (GRP, Sect. 2.4.3) can be distributed to obtain GDP per grid cell. Because of a lack of subnational produced capital data, GDP and GRP are used to evaluate the methodology by assessing the subnational disaggregation skill for varied combinations of the input data, as described in Sect. 2.6. A detailed overview of the input data is provided in Table 1; the disaggregation approach is illustrated in Fig. 1.
Table 1Overview of input dataset, including information on usage, resolution, reference year, data source, and references. The reference year indicates the year for which the data used were provided. * For GDP, the value of 2014 in current US dollars was used for 203 countries. For 21 countries without GDP data available for 2014, the closest available data points from the years 2000 to 2017 were used instead.
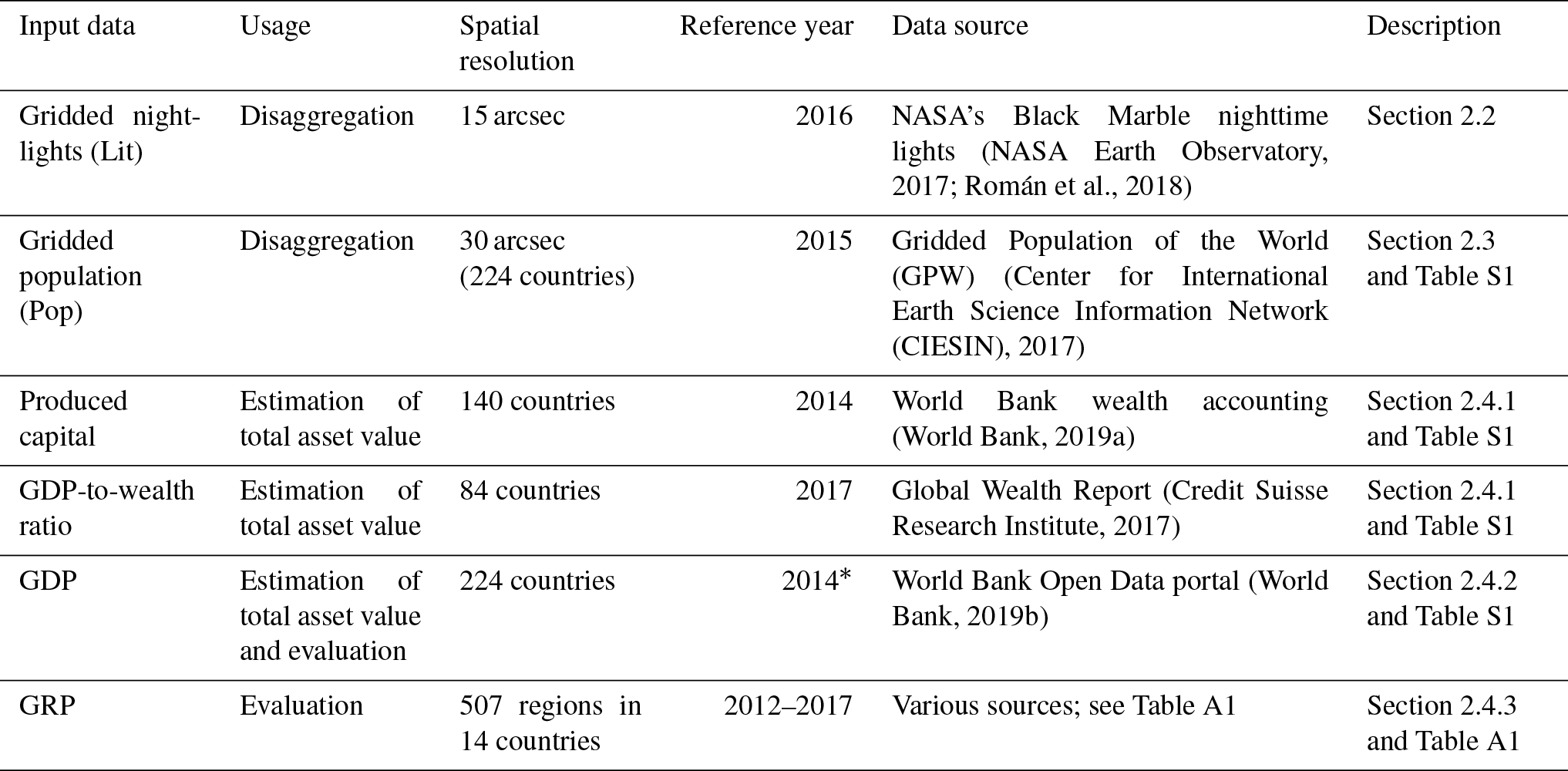
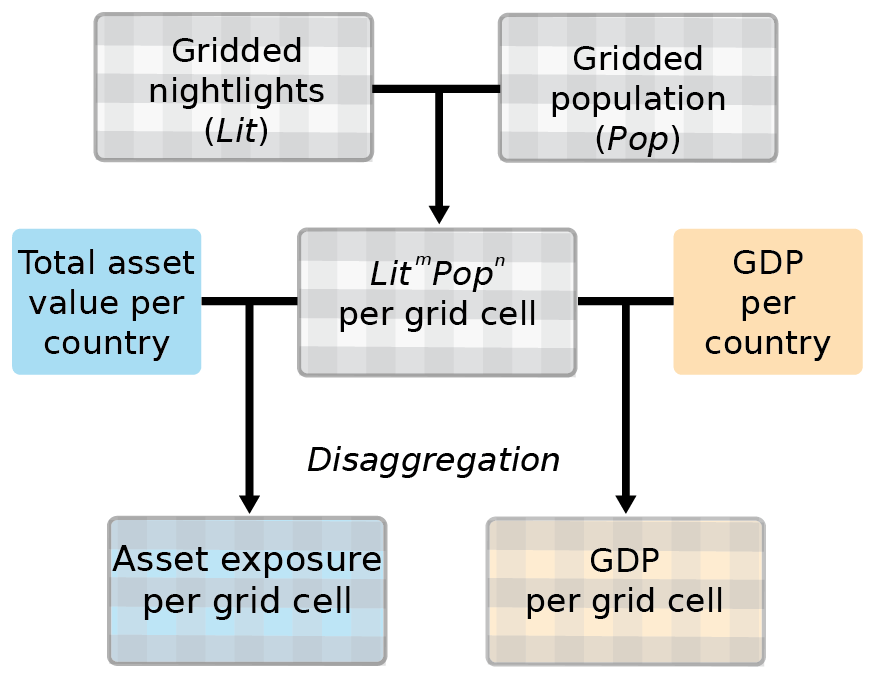
Figure 1Work flow of the LitPop downscaling: gridded nightlights (Lit) and population (Pop) data are combined to compute gridded digital number LitmPopn (Eq. 1). Then, total asset value per country (i.e., produced capital or nonfinancial wealth) is disaggregated proportionally to LitmPopn to obtain gridded asset exposure data (Eq. 2). GDP is disaggregated in the same way and compared against reported GRP for the evaluation of the downscaling approach.
2.2 Satellite nightlight data
The nightlight intensity products used here are nighttime lights of the Black Marble 2016 annual composite of the VIIRS day–night band (DNB) at 15 arcsec resolution (Román et al., 2018), downloaded from the NASA Earth Observatory (2017). The processed datasets of luminosity by human activity based on VIIRS mark a distinct improvement over previous technologies, allowing for a greater range of light to be recorded (Carlowicz, 2012). The sun-synchronous satellite passes each place on Earth twice a day, at approximately 01:30 and 13:30 local time. Nightlight intensity on a scale from 0 to 255 is a variable derived from raw measurements. To isolate luminosity from sustained human activity, the Black Marble nightlight product includes corrections for Lunar artifacts, cloud, terrain, atmosphere, snow, airglow, stray light, and seasonal effects (Carlowicz, 2017; Lee et al., 2014; Román et al., 2018). The data are provided for 2012 and 2016 at a resolution of 15 arcsec, which corresponds to around 500 m at the Equator. The open-source code developed here can be adapted easily to use other versions and sources of nightlight data. This could be of interest for near-time applications in the future, as daily nightlight images could be available in the future (Carlowicz, 2017).
2.3 Gridded population data
The Gridded Population of the World (GPW) dataset is a spatially explicit representation of the world's population. It is based on two sets of inputs: nonspatial population data and cartography data. Using census data or population figures by the official national statistics offices, it uniformly distributes the numbers at the smallest available administrative unit to the corresponding cartographic shape, without taking into account any ancillary sources (Doxsey-Whitfield et al., 2015). The data quality for each country strongly depends on the underlying level of availability of population data. For example, for Canada, population data are available down to the fifth subnational administrative unit, of which 493 185 exist. The information for Canada is hence a lot more fine-grained than for instance for Jamaica or Uzbekistan, where population numbers are only recorded at the first subnational administrative unit (Socioeconomic Data and Applications Center (SEDAC), 2017). The level of detail and number of subnational administrative units resolved per country are listed in Table S1 in the Supplement. While modeling is kept at a minimum in the GPW dataset, values are inflated or deflated from the latest year with data available to 2000, 2005, 2010, 2015, and 2020 (Center for International Earth Science Information Network (CIESIN), 2017).
GPW was selected for the LitPop methodology because, unlike other spatial population datasets, it does not incorporate nightlight satellite data or other auxiliary data sources (Leyk et al., 2019). This allows us to enhance nightlight data with a completely independent dataset. Moreover, it is released under the Creative Commons license. From GPW, the Population Count v4.10 data at the highest available resolution, 30 arcsec, are used, because they are the closest to NASA's nightlight dataset, in terms of both spatial resolution and available time steps.
2.4 Socioeconomic indicators
2.4.1 Total asset value per country
The World Bank's produced capital stock (World Bank, 2018) is one of the most comprehensive global estimates of the value of manufactured or built assets per country. It has been used as an indicator of exposure to natural disaster in the UNISDR's Global Assessment Report 2013 (De Bono and Mora, 2014). Produced capital accounts for machinery, equipment, and physical structures (World Bank, 2018). It also includes a fixed scale-up of 24 % to account for the value of built-up land.
Produced capital values are currently available for 140 countries and five time steps: 1995, 2000, 2005, 2010, and 2014 from the World Bank wealth accounting (World Bank, 2019a). Per default, the scale-up for built-up land is subtracted, assuming that there is no direct damage to the value of the land itself in the case of disaster. While not universally true, this assumption is based on the focus of the asset exposure data for the purpose of assessing direct impact on tangible structures. For applications considering the impact on the value of land, the linear scale-up can be reapplied before utilization of the asset exposure data.
Out of a total of 250 countries we considered for the production of this dataset, produced capital numbers for 2014 are available for 140 countries. For these 140 countries, produced capital for 2014 was used here as the total asset value for disaggregation. For an additional 87 countries, total asset values were set to nonfinancial wealth. Nonfinancial wealth was computed from the country's GDP and the GDP-to-wealth ratio estimates derived from the Credit Suisse Research Institute's Global Wealth Report (Credit Suisse Research Institute, 2017). This approach has previously been followed by Geiger (2018). We compared produced capital and nonfinancial wealth for 140 countries (Table S1 in the Supplement) and found that nonfinancial wealth can be used as a conservative approximation of produced capital. For 59 of the 87 countries with neither produced capital nor nonfinancial wealth data available, an average GDP-to-wealth ratio of 1.247 was applied. In summary, the whole dataset contains gridded asset exposure data for a total of 224 countries, ignoring 26 countries and areas due to lack of data. Missing countries and areas (with currently assigned ISO 3166-1 alpha-3 codes) are the Åland Islands, Antarctica, Bonaire, British Indian Ocean Territory, Sint Eustatius and Saba, Bouvet Island, the Cocos (Keeling) Islands, Christmas Island, Guadeloupe, French Guiana, French Southern and Antarctic Territories, Heard Island and the McDonald Islands, Holy See, Kosovo, Libya, Martinique, Mayotte, Pitcairn, Palestine, Réunion, South Georgia and the South Sandwich Islands, South Sudan, Svalbard and Jan Mayen, Syrian Arab Republic, Tokelau, the United States Minor Outlying Islands, and the Western Sahara. An overview of the utilized data per country, including produced capital (were available), GDP-to-wealth ratios, and GDP for 2014, is provided in Table S1.
2.4.2 GDP
GDP is a well-established indicator of macroeconomic output. For most countries in the world, annual values are available dating back several decades. National GDP data in current US dollars in 2014 or the nearest available year are retrieved from the World Bank Open Data portal (World Bank, 2019b).
While GDP is not a direct measure of physical asset values, it is used here both for scaling asset values in time to fill data gaps and for the evaluation of the LitPop methodology. The underlying assumption is that within a country GDP and wealth are correlated; i.e., a higher GDP value is equivalent to higher asset values. This correlation has been established in empirical studies (Kuhn and Ríos-Rull, 2016).
2.4.3 GRP
The subnational equivalent to GDP is often referred to as GRP. GRP can be used to improve the downscaling of GDP, especially for countries with considerable regional differences. As described in Sect. 2.6 below, we use GRP data from 14 countries to evaluate the LitPop methodology by assessing its skill to disaggregate national GDP to a subnational level. As there is no unified data source for GRP, it was gathered manually from government sources and OECD.Stat (Organisation for Economic Co-operation and Development, 2019). The countries used for evaluation are Australia, Brazil, Canada, Switzerland, China, Germany, France, Indonesia, India, Japan, Mexico, Turkey, the USA, and South Africa. The aim of the selection was to include countries from as wide a range as possible of income groups and world regions. Since the selection of countries was limited by the availability of GRP data, the selection has a bias towards industrialized and newly industrialized OECD member states. According to World Bank income groups, these countries include eight countries from the high-income group (World Bank income group 4), four countries from the upper-middle-income group (3), two countries from the lower-middle-income group (2), and no countries from the low-income group (1). Income groups and data sources per country are listed in Table A1 in the Appendix.
2.5 Disaggregation of asset exposure
To produce a high-resolution asset exposure map, the total asset value per country is disaggregated proportional to a function of nightlight luminosity and population count. This approach is closely adapted from the work of Zhao et al. (2017). In their paper, historic GDP is disaggregated proportionally to a digital number computed from a multiplicative function of nightlights and population with the aim to make spatial GDP predictions for China. The underlying idea is to enhance brightness values with spatial population data to get a more accurate estimation of spatial economic activity. The work flow of the asset exposure disaggregation is described here in detail and illustrated in Fig. 1.
In a first step, the two gridded input datasets are interpolated linearly to the same resolution of 30 arcsec. Then, the combination of the two aforementioned datasets is conducted for each grid cell:
where the digital number value LitmPop per grid cell (pix) is computed from the grid cell's nightlight intensity , population count , and the exponents . For all m>0, the added δ is equal to 1 to ensure that non-illuminated but populated grid cells do not get assigned zero values. In the case that nightlight data are used on their own without population data (m=0), δ is set to zero.
In a second step, gridded LitmPopn is taken as a relative representation of economic stocks at each grid cell. It is used to linearly disaggregate total asset values of a country to a geographical grid. More precisely, the value of LitmPop relative to the sum of LitmPopn over all pixels within the boundaries of the country determines how much of a total value is assigned to each grid cell:
where Ipix denotes the asset value per grid cell. The given value of a country's total asset value Itot is distributed to each grid cell proportionally to the LitmPopn share of the grid cell. N denotes the total number of grid cells (iterator pixi) inside the boundaries of the country.
Changing the exponents m and n determines with which power the two input variables contribute to the disaggregation function. The exponents m and n do not only weight relatively between Lit and Pop but they also determine the contrast in the distribution between all grid cells within a country. The larger the exponent, the more value is concentrated on grid cells with large values of Lit or Pop. The aim of the evaluation described in Sect. 2.6 is to compare disaggregation skill of varied combinations of m and n and select the most adequate combinations for subnational disaggregation.
Itot can represent either asset value or GDP, depending on the context. For the creation of gridded asset exposure data, Itot represents asset value, i.e., produced capital or nonfinancial wealth. For the evaluation presented in Sect. 2.6, Itot represents the flow variable GDP instead, as in the study of Zhao et al. (2017).
2.6 Evaluation
Gridded population and nightlight intensity can both be used as proxies for the spatial distribution of asset exposure. Both proxies have limitations: an asset distribution proportional to population density assumes that physical wealth is distributed equally among the population and that assets are located exactly where people live. As already mentioned in Sect. 2.3, for many developing countries, gridded population data have a coarse resolution. Nightlight-based models, on the other hand, are mainly limited by saturation and blooming as described in the Introduction. By combining nightlight intensity and population count, we expect to combine their skills while reducing the limitations mentioned above.
The LitPop approach's skill in disaggregating asset exposure cannot be assessed directly due to the lack of reference asset value data on a subnational level. Therefore, GDP and GRP are used instead for an indirect evaluation of the methodology. GDP and GRP are used to assess the subnational disaggregation skill, comparing varying combinations of the exponents m and n in LitmPopn.
The disaggregation skill is assessed as follows: (i) national GDP is disaggregated to the grid level. (ii) The resulting gridded GDP is then re-aggregated for each subnational region (i.e., district, state, or canton) to obtain modeled GRP. (iii) Based on the comparison of normalized modeled and reported reference values of GRP, skill metrics are computed per country. In total, we use reported GRP data for 507 regions in 14 countries to evaluate the model's ability to distribute national GDP to subnational regions.
To ensure comparability of skill metrics between different countries, GRP is normalized:
where nGRPi denotes the normalized GRP of subnational region i. Given that , it follows from Eq. (3) that . Here, N is the set of all subnational units in the country.
To assess the disaggregation skill per country, three skill metrics are computed from nGRP.
The Pearson correlation coefficient ρ (Eq. 4) is computed to measure the linear correlation between the modeled nGRPmod and the reference value nGRPref. ρ is computed from the covariance (cov) and the standard deviations σmod=σ(nGRPmod) and σref=σ(nGRPref):
The correlation coefficient ρ is a widely used metric and straightforward to interpret and communicate: a value of 1 indicates a perfect positive linear correlation between the two variables while a value of 0 indicates that there is no linear correlation. However, ρ is no direct measure of the deviations of nGRPmod from nGRPref and yields no information regarding the slope β of the linear relationship. Therefore, it only represents a potential skill and needs to be evaluated in combination with a measure of the slope. The slope of the linear regression conveys the information, whether there is a systematic over- or underestimation of regions with relatively large GRP in the disaggregated data. is calculated to complement the analysis: β larger (lower) than 1 implies an overestimation (underestimation) of the GRP of regions with relatively large GRP and an underestimation (overestimation) of regions with relatively low GRP by the downscaling within one country. Together, ρ and β allow for an evaluation of the linear fit between modeled and reference data.
Complementarily, the root-mean-squared fraction (RMSF) is a relative error metric, weighting the relative deviation for each region equally, independently of the absolute values. Therefore, RMSF (Eq. 5) puts equal weight on all subnational administrative units in a country, even if their GRP and thus their absolute difference between modeled and reference values are small. A RMSF of 1 indicates a perfect fit. A RMSF value of 2 means that on average the modeled GRP deviates by a multiplicative factor of 2 from the reference value.
For evaluation, the three skill metrics are calculated for varying combinations of nightlight and population data for the disaggregation of GDP. The resulting skill metrics are compared for each combination and country.
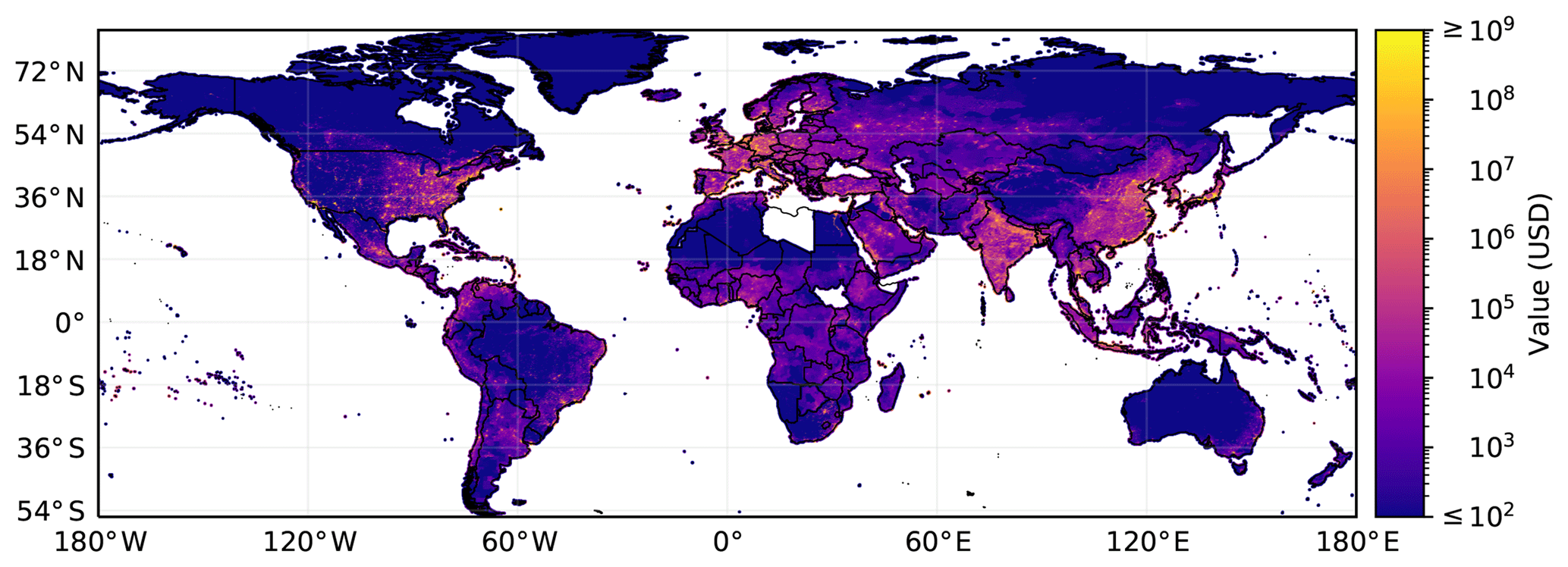
Figure 2World map showing gridded asset exposure values scaled to a resolution of 600 arcsec. The actual resolution of the underlying gridded data is 30 arcsec (∼1 km). To obtain this dataset, national total asset values were disaggregated proportional to the distribution of Lit1Pop1 for 224 countries and areas. A total of 26 countries and areas without data are left blank, including Libya, South Sudan, and Syria. The color map is logarithmic and limited to USD 100 (lower bound) and USD 1 000 000 000 (upper bound). Borders and coast lines are based on Cartopy (Met Office, 2019).
3.1 Global gridded asset exposure
We applied the LitPop methodology with the exponents to compute gridded asset exposure data for 224 countries and areas worldwide (Fig. 2). Total physical asset values of 2014 were disaggregated proportionally to Lit1Pop1 to a grid with the spatial resolution of 30 arcsec (approximately 1 km). Total asset values in the dataset sum up to 2.51×1014 (251 trillion) current US dollars in 2014. The 140 countries with produced capital data used as total asset value (see Sect. 2.4.1) contribute USD 245 trillion (97.6 %) to the total asset exposure. The remaining 84 countries where asset values were estimated from GDP and a GDP-to-wealth ratio instead contribute the remaining USD 6 trillion. In total, the 224 countries contribute around 99.9 % to recorded global GDP. All numbers are based on the national values assembled in Table S1. Data sources are summarized in Table 1.
In the following subsections, the LitPop methodology is evaluated both quantitatively and qualitatively. The results of the quantitative assessment of disaggregation skill introduced in Sect. 2.6 are presented in Sect. 3.2, providing justification for the selected combination of the exponents m and n for the global dataset. Differences between asset exposure distribution based on Lit1, Pop1, and Lit1Pop1 are shown by example of detail maps of two metropolitan areas (Sect. 3.3). Finally, limitations of the LitPop methodology are discussed by the example of GDP disaggregation in Mexico (Sect. 3.4).
3.2 Evaluation
To evaluate the performance of the LitPop methodology, we compute and compare the disaggregation skill with regards to GDP for varying exponents m and n in LitmPopn (Eqs. 1 and 2). Here, we show the comparison based on 14 countries with a total of 507 regional GRP data points available. The 14 countries make up 67 % (USD 168 trillion) of the total dataset's exposure and 64.5 % (USD 52 trillion) of global GDP in 2014. Ten combinations of m and n are assessed: Lit1Pop1, Lit1, Lit2, Lit3, Lit4, Lit5, Pop1, Pop2, Lit2Pop1, and Lit3Pop1. These exponent combinations were selected based on examples in the literature and then explored iteratively, stopping at combinations with decreased skill compared to lower-order combinations. For each country and exponent combination, the median and the spread of three skill metrics are compared: ρ, β, and RMSF (Fig. 3 and Tables A2 and A3).
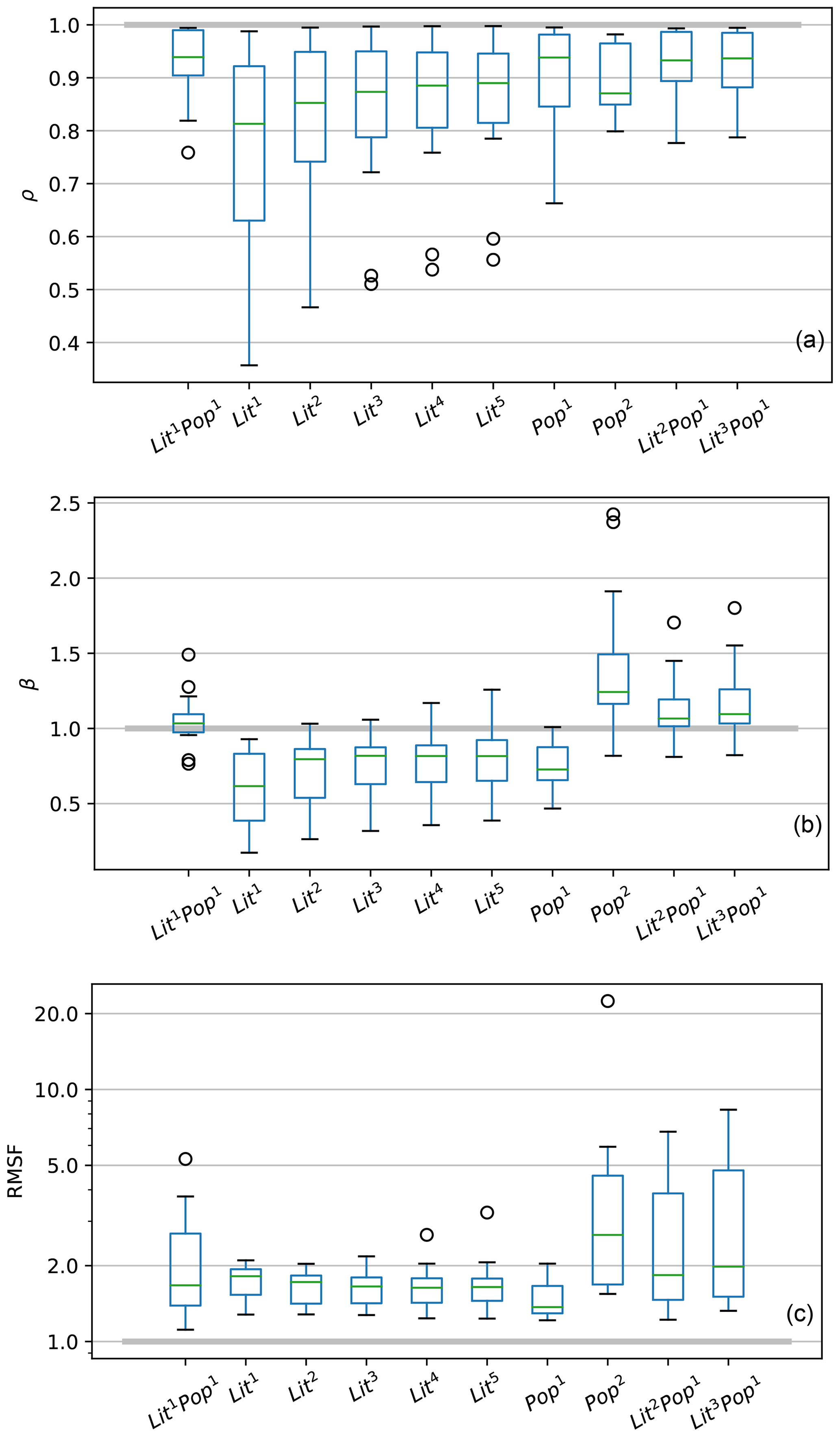
Figure 3Box plots showing the skill metrics ρ (a), β (b), and RMSF (c) for variations in LitmPopn. The metric value of 1, indicating perfect skill, is demarcated by the solid grey line. The plots are based on data from 14 countries and show the median (green), the first and third quartiles (IQR, blue box), data points outside the IQR but not more than 1.5⋅IQR distance from either the first or the third quartile (black whiskers), and outliers (black circles). RMSF is plotted on a logarithmic scale. Underlying metric values per country are listed in Table A2. Median and IQR per skill metric and combination of exponents are shown in Table A3.
For ρ (Fig. 3a), Lit1Pop1 shows the best overall median of ρ (0.94) with the lowest interquartile range (IQR) of 0.09. The IQR is used here as a measure of variability of the skill metrics, as it signifies the difference between the 25th and the 75th percentiles of the resulting skill metric. The same holds for β of Lit1Pop1 (median =1.03, IQR =0.12, Fig. 3b). In contrast, β is on average well below 1 for combinations exclusively based on Lit (i.e., Litm). A value of β below 1 indicates an underestimation of the GRP of regions with relatively large GRP and an overestimation of smaller regions. This can possibly be attributed to the saturation problem of nightlight intensity data, given that large regions with relatively large GRP usually accommodate more metropolitan areas where saturation occurs the most. This interpretation is supported by the relatively low asset values attributed to London and Mumbai metropolitan areas by Lit1 shown in Sect. 3.3.
For purely population-based disaggregation, we found a median of β below 1 for Pop1and well above 1 for Pop2 (Fig. 3b). This suggests that disaggregation proportional to Pop1 underestimates the asset values in urban agglomerations, while it is overestimated by Pop2. For the metric RMSF, Pop1 (median =1.37, IQR =0.37) and Lit4 (median =1.64, IQR =0.36) perform best, while Lit1Pop1 has a median RMSF of 1.67 and an IQR of 1.29 (Fig. 3c).
Within the set of combinations exclusively based on Lit (n=0), the skill metrics β and RMSF perform best for Lit4 (Fig. 3b, c), with median ρ improving for larger values of m, however changing little from Lit4 to Lit5 (Fig. 3a).
Based on the comparison of the disaggregation skill with varying exponents m and n, there are two candidates for the most adequate functionality: Lit1Pop1 (best ρ and β) and Lit4 (best RMSF and best performance for n=0). The skill metrics of linear regression, ρ and β, give a better representation of the disaggregation skill for the absolute values than RMSF, which is based on the relative deviation per data point. Prioritizing a better distribution of total values over relative performance, we conclude that Lit1Pop1 can be considered the most adequate combination of Lit and Pop for the subnational downscaling of GDP. For countries with a lack of highly resolved population data, alternative datasets could be produced based on Lit4 alone.
3.3 Detailed maps for metropolitan areas
Saturation and blooming in nightlight intensity data cause disaggregation based on nightlights alone to misrepresent actual value distribution, especially in urban areas. This can be seen in Fig. 4, showing maps of the distribution of national produced capital disaggregated proportional to Lit1 (a), Pop1 (b), and Lit1Pop1 (c) for two wider metropolitan areas. London (top row) and Mumbai (bottom) were chosen as examples. Comparable maps for Mexico City and New York are shown in Fig. A1 in the Appendix.
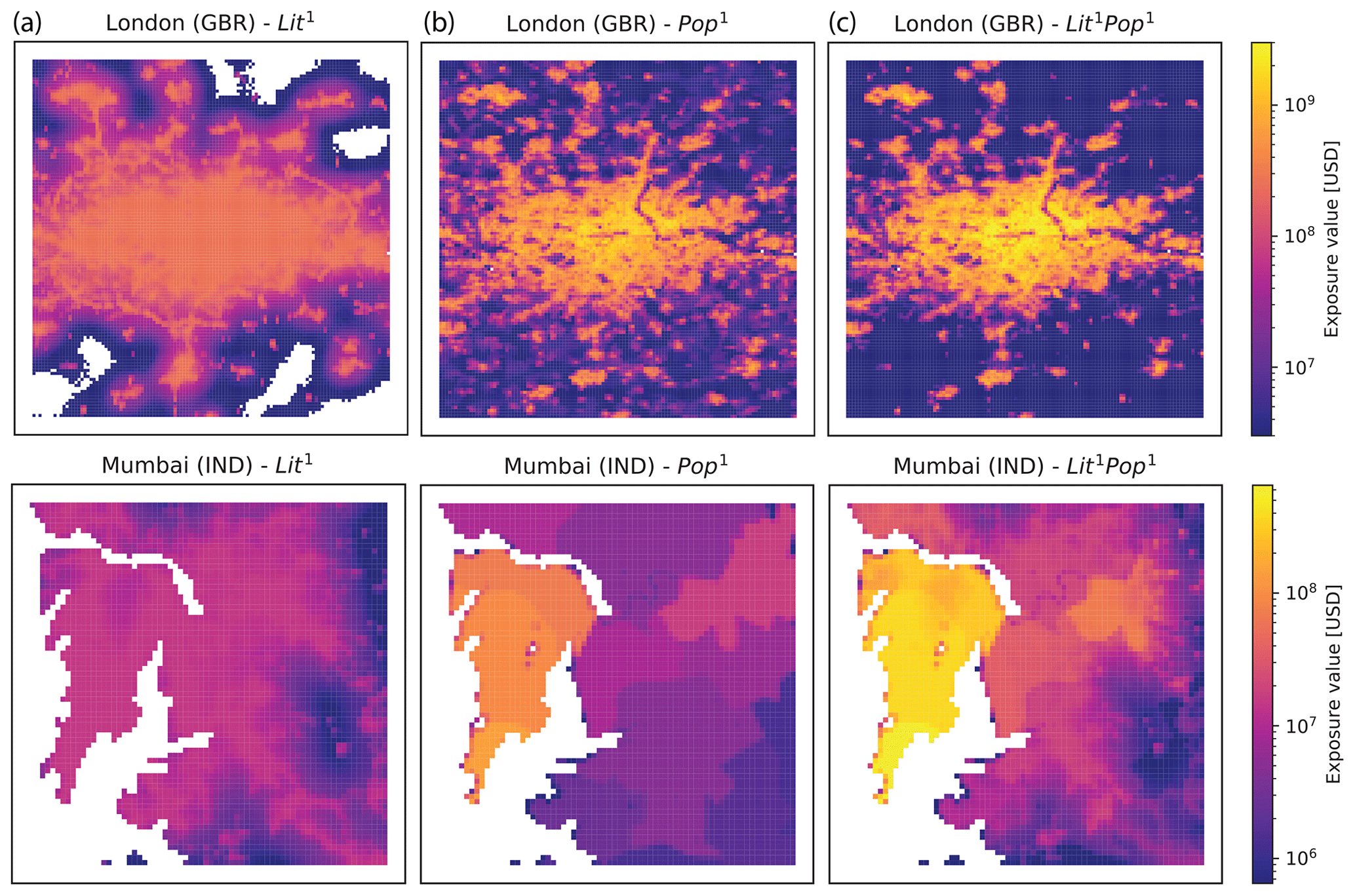
Figure 4Maps of disaggregated asset exposure value. Values are spatially distributed proportional to nightlight intensity of 2016 (Lit1, a), population count as of 2015 (Pop1, b), and the product of both (Lit1Pop1, c) for metropolitan areas in the United Kingdom (GBR) and India (IND). The maps are restricted to the wider metropolitan areas of London (51–52∘ N, 0.6∘ W–0.4∘ E) and Mumbai (18.8–19.4∘ N, 72–73.35∘ E). The color bar shows asset exposure values in current USD in 2014 per pixel of approximately 1 km2.
The general exposure value level in the metropolitan areas shown in Fig. 4 are largest for Lit1Pop1 (Fig. 4c), highlighting a larger concentration of values in urban areas with this approach. The value distribution based on Lit1 (Fig. 4a) does not show many details within the urban area. This effect is partially caused by saturation: the light radiation in the depicted areas is of such high intensity that the nightlight data do not offer any way to distinguish different levels of human activity. We can also observe the blooming effect, with the luminosity of bright parts crowding out to neighboring pixels, causing them to appear brighter than their underlying light sources would warrant. This latter effect can be particularly illustrated over the Thames River and Bow Creek in the northeastern part of London: The unpopulated river area is resolved by Pop1 (Fig. 4b top) but not by Lit1 (Fig. 4a top). By taking population density into account, the Lit1Pop1 dataset enhances contrast and detail in urban areas (Fig. 4b, c). In addition, bright objects can be overrepresented by Lit1: in Fig. 4a (top), the M25 London Orbital Motorway around London clearly stands out, with some pixels even at the same value as in central London. As seen in the case of Mumbai, the Lit1Pop1-based asset exposure map of the metropolitan area in Fig. 4c (bottom) shows much higher total values than those based on nightlights or population alone. This means that for Lit1Pop1, a larger proportion of the national produced capital of India is attributed to the metropolitan area of Mumbai compared to Lit1 and Pop1 alone.
3.4 Example Mexico
The skill metrics for the subnational disaggregation of GDP in the country Mexico show low values of ρ compared to most other countries for all tested values of m and n (ρ=0.76 for Lit1Pop1; see Table A2a). The example of Mexico is presented here to illustrate limitations and uncertainties of the disaggregation approach. Figure 5 shows the data behind the evaluation for Mexico, i.e., modeled and reference nGRP for all 32 districts of Mexico. The corresponding plot data can be found in Table S2 in the Supplement. While the LitPop methodology performs well for most of the districts with relatively low GRP, it fails to reproduce reference nGRP for the main (capital) metropolitan region consisting of the districts México and Mexico City (Distrito Federal).
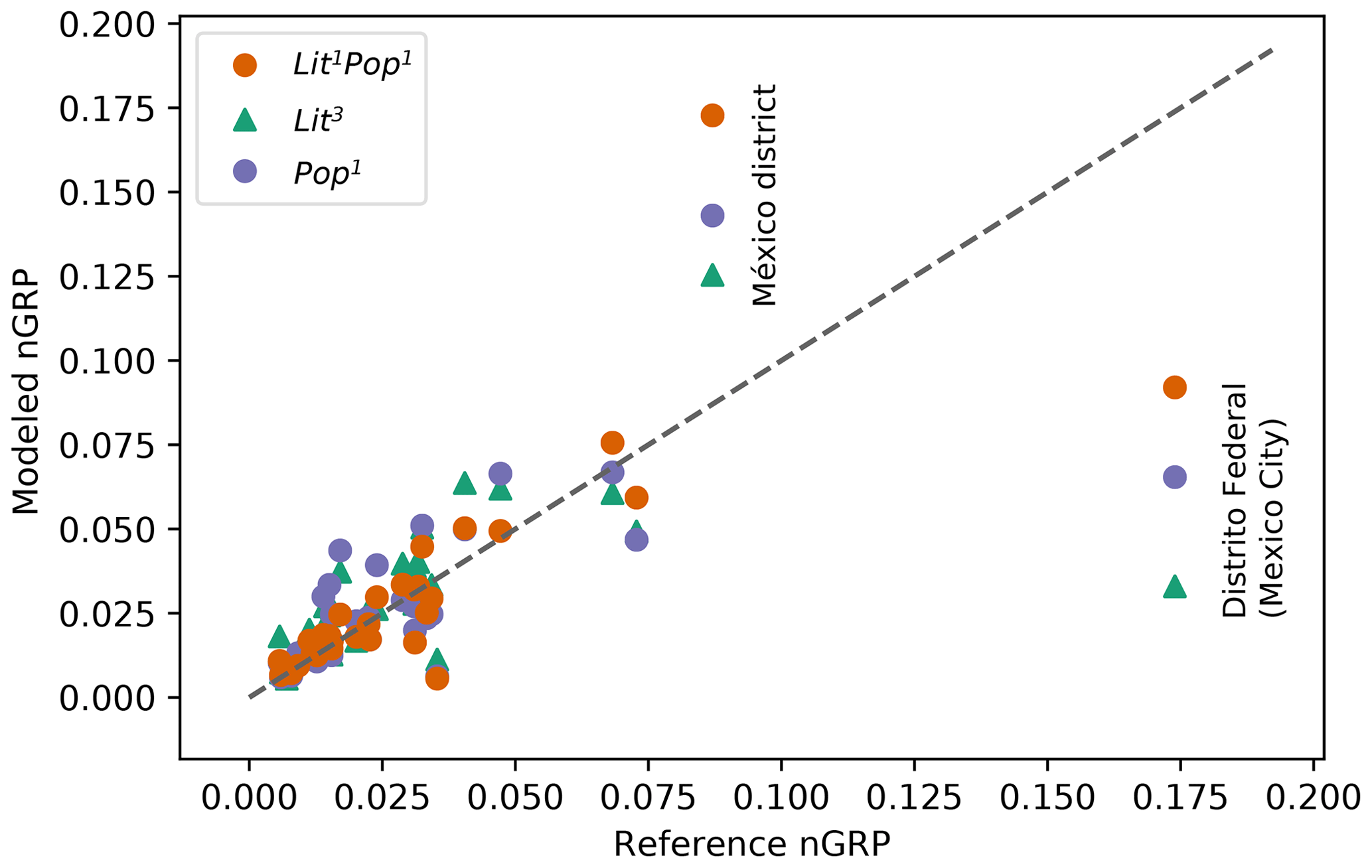
Figure 5Normalized gross regional product (nGRP) for the 32 districts of Mexico. Reference values are shown on the horizontal axis and modeled values on the vertical axis.
The two districts with the largest GRP of the highly centralized country are Distrito Federal (the Mexico City district) with a reference nGRP of 17.4 % and the México district (8.7 %), surrounding Distrito Federal. Asset exposure maps of the metropolitan region are shown in Fig. A1 in the Appendix. The disaggregation of GDP underestimates nGRP for the Mexico City district while overestimating the value for México for all evaluated combinations of m and n (nGRP values for Lit1Pop1, Lit3, and Pop1 are shown in Fig. 5). The overestimation of the México district's nGRP indicates that the district has an overproportional nightlight intensity and population count compared to a relatively low reference nGRP. Both districts combined sum up to modeled nGRP values of 11.2 % (m=1) to 17.6 % (m=5) for Litm, 20.8 % for Pop1, and 26.5 % for Lit1Pop1 (Table S2), the last agreeing well with a combined reference nGRP of 26.1 %.
The LitPop methodology allows for the creation of globally consistent and spatially highly resolved estimates of gridded asset exposure value. According to Pittore et al. (2017), efforts towards improving exposure data should aim at global consistency, continuous integration of new data and methods, and a careful validation of models and data. Here, we will discuss the advantages and limitations of the LitPop methodology with regard to the following key criteria: global consistency, disaggregation skill, scalability and flexibility, openness, replicability and reproducibility, and low entry threshold.
Global consistency. Based on globally available input data, the LitPop methodology was applied across countries from different continents and income groups. While the presented asset exposure dataset is not complete, it provides data for 224 countries contributing 99.9 % of global GDP. Therefore, LitPop-based asset exposure data can be used as a basis for globally comparable economic risk assessments. However, the evaluation of the methodology's disaggregation skill presented here is limited to an assessment of disaggregation skill for 14 OECD countries. It should be noted that due to lack of data we were not able to evaluate the method's performance for low-income countries (World Bank income group 1). Therefore, the application of the asset exposure data for local assessments in countries within low-income groups should be treated with caution. Another caveat to global consistency is the fact that the quality and resolution of the underlying population dataset vary between countries, as discussed in greater detail in the next paragraph. As a consequence of these limitations, asset exposure data should be validated against local data before application for local risk assessments, especially in low-income countries.
Assessment of disaggregation skill. For the gridded exposure dataset presented here, the LitPop methodology is used to disaggregate total asset values. Due to a lack of subnational reference asset values, the LitPop methodology's performance for the downscaling of asset stock values could not be evaluated directly. The assessment of disaggregation skill was instead based on the flow variables GDP and GRP. Given a correlation between stocks and flows within each country, this approach represents an indirect evaluation of the methodology for asset exposure downscaling. Evaluating 14 countries, we found that the LitPop methodology generally performs well in disaggregating GDP to the subnational level. The skill metrics ρ and β showed that Lit1Pop1 distributes GDP better to the subnational level than the other combinations of nightlight and population data assessed. For RMSF, Pop1 and Lit4 perform best on average. We selected Lit1Pop1 as a basis for the disaggregated asset exposure dataset presented here. This decision is based on two considerations: (1) giving ρ and β priority over RMSF because they are measures of absolute deviation between variables (compared to RMSF that is a measure of relative deviation per data point) and (2) the fact that Lit1Pop1 combines the advantages of both input data types and mitigates their disadvantages, i.e., with regard to saturation, blooming, and detail. For countries without a high detail level in the population data available, asset exposure based on LitmPopn is more or less equivalent to that based on Litm alone. For regional application in these countries, evaluation results suggest that disaggregation proportional to Lit4 could distribute asset values best in the absence of detailed population data.
Scalability and flexibility. Subject to data availability, the LitPop methodology can be used to estimate the distribution of physical asset values for any target year at a wide range of resolutions. The data sources used here cater to resolutions up to 30 arcsec. While the GPW dataset provides population data for the previous 2 decades, the NASA nightlight images are currently only available for 2012 and 2016. The methodology includes a scaling of exposure data proportional to current GDP for years without any data available. The methodology can potentially be adapted to a variety of applications by an appropriate choice of the socioeconomic indicator that is disaggregated. The World Bank's produced capital data are used here as the default total asset value per country. Alternatively, GDP can be used as an estimator of economic output. GDP multiplied by a factor derived from the country-specific income group can also be used to estimate asset values (Aznar-Siguan and Bresch, 2019; Geiger et al., 2017). This was done for countries without produced capital numbers available. Since the CLIMADA repository is open-source, the LitPop methodology can be amended to include alternative data sources and versions of gridded nightlight, population, and total asset values or other socioeconomic indicators to expand and update the asset exposure data. The LitPop methodology was developed to provide globally consistent asset exposure data for global-scale physical risk modeling. While it could be used for other applications as well, the limitations of its scope should be noted. The LitPop methodology does not account for differences in infrastructure types and vulnerability. In addition, gridded data may cause poor scoping of areas most vulnerable, or those with more exposed population. The example of Mexico (Sect. 3.4) illustrates the limitations of the LitPop methodology when it comes to the disaggregation of GDP within a metropolitan area. While the disaggregation of GDP proportional to Lit1Pop1 nicely reproduces the summed nGRP of the metropolitan area, the methodology fails to reproduce the distribution of nGRP between the two districts that make up the metropolitan area. Therefore, the use of the asset exposure data for local applications should be treated with care. The use for local or sector-specific applications is limited without the addition of sector-specific datasets. For risk assessments with a local focus as well as in countries of low income, we would advise using more local approaches and bottom-up methods for identifying and analyzing the vulnerability component. Additionally, the asset exposure data could be further refined by including auxiliary data, such as road networks and land cover (Geiger et al., 2017; Murakami and Yamagata, 2019), or mobile phone cell antenna density (Brönnimann and Wintzer, 2018). In order to include sector-specific assets not represented by the LitPop methodology, i.e., power plants or mines in unpopulated areas, additional sector-specific asset inventories should be included (Gunasekera et al., 2015). For a globally consistent approach, sectoral data should however be included with caution, as such datasets are prone to regional or national biases.
Openness, replicability, and low entry threshold. The LitPop methodology was developed in the programming language Python 3 and published on the code hosting service GitHub as well as in a permanent repository (see Sect. 5). The CLIMADA repository is developed open-source and makes use of open-access data to enable unrestricted use for applications beyond academia. In addition to the dataset provided, the LitPop-module can be used both to apply the computed asset exposure data for direct application in event-based risk assessments with CLIMADA and to export gridded asset exposure data to standard formats for use in other applications. While Lit1Pop1 is the default, LitmPopn with custom exponents can be chosen as a basis for disaggregation. The documentation of CLIMADA is hosted on Read the Docs (https://climada-python.readthedocs.io/en/stable/, last access: 4 April 2020). It includes an interactive tutorial of CLIMADA and the LitPop module (https://climada-python.readthedocs.io/en/stable/tutorial/climada_entity_LitPop.html, last access: 4 April 2020), with guidance on how to compute and export LitPop-based asset exposure data.
Asset exposure data at a resolution of 30 arcsec for 224 countries, as well as normalized Lit1 and Pop1 for the 14 countries used for evaluation, are archived in the ETH Research Repository with the link https://doi.org/10.3929/ethz-b-000331316 (Eberenz et al., 2019). The LitPop methodology is openly available as a module of CLIMADA (Bresch et al., 2019a) at GitHub under the GNU GPL license (GNU Operating System, 2007). CLIMADA v1.2.0 was used for this publication, which is permanently available at the ETH Data Archive with the link https://doi.org/10.5905/ethz-1007-226 (Bresch et al., 2019b). The scripts reproducing the published dataset, as well as all figures in the present publication and the main results, are published in the CLIMADA papers repository on GitHub with the link https://github.com/CLIMADA-project (Aznar-Siguan et al., 2019).
The open-source LitPop methodology was developed to provide a geographical distribution of physical asset exposure values that can be used to model first-order economic impacts of weather and climate events and other natural disasters. It uses publicly available data sources to calculate gridded asset exposure estimates. The global consistency, flexibility and openness, and the integration in the CLIMADA repository offer value for manifold use cases for economic disaster risk modeling and climate change adaptation studies. However, the methodology could not be evaluated directly against subnational asset data, and the evaluation based on GDP was limited to 14 OECD countries. Therefore, the asset exposure data are not suitable for applications with a local or sector-specific focus without further validation. Future research and development could focus on the integration of more highly resolved population data and other ancillary data sources as they become available globally. Validation against subnational asset value and empirical asset stock inventories yields the potential to evaluate and further improve the accuracy of asset exposure downscaling, for both global and regional applications. Regional validation could further inform the choice of the most appropriate downscaling functionality for different income groups and world regions.
Table A1List of countries used for evaluation with the number of regions on the administrative level 1, the World Bank income group 2016, and GRP data source with URLs as accessed in January 2019. The income groups are low income (1), lower-middle income (2), upper-middle income (3), and high income (4). In total, GRP data for 507 regions in 14 countries were used.
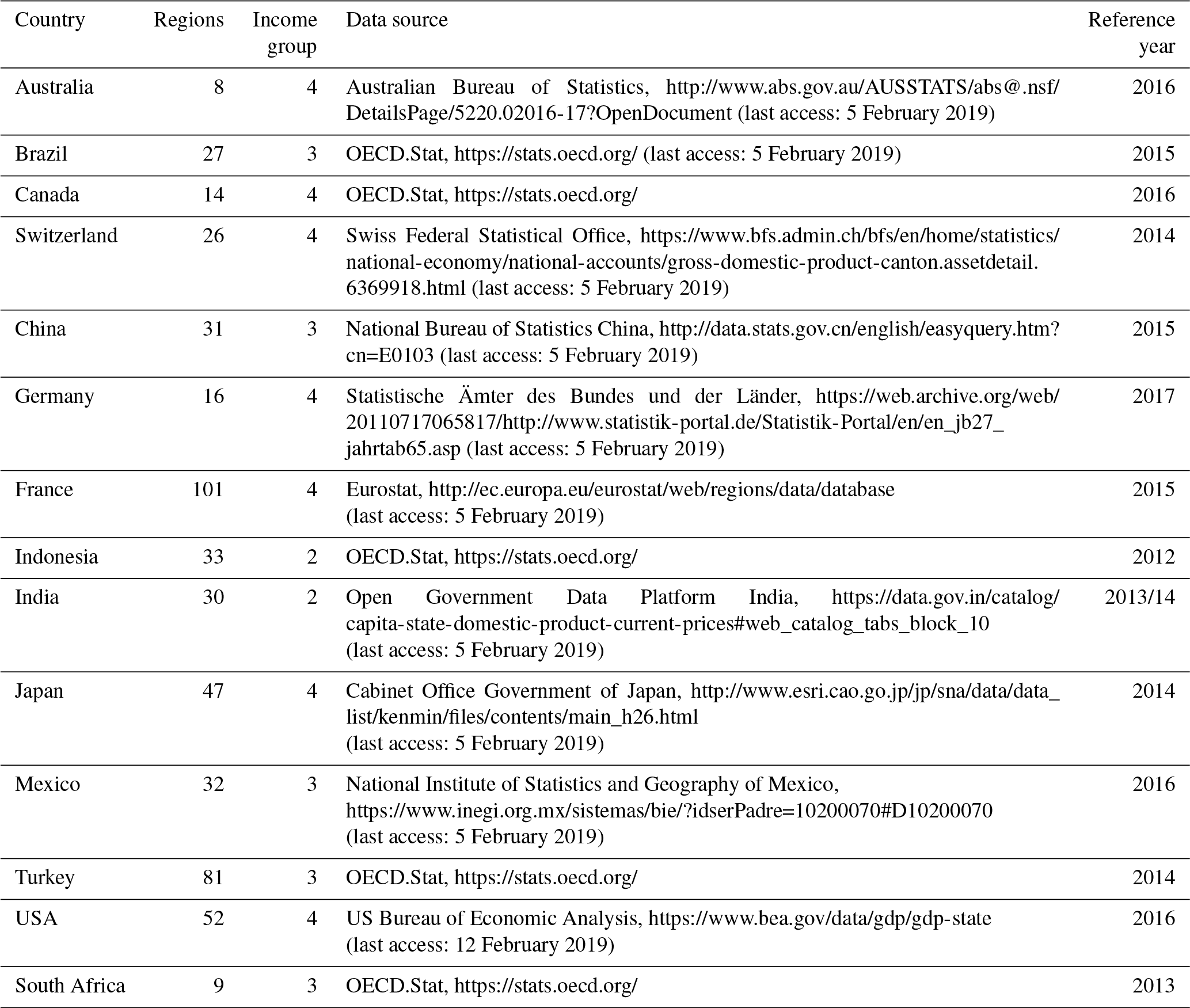
Table A2(a) Comparison of ρ for 10 exponent combinations and 14 countries: Australia (AUS), Brazil (BRA), Canada (CAN), Switzerland (CHE), China (CHN), Germany (DEU), France (FRA), Indonesia (IDN), India (IND), Japan (JPN), Mexico (MEX), Turkey (TUR), the United States of America (USA), and South Africa (ZAF). Best fit would mean ρ=1. Linear correlation is statistically significant with a p value lower than 0.05 for all shown countries and combinations. (b) Comparison of β for 10 exponent combinations and 14 countries: Australia (AUS), Brazil (BRA), Canada (CAN), Switzerland (CHE), China (CHN), Germany (DEU), France (FRA), Indonesia (IDN), India (IND), Japan (JPN), Mexico (MEX), Turkey (TUR), the United States of America (USA), and South Africa (ZAF). Best fit would mean β=1. Linear correlation is statistically significant with a p value lower than 0.05 for all shown countries and combinations. (c) Comparison of RMSF for 10 exponent combinations and 14 countries: Australia (AUS), Brazil (BRA), Canada (CAN), Switzerland (CHE), China (CHN), Germany (DEU), France (FRA), Indonesia (IDN), India (IND), Japan (JPN), Mexico (MEX), Turkey (TUR), the United States of America (USA), and South Africa (ZAF). Best fit would mean RMSF =1.
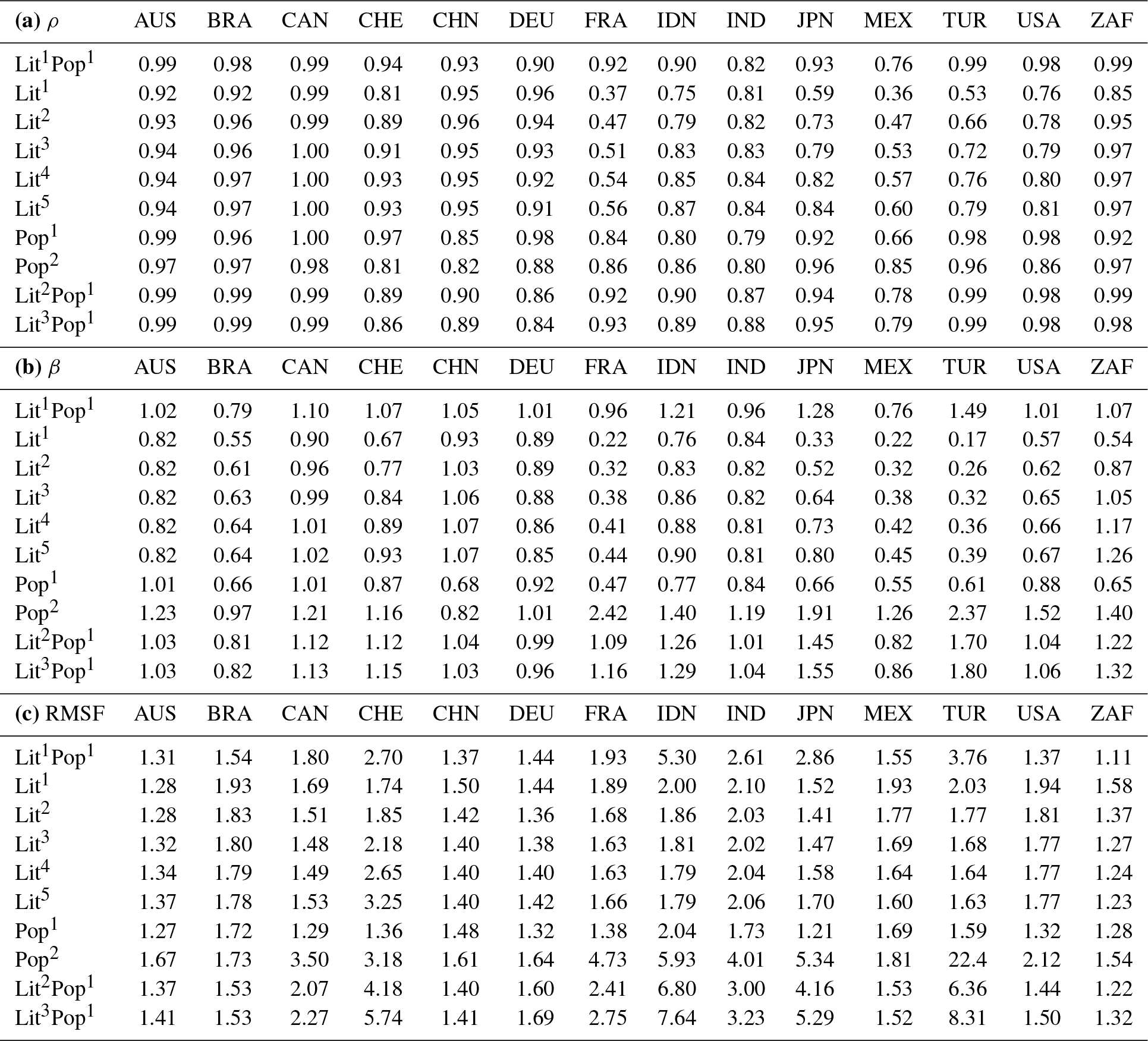
Table A3Comparison of three skill metrics measuring the fit between modeled and reference nGRP. The table shows the median and IQR over 14 countries computed from the data in Table A2a–c. Perfect fit would mean a value of 1 for each metric.
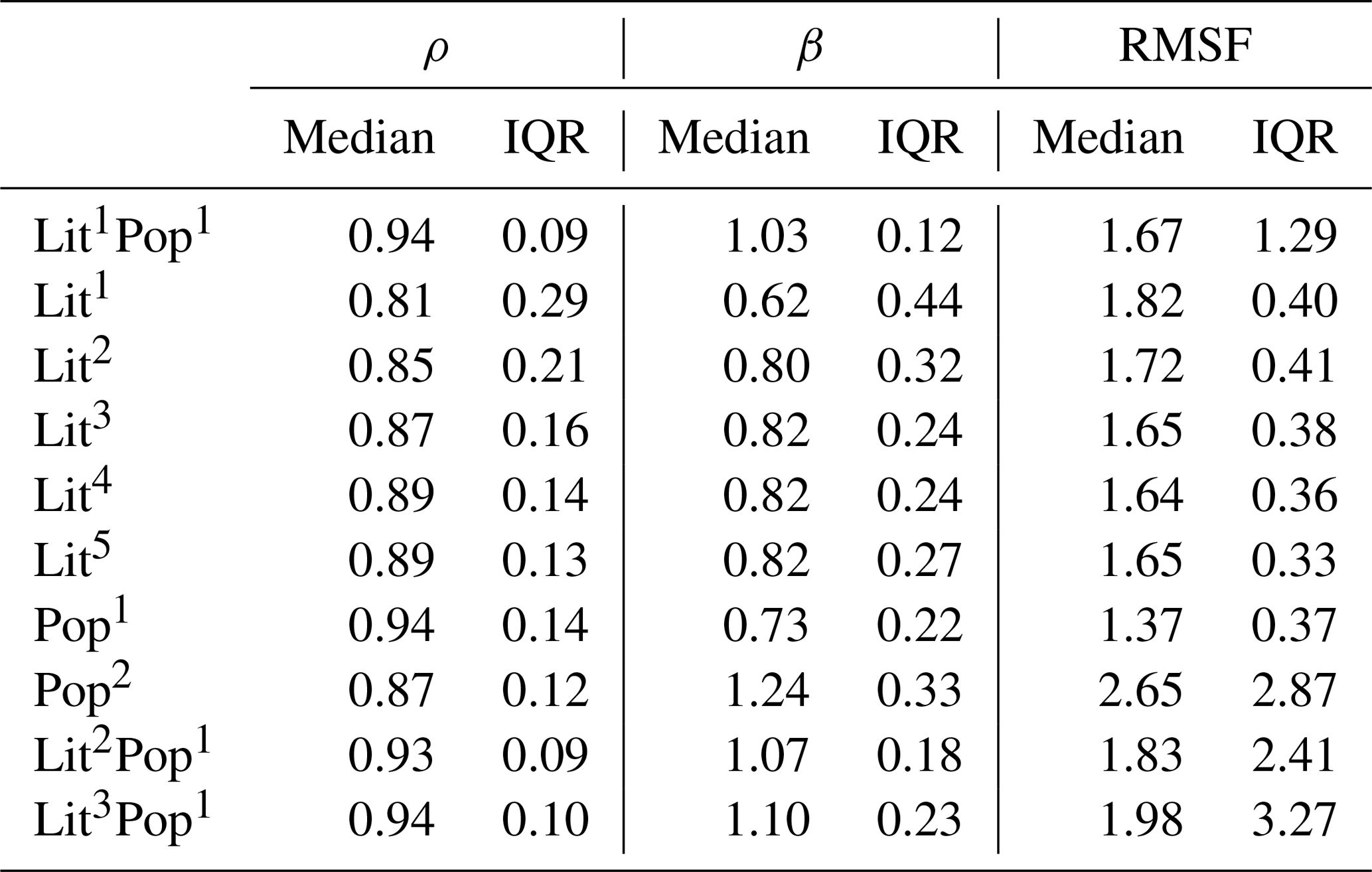
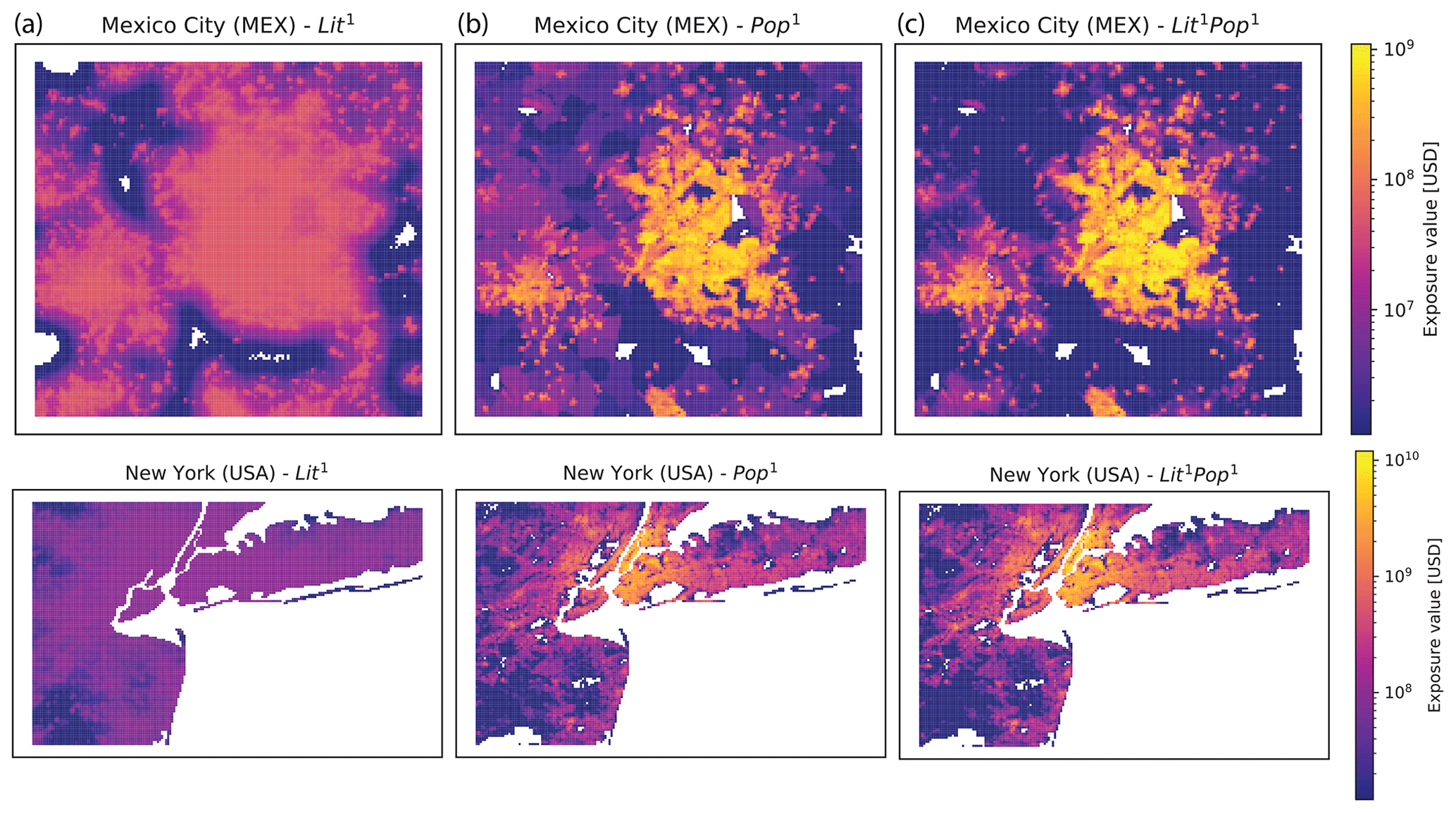
Figure A1Maps of disaggregated asset exposure value. Values are spatially distributed proportionally to nightlight intensity of 2016 (Lit1, a), population count as of 2015 (Pop1, b), and the product of both (Lit1Pop1, c) for Mexico City (MEX) and New York (USA). The maps are restricted to the wider metropolitan areas of Mexico City (18.9–20∘ N, 99.8–98.6∘ W) and New York (40–41∘ N, 74.6–73∘ W). The color bar shows asset exposure values in current US dollars in 2014.
The supplement related to this article is available online at: https://doi.org/10.5194/essd-12-817-2020-supplement.
DS, SE, and DNB developed the method collaboratively. The programming code was written by DS, TR, and SE. Evaluation and visualization was carried out by TR and SE. SE prepared the manuscript with contributions from all co-authors.
The authors declare that they have no conflict of interest.
We would like to thank Lea Müller for her initial implementation of gridded nightlight as a proxy for global asset exposure, Gabriela Aznar-Siguan for her input regarding the platform CLIMADA, and all members of the Weather and Climate Risks Group at ETH Zurich for their input and discussions shaping this publication. We would like to thank the two anonymous referees for their thorough and valuable reviews.
This research has been supported by the Innosuisse – Schweizerische Agentur für Innovationsförderung (grant no. 26792.1 PFES-ES).
This paper was edited by David Carlson and reviewed by two anonymous referees.
Aznar-Siguan, G. and Bresch, D. N.: CLIMADA v1: a global weather and climate risk assessment platform, Geosci. Model Dev., 12, 3085–3097, https://doi.org/10.5194/gmd-12-3085-2019, 2019.
Aznar-Siguan, G., Bresch, D. N., and Eberenz, S.: CLIMADA-papers repository – github.com/CLIMADA-project/climada_papers, available at: https://github.com/CLIMADA-project/climada_papers, last access: 20 March 2019.
Bresch, D. N., Aznar-Siguan, G., Eberenz, S., Röösli, T., Stocker, D., Hartman, J., Pérus, M., and Bozzini, V.: CLIMADA repository, available at: https://github.com/CLIMADA-project/climada_python last access: 20 March 2019a.
Bresch, D. N., Aznar-Siguan, G., Eberenz, S., Röösli, T., Stocker, D., Hartman, J., Pérus, M,. and Bozzini, V.: CLIMADA v.1.2.0, ETH Data Archive, https://doi.org/10.5905/ethz-1007-226, 2019b.
Brönnimann, S. and Wintzer, J.: Climate data empathy, Wires. Clim. Change, 10, 1–8, https://doi.org/10.1002/wcc.559, 2018.
Cardona, O.-D., van Aalst, M. K., Birkmann, J., Fordham, M., McGregor, G., Perez, R., Pulwarty, R. S., Schipper, E. L. F., Sinh, B. T., Décamps, H., Keim, M., Davis, I., Ebi, K. L., Lavell, A., Mechler, R., Murray, V., Pelling, M., Pohl, J., Smith, A.-O., and Thomalla, F.: Determinants of Risk: Exposure and Vulnerability, in Managing the Risks of Extreme Events and Disasters to Advance Climate Change Adaptation, edited by: Field, C. B., Barros, V., Stocker, T. F., and Dahe, Q., Cambridge University Press, Cambridge, 65–108, 2012.
Carlowicz, M.: Out of the Blue and Into the Black, available at: https://earthobservatory.nasa.gov/Features/IntotheBlack (last access: 10 February 2020), 2012.
Carlowicz, M.: Night Light Maps Open Up New Applications, available at: https://earthobservatory.nasa.gov/images/90008/night-light-maps-open-up-new-applications (last access: 10 February 2020), 2017.
Center for International Earth Science Information Network (CIESIN): Documentation for the Gridded Population of the World, Version 4 (GPWv4), Revision 10 Data Sets, 2017.
Credit Suisse Research Institute: Global Wealth Report 2017, Credit Suisse Research Institute, available at: https://www.credit-suisse.com/corporate/en/articles/news-and-expertise/global-wealth-report-2017-201711.html (last access: 6 September 2019), 2017.
De Bono, A. and Mora, M. G.: A global exposure model for disaster risk assessment, Int. J. Disaster Risk Re., 10, 442–451, https://doi.org/10.1016/j.ijdrr.2014.05.008, 2014.
Doxsey-Whitfield, E., MacManus, K., Adamo, S. B., Pistolesi, L., Squires, J., Borkovska, O. and Baptista, S. R.: Taking Advantage of the Improved Availability of Census Data: A First Look at the Gridded Population of the World, Version 4, Papers in Applied Geography, 1, 226–234, https://doi.org/10.1080/23754931.2015.1014272, 2015.
Eberenz, S., Stocker, D., Röösli, T., and Bresch, D. N.: LitPop: Global Exposure Data for Disaster Risk Assessment, ETH Research Collection, https://doi.org/10.3929/ethz-b-000331316, 2019.
Elvidge, C., Safran, J., Nelson, I., Tuttle, B., Ruth Hobson, V., Baugh, K., Dietz, J., and Erwin, E.: Area and Positional Accuracy of DMSP Nighttime Lights Data, in: Remote Sensing and GIS Accuracy Assessment, 281–292, 2004.
Elvidge, C. D., Cinzano, P., Pettit, D. R., Arvesen, J., Sutton, P., Small, C., Nemani, R., Longcore, T., Rich, C., Safran, J., Weeks, J., and Ebener, S.: The Nightsat mission concept, Int. J. Remote Sens., 28, 2645–2670, https://doi.org/10.1080/01431160600981525, 2007.
Elvidge, C. D., Baugh, K. E., Anderson, S. J., Sutton, P. C., and Ghosh, T.: The Night Light Development Index (NLDI): a spatially explicit measure of human development from satellite data, Soc. Geogr., 7, 23-35, https://doi.org/10.5194/sg-7-23-2012, 2012.
Geiger, T.: Continuous national gross domestic product (GDP) time series for 195 countries: past observations (1850–2005) harmonized with future projections according to the Shared Socio-economic Pathways (2006–2100), Earth Syst. Sci. Data, 10, 847–856, https://doi.org/10.5194/essd-10-847-2018, 2018.
Geiger, T., Daisuke, M., Frieler, K., and Yamagata, Y.: Spatially-explicit Gross Cell Product (GCP) time series: past observations (1850–2000) harmonized with future projections according to the Shared Socioeconomic Pathways (2010–100), https://doi.org/10.5880/PIK.2017.007, 2017.
Gettelman, A., Bresch, D. N., Chen, C. C., Truesdale, J. E., and Bacmeister, J. T.: Projections of future tropical cyclone damage with a high-resolution global climate model, Climatic Change, 146, 575–585, https://doi.org/10.1007/s10584-017-1902-7, 2017.
Ghosh, T., Anderson, S. J., Elvidge, C. D., and Sutton, P. C.: Using nighttime satellite imagery as a proxy measure of human well-being, Sustainability-Basel, 5, 4988–5019, https://doi.org/10.3390/su5124988, 2013.
GNU Operating System: GNU General Public License, version 3, available at: https://www.gnu.org/licenses/gpl-3.0.en.html (last access: 10 February 2020), 2007.
Gunasekera, R., Ishizawa, O., Aubrecht, C., Blankespoor, B., Murray, S., Pomonis, A., and Daniell, J.: Developing an adaptive global exposure model to support the generation of country disaster risk profiles, Earth-Sci. Rev., 150, 594–608, https://doi.org/10.1016/j.earscirev.2015.08.012, 2015.
Han, J., Meng, X., Liang, H., Cao, Z., Dong, L., and Huang, C.: An improved nightlight-based method for modeling urban CO2 emissions, Environ. Modell. Softw., 107, 307–320, https://doi.org/10.1016/j.envsoft.2018.05.008, 2018.
Henderson, J. V., Storeygard, A., and Weil, D. N.: Measuring Economic Growth from Outer Space, Am. Econ. Rev., 102, 994–1028, https://doi.org/10.1257/aer.102.2.994, 2012.
IPCC: Managing the Risks of Extreme Events and Disasters to Advance Climate Change Adaptation: Special Report of the Intergovernmental Panel on Climate Change, edited by: Field, C. B., Barros, V., Stocker, T. F., and Dahe, Q., Cambridge University Press, Cambridge, 2012.
IPCC: Climate Change 2014: Impacts, Adaptation, and Vulnerability. Part A: Global and Sectoral Aspects. Contribution of Working Group II to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change, edited by: Field, C. B., Barros, V. R., Dokken, D. J., Mach, K. J., Mastrandrea, M. D., Bilir, T. E., Chatterjee, M., Ebi, K. L., Estrada, Y. O., Genova, R. C., Girma, B., Kissel, E. S., Levy, A. N., MacCracken, S., Mastrandrea, P. R., and White, L. L., Cambridge University Press, Cambridge, United Kingdom and New York, NY, USA, 2014.
Kuhn, M. and Ríos-Rull, J.-V.: 2013 Update on the U.S. Earnings, Income, and Wealth Distributional Facts: A View from Macroeconomics, Quarterly Review, 37, https://doi.org/10.21034/qr.3711, 2016.
Kummu, M., Taka, M., and Guillaume, J. H. A.: Gridded global datasets for Gross Domestic Product and Human Development Index over 1990–2015, Sci. Data, 5, 180004, https://doi.org/10.1038/sdata.2018.4, 2018.
Lee, S., Chiang, K., Xiong, X., Sun, C., and Anderson, S.: The S-NPP VIIRS Day-Night Band On-Orbit Calibration/Characterization and Current State of SDR Products, Remote Sensing, 6, 12427–12446, https://doi.org/10.3390/rs61212427, 2014.
Leyk, S., Gaughan, A. E., Adamo, S. B., de Sherbinin, A., Balk, D., Freire, S., Rose, A., Stevens, F. R., Blankespoor, B., Frye, C., Comenetz, J., Sorichetta, A., MacManus, K., Pistolesi, L., Levy, M., Tatem, A. J., and Pesaresi, M.: The spatial allocation of population: a review of large-scale gridded population data products and their fitness for use, Earth Syst. Sci. Data, 11, 1385–1409, https://doi.org/10.5194/essd-11-1385-2019, 2019.
Mellander, C., Lobo, J., Stolarick, K., and Matheson, Z.: Night-Time Light Data: A Good Proxy Measure for Economic Activity?, edited by: Schumann, G. J.-P., PLOS ONE, 10, e0139779, https://doi.org/10.1371/journal.pone.0139779, 2015.
Met Office: Cartopy: A Cartographic Python Library with a Matplotlib Interface, Devon, Exeter, United Kingdom, available at: http://scitools.org.uk/cartopy (last access: 7 April 2020), 2019.
Murakami, D. and Yamagata, Y.: Estimation of Gridded Population and GDP Scenarios with Spatially Explicit Statistical Downscaling, Sustainability, 11, 2106, https://doi.org/10.3390/su11072106, 2019.
NASA Earth Observatory: Earth at Night: Flat Maps, available at: http://earthobservatory.nasa.gov/features/NightLights/page3.php (last access: 10 February 2020), 2017.
Organisation for Economic Co-operation and Development: OECD.Stat, available at: https://stats.oecd.org/ (last access: 31 January 2019), 2019.
Pinkovskiy, M. L.: Economic Discontinuities at Borders: Evidence from Satellite Data on Lights at Night, Working Paper, 2014.
Pittore, M., Wieland, M. and Fleming, K.: Perspectives on global dynamic exposure modelling for geo-risk assessment, Nat. Hazards, 86, 7–30, https://doi.org/10.1007/s11069-016-2437-3, 2017.
Román, M. O., Wang, Z., Sun, Q., Kalb, V., Miller, S. D., Molthan, A., Schultz, L., Bell, J., Stokes, E. C., Pandey, B., Seto, K. C., Hall, D., Oda, T., Wolfe, R. E., Lin, G., Golpayegani, N., Devadiga, S., Davidson, C., Sarkar, S., Praderas, C., Schmaltz, J., Boller, R., Stevens, J., Ramos González, O. M., Padilla, E., Alonso, J., Detrés, Y., Armstrong, R., Miranda, I., Conte, Y., Marrero, N., MacManus, K., Esch, T., and Masuoka, E. J.: NASA's Black Marble nighttime lights product suite, Remote Sens. Environ., 210, 113–143, https://doi.org/10.1016/j.rse.2018.03.017, 2018.
Small, C., Pozzi, F., and Elvidge, C. D.: Spatial analysis of global urban extent from DMSP-OLS night lights, Remote Sens. Environ., 96, 277–291, https://doi.org/10.1016/j.rse.2005.02.002, 2005.
Socioeconomic Data and Applications Center (SEDAC): Country-level Information and Sources Revision 10, available at: https://beta.sedac.ciesin.columbia.edu/data/set/gpw-v4-admin-unit-center-points-population-estimates-rev10/docs (last access: 4 April 2020), 2017.
Sutton, P., Elvidge, C., and Ghosh, T.: Estimation of gross domestic product at sub-national scales using nighttime satellite imagery, International Journal of Ecological Economics & Statistics, 8, 5–21, 2007.
Sutton, P. C. and Costanza, R.: Global estimates of market and non-market values derived from nighttime satellite imagery, land cover, and ecosystem service valuation, Ecol. Econ., 41, 509–527, https://doi.org/10.1016/S0921-8009(02)00097-6, 2002.
UNISDR: Terminology on Disaster Risk Reduction, United Nations Publications, Geneva, Switzerland, 2009.
World Bank: Building the World Bank's Wealth Accounts: Methods and Data, Environment and Natural Resources Global Practice, World Bank, available at: https://development-data-hub-s3-public.s3.amazonaws.com/ddhfiles/94641/wealth-methodology-january-30-2018_4_0.pdf (last access: 14 January 2019), 2018.
World Bank: Wealth Accounting, available at: https://datacatalog.worldbank.org/dataset/wealth-accounting (last access: 10 February 2020), 2019a.
World Bank: World Bank Open Data, available at: https://data.worldbank.org/ (last access: 10 February 2020), 2019b.
Zhao, N., Samson, E. L., and Currit, N. A.: Nighttime-Lights-Derived Fossil Fuel Carbon Dioxide Emission Maps and Their Limitations, Photogramm. Eng. Rem. S., 81, 935–943, https://doi.org/10.14358/PERS.81.12.935, 2015.
Zhao, N., Liu, Y., Cao, G., Samson, E. L., and Zhang, J.: Forecasting China's GDP at the pixel level using nighttime lights time series and population images, GISci. Remote Sens., 54, 407–425, https://doi.org/10.1080/15481603.2016.1276705, 2017.
The requested paper has a corresponding corrigendum published. Please read the corrigendum first before downloading the article.
- Article
(5191 KB) - Full-text XML
- Corrigendum
-
Supplement
(61 KB) - BibTeX
- EndNote